 夜雨聆风
夜雨聆风

不好意思,可能还没有。:)
过去,你以为 AI 自由是“我终于不用自己干活了”;现在你会发现,真正卡住你的,可能不是能力,而是 Token 账单。
过去,这个账单之所以没那么刺眼,是因为大多数人还停留在“聊天框时代”:问几个问题,写几段文案,总结几篇文章。对个人用户来说,Token 被折叠进会员费、免费额度和次数限制里;对商业客户和团队来说,它也只是 API 控制台里一行不太起眼的消耗数字。它一直在计费,只是过去用得不够狠,所以疼得不明显。
但 Coding Agents、OpenClaw 和各类自动化工作流普及之后,事情变了。AI 不再只是“回答你”,而是开始“替你跑流程”:读文件、写计划、调用工具、执行脚本、分析日志、反复修正,再把结果整理成报告。你以为自己只是按下了一次“开始”,后台却可能已经默默烧掉了成千上万 Token;一转脸看账单,不对,是上百万。
于是,一个原本藏在冰山下的问题,被提前推到了所有人面前:
Tokens 的价格,怎样才不算太离谱?
2026 年 5 月,这个问题开始变得格外刺眼。DeepSeek V4 Flash 的价格已经低到 0.14 美元 / 百万 Token 起,粗略折算,100 万 Token 的输入成本接近 1 元人民币;而 OpenAI GPT-5 标准档的输出价格是 10 美元 / 百万 Token。如果同样按 1 亿 Token 的输出量粗算,GPT-5 约 7,100 元人民币,DeepSeek V4 Flash 约 200 元人民币。
这不是“贵一点”或“便宜一点”。这是同样叫 Token,背后却可能是两张完全不同的账单。
更反常的是,AI 价格并不是一路向下。2024 年 5 月,豆包主力模型打到 0.0008 元 / 千 Token,百度文心部分模型宣布免费,阿里通义千问 Qwen-Long 也把输入价格打到 0.0005 元 / 千 Token。那时,市场像是在宣告:AI 算力会越来越便宜,直到接近免费。
但两年后,价格又换了一种方式回来:豆包 App 开始测试 68 元 / 月起的订阅;阿里部分高阶模型和长上下文场景,价格重新回到 数十元 / 百万 Token。免费没有消失,它只是被重新包装、重新分层、重新收费。
所以,真正的问题不是“哪家最便宜”,而是:
我怎么知道一款模型的定价是否离谱?
对个人用户来说,这个问题决定会员值不值得买、免费额度会不会缩水、高级模型会不会被放进更贵档位;对商业客户和团队来说,它决定一次 Agent 工作流是否跑得起,模型选型是否划算,云端 API 和本地化部署之间应该如何取舍。
而这还只是开始。今天的 AI 普及度,远没有达到它真正会抵达的位置。我们正站在一个转折点上:AI 将从聊天框里的工具,逐渐嵌入写作、编程、教育、办公、客服、设计、搜索、数据分析,以及企业内部的每一道流程。到那时,Token 价格就不再只是 API 控制台上的数字,而会变成个人的数字生活成本、团队的生产预算、企业的基础设施开支。
所以,Token 定价最终决定的,不只是“哪家模型便宜”。它决定的是:AI 能不能被真正用起来,谁能用得起更强的智能,以及未来软件和服务的价格底座会被谁重新定义。
这就留下了一串更尖锐的问题:如果 Token 有成本,这个成本到底来自哪里?是 GPU、电费、带宽、模型大小、上下文长度,还是推理时间?为什么同样是生成 1 个 Token,不同厂商可以差几十倍?为什么 2024 年可以打到接近免费,2026 年又能换一种方式涨回来?当你看到一张模型价格表时,你看到的是全部公平信息,还是只看到了厂商愿意让你看到的那一层报价?
要回答这些问题,不能只看价格表。我们需要从四个维度重新关照这粒小小的 Token:标价维度,看厂商如何写价格;计费维度,看用户和团队如何真正付钱;价值维度,看 AI 能力如何被重新包装;资本运作维度,看厂商如何用补贴抢市场、用融资堆算力,再把算力变成可以被资本定价的资产。
今天,我们不比价。
我们解码。
一、Token 是 AI 时代的"千瓦时",但不是同一个"度"
Token 是大语言模型处理文本的最小单位。你可以把它理解为 AI 世界的"千瓦时"——就像电力公司按度收费,AI 厂商按 Token 收费。
一个英文单词通常拆成 1–2 个 Token,一个汉字约 1–1.5 个。你的问题被拆成 Input Tokens,AI 的回复被拆成 Output Tokens。两者价格不同,而且差距悬殊。
到这里为止,都是常识。但常识背后藏着一个很少有人注意的事实:
不同厂商的 Token,不是同一个计量单位。
TensorZero 团队做过一个系统实测:将完全相同的输入文本,分别用 OpenAI、Anthropic、Google 的官方 Token 计数 API 计算。结果是——Token 数差异高达 2.65 倍以上。
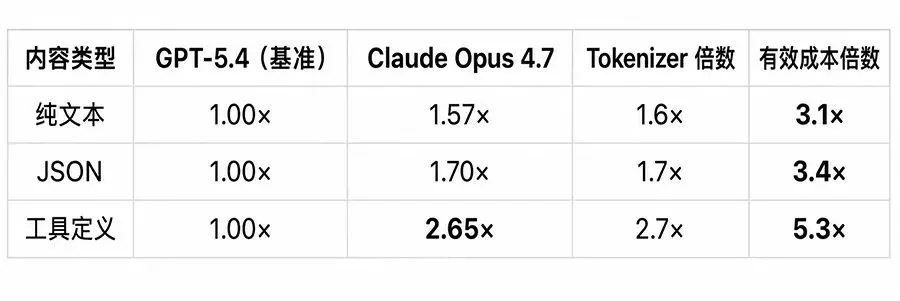
注意这个区别:Token 数差异是 Claude 把同一段文本切成了 2.65 倍 Token;有效成本倍数还要再叠加 Claude 输入标价是 GPT-5.4 的 2 倍——最终同一工具定义任务的实际输入成本可达到 5.3 倍。
就像你去两个菜市场买菜,A 市场说"每斤 10 元",B 市场说"每斤 5 元"。但你没注意到,B 市场的"斤"比 A 市场的大一倍,而且 B 的秤还额外加了一道手续费——算下来,B 市场反而更贵。
所以,"每百万 Token 多少钱"这个指标,本身就是第一层迷雾。它只告诉了你"标价层"的数字,完全没告诉你"计量层"的真相。
计费方式主要有两种:按量付费(用多少付多少)和包月订阅(ChatGPT Plus $20/月,本质上是带动态限额的访问套餐)。但无论哪种方式,核心计量单位都是 Token。而 Token 的计数方式,由厂商说了算。
二、标价全景:从"厘计价"到"明码标价的阳谋"

先来看一组数据。为了避免货币和口径混乱,以下统一按美元/百万 Token展示;国内平台若官方以人民币计价,按当前汇率折算。
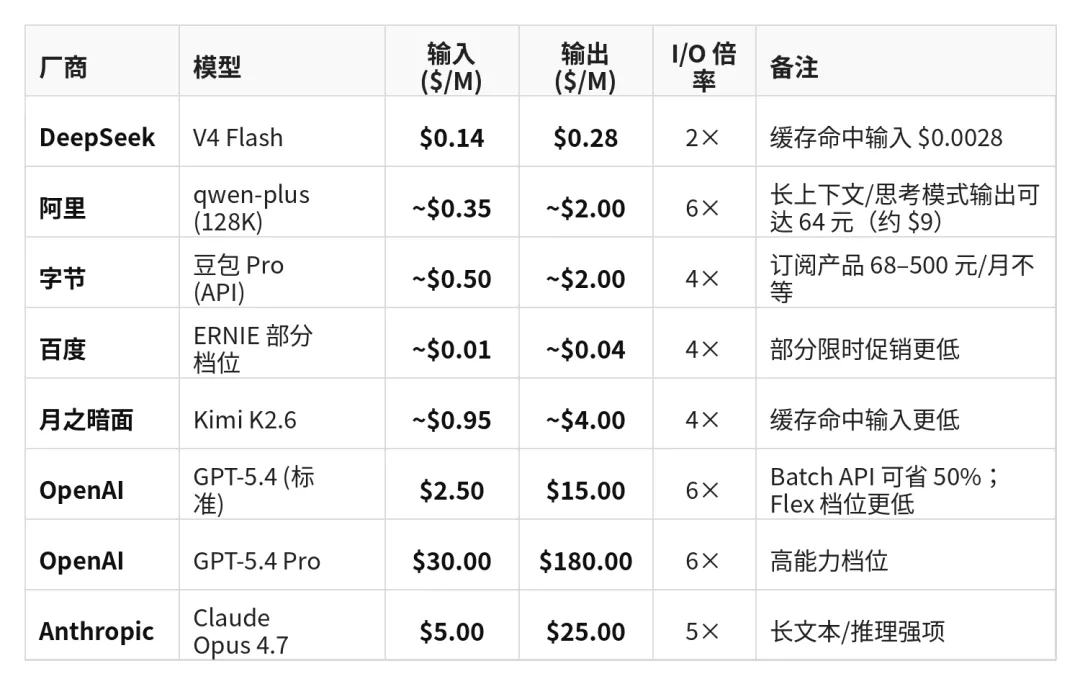
同样消耗 1 亿 Token(按 1:1 输入输出混合估算):Claude Opus 约 $1,500,DeepSeek Flash 约 $21,百度 ERNIE 低档位约 $10。标准档位差距约 70 倍;极端档位(Pro 对比促销价)差距可超过 500 倍。
但这个对比表有一个致命的盲区:它只展示了标价层的数字,完全没有展示计量层的差异、运行层的黑箱、以及资本层的成本结构。
价格战的逆转
2024 年 5 月,字节豆包以"比行业价格低 99.3%"点燃价格战。阿里、百度迅速跟进,一时间"免费""厘计价"成为热词。
但战火并未持续燃烧。到 2025 年,多家厂商陆续回调价格(新浪财经报道)。阿里 qwen-plus 在长上下文和思考模式下输出可达 64 元/百万 Token。讯飞星火 4.0 Turbo 维持高价。
2026 年 3 月,豆包 App 开始收费(标准版 68 元/月、专业版 500 元/月)。火山引擎披露:豆包日均 Token 使用量突破 120 万亿——从 2024 年的 1,200 亿暴涨 1000 倍,终于让字节也"扛不住了"。
这揭示了一个反直觉的事实:"免费"从来就不是商业模式,它是获客手段。 就像 19 世纪的电灯公司,先用免费照明培养用户习惯,再建立电网收费。
更隐蔽的是,部分厂商的账单设计暗藏阶梯:输出越长、上下文越大、调用越复杂,单价可能悄然跳涨。你在价格表上看不到这些暗门——它们藏在 API 文档的脚注里,或者更深处。
标价是厂商愿意给你看的叙事,账单才是用户的真实体验。
三、成本拆解:一粒 Token 的"成本篮子"

要理解定价,先要理解成本。一粒 Token 从出生到被你消费,经历多层成本。
第一层:边际成本——推理一次,到底花多少钱?
以 NVIDIA H100 GPU 为例:
算力租赁:公开云报价约 $2.85–3.50/小时(已从 2023 年的 $7–8/小时大幅下降) 芯片电力:满载约 700 瓦,按 $0.12/千瓦时计算,每小时芯片电费约 $0.084(仅为芯片电力,不含整机冷却和数据中心 PUE) 网络与运维:数据中心冷却、带宽、维护
边际推理成本高度依赖模型架构、利用率、批处理大小、上下文长度和量化精度,不是一个固定数字。业内估算,当前主流模型的边际推理成本约占公开标价的 一小部分到中等比例,具体比例因厂商、模型档位和利用率而异。
那标价的大头是什么?
第二层:沉没成本——训练一个模型,要烧多少钱?
训练一个前沿模型,算力成本在 数千万到数亿美元级别。Anthropic CEO Amodei 2024 年表示,正在训练中的下一代模型成本接近 $10 亿。这包括数千张 GPU 数月运算、顶尖团队的人力、数据采集与清洗、无数次失败实验。
DeepSeek V3 技术报告显示训练算力成本约 $558 万美元(约 $600 万四舍五入),但这个数字仅含算力成本,不含人力和前期研发。即便如此,DeepSeek 的训练效率也解释了为什么它能把价格打到地板价。
第三层:战略溢价——品牌、生态与市场博弈
- 品牌溢价
:OpenAI 高端档位定价可以比 DeepSeek 高数百倍,因为市场认可其技术领先性和服务稳定性 - 生态锁定
:Azure OpenAI 的捆绑销售、渠道控制 - 价格战策略
:主动降价甚至阶段性亏本,以抢占市场份额和数据飞轮
这三层叠加,构成了你看到的最终标价。
但这里有一个关键的省略:上述计算都是基于标价层的。如果计入计量层的 Tokenizer 差异、运行层的缓存和延迟——真实成本结构会更加扭曲。
四、从标价到运行:AI 正在变成"云资源调度价格"

定价表上最隐蔽的设计,是 Input/Output 的不对称。
所有厂商的 Output Token 都比 Input 贵,而且差距巨大。Claude Opus 4.7 的 Output 是 Input 的 5 倍,GPT-5.4 标准版是 6 倍。
为什么?因为 Input 是低门槛入口,Output 更接近账单大头。厂商用便宜的 Input 吸引你,但 AI 的长篇回复才是成本主力。这就像打印机的商业模式——低价卖机器,高价卖墨盒。
但这只是第一层不对称。更准确地说,Token 定价正在从"模型价格"变成"AI 云资源调度价格"。
同一个模型,在 Standard、Batch、Priority、Flex 等不同服务层级下,价格、延迟、稳定性并不相同。OpenAI 的 Batch API 可以比标准版便宜 50%,但响应时间更长;Priority 档位更快,但更贵。
厂商卖的不是一粒静态 Token,而是一段带时间优先级、缓存概率、可用性承诺的推理服务。
运行层的迷雾:缓存不是完全黑箱,但不可完全控制
OpenAI 的缓存 Token 可以在 API usage 字段中看到(cached_tokens),价格也通常低于未缓存输入。但用户仍然无法完全预测缓存是否命中、命中多久、不同请求如何被路由。
也就是说,缓存不是完全黑箱,但它是"可观察、不可完全预测、不可完全控制"的账单变量。
Token 计数器的可审计边界
Token 计数由厂商服务器完成,用户只能被动接受。虽然有开源的 tiktoken 库可以自行验证,但不同模型、不同版本的计数规则可能变化。没有第三方独立审计,用户无法 100% 验证。
为什么结算单从不按任务类型拆解
多数厂商的原生账单只显示"总 Input Tokens / 总 Output Tokens / 总费用",默认不按业务任务类型、复杂度或应用场景拆解。用户无法直接回答"我哪类任务最烧钱"——而这正是厂商希望保持的盲区。
五、API 聚合平台:价格离散性的信号
如果你认为官方价格表就是模型厂商的“底价”,API 聚合平台的存在会让你重新思考。
胜算云、DMXAPI、硅基流动,以及海外的 OpenRouter、Together AI、LiteLLM Gateway 等平台,都在做一件相似的事:把多个模型、多个厂商、多个推理资源,封装成一个统一入口。用户不必逐一接入不同厂商,只需要通过一个 API Key、一个网关,或者一个企业内部路由层,就能在不同模型之间切换。
表面上看,聚合平台解决的是接入效率问题;但从价格观察的角度看,它真正有价值的地方在于:它让我们看见了 AI 推理市场的价格离散。
所谓价格离散,就是同一个模型、同一类能力,到了不同渠道、不同客户、不同调用规模、不同服务等级里,会出现不同价格。官网价格是一种价格,企业合同价是一种价格,聚合平台价格是一种价格,批量采购价又是另一种价格。它们未必互相矛盾,而是共同构成了一个多层定价体系。
这对我们判断“价格是否合理”非常重要。
因为如果 Token 价格完全由刚性成本决定,那么同一类服务的价格就不应该出现太大的渠道差异。可一旦聚合平台能够长期存在,并且在部分模型、部分场景下给出接近官方价、低于官方价,甚至更灵活的价格方案,就说明公开标价和实际履约成本之间存在空间。
这个空间未必都是利润。它可能来自大客户批发价、预付费采购、调用量承诺、闲置算力消纳、区域代理政策、低 SLA 通道、缓存复用、智能路由、模型替代,或者不同任务之间的成本交叉补贴。
但无论来源是什么,它都告诉我们一件事:官方价格表不是成本本身,而是厂商定价体系中的零售层。
这就是聚合平台提供的第一个洞察:价格表不是底价,官网价更像零售价。
第二个洞察是:Token 价格不是单点价格,而是区间价格。
同样是“调用一个模型”,你买到的可能并不完全一样。官方直连可能买的是稳定性、品牌信用、最高优先级和更清晰的责任边界;聚合平台可能买的是更低价格、更方便的多模型切换、更灵活的路由,但也可能牺牲部分 SLA、延迟稳定性、透明度或错误追责。于是,便宜不一定代表“厂商暴利”,贵也不一定代表“纯粹智商税”。真正要看的,是价格背后包含了哪些服务承诺。
第三个洞察是:价格差异本身,是判断是否离谱的重要信号。
如果一个模型的官方价格长期显著高于多个渠道的有效价格,而体验、延迟、成功率、上下文、限流和稳定性并没有明显优势,那么这个官方价格就可能存在较高的品牌溢价或定价权溢价。反过来,如果一个低价渠道虽然便宜,但牺牲了稳定性、速度、上下文、失败重试、数据合规或售后支持,那么这个低价也不一定是真正便宜。
所以,聚合平台不能直接告诉我们“真实成本是多少”,但它能提供一种观察价格合理性的坐标系:
看官方价,知道厂商怎么标价;看聚合价,知道市场怎么折价;看企业价,知道规模怎么议价;看 SLA 差异,知道用户到底为哪些服务承诺付费。
这套坐标系一旦建立,我们就不会再把“每百万 Token 多少钱”当成唯一判断标准。我们会开始追问:这个价格包含什么?不包含什么?它是否包含品牌溢价、稳定性溢价、长上下文溢价、优先队列溢价、渠道空间、路由优化、批量折扣,甚至资本补贴?
这也是 API 聚合平台在本文中的真正意义。
它不是为了证明某家厂商“利润很厚”,也不是为了推荐用户去找最便宜的 API。它更像一面价格透视镜:让我们看到 AI 推理市场正在从单一厂商标价,走向多渠道、多 SLA、多路由策略的“算力集市”。
在这个集市里,Token 可以被批发,可以被打包,可以被补贴,可以被路由优化,也可以被重新包装成会员、套餐、额度、优先队列和企业合同。
因此,聚合平台这一维度最终给我们的洞察是:
判断一款模型定价是否离谱,不能只看它报多少钱,而要看同类能力在不同渠道里的价格分布。价格分布越离散,越说明这不是单纯的成本定价,而是渠道、规模、服务承诺和定价权共同作用的结果。
六、价格战与算力金融化:资本的双重游戏
2024–2026 年的大模型价格战,表面是技术竞争,本质也是资本叙事。
价格战时间线
- 2024 年 5 月:字节豆包打到极低单价,比行业均价低 99.3%
- 2025 年 2 月:DeepSeek 以极低价格冲击国际市场
- 2025 年 9 月:英伟达拟向 OpenAI 投资高达 1000 亿美元,共建 10 GW 规模 AI 数据中心(后陷入停滞,但足以折射趋势)
- 2025 年底:H100 云租赁价格从 $7–8/小时降至 $2.85–3.90/小时区间
- 2026 年 3–4 月:DeepSeek V4 Flash 以 $0.14/百万 Token 刷新主流前沿模型价格下限
开发者社区的一种常见观点是:厂商正在亏钱换市场。这与网约车、外卖、共享单车的剧本如出一辙。AI 的特殊之处在于:更多用户 = 更多反馈数据 = 更好模型 = 更强护城河。
GPU 正在出现"类房地产化"的金融特征
但价格战背后,还有一个更深刻的变革正在发生——算力金融化。
这不再是概念,而是已经发生的事实:
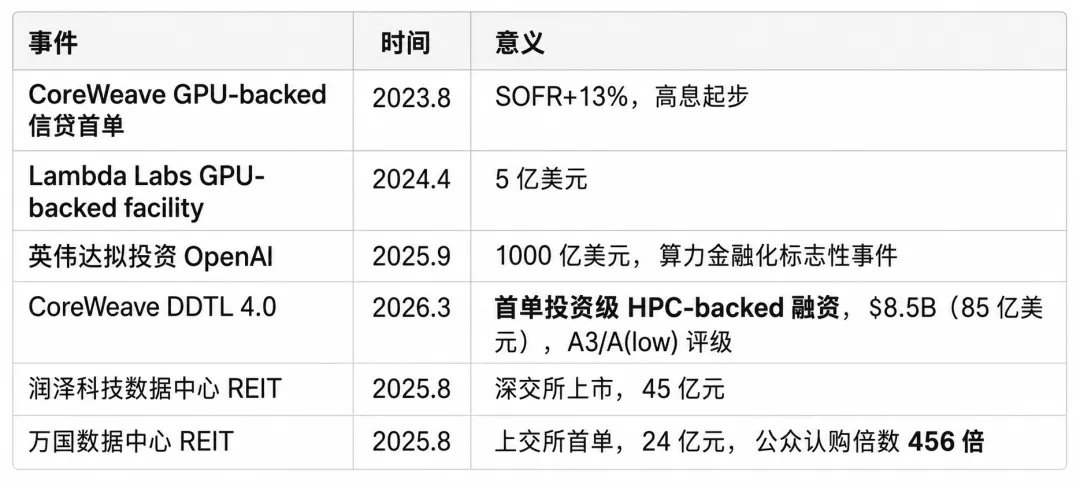
18 个月内,GPU-backed 信贷的利差从约 1300 基点压缩到约 110 基点。 这意味着资本市场对"GPU 作为抵押品"的信心,已经从"实验性资产"跃升为"投资级资产"。
H100 租金经历了戏剧性的下行:从 2023 年的 $8/小时,跌至 2025 年的 $2.85–3.50/小时区间。当前公开报价仍在 $2.35–3.50/小时范围波动。
GPU 正在出现"类房地产化"的金融特征:它不再只是芯片,而是可以产生租赁现金流、绑定长期客户合同、支撑债务融资的数据中心资产。
当算力变成金融资产,Token 定价将由资本市场重新定义。未来 Token 价格的一部分,可能越来越多地反映资本成本——算力债券的利息、数据中心 REITs 的分红、基础设施融资的溢价——而不仅仅是每次推理的电费和折旧。
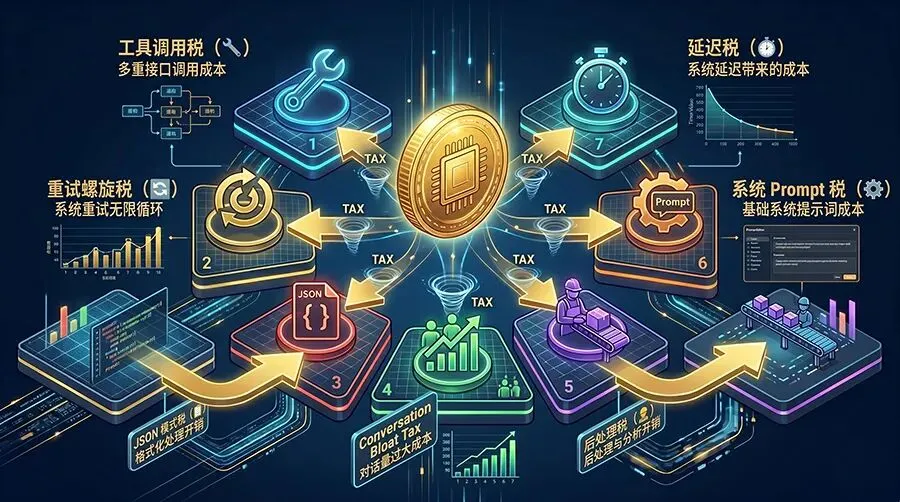
七、隐藏成本清单:账单上看不到的七种"税"
前面的讨论都是基于标价和计费逻辑。但还有一层更隐蔽的成本——隐藏税费。
1. 工具调用税
每次 Function Call 可能额外增加数百到数千 Token 开销,取决于工具定义 Schema 的大小和调用链长度。Claude 的工具定义 Token 化效率显著低于 OpenAI(TensorZero 实测)。一个"查天气"请求,可能触发数千 Token 的工具调用链——这个成本在价格表上完全不可见。
2. 重试螺旋
API 超时后重试 3 次 = 3 倍 Token 消耗。低价模型错误率更高,重试更频繁。一个"单价便宜 50%"的模型,如果需要 3 次重试才能成功,实际成本反而更高。
3. JSON 模式税
结构化输出比纯文本可能显著增加 Token 消耗,具体取决于模型和格式要求。
4. 对话历史膨胀税
在未做摘要/截断时,第 10 轮对话的 Token 数约为第 1 轮的 10–20 倍——每轮都重复发送完整历史。长对话的成本不是线性增长,是指数增长。
5. 后处理劳动力税
低价模型输出质量差,需要更多人工修正。"廉价模型 + 人工修正"的总成本,往往超过"昂贵模型一次性输出"。这个"人力成本"从未出现在 API 账单的任何一行。
6. 系统 Prompt 重复计费
每次调用都重新发送系统 Prompt,这个固定开销在高频场景下不可忽视。
7. 延迟税
在高频交易、实时客服等场景中,响应延迟直接等于商业损失。低价模型在高峰时段延迟增加,可能迫使你回退到更贵的备用模型——低价模型反而成了"昂贵的备份"。
八、真正该比较的公式:同一任务完成一次多少钱
这七种"税"叠加在一起,构成了标价与真实成本之间的巨大鸿沟。所以真正该比较的不是"每百万 Token 多少钱",而是"同一任务完成一次多少钱"。
一个更接近真实账单的思考框架:
单次任务有效成本 = 输入Token数 × 输入单价 × Tokenizer系数 × 缓存折扣系数+ 输出Token数 × 输出单价+ 工具调用/搜索/文件/代码解释器等附加费用+ 重试次数 × 单次任务成本+ 人工后处理时间 × 人力单价+ 延迟造成的业务损失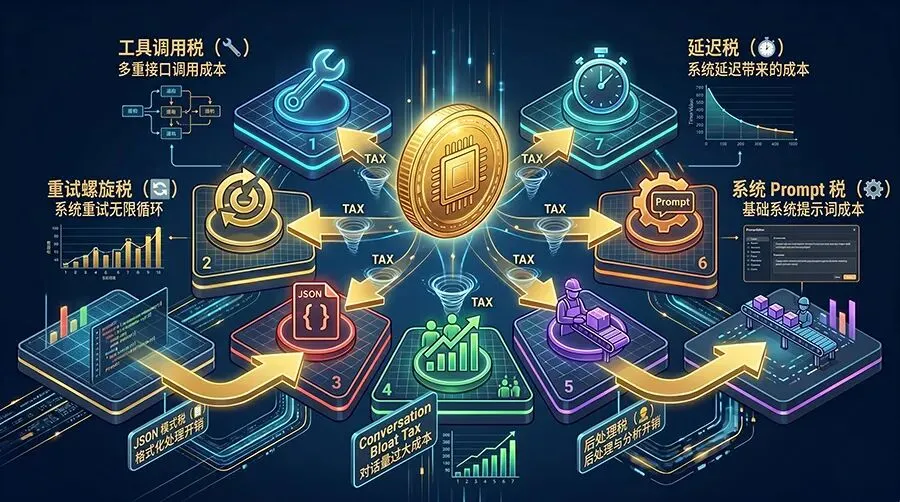
只有把这些变量放进同一个公式,便宜模型和贵模型才有可比性。
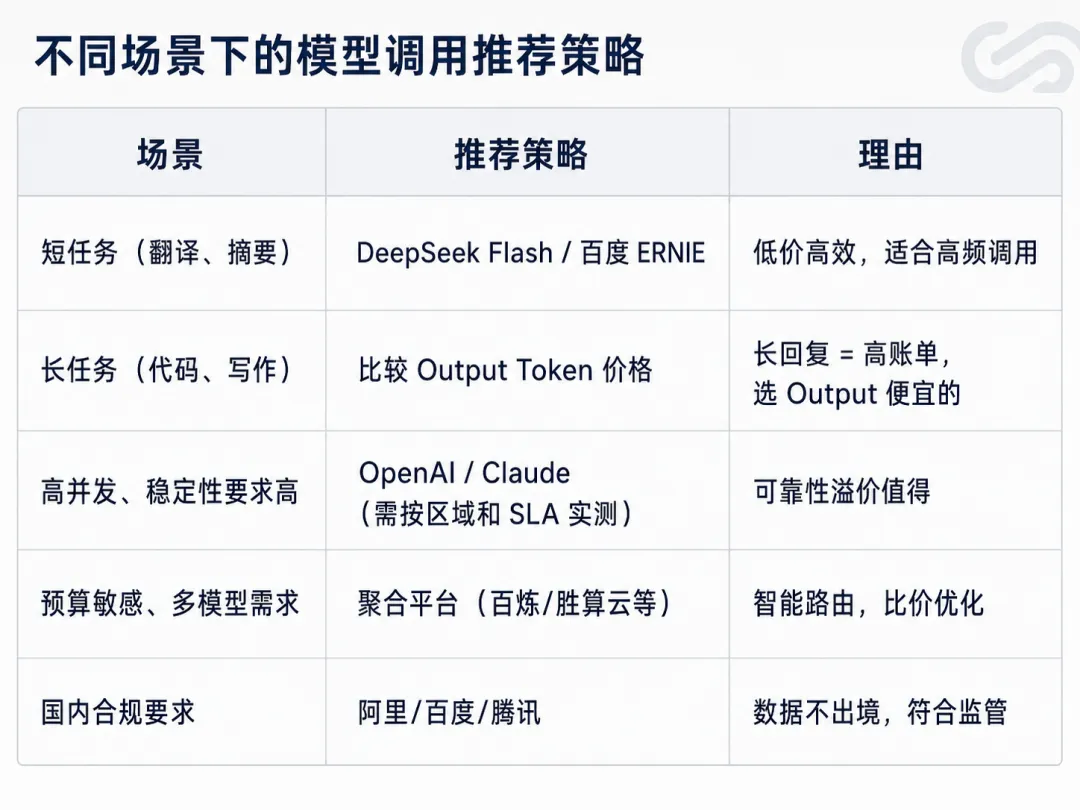
降低账单的实操技巧
- 精简 Prompt:输入越少,Input Token 越省
- 控制输出长度:明确指定回复限制
- 实验验证:用统一输入测试不同厂商的真实 Token 数
- 监控重试率:重试率 >20% 时考虑更换(工程经验阈值)
- 多模型对冲:简单任务用便宜的,复杂任务用贵的
下一个前沿:可审计的 AI 账单
企业客户未来会要求更透明的账单。成熟的 AI 账单应该能拆出任务类型、缓存命中、工具调用、重试次数、延迟分布和质量指标。
谁先把账单做成可审计系统,谁就可能掌握企业级 AI 成本治理的入口。
结语:Token 定价的终局
回到开头的问题:你花的钱,到底买了什么?
答案是:你买的不是单纯"算力",而是一篮子成本和权利——GPU 与电力,模型训练和研发,服务稳定性,缓存与路由系统,生态绑定,品牌信任,以及资本市场对算力资产的定价。不同厂商、不同模型、不同服务层级,这个篮子的比例完全不同。
今天的 Token 定价,标准尚未统一,信息不对称巨大,资本开支空前——但终将走向标准化和可审计化。
标价、计量、运行、资本之间的四重迷雾,短期内不会消散。但对用户来说,好消息是:中国市场的竞争比国际更激烈,"厘计价"在部分场景已成为常态。DeepSeek、豆包、通义千问们正在用技术和资本的双重力量,把 AI 从"奢侈品"变成"日用品"。
在那之前,作为用户,你能做的最聪明的事,就是读懂这粒 Token 的定价密码——在标价里看到叙事,在计量里看到差异,在运行里看到真相,在资本里看到终局。
延伸阅读:如果你想深入了解某家厂商的具体定价策略,推荐使用各厂商官方定价页进行实时比价。优先阅读官方文档、上市公司公告和公开研究报告。
*本文数据截至 2026 年 5 月,定价数据来源于各厂商官方公告及第三方比价平台。核心素材来源:TensorZero Tokenizer 实测(tensorzero.com)、CoreWeave 投资者关系文件、润泽科技/万国数据 REIT 公告、新浪财经/财新/21 经济网、开发者社区讨论。

