AI大白话,把“机器的话”翻译成“人的话”。每篇拆解一个AI的核心名词,让你真正看懂AI。
豆包突然宣布收费了。三档订阅:68元/月、200元/月、500元/月。消息一出,网上直接炸锅。所有这些问题,都指向大模型计费体系里最基础的那个单位——Token。今天这篇文章,帮你搞懂:Token到底是什么?怎么算出来的?为什么不同模型分词差异直接导致计费不同?收费背后的算力和电力成本是什么?以及,怎么让你花的每一分钱都值。一、AI只认识向量,Token是输入输出的最小计量单位
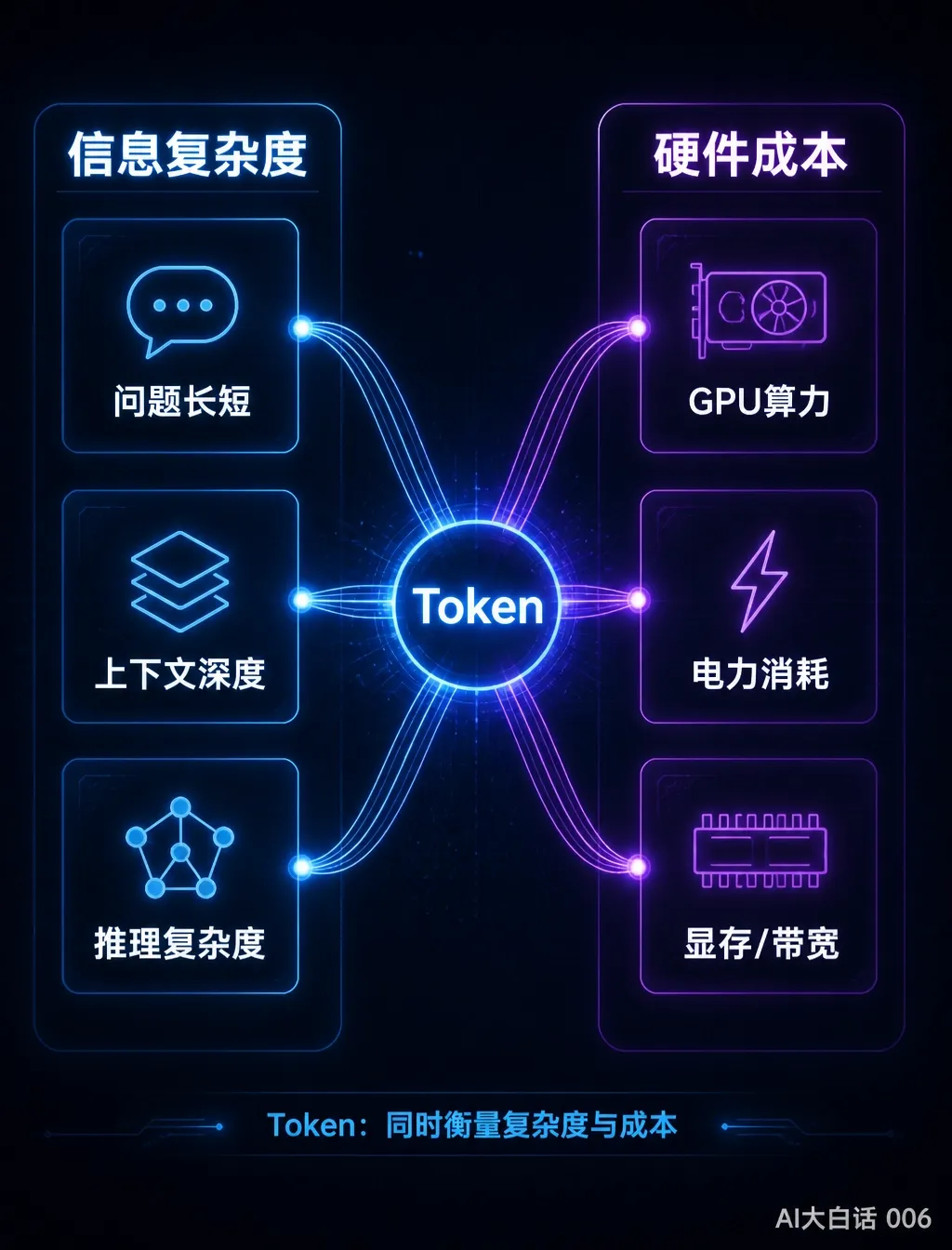
我们之前讲过,AI不认识汉字,只认识向量——一串数字坐标。每个词在AI的语义宇宙里都是一个高维向量,语义越相近,向量越接近。AI不能直接把整个句子翻译成向量。它需要先把句子切成一小块一小块的单元,每个单元去词嵌入矩阵里查表,找到对应的向量。这些单元,就是Token。Token是与大模型交互输入和输出的最小单位,也是大模型与用户沟通的信息长度单位。你说一句话,系统先切成若干个Token,再逐个转成向量去计算。AI算完后,输出新的向量,再反查回Token,最后拼成人话还给你。整个链路:人话 → 切成Token → 转成向量 → 计算 → 输出向量 → 反查Token → 拼成人话。二、Token怎么切出来的?为什么不同模型不一样?
Token不是按字切的,也不是按词切的,是靠一套叫**BPE(字节对编码)**的算法,从海量文本里统计出来的。相邻字符出现频率越高,越容易被合并成一个独立Token。“家人们谁懂啊”——每个字大概率都是独立Token。“这简直是‘神仙’操作!”——“简直”可能是一个Token,“神仙”可能被拆成两个。这里有一个大多数人不知道的关键:每个模型的分词表是独立训练出来的,同一个词在不同模型里,可能被切成不同数量的Token。“简直”在豆包的词表里可能是一个完整Token,在另一个模型里可能被切成两个。“Token”在GPT-4里可能1个Token直接过,在某些中文模型里可能被切成两个。这意味着什么?同一句话在不同模型里的Token消耗量不同,计费也不同。在豆包上问同样的问题,和在Kimi上问,Token数量可能差10%-20%。对日常聊天差异不大,但对每天调用几十万次API的企业,这可能就会是一笔不小的支出。“我今天很开心”:中文4个Token,“I am very happy today”: 英文5-7个Token。句子越长,差距越明显:“请帮我总结这篇文章的核心观点”——中文10来个Token,同样的英文可能15-20个Token。同样的意思,中文花的Token更少,同样的钱更耐花。三、Token的本质:算力消耗的计量单位
因为Token能同时代表两件事:用户与大模型交互的信息复杂度,以及背后消耗的硬件成本单位。一个500字的问题比50字的问题消耗更多Token——对应的GPU计算链路更长、KV Cache占用更多显存、电力消耗更大。Token是最简洁、最公平的计量方式:你消耗多少算力,就付多少Token的费。大模型每处理一个Token,都要经历多层Transformer的完整计算。每个Token消耗GPU算力和内存,而GPU背后是电力——电费是整个AI基础设施最直接、持续的成本。输入Token:每次提问,系统都会把完整历史对话重新“读”一遍。上下文越长,输入Token越多。而且输入Token缓存在GPU的KV Cache里,占用昂贵的高速显存。输出Token:AI生成的每个字都是经过计算,且每输出一个Token,都要把它拼回输入序列、再过一遍完整网络。输出通常比输入更贵,因为它不仅消耗算力,还消耗时间。上下文叠加成本:对话越长,历史累积越重。第一轮100 Token,第二轮重复第一轮+新增100 Token,第三轮重复前两轮+新增——越往后越加速膨胀。每次和AI对话,背后都在发生巨额计算和电力消耗。按Token平摊计费,让高频重度用户自己覆盖成本,轻度用户继续享受免费或低价额度。四、豆包每个月要消耗多少Token?
以公开的数据来评估,豆包日均Token消耗量已突破120万亿,且每三个月翻一番。单月消耗量约3600万亿Token。按目前长上下文模型的实际使用情况,输入:输出约20比1——用户带着几百k历史对话进来,输入量远超输出量。拿DeepSeek V4定价算(输入0.27元/百万Token,输出1.10元/百万Token),假设DeepSeek定价与成本为1比 1:单月总成本:约1.11亿元人民币 (不考虑命中缓存的前提下)这还不包括机房电力、GPU折旧、带宽和运维。Token消耗每三个月翻一番,一年后单月成本可能超过10亿。永远免费,不现实。从免费到收费,本质是用价格杠杆分配算力:重度用户付费覆盖成本,轻度用户继续享受免费或低价额度。说明:Token消耗量数据来自行业公开报告。输入输出比例取20:1(实际可能更高),基于当前长上下文模型的实际使用实况。成本估算基于DeepSeek V4官方API定价,仅供参考,不代表豆包实际运营成本。
五、面对AI服务收费终局,Token应该怎么省?
Token的消耗方式,和你使用AI的深度直接相关。咱们以豆包为例,分三种情况来说。如果你只是每天和豆包聊聊天、让它帮你搜资料、写点简单文案,那么免费版完全够用。豆包的免费基础版会继续保留,满足日常使用需求。:把需求一次描述清楚,避免来回追问。每次追问都要重新“看”一遍前面的对话,Token会被重复计算。:把“你能不能帮我写一篇大概500字左右、关于Token计费的科普文章”压缩成“写500字Token计费科普”,效果一样,Token更少。如果你的使用场景比较复杂——比如用AI做PPT、分析数据、处理大量文档——这时候免费版可能不够用了。豆包目前测试了三档订阅:68元/月(标准版)、200元/月(加强版)、500元/月(专业版)。:每天用几次简单聊天,免费版够了;每天用几十次做深度任务,付费版更划算。:写文案、查资料是轻量任务;做PPT、分析数据、处理几百页文档是重度任务,后者才需要付费版的算力。:付费版通常保障高峰期优先响应,如果你在工作流里重度依赖AI,稳定性和速度本身就有价值。情况三:开发者 & 高级玩家(API、Agent)如果你用API调用大模型、或者用Agent自动执行多步任务,Token消耗逻辑完全不一样。:系统指令每次都会被重发,太长的话积少成多成本巨大。:限制每次输出的最大Token数,避免模型生成过长、无效的高成本推理链。:多次调用中不变的部分(如长System Prompt)可以缓存,避免每次重复计费。Agent每执行一步任务,都要把整个上下文窗口重放一遍,同一个Token可能被重复计算多次,费用成倍叠加。:每步任务只给最关键的信息,别让Agent带着几百字无关背景反复执行全部推理链。:长任务到固定步数后,清除无用的历史上下文再继续,避免一次长链推理重复计费数十次。:简单子任务调用小规格模型,只在关键推理步骤调用高压模型,成本优化嵌入到执行流内。预告:关于Agent应用的详细教学——包括怎么搭建、怎么优化、怎么让Agent在复杂任务中稳定运行——我们会在后续的进阶篇中专文展开。这篇文章先帮你理解Agent场景下Token消耗的核心逻辑,后续会有更深入的实操指南。
所以,当你下次再打开豆包或者其他AI工具,看着收费信息时,已经不再是一头雾水地问“凭什么收钱”,而是知道这一切背后,都是一整套围绕Token建立起来的计费体系。每一个精简输入、每一次清理上下文、每一次精准提问,都在帮你管理Token的消耗量。中文母语者在AI时代的天然优势就在你每次敲键盘的瞬间——同一个意思,中文花的Token更少,同样的钱更耐花。而理解不同模型的Token差异,选择适合你使用场景的平台,也会让你的AI账单更划算。今天我们拆解了Token——大模型计费的底层单位。下一篇#007我们来聊聊训练——大模型到底是怎么“训练”出来的?那些万亿参数,是怎么从随机数字变成能和你对话的智能体的?快速总结:“Token是AI和用户之间沟通的信息长度单位。Token量越大,计算量越大,费用越高。”
“同一句话,在不同模型里的Token消耗量不同,计费也不同。选对模型,本身就是成本控制。”
“中文Token的信息密度更高,同样的意思花的Token更少,同样的钱更耐花。” 夜雨聆风
夜雨聆风