 夜雨聆风
夜雨聆风
点击蓝字 关注我们

近期,Eywa 异构智能体框架应运而生,核心思想是为领域专用基础模型接入一个由语言模型驱动的推理接口,使 LLM 不再只把科学数据转成文本来“硬推理”,而是能够调用时间序列、表格等专用基础模型进行原生计算。文章进一步构建 EywaAgent、EywaMAS 和 EywaOrchestra 三种形态,并在覆盖物理、生命和社会科学的 EywaBench上验证其效果,结果显示 Eywa 能在提升任务效用的同时减少 token 消耗和运行时间。


研究背景:
当前智能体系统主要依赖自然语言作为统一接口,但科学问题常涉及时间序列、表格、符号、蛋白质、材料结构等非语言数据。把这些数据强行文本化,容易造成信息损失,也增加 token 和推理成本。与此同时,各科学领域已经发展出大量专用基础模型,但它们通常没有自然语言接口,难以直接参与 LLM 智能体协作。本文正是为了解决“语言智能体如何调用并协调异构科学基础模型”这一问题。

本文亮点:
1. 提出 Eywa 异构科学智能体框架,突破语言中心化瓶颈。 作者指出,很多科学任务的关键输入并不是自然语言,而是结构化或领域特定数据。Eywa 通过为领域基础模型接入 LLM 推理接口,让专用模型以更接近原生数据模态的方式参与任务求解。
2. 构建 EywaAgent、EywaMAS 和 EywaOrchestra 三级协作形态。 EywaAgent 让单个 LLM 与一个领域基础模型形成“推理—专用计算”耦合单元;EywaMAS 将这种单元插入多智能体系统;EywaOrchestra 则通过规划器动态选择模型、角色和拓扑结构,实现任务自适应编排。
3. 在 EywaBench 上验证跨学科有效性和效率优势。 作者构建覆盖物理科学、生命科学和社会科学的多任务基准。实验显示,EywaAgent、EywaMAS 和 EywaOrchestra 在多个子领域中相比语言-only 基线具有更好的效用—成本权衡,尤其体现为更高 utility、更低 token 消耗和更短运行时间。

图文导读:
01
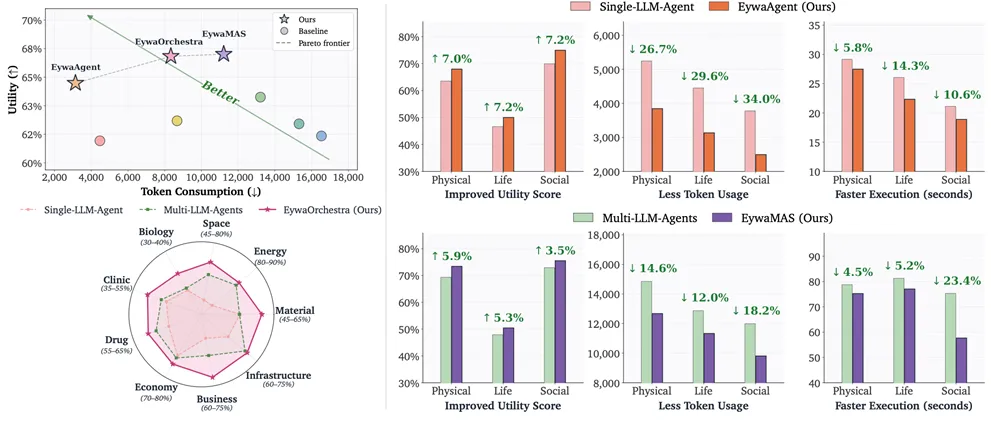
图1:Eywa扩展现有智能体系统并改善效用—成本权衡。 图1展示了 Eywa 与语言-only 基线在整体效用、token 消耗和运行时间上的比较。左侧散点图显示,EywaAgent、EywaMAS 和 EywaOrchestra 更靠近或位于 Pareto frontier,即在更少 token 消耗下获得更高 utility。右侧分领域结果进一步显示,Eywa 在物理、生命和社会科学任务中普遍带来 utility 提升、token 使用减少和执行时间下降。
图片解析:这张图是全文的结果入口。它想说明的不是 Eywa 单纯“多接了一个工具”,而是异构模型协作改变了科学智能体的成本结构。传统 LLM 智能体需要把结构化科学数据转成语言再推理,既费 token,也容易损失模态信息;Eywa 把专用计算交给领域基础模型,因此能在提升任务表现的同时减少语言推理负担。
02
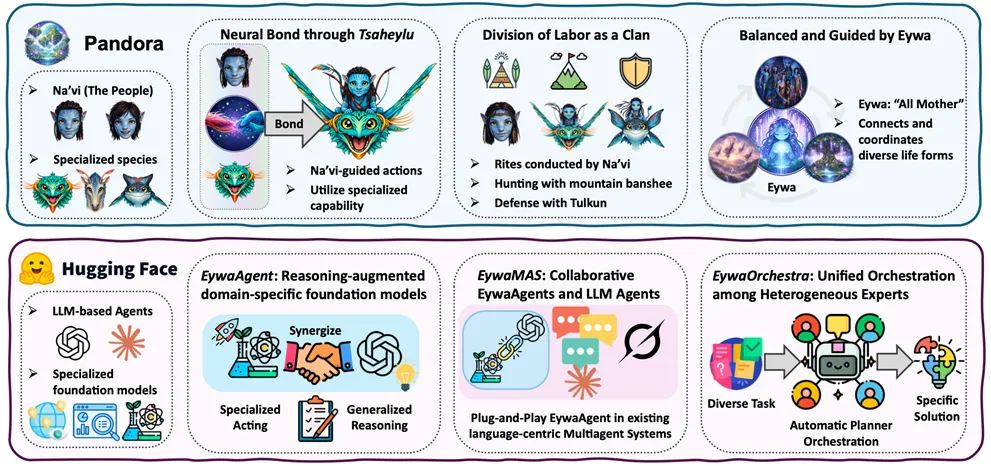
图2:从 Avatar 的 Pandora 生态类比 Eywa 的三阶段框架。图2用电影 Avatar 中 Pandora 生态作类比:Na’vi 通过 Tsaheylu 与具有特殊能力的物种建立连接,并在 Eywa 的整体协调下形成分工协作。对应到 AI 系统中,LLM 类似具备通用推理能力的协调者,领域基础模型类似具备专门能力的物种。文章据此提出三阶段框架:EywaAgent、EywaMAS 和 EywaOrchestra。
图片解析:这一图主要帮助理解文章的核心思想。Eywa 不是让所有模型都变成聊天机器人,而是建立一种“可沟通接口”。LLM 负责理解任务、规划步骤和整合结果,领域基础模型负责处理自己擅长的非语言数据。这个分工让科学智能体从“全部靠语言推理”转向“通用推理 + 专用模型原生计算”。
03
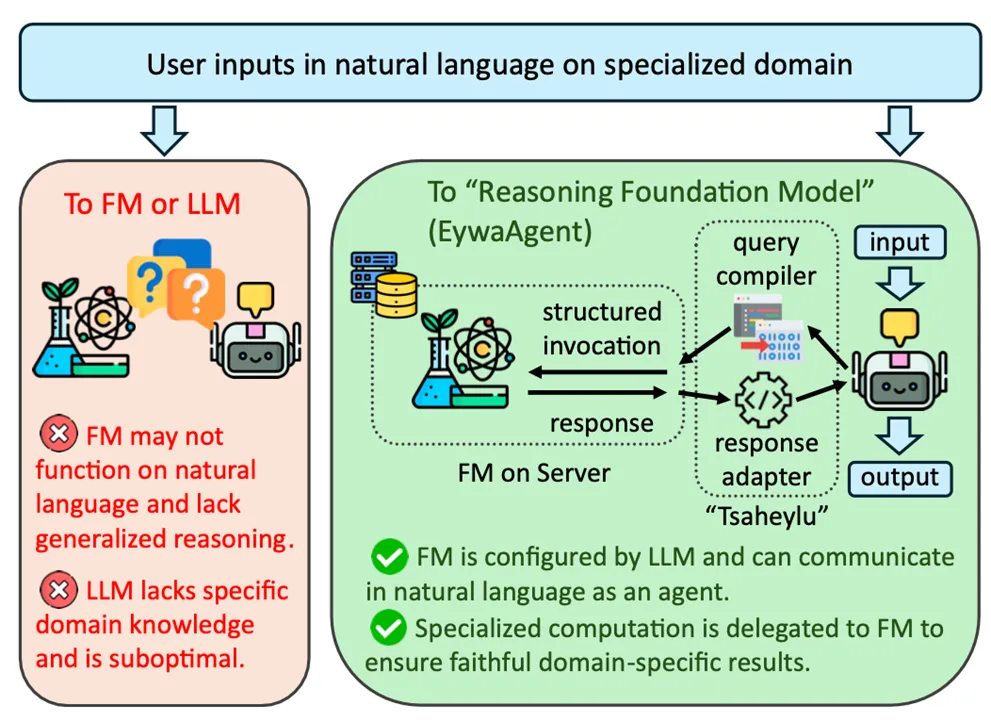
图3:EywaAgent通过FM-LLM “Tsaheylu” 接口连接通用推理与专用计算。图3展示了 EywaAgent 的基础单元。用户以自然语言提出领域任务后,LLM 不再直接对所有数据进行文本化推理,而是通过 query compiler 将任务状态转换成领域基础模型可执行的结构化调用;领域基础模型完成预测或计算后,再由 response adapter 把结果转成规划器可消费的表示,重新进入 LLM 的推理与综合过程。
图片解析:这张图是理解 EywaAgent 的关键。它回答了“LLM 和不会说话的领域模型怎么协作”的问题:中间需要一个双向接口。query compiler 负责把自然语言任务翻译成模型参数,response adapter 负责把模型输出翻译回推理上下文。这样,LLM 不必伪装成时序模型或表格模型,而是把专业任务交给真正擅长该模态的基础模型。
04
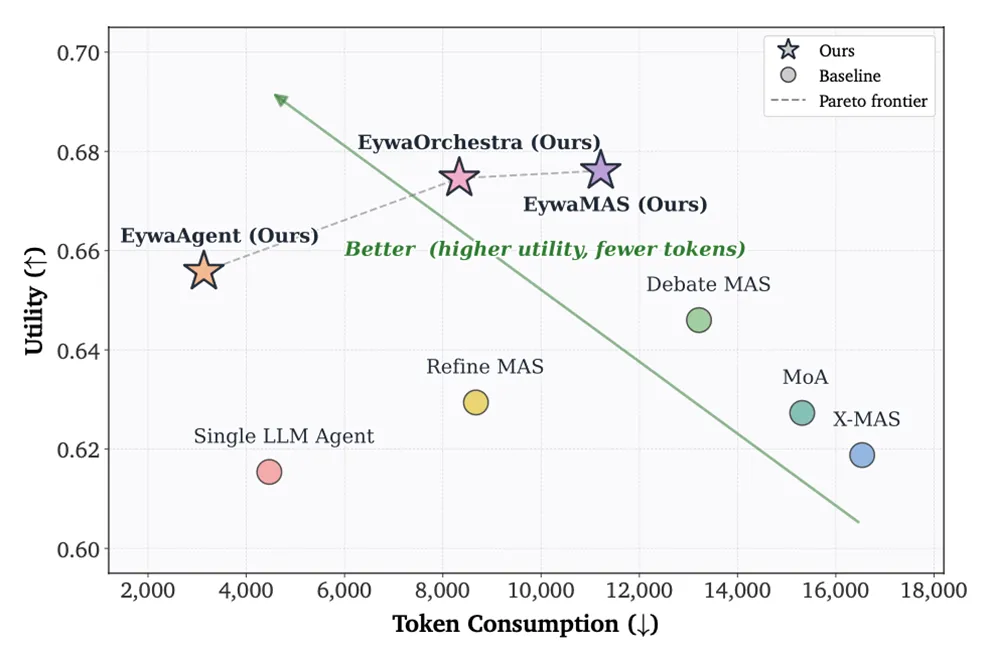
图4:不同方法的效用—token 消耗权衡。图4展示了不同智能体方法在整体 utility 和 token consumption 之间的关系。横轴为 token 消耗,纵轴为任务效用,图中同时标出了 Pareto frontier。结果显示,Eywa 系列方法整体更靠近效用—成本最优区域,说明其并不是单纯依赖更多语言模型推理来提升表现,而是在减少 token 使用的同时获得更高 utility。
图片解析:这张图进一步验证了 Eywa 的核心优势:科学任务中,提升智能体表现不一定要靠“更多 LLM 反复讨论”,而是要让合适的领域基础模型参与原生计算。传统语言-only 智能体需要把时间序列、表格等结构化数据转成语言再推理,因此容易增加 token 成本,也可能损失模态信息。Eywa 则通过 EywaAgent、EywaMAS 或 EywaOrchestra,把专用预测任务交给领域基础模型,再由 LLM 负责规划和整合结果,所以能在更低 token 消耗下取得更好的效用—成本平衡。
05
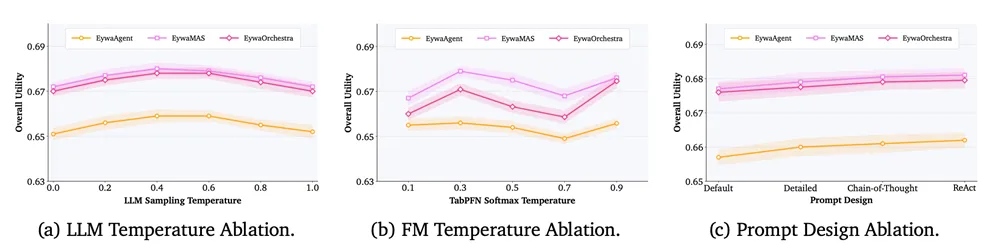
图5:Eywa对温度参数和提示词设计具有较好鲁棒性。图5展示了 EywaAgent、EywaMAS 和 EywaOrchestra 在不同 LLM sampling temperature、TabPFN softmax temperature 和提示词设计下的表现。结果显示,Eywa 在较宽参数范围内保持稳定,结构化提示词通常带来略高 utility,但整体收益并不依赖某一个特定 prompt 或超参数组合。
图片解析:这张图回应了一个很现实的问题:Eywa 的提升会不会只是 prompt 调得好?结果显示,Eywa 在不同温度和提示策略下都比较稳定,说明它的优势主要来自“异构模型协作机制”本身,而不是某个提示词技巧。对于后续做科学智能体平台的人来说,这意味着 Eywa 思路有一定可迁移性。
总结与展望
这篇文章最大的创新点,是提出了一个让 LLM 与领域基础模型协同工作的异构智能体框架。Eywa 不再把语言作为科学任务的唯一接口,而是让 LLM 负责理解任务、规划流程和整合结果,让时间序列、表格等领域模型负责更擅长的专用计算。
从应用角度看,Eywa 为科学自动化和跨模态科研助手提供了新的思路。未来如果接入蛋白结构、单细胞、药物设计、医学影像等更多生命科学模型,有望进一步拓展到真实科研流程中。不过,本文目前仍是预印本,实验场景也主要集中在结构化数据任务,后续仍需要在真实科研场景和多模态任务中继续验证。
原文链接:
https://arxiv.org/abs/2604.27351




公众号丨虚拟囊泡
欢迎关注

点赞
收藏
分享
