 夜雨聆风
夜雨聆风

你猜全球那些科技巨头,每年砸进AI算力的钱,超过70%最后进了谁兜里?就那么几家芯片公司。
大家都在追大模型、追应用,觉得那才是风口。但真正闷声发大财的,根本不是你以为的那些人。今天我就把这条产业链上躺着数钱的玩家,给你一个一个扒出来。
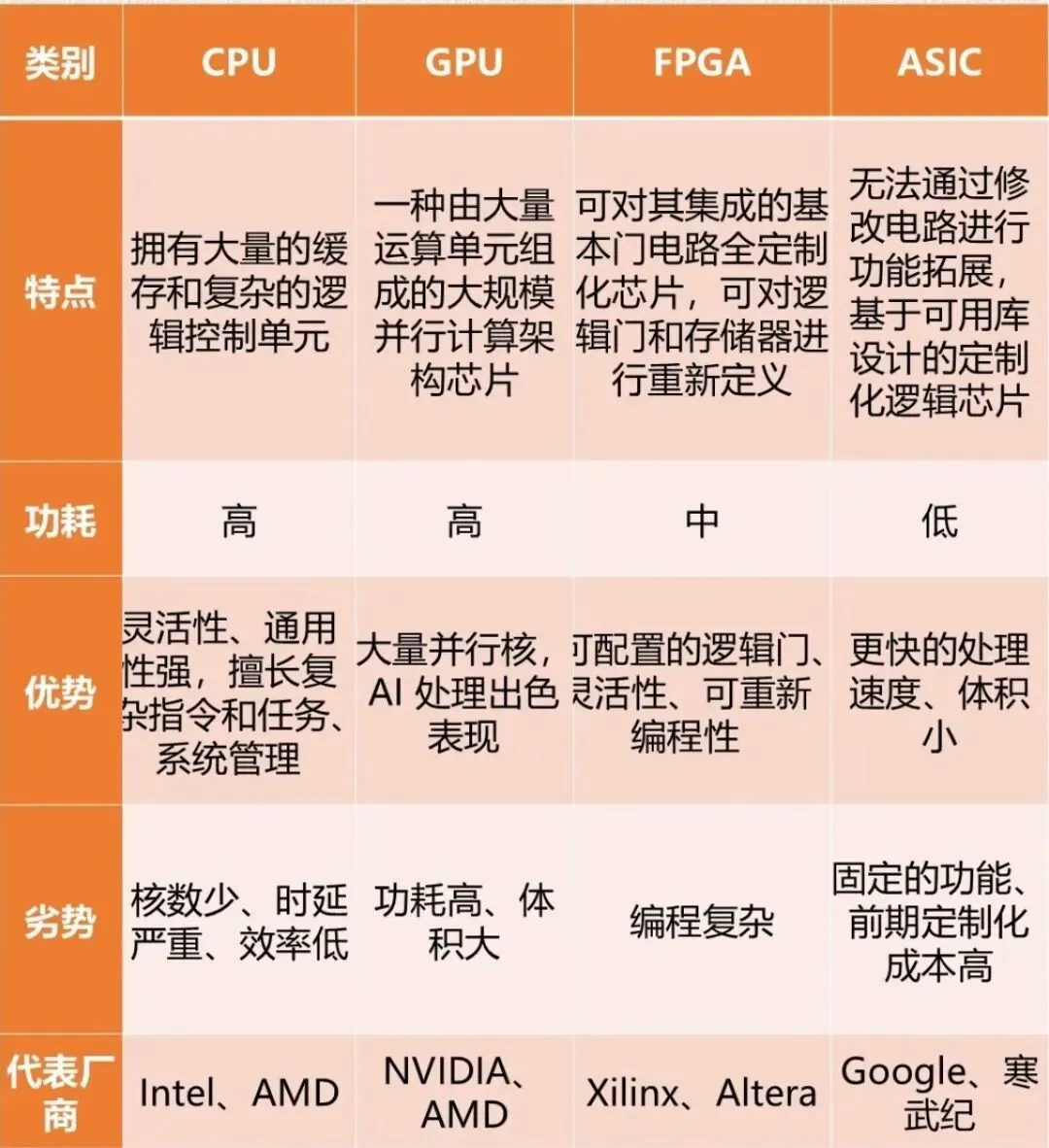
我喜欢把AI算力系统比作一座高速运转的工厂。最核心的算力芯片GPU,是工厂里干粗活的工人,专门扛起大模型海量数据的计算。
但工人算得再快,旁边没人递材料也白搭。这个递材料的角色,叫高带宽存储HBM,它直接贴在GPU旁边,专职喂数据,速度极快。
CPU是做统筹的包工头,负责调度整个流程。再加上负责数据预处理的系统内存,和存放海量训练数据的固态硬盘,这五个角色加在一起,就是整套AI算力系统的完整骨架。
说完结构,咱们聊最核心的战场,算力芯片。
训练市场,英伟达一家独大,占比超过90%。
为什么别人追不上?三个字,生态锁。
英伟达的CUDA软件体系,就是AI领域的Windows系统。
十几年积累下来,全行业最成熟的算法和工具全在里面。你要换别家芯片?代码几乎得重写,遇到报错可能几个月都排查不出来。
对于烧钱如流水的大模型团队,这种时间成本根本承受不起。再加上英伟达保持一年一代的迭代速度,你刚追上上一代,它的下一代已经开始交货了。

黄仁勋的逻辑就一句话,只要我跑得够快,你就只能永远追在后面。
但天下苦英伟达久矣。谷歌、亚马逊、微软这些云巨头,绝不甘心永远给黄仁勋打工。
他们的反击路线很清晰,一边扶持AMD,一边自己下场造定制芯片ASIC。ASIC的逻辑很简单,GPU是通用芯片,里面保留了大量为游戏渲染设计的电路,纯属浪费。
自研ASIC直接把这些全砍掉,把每一个晶体管都用来伺候大模型的矩阵计算。结果就是,同等算力下,ASIC的成本和功耗只有GPU的一半。
英伟达当然不是吃素的。直接砸200亿美元,把推理市场最火的独角兽公司收入囊中,顺手封死了其他创业公司弯道超车的路。
又战略投资了帮云大厂造芯片的幕后推手,推出新的网络架构,潜台词是,你们爱造自己的芯片没关系,但只要把芯片连成集群,这笔网络过路费你照样得交给我。
这场博弈的结果,反而把ASIC推理市场越炸越大,预计到2028年市占率从现在的10%飙升到40%。
然后是被严重低估的CPU。
过去两年,大家眼里只有GPU,CPU像个可有可无的配角。
但AI Agent时代一来,问题就变了。Agent不只是聊天,它要多步骤决策、调用工具、发邮件、订机票,这些复杂的任务调度,恰恰是CPU的老本行。
英伟达已经推出了自研CPU,直接把英特尔和AMD从最赚钱的高端AI服务器里踢了出去。云大厂也纷纷基于ARM架构自研CPU。
更有意思的是ARM公司本身,从卖图纸升级到亲自下场造芯片,直接向大客户供货。X86的蛋糕,正在被三路人马悄悄蚕食,而大多数人还没意识到。
最后说存储,这是整个系统里最卡脖子的命门。
高带宽存储HBM,全球只有三家公司能造,SK海力士占57%,三星22%,美光21%。
为什么只有三家?因为HBM的制造工艺极其苛刻,必须靠几十年经验慢慢摸索,而且必须自建工厂,没有百亿美元级的资本投入,连上桌的资格都没有。
国内方面,长鑫存储是目前唯一有希望量产HBM的企业,样品已经完成,2026年冲量产,带着全村的希望在追赶。
企业级固态硬盘这块,国产替代反而跑得最快,国内市占率已经做到了20%到25%。
但这个领域水很深,很多公司业绩暴涨,不过是趁着涨价周期吃了一波库存差价,本质上是投机不是技术。
判断真假选手就看两条,第一,有没有自研主控芯片的能力;第二,产品有没有真正进入一线云厂的核心服务器。两条都过了才算真本事,否则大概率只是周期红利的过客。
从算力芯片到存储,从CPU到封装,每一个环节都是全球顶尖大脑在纳米级别的博弈。
而真正稳坐钓鱼台的,是那些向全行业默默收税的底层玩家,台积电负责把所有芯片从图纸变成实物,EDA软件商和芯片IP授权方提供设计工具和架构图纸。无论上面打得多热闹,这些人永远在赢。
看懂了这张博弈地图,你才能真正看透AI产业的钱到底流向哪里。
记得点好关注,yiyi带你穿透科技的迷雾。

市面上讲半导体的人很多,但大多数是观察者在转述。
我做过芯片设计公司的联合创始人,做过投资机构的产业研究,也做过面向百万用户的科技自媒体传播。这条路走下来,我越来越清楚一件事,真正准确有效的半导体产业认知,只能来自身在其中的人。
半导体是AI时代真正的底层战场,算力竞赛、国产替代、先进制程、供应链重构,每一场博弈的背后,都有你看不见的产业逻辑在运转。
这些你每天都在看的词,背后真实的逻辑是什么?我想把我在决策层和投研端看到的那些,系统地讲给你听。


