 夜雨聆风
夜雨聆风我用 10 张图,把 AI 产业链从芯片,存储,服务器到数据中心完整拆了一遍.
很多人每天都在用 AI,但并不知道背后到底是什么在支撑它:
GPU 负责算力,
HBM 负责给 GPU 喂数据,
CPU 负责调度整台机器,
高速互联 负责让多张 GPU 协同,
先进封装 负责把 GPU 和 HBM 接成一个系统,
AI 服务器 负责把这些硬件组织起来,
数据中心 负责供电,散热和网络,
训练和推理 则决定 AI 怎么被造出来,怎么被真正用起来.
AI 看起来是模型和应用的竞争,但底层其实是一整套工业系统.下面就用 10 张图,一层一层拆开看.
1. GPU: AI 算力到底从哪里来
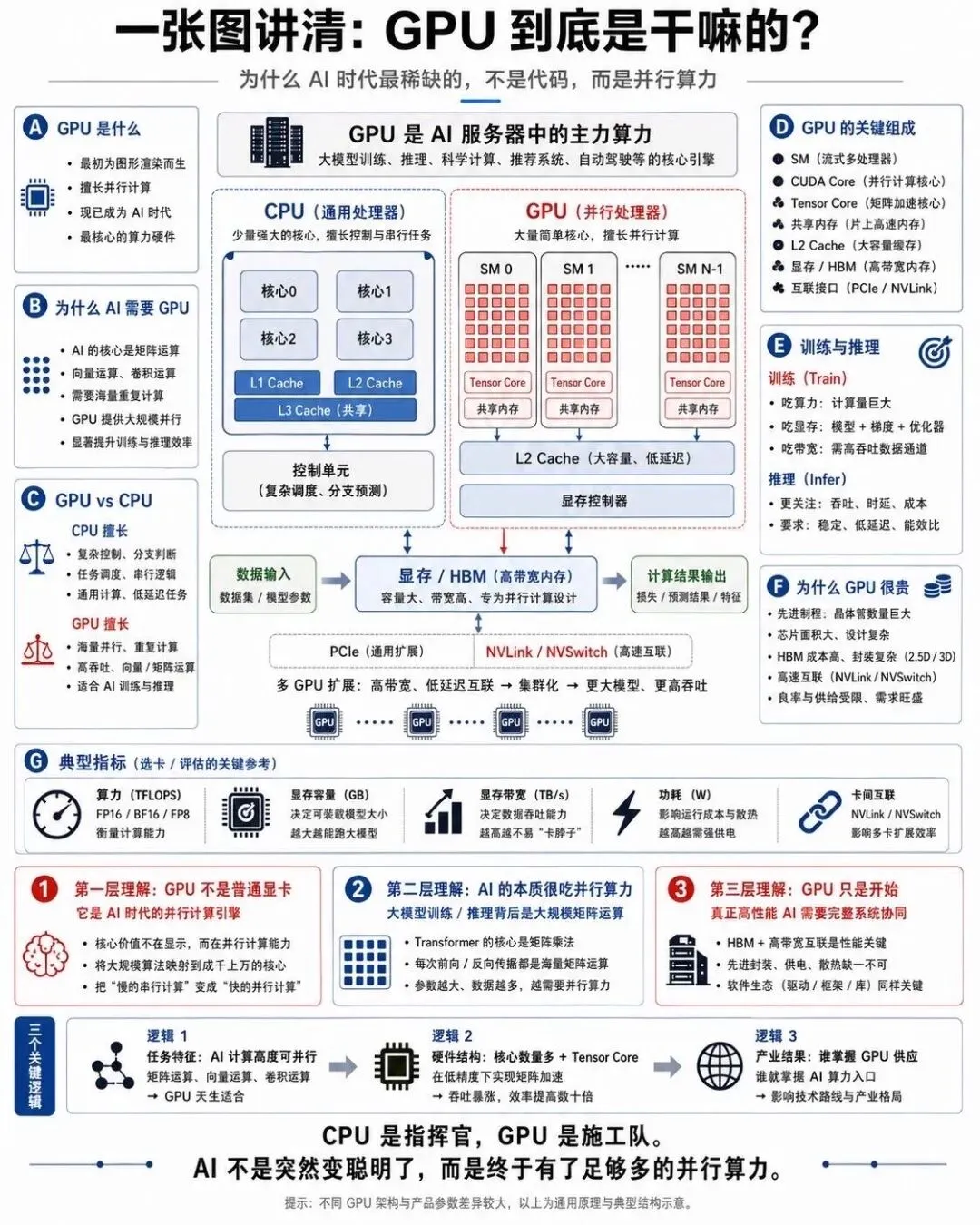 AI 所有的工作,最终都要落到计算上.而今天,几乎所有的模型训练和大规模推理,都跑在 GPU 上.
AI 所有的工作,最终都要落到计算上.而今天,几乎所有的模型训练和大规模推理,都跑在 GPU 上.
和 CPU 不同,GPU 设计之初就是为了大规模并行计算.一个现代 GPU 拥有上万个计算核心,可以同时处理海量的矩阵乘法与向量运算,这正是神经网络所需要的.无论是 Transformer 里的自注意力,还是卷积运算,本质上都是高度并行的张量计算.
在这张图里,你可以看到 GPU 的核心结构: 大量的流式多处理器,高带宽显存接口,专用的 Tensor Core.这些 Tensor Core 是 AI 加速的关键,它们在一个时钟周期内就能完成多次矩阵乘加运算,把 AI 训练的浮点运算效率直接拉高了数倍.
可以说,没有 GPU 架构的持续演进,大模型时代的到来至少要推迟很多年.
2. HBM: 为什么内存的关键不是容量,而是带宽
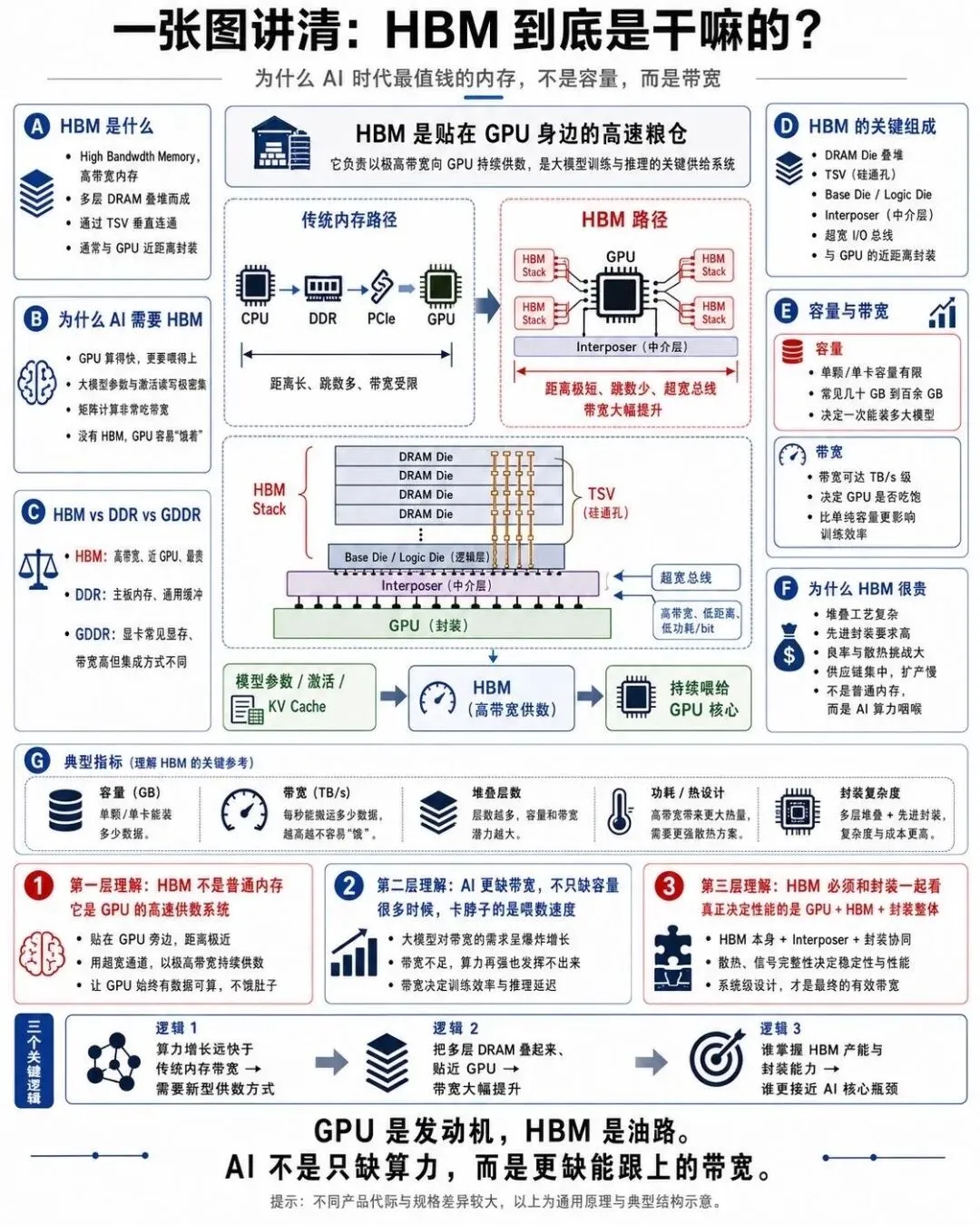 很多人以为 AI 的内存瓶颈是'容量不够',但其实真正的瓶颈是带宽.
很多人以为 AI 的内存瓶颈是'容量不够',但其实真正的瓶颈是带宽.
GPU 的计算速度太快了,如果数据来不及从内存搬运到计算核心,再多的计算单元也只能空转.于是,HBM(高带宽内存)成为 AI 芯片的标配.
这张图展示的是 HBM 的堆叠结构: 多层 DRAM 芯片通过硅通孔垂直互联,再通过一个中间层紧挨着 GPU 核心封装在一起.相比传统的 GDDR 显存,HBM 的总线宽度可以达到 1024 位甚至更高,带宽动辄每 TB/s 级别,而功耗和物理尺寸反而更小.
正是这种'近水楼台'的设计,让 GPU 可以源源不断地拿到数据,而不被'饿着'.可以说,GPU 决定 AI 的算力上限,HBM 决定这算力能不能被真正用出来.
3. DRAM / SSD / HDD: AI 数据是怎么分层存储的
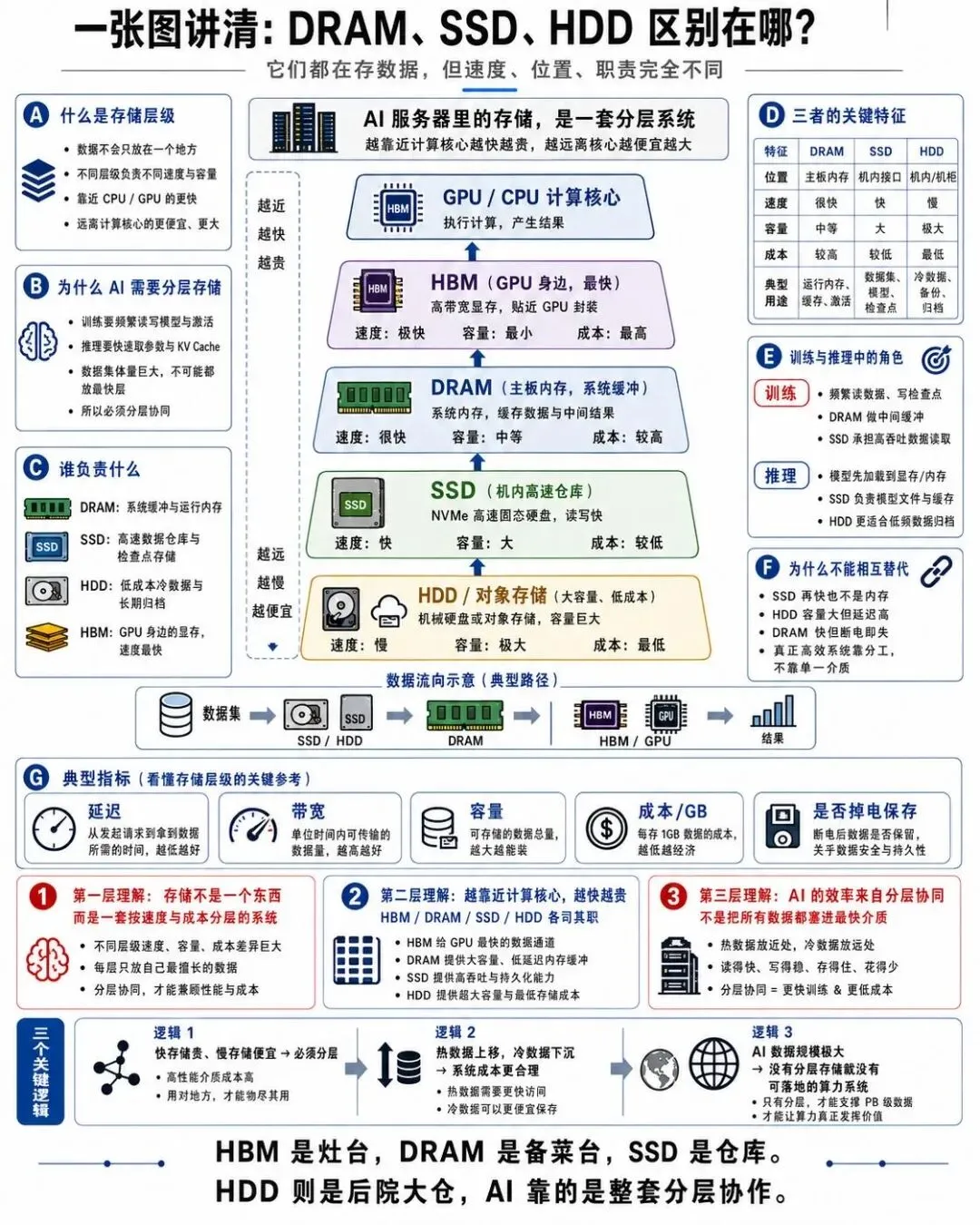 在 AI 训练和推理的整个流程里,数据是分层存放的,不同层级对应不同的速度和成本.
在 AI 训练和推理的整个流程里,数据是分层存放的,不同层级对应不同的速度和成本.
这张图展示了从快到慢,从贵到便宜的存储金字塔:
HBM: 紧贴 GPU,带宽最高,但容量最小,成本最高,存放正在计算的数据.
系统 DRAM: CPU 侧的内存,容量更大,用来暂存模型参数,批数据,中间结果.
NVMe SSD: 高性能固态硬盘,用来高速读取训练数据,要求极低的读写延迟.
HDD / 大容量闪存: 冷数据存储,海量训练数据集的最终归宿.
AI 训练过程中,数据会从 HDD 读到 SSD,再加载到 DRAM,最后被搬运到 HBM 送到 GPU 计算.每一层存储的带宽和延迟都影响整体效率,任何一层出现瓶颈,都会拖慢整个训练集群.
4. CPU: GPU 干重活,CPU 负责调度整台机器 很多人误以为 AI 服务器里 CPU 是配角,但其实没有它,GPU 根本跑不起来.
很多人误以为 AI 服务器里 CPU 是配角,但其实没有它,GPU 根本跑不起来.
在这张图里,CPU 在 AI 系统中的角色非常清晰: 它负责操作系统的运行,数据预处理,任务调度,参数分发,梯度同步控制,以及和外部存储,网络的交互.训练一个 GPT 类模型时,CPU 要不断从 SSD 读取数据,做好 token 化和批处理,再把处理好的数据送到 GPU;多 GPU 之间梯度汇总后的 All-Reduce 同步,也要靠 CPU 参与协调.
此外,随着模型规模越来越大,CPU 和 GPU 之间的 PCIe 带宽,内存带宽都在持续升级,否则数据在这最后一公里还是会卡住.CPU 的性能和通道数,直接决定了单台机器能带多少张 GPU.
5. 高速互联: 多张 GPU 为什么必须高速通信
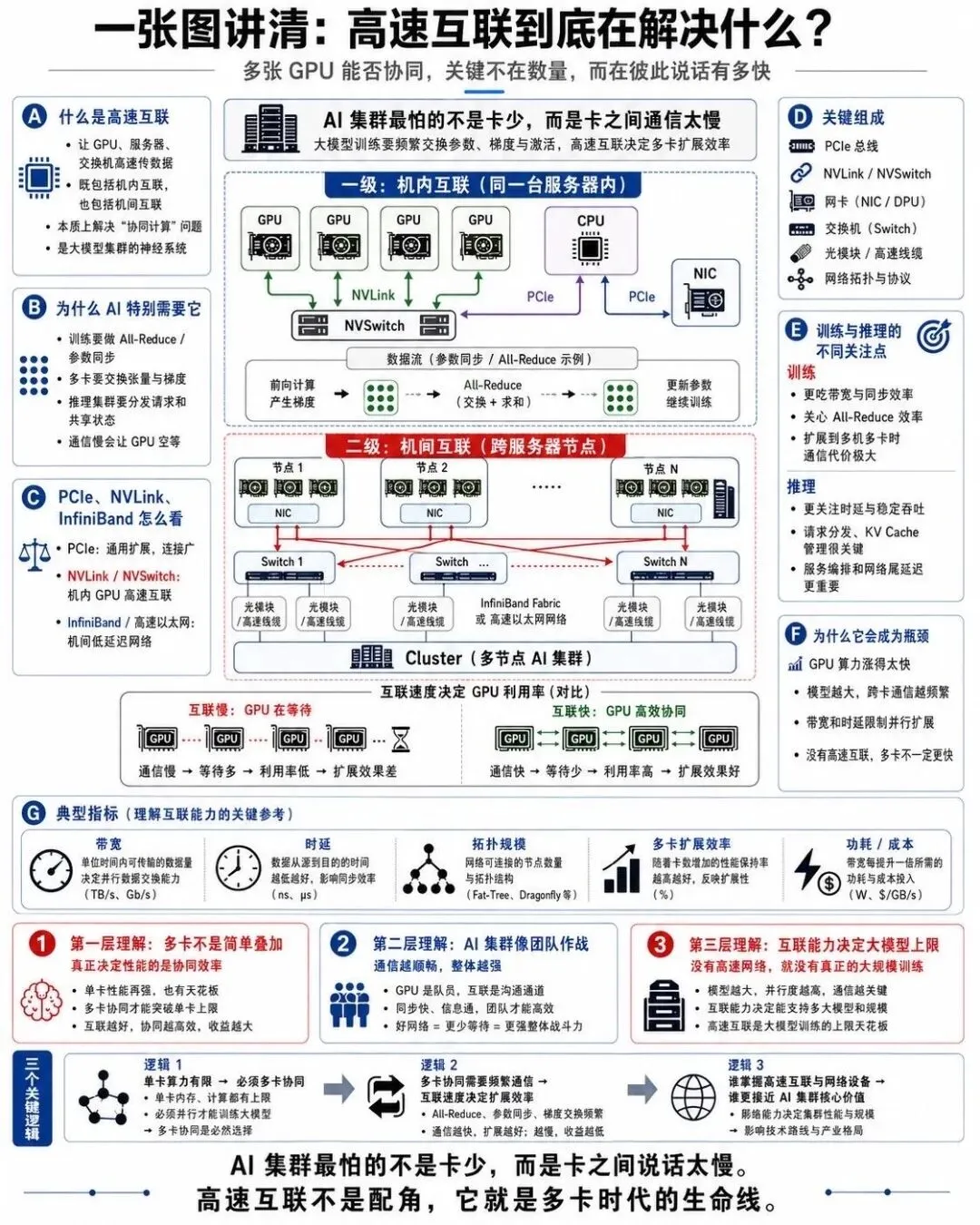 今天的大模型,单靠一张 GPU 已经装不下了,必须用到分布式训练.多张 GPU 之间要频繁地交换梯度,参数和中间结果,如果互联通道慢,计算卡就会互相等待,效率急剧下降.
今天的大模型,单靠一张 GPU 已经装不下了,必须用到分布式训练.多张 GPU 之间要频繁地交换梯度,参数和中间结果,如果互联通道慢,计算卡就会互相等待,效率急剧下降.
这张图展示的,就是 AI 系统里几种关键的高速互联技术:
NVLink / NVSwitch: GPU 之间的直连通道,带宽远高于 PCIe,能实现多 GPU 全互联.
InfiniBand / 以太网 RDMA: 跨节点的 GPU 通信网络,负责把几百甚至几千张 GPU 连成一个整体.
PCIe 交换架构: 连接 CPU,GPU,网卡,存储等设备.
可以这样理解: 单机内部靠 NVLink 把 GPU 紧紧'粘'在一起,跨机靠 InfiniBand 构建一个超大带宽,超低延迟的算力网络.网络就是分布式训练的中枢神经.
6. 先进封装: 为什么 GPU 和 HBM 需要被封装成一个系统
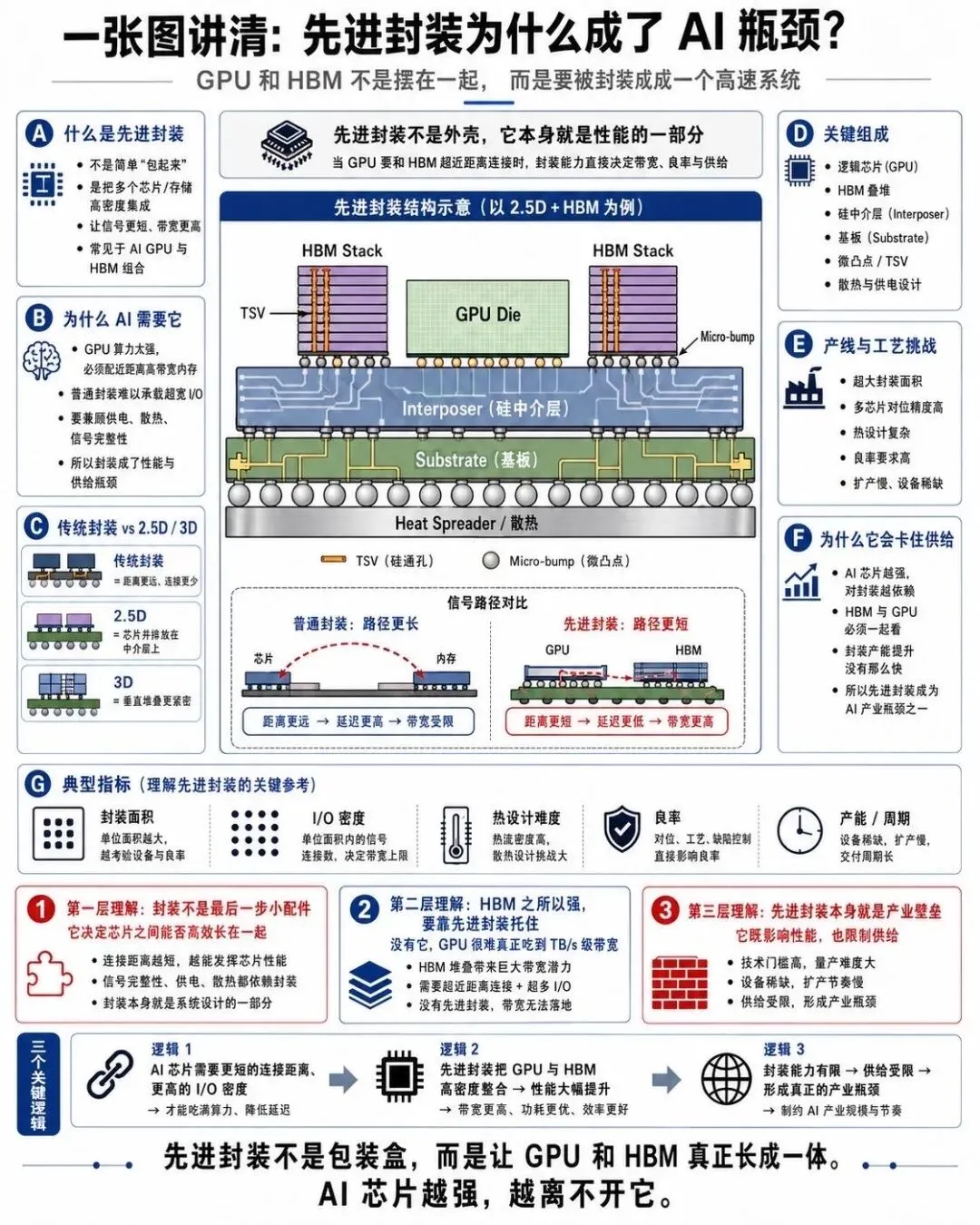 AI 芯片越来越不是单颗芯片,而是一个'系统'.
AI 芯片越来越不是单颗芯片,而是一个'系统'.
这张图展示的,是先进封装如何把 GPU 核心裸片和 HBM 堆栈集成在一块硅中介层上,再整体封装成一个芯片.Chiplet 技术让不同工艺,不同功能的芯片可以像搭积木一样组合,既突破了单芯片的面积限制和良率瓶颈,又大幅缩短了 GPU 与内存之间的物理距离.
更近的距离意味着更高的信号完整性,更低的延迟和功耗.在 AI 芯片里,从 GPU 到 HBM 的每一毫米走线都被精心设计,因为哪怕是几毫米的差距,都会影响整个系统的频率和带宽.可以说,先进封装决定了 AI 芯片的物理上限.
7. AI 服务器: 一台 AI 服务器里到底装了什么
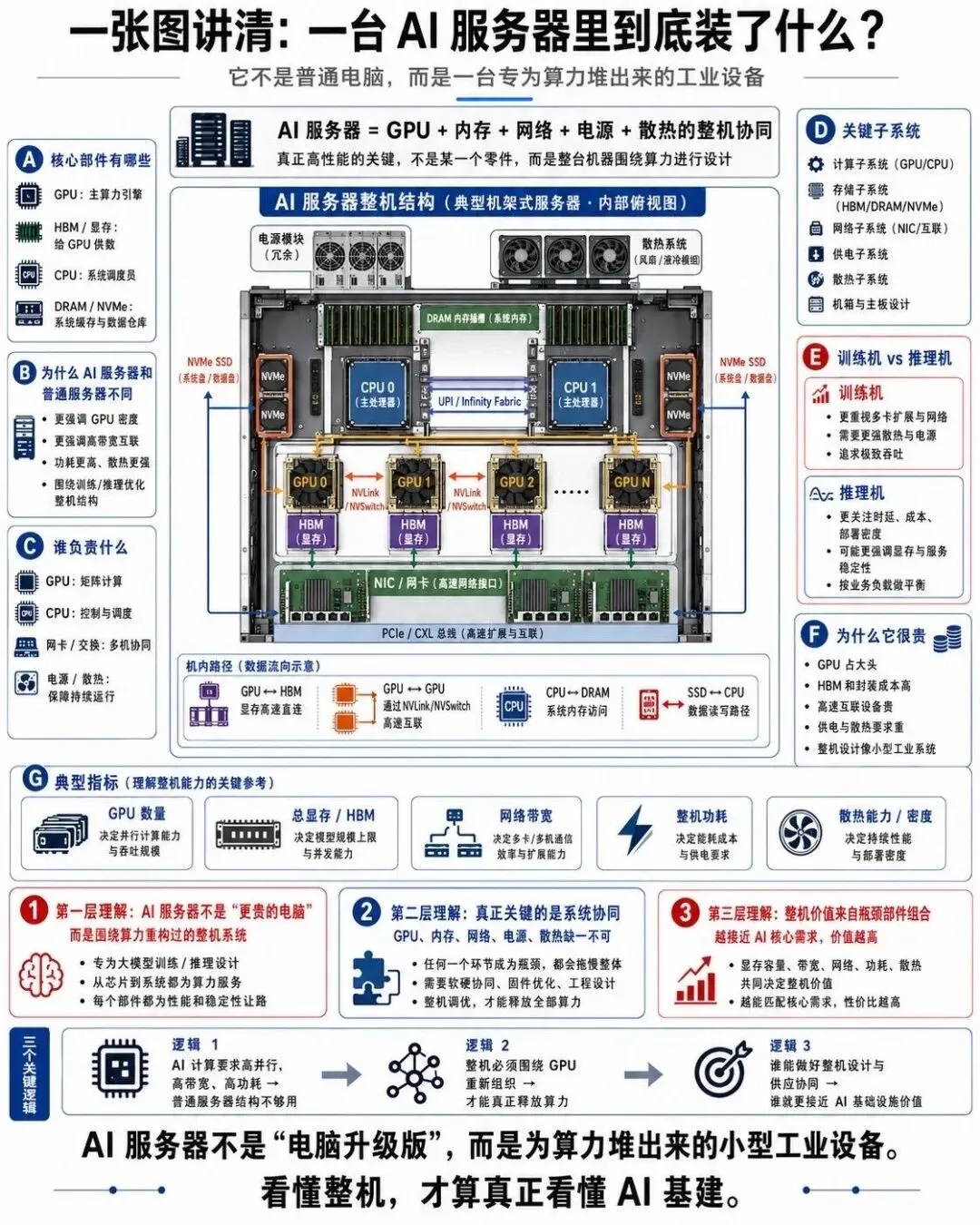 打开一台 AI 服务器,里面远不止几张 GPU.
打开一台 AI 服务器,里面远不止几张 GPU.
这张图展示的是典型 AI 服务器的内部结构:
N 张 GPU 通过 NVSwitch 全互联;
每张 GPU 周围密布 HBM 堆栈;
两颗高端 CPU 负责整体调度;
多组大容量 DRAM 内存;
多块 NVMe SSD 组成高速存储;
多张 400G / 800G 网卡,用于连接外部网络;
强大的液冷或风冷散热系统,确保整机功耗高达几千瓦时依然稳定运行.
一台 AI 服务器就是一个小型超算节点.成千上万台这样的服务器,通过高速网络连接在一起,才构成了训练千亿参数模型的硬件底座.
8. AI 数据中心: 为什么 AI 最后会拼电力,散热和机房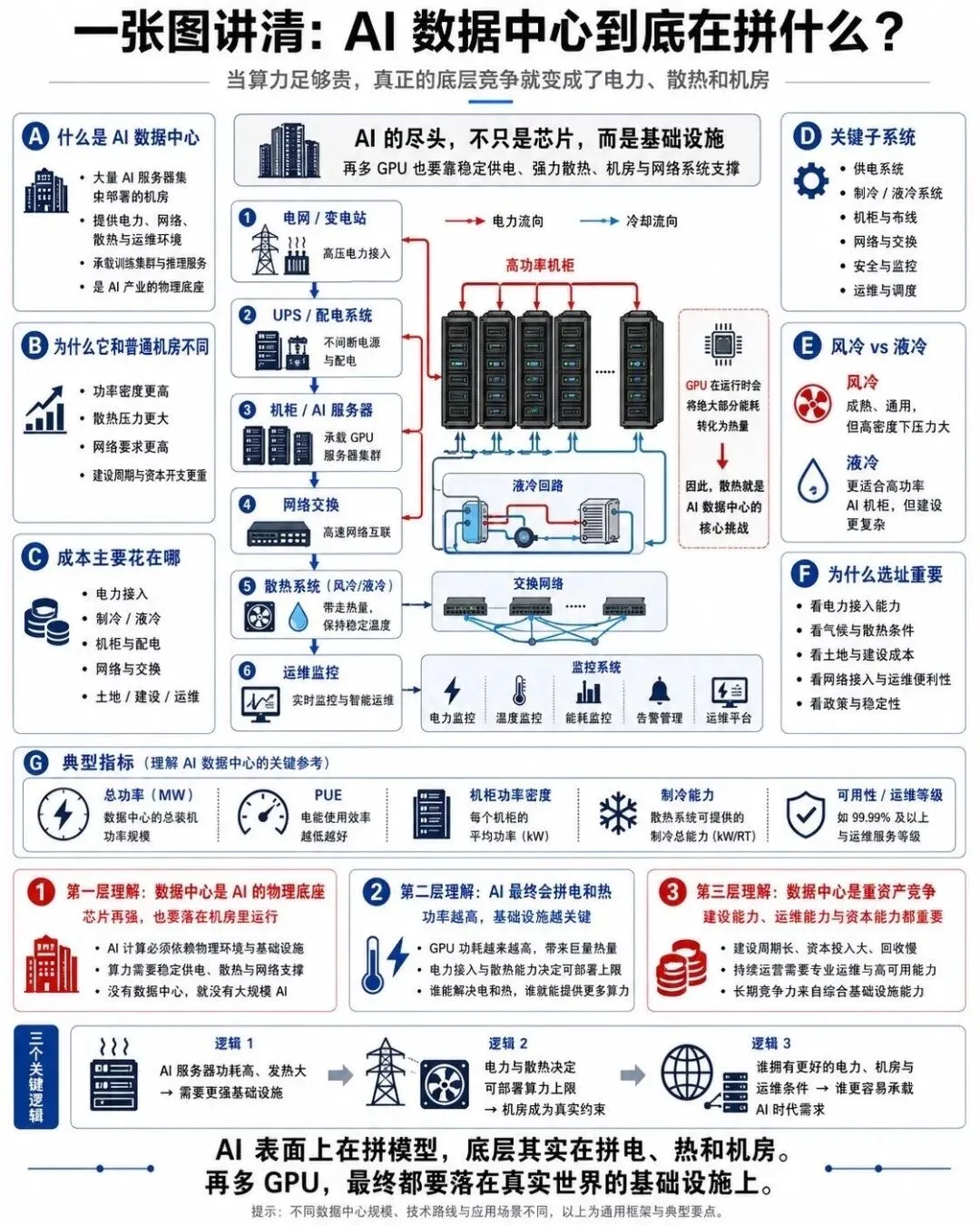
当 AI 规模大到一定程度,瓶颈从芯片转移到了电力,散热和基础设施.
这张图展示的是一个现代 AI 数据中心的痛点:
功耗密度急剧上升: 一个 AI 服务器机柜功耗可以轻松超过 40 kW,传统风冷根本压不住,必须走向液冷甚至浸没式冷却.
电力供给成为硬约束: 训练一次大模型动辄消耗几千万度电,数据中心的选址越来越靠近电力资源丰富,绿电充足的地方.
网络架构极其复杂: 几千张 GPU 之间的通信要求无阻塞,极高带宽的网络拓扑,光模块,交换机数量惊人.
AI 的竞争到最后,不只是芯片和算法的竞争,更是能源,散热,基建能力的综合较量.
9. 训练 vs 推理: 一个在造模型,一个在用模型
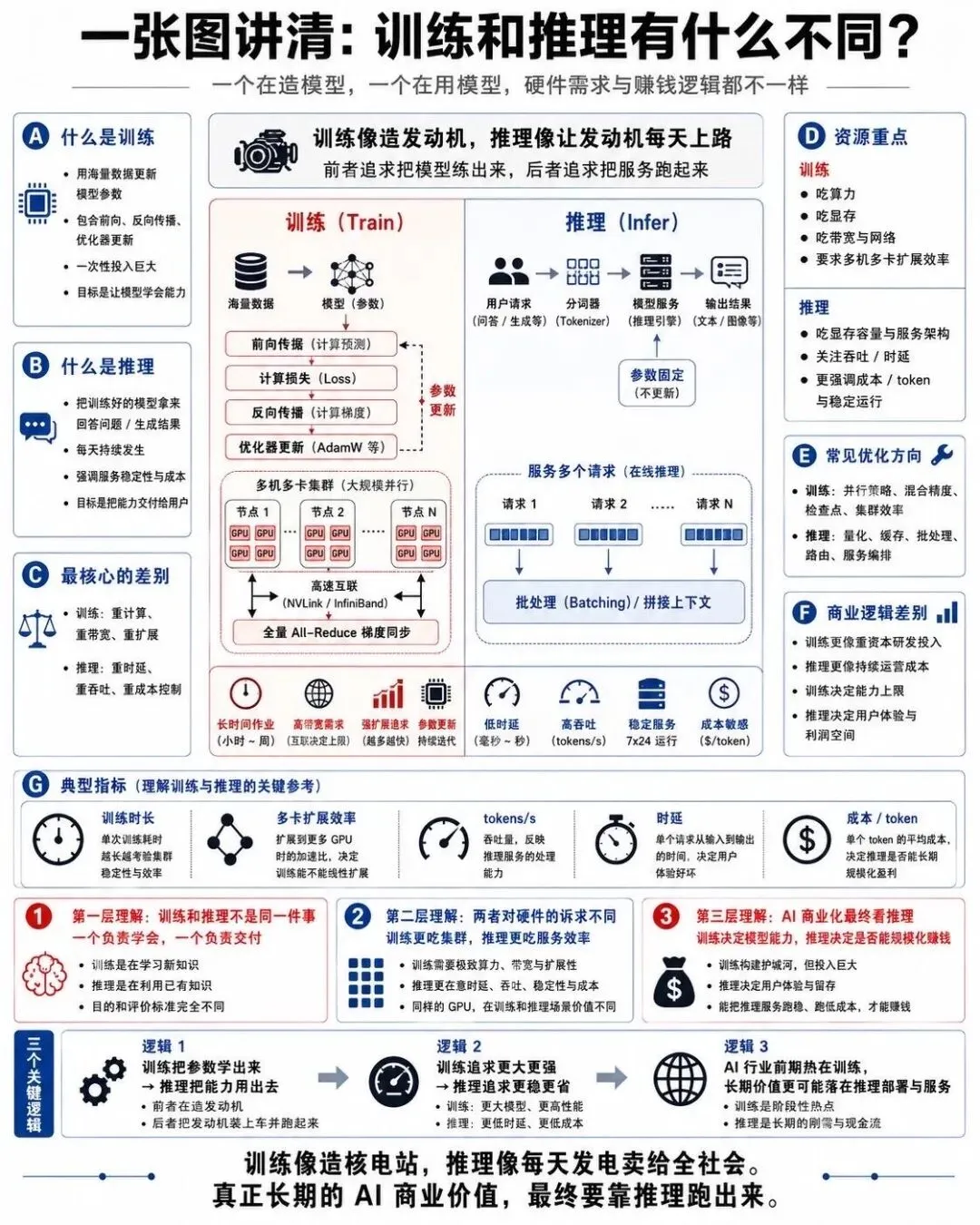 AI 的算力消耗,可以分为两个完全不同的阶段: 训练和推理.
AI 的算力消耗,可以分为两个完全不同的阶段: 训练和推理.
这张图对比了两者的特点:
训练: 用海量数据和巨大的算力,对模型进行前向传播和反向传播,反复更新参数,直到模型收敛.这个过程可能持续数周甚至数月,需要数千张 GPU 密集计算,对通信带宽要求极高.
推理: 模型训练好后,面向用户提供服务.每次输入一个 prompt,模型只做前向传播,生成一个 token.虽然单次计算量不大,但当用户规模到数亿级别时,推理所需的算力总和反而可能超过训练,并且要求极低的响应延迟.
训练决定了模型的能力上限,推理决定模型能否变成可用的产品.两者对硬件,网络,存储的要求截然不同,现在整个 AI 产业正在从'重训练'转向'训练+推理并重'.
10. AI 产业链的钱: 利润最终会流向哪些环节
 最后这张图,把 AI 产业链的价值分布画了出来.
最后这张图,把 AI 产业链的价值分布画了出来.
最底层是硬件: GPU,HBM,先进封装,网络设备.这些环节集中度极高,技术和产能壁垒深,目前拿走整个产业链中最丰厚的利润.往上一层是基础设施: 服务器制造,数据中心运营,云计算平台.这些环节资本投入巨大,规模效应明显,长期的回报取决于利用率和运营效率.再往上是模型层: 基础大模型的训练需要天量的资本投入,竞争极其激烈,真正的利润还在探索中.最上层是应用和工具: 面向用户的产品和服务,天花板极高,但壁垒相对较低,超额利润需要靠产品体验和网络效应来创造.
整体来看,AI 产业链的利润短期高度集中于芯片等基础硬件,长期会逐渐向下游的应用和生态环节扩散.但无论如何,看懂底层硬件,才能理解整个 AI 大厦是建在什么样的地基上.
AI 不是一个凭空出现的魔法,而是一整套精密工业系统运转的结果.从 GPU 的一个 Tensor Core,到数据中心的一条液冷管路,每一环都在支撑着大模型的训练和推理.
这 10 张图串起来,就是一幅 AI 产业链的全景地图.建议收藏,慢慢看.看懂这些,再去看 AI,半导体,算力,数据中心和相关公司,脉络会清楚很多.
