 夜雨聆风
夜雨聆风📄 AI单独92分,医生单独74分,联合只有76分——医学AI最魔幻的现实
全文字数:约 3,200 字预估阅读时间:8-10 分钟摘要:Harvard最新《Science》研究显示,AI在急诊分诊中诊断准确率67%,超过人类医生的50%-55%。但本文认为,真正值得关注的不是AI"赢了",而是它第一次走进真实临床的"深水区",暴露出影像缺失、长期病史处理不足、非语言信号盲区三大边界。结合JAMA研究"医生+AI反而不如AI单独"的发现和张文宏教授的警告, 本文呼吁:AI最大的风险不是出错和幻觉,而是医生不再怀疑和盲从。
AI急诊诊断考了67分:这张"不及格"的成绩单,为什么让我更兴奋?
上周,一篇发表在《Science》上的Harvard研究刷了不少医生的朋友圈。标题翻译过来大概是:AI在急诊分诊中诊断准确率超过了人类医生。

数字很直接:在患者刚进急诊、信息极其有限的早期分诊阶段,OpenAI的o1模型给出正确或接近正确诊断的比例是67%,而同样条件下的两位人类医生,只有50%到55%。

你看,如果把这当考试,满分100分,AI考了67,医生考了50到55。
按照惯例,这时候你应该焦虑一下,转发一下,感叹一句"医生要被替代了"。
但我读完这篇论文,反应恰恰相反——我是兴奋的。
而且我兴奋的点,不是AI考了67分。恰恰相反,我兴奋的是:它只考了67分。
你先别急,听我说完。

先看清楚,AI到底赢在哪里
这次Harvard的研究,发表在《Science》上,不是那种"让AI做几道选择题"的简单测试。它更像是一场正经的医学能力考试,而且连考了好几科。
研究团队让OpenAI的o1模型完成了五项不同的临床任务:读病历、做诊断、选下一步检查、评估预后、制定治疗方案。五科考下来,AI的表现全部持平或优于人类医生。
其中有一科特别夸张:临床推理能力评分。评的是你的诊断思路讲不讲得通、下一步安排合不合理。AI在98%的病例上拿了满分,而主治医师只有35% 。
你没看错,98%对35%。
但研究者自己说,这五科都不是最重要的那场考试 。
最重要的是第六科——真实急诊模拟。
他们从波士顿Beth Israel医院的急诊室里,选了76个真实病人的电子病历,然后把每个病例切成三个阶段,模拟真实的急诊流程:
🔹 第一阶段:病人刚进急诊,护士登记了几句主诉,加上生命体征。信息极其有限。 🔹 第二阶段:医生开始评估,信息多了一些。 🔹 第三阶段:检查结果陆续出来,信息相对充分。
AI和两位人类医生,拿到的是一模一样的电子病历文本。结果:
| 67% | ||
| 82% |
早期分诊阶段,AI领先医生超过10个百分点。信息充分之后,差距缩小了,但AI仍然保持领先。
这里有一个特别值得说的案例。有个病人因为肺栓塞入院,抗凝治疗后症状反而加重。两位人类医生都觉得是抗凝药效果不好。但AI注意到了一个细节——病人有狼疮病史。AI据此推断,肺部炎症可能不是栓塞本身的问题,而是狼疮引起的。后来证实,AI是对的。
这种"把病史里被忽略的线索串起来"的能力,恰恰是大模型在罕见病诊断上最被寄予厚望的方向。我之前专门写过一篇,感兴趣的朋友可以回看:
👉AI诊断罕见病,终于不再"瞎猜"了 | Nature最新突破。
今天我们继续聚焦急诊场景。
好,数字摆完了。单看这些数据,确实很容易得出一个结论:AI比医生强。
但这个结论,恰恰是我觉得最需要警惕的。
因为这次研究里,AI真正暴露出来的短板,比它的成绩更值得医生关注。
但真正值得兴奋的,是AI"考砸的地方"
看完上面那些数字,你可能已经开始焦虑了。
别急。我说我兴奋,不是因为AI赢了,是因为这次研究的设计,和以前那些"AI刷医学考试"的论文有一个根本的不同。
以前的AI医学研究,大多是让模型做标准化病例:整理好的、干净的、有明确答案的教科书式案例。那叫什么?那叫开卷考试做模拟题。AI在那种场景下考高分,说明不了太多问题。
而这次Harvard的研究,用的是Beth Israel急诊室里真实病人的电子病历 。研究者自己用了一个词来形容这些数据——“real-world, messy”,现实世界里的、乱糟糟的数据 。信息可能是不完整的,可能有偏差,可能护士记录的主诉和病人实际想表达的完全是两回事。
这才是"做真题"。
而AI在"真题"上考了67分。
你想想,如果一个医学生,从来只做模拟题能考95分,突然去急诊轮转,面对真实病人,只能考67分——你会觉得他"碾压了老医生"吗?还是觉得"嗯,这孩子终于开始面对现实了"?
我的感受是后者。
更重要的是,这篇论文很诚实地告诉你:AI这次做的"真题",其实还是有限制的真题。它还有三条边界没有跨过:


第一,没有影像。
整个实验中,AI拿到的全部是文本——电子病历里的文字信息。没有CT,没有超声,没有X光。而你我都知道,急诊里大量的关键诊断——肺栓塞、主动脉夹层、骨折——是靠影像定的。纯靠文字,相当于让一个医生蒙着眼睛看病。
第二,没有长期病史。
急诊停留时间通常只有几个小时。这次AI处理的也就是这几个小时的信息。研究者Adam Rodman自己说得很直白:“如果是一个住院好几天的病人,信息量大了之后,我认为AI的表现会下降。”
第三,没有非语言信号。
病人进来时脸色发灰、大汗淋漓、烦躁不安——这些信息,人类医生一秒钟就能捕捉到,但AI在这个实验里完全"看"不到。用研究者的话说,AI在这个实验里更像是"一个根据文字材料给出第二意见的远程会诊专家",而不是一个站在病床边的急诊医生 。
所以你看,AI的67分,是在一个受限场景里考出来的。它还没跨过影像、长期病史和非语言信号这三道门槛。
但这恰恰是让我兴奋的地方——AI终于不躲了。它不再只做干净的模拟题,它开始啃真实临床里那些乱糟糟的硬骨头了。67分不是终点,是起跑线。
而且别忘了,这次用的o1模型是2024年底发布的。用Harvard研究者Thomas Buckley的原话说:“那在机器学习的时间尺度里,已经是古代史了。”
新模型只会更强。问题是:当AI越来越强的时候,医生准备好了吗?
一个研究里没大声说,但医生必须警惕的发现
在所有对这篇Harvard研究的评论里,有一条被很多人忽略了,但我觉得它可能是整篇论文里最危险的暗线。
英国谢菲尔德大学的Wei Xing博士指出:实验数据暗示,当医生看到AI给出的答案后,可能会无意识地服从AI的判断,而不是独立思考。
他的原话是:
“This tendency could grow more significant as AI becomes more routinely used in clinical settings.” (随着AI在临床中越来越常规化使用,这种倾向会变得更加显著。)
这就是心理学里说的“自动化偏差”(automation bias)。
打个比方。你开车用导航,刚开始你还会看路牌、凭经验判断。但用了三年之后呢?导航说左转你就左转,哪怕你隐约觉得不对劲,你也懒得质疑了。直到有一天,导航把你带进了一条死胡同。
临床里也一样。AI说是肺栓塞,你还会不会坚持自己怀疑的主动脉夹层?AI给出的鉴别诊断列表里没有某个罕见病,你还会不会想到它?
当AI的准确率达到67%、82%甚至更高的时候,医生质疑AI的心理门槛会越来越高。而每一次不加质疑的服从,都是临床判断肌肉的一次萎缩。

这不是我一个人的担忧。
2026年年初,国家传染病医学中心(上海)主任张文宏教授专门谈到了这件事。
他明确表示,反对将AI系统性地引入医院的日常诊疗流程。
张文宏说,他个人用AI的方式是让AI对病例"先看一遍",然后凭借自己深厚的临床经验,一眼就能看出AI哪里是错的。但他担忧的是——一名医生若从实习阶段就未经完整的诊断思维训练,直接借助AI获得结论,将导致其无法鉴别AI诊断的正误。
这句话你细品。
张文宏能"一眼看出AI哪里错",是因为他有几十年的临床积累。但如果一个住院医师从第一天起就依赖AI给答案,他永远不会建立起那种"一眼看出错误"的能力。
这种能力的缺失,是隐藏在技术便利背后的深层隐患。
张文宏说的,其实和Harvard这篇论文的暗线是同一件事——只是一个发生在科研论文的数据里,一个发生在真实的住院医师培养现场。
AI最大的风险,从来不是它出错,而是医生不再怀疑它。
那医生到底该怎么和AI一起"做题"?
说到这里,你可能觉得:道理我都懂,那到底该怎么办?用还是不用?
我先给你看另一个实验的数据。这个实验的结论,可能比Harvard那篇更让你震撼。
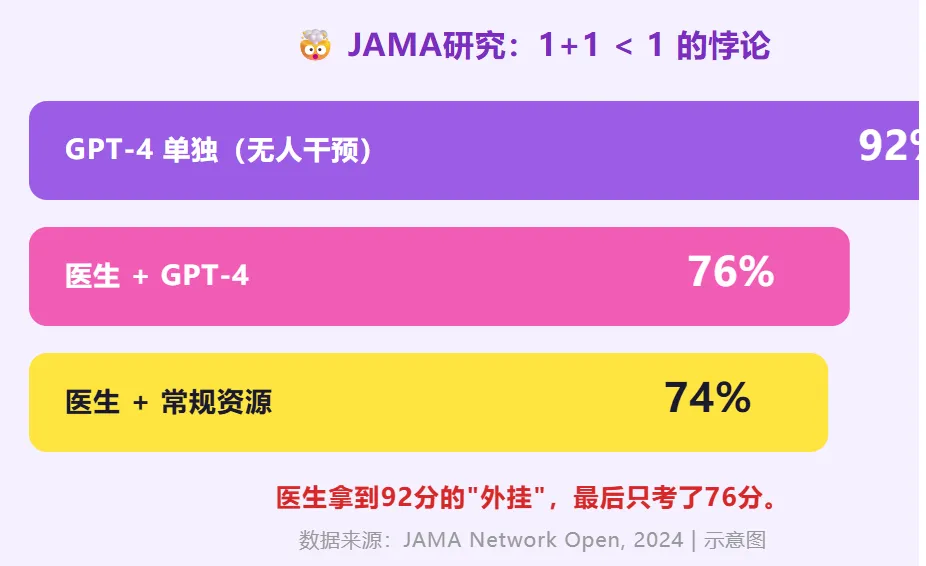
2024年,一篇发表在JAMA Network Open上的随机对照试验,招募了50名美国执业医生(26名主治医师,24名住院医师),让他们在60分钟内完成最多6个临床病例的诊断。一组可以用ChatGPT Plus(GPT-4),另一组只能用常规资源(UpToDate、Google等)。
结果:
| 74% | |
| 76% | |
| 92% |

两组医生之间几乎没有区别(差2个百分点,P=0.60,无统计学意义)。
但GPT-4单独做,比两组医生都高出16个百分点(P=0.03,有统计学意义)。
你再读一遍这个结果:
• AI单独考:92分。 • 医生单独考:74分。 • 医生+AI一起考:76分。
医生拿到了一个92分的"外挂",最后只考了76分。
换句话说——医生加入之后,不是在给AI加分,而是在拖AI的后腿。

这才是真正值得每个医生反思的问题。
不是"AI会不会替代我",而是——“我会不会用AI?”
我做了5期医学AI培训班,接触了几百位来自全国各地的医生。根据我的观察,医生在使用AI辅助诊断时,最常犯的三个错误是:
误区一:把AI当搜索引擎用。
只丢一句话过去——“胸痛鉴别诊断”——然后看AI给出的列表。这就像你把一个病人的主诉念给一位专家听,但不告诉他年龄、性别、病史、体征。专家能给你什么?只能给你一个教科书式的泛泛回答。
误区二:先有结论,再问AI。
心里已经觉得是肺炎了,打开AI只是想让它"确认一下"。这时候你看到的所有信息都会被你的大脑自动筛选——支持你结论的你记住了,反对的你忽略了。AI变成了你自我确认的工具,而不是挑战你盲区的工具。
误区三:AI一说不一样,就关掉。
AI给出一个你没想到的鉴别诊断,你的第一反应是"AI瞎说",而不是"我是不是漏了什么?“——但Harvard那个狼疮+肺栓塞的病例告诉你,有时候恰恰是AI给出的那个"意外答案”,才是对的。
JAMA的数据本质上在说一件事:不是AI不够强,是医生还没学会怎么和AI协作。
这就像给你一辆赛车,但你还在用骑自行车的方式开它——不是车不好,是你没学会开。
那怎么办?我的建议只有三条,很具体:
第一,把AI当资深同事的会诊意见,而不是判决书。
可以参考,必须复核。你在临床上收到一份会诊意见,也不会直接照抄吧?你会看看它的逻辑通不通,有没有遗漏,和你手上的信息是否一致。对AI的输出,也应该是这个态度。
第二,学会"喂数据、读输出、挑毛病"。
给AI更完整的上下文(病史、体征、检查结果、你的初步判断),然后重点看AI给出了什么你没想到的东西。不是看它和你一不一样,而是看它能不能帮你拓宽鉴别诊断的范围。
第三,越用AI,越要刻意训练自己的独立判断。
这条听起来矛盾,但它是张文宏那句话的实操版。用AI没问题,但每次用之前,先自己想一遍。先形成自己的判断,再看AI的答案,然后对比差异。这样做的好处是:你永远保持着"独立思考在先"的习惯,AI只是你的校验工具,而不是你的思考替代品。
Harvard研究的共同作者Adam Rodman提出了一个概念,叫“三元医疗模式”(triadic care model):未来的医疗不是"医生对病人"的二元关系,而是"医生 + 病人 + AI"的三角关系 。
在这个三角里,AI提供信息和推理,病人提供症状和偏好,而医生——医生的角色是做最终判断、承担责任、以及在AI出错时兜底。
这个角色,AI代替不了。但前提是——你得有能力兜得住。
AI考了67分,但真正的考试是给医生的
回到开头那个问题。
Harvard这篇《Science》论文发出来之后,很多人的反应是:“AI比医生强了,医生要被替代了。”
而我的反应是兴奋。
因为这是AI第一次认真地走进真实急诊、面对真实的乱数据、并且诚实地暴露出自己的边界 。它不再只是在标准化考试里刷分,它开始做真题了。
67分不算高。但它代表的趋势,不可逆转。
而JAMA那篇文章告诉我们:AI的成绩会越来越高,但如果医生不学会怎么用它,人用了AI,也等于白用。
张文宏的警告也在提醒我们:如果年轻医生从来没有被训练过独立诊断思维,未来面对一个92分的AI,他连错在哪里都看不出来。
所以,真正的考试不是给AI的。
真正的考试,是给每一个正在执业,和未来即将执业的医生的。
你准备好了吗?
AI考多少分不重要,重要的是医生有没有意识到——从今天起,医生也在被考。
如果你觉得文章有用,欢迎转发给你身边的同事。如果你想系统学习怎么在临床和科研中用好AI,欢迎关注我的公众号和知识星球"医学AI思维营"。
刚好最近,我也开了一个“给医学人士的Openclaw课”。手把手带大家学会养“小龙虾”,用好小龙虾来赋能忙碌的医学工作,第一期已经开班,欢迎关注。
我们下篇见。
文中的文章链接:
https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2825395
https://hms.harvard.edu/news/study-suggests-ai-good-enough-diagnosing-complex-medical-cases-warrant-clinical-testing
