 夜雨聆风
夜雨聆风AI Agent 已经能写代码、做研究、调用工具链,但碰到一份普通的 PDF 合同,它可能连表格第三列的数字都读错。LlamaIndex 创始人 Jerry Liu 在 DeepLearning.AI 的 AI Dev '26 上做了一场深度分享,把 PDF 解析拆解到格式底层:这个诞生于 1993 年的文件格式,记录的是"页面怎么画",根本没有"内容是什么"的概念。当 Agent 开始替人类处理保险理赔、财务审计、法律合同,读错一个数就是业务事故。
AI Agent 的能力天花板,卡在了一份 PDF 上
Jerry Liu 上周在 X 上分享了他在 AI Dev '26 的演讲 slides,主题直白到刺眼:"AI can't read PDFs, how do we fix it"。
"AI agents are going to automate huge amounts of knowledge work, but knowledge work depends on data, a lot of that data is in documents/PDFs, and existing OCR tools suck."
「AI Agent 将自动化大量知识工作,但知识工作依赖数据,大量数据存在于文档和 PDF 中,而现有的 OCR 工具很烂。」
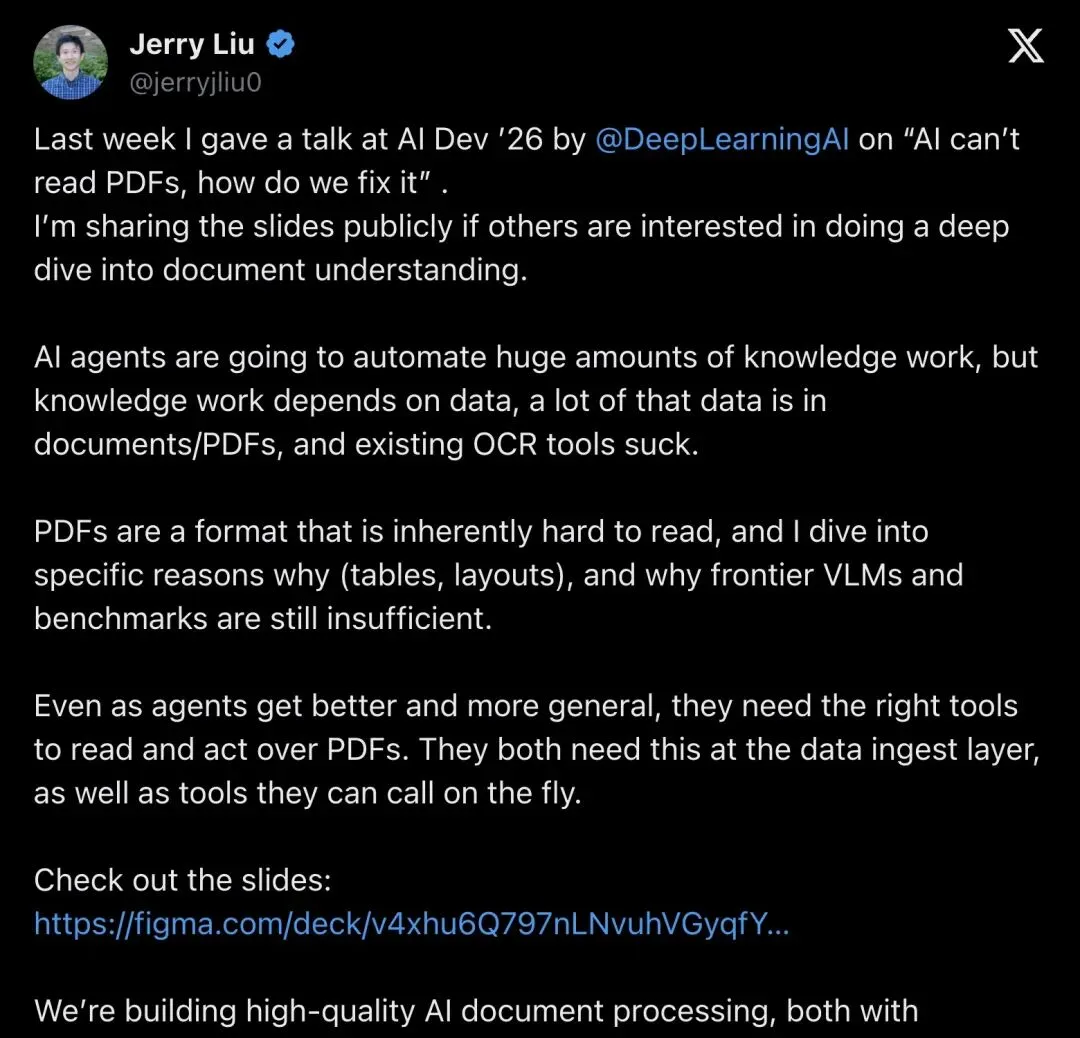
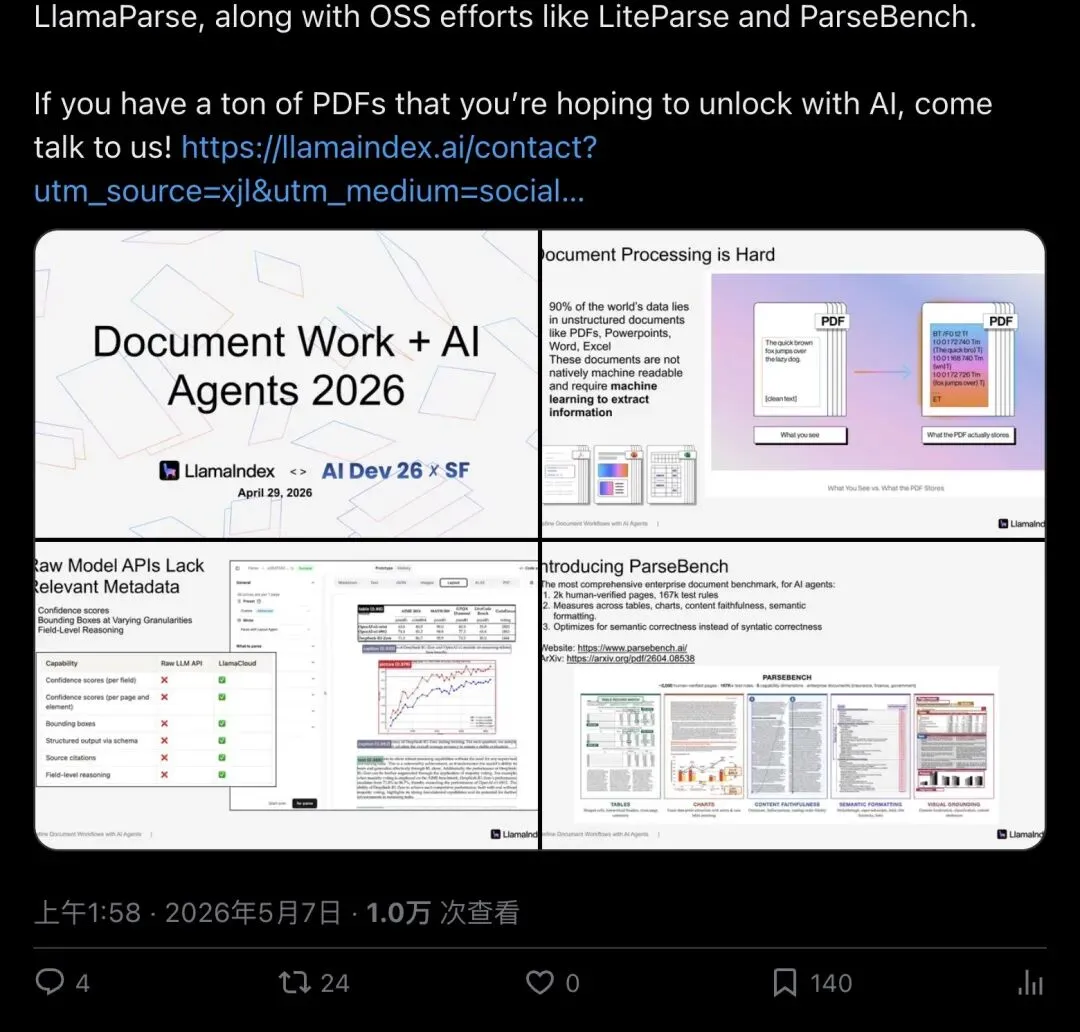
▲ Jerry Liu 在 X 上分享 AI Dev '26 演讲,公开 Figma slides,核心议题:AI 读不了 PDF,怎么办?
这个判断的杀伤力在于:模型能力再强、推理链再长,如果输入层就是错的,后面所有决策都建立在污染数据上。一个处理保险理赔的 Agent 读错了 coverage table 里的赔付金额,一个财务 Agent 把删除线标注的旧价格当成现价——这类错误在搜索摘要场景只是"不够好",在自动决策场景就是事故。
Jerry 把这个问题定位得很明确:Agent 同时需要两层文档能力——数据接入层的离线解析,以及运行时可调用的工具。光有一个还不够。
PDF 的底层真相:它画的是图,不是存的文字
为什么 PDF 这么难读?Jerry 今年 3 月发过一条长帖,开头就是:
"Parsing PDFs is insanely hard."
「解析 PDF 难到离谱。」
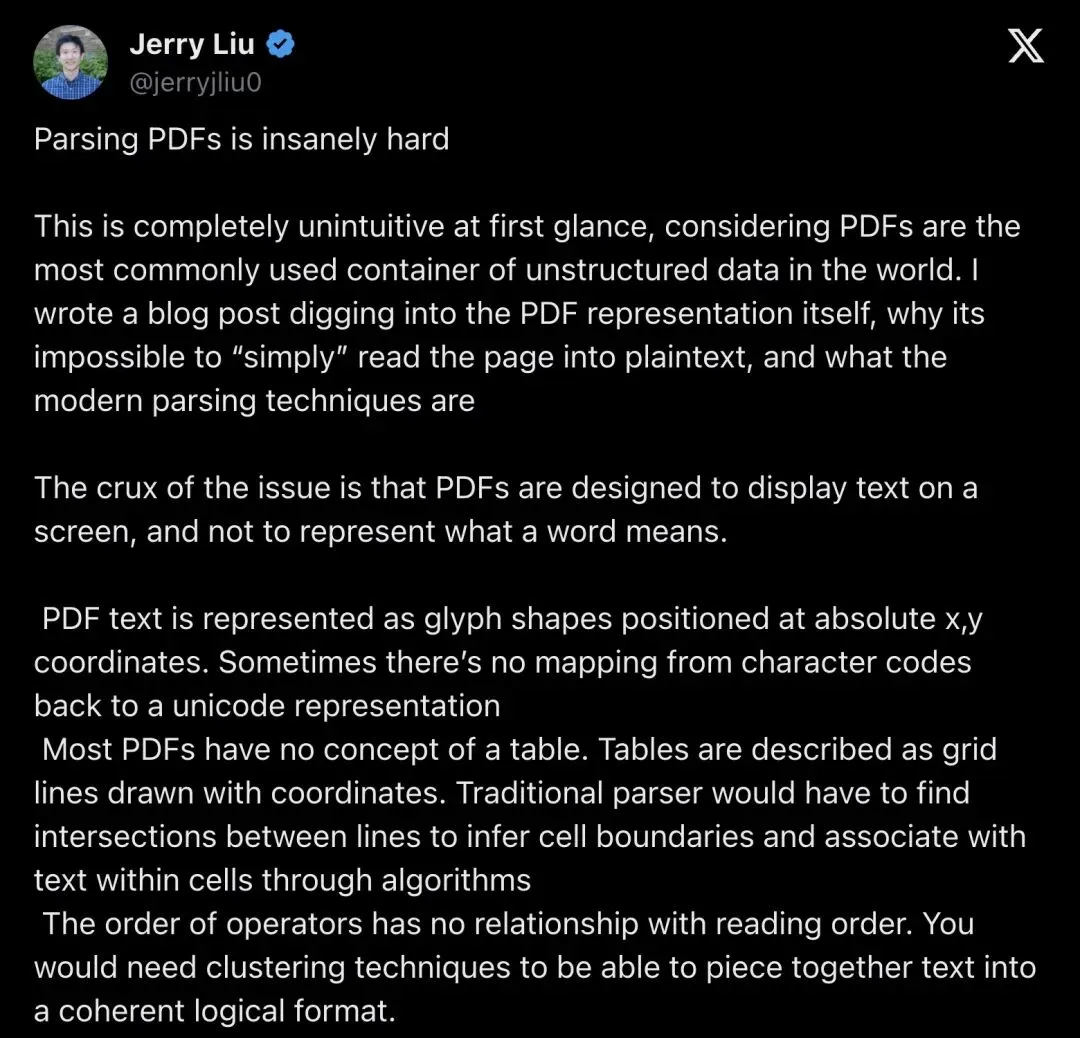
▲ Jerry Liu 3 月长帖,近 10 万次浏览,系统梳理 PDF 为什么天然不适合机器阅读
LlamaIndex 随后发了一篇官方博客《Why Reading PDFs is Hard》,把技术细节全部摊开。核心论点:
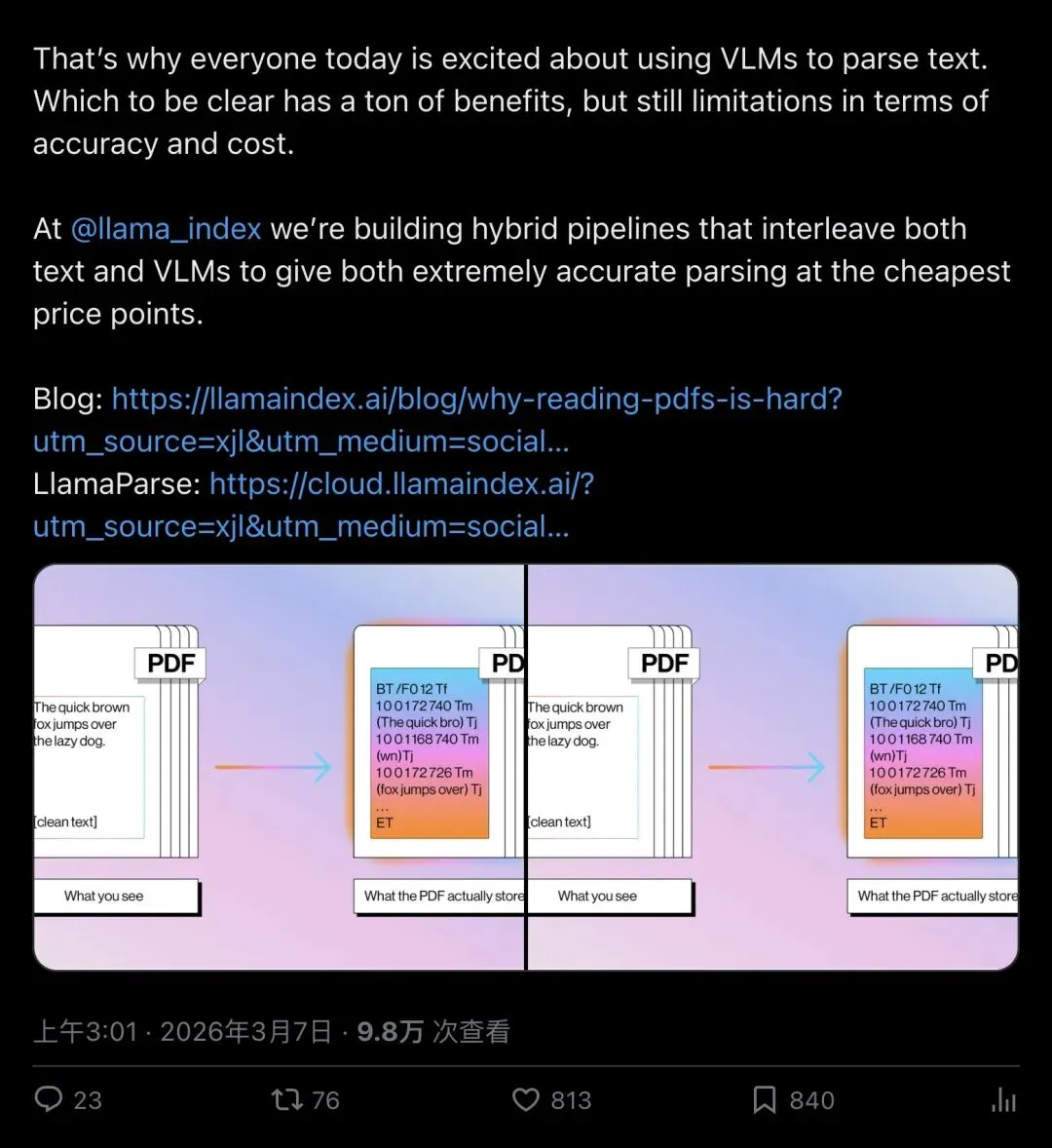
"A PDF describes how a page looks, not what it means."
「PDF 记录的是页面长什么样,不管内容是什么意思。」
▲ LlamaIndex 官方博客《Why Reading PDFs is Hard》,从 PostScript 源头解释 PDF 的先天缺陷
这要从历史说起。PDF 继承自 Adobe 1982 年的 PostScript,本质是一套页面描述语言。HTML 有 `<h1>`、`<table>`、`<p>` 这些语义标签,浏览器知道哪里是标题、哪里是表格。PDF 完全不同——它的指令是"在坐标 (x, y) 处,用这个字体,画出这些字形轮廓"。
这意味着几件事:
文字可能根本提取不出来。PDF 里的文本是 glyph(字形),被放在绝对坐标上。如果字体缺少正确的 Unicode 映射表(`/ToUnicode` CMap),屏幕上你明明看到正常的文字,复制出来却是一堆 `(cid:38)(cid:76)...` 乱码。光看 Common Crawl 就有大约13 亿份 PDF,其中大量存在这个问题。
表格在 PDF 里根本不存在。博客明确写道:"Most Real-World PDFs Have No Concept of a Table." 你看到的表格,在 PDF 内部是两组完全独立的绘图操作:一组画线条和矩形边框,另一组把文字扔到某些坐标。解析器必须自己检测线段交点、推断单元格边界,再把文字分配进去。更糟的是无框线表格——几乎变成纯粹的视觉模式匹配。
阅读顺序靠猜。博客里有一段描述尤其扎心:
"The order of operators in a content stream has zero guaranteed relationship to visual reading order."
「内容流中的操作符顺序,和视觉阅读顺序没有任何保证关系。」
两栏论文、财报脚注、页眉页脚,都可能以完全不符合人类阅读习惯的顺序写入内容流。解析器要把字符聚成词、词聚成行、行聚成列,再决定输出顺序。任何一步出错,送进 RAG 或 Agent 的上下文就被污染了。
截图扔给 GPT-4V?没那么简单
面对这些底层困难,一个直觉反应是:干脆把 PDF 每页截图,丢给 GPT-4V、Gemini、Claude 这些视觉大模型去读。
LlamaIndex 承认这个方法确实可行,但同时列出了生产级部署的四个硬伤:
成本失控。每页都要消耗 vision tokens,即使是纯文本页面也一样。一份 200 页的财报,全部截图走 VLM,成本是文本提取的几十倍。
幻觉风险。对高密度内容——密排表格、多列数字——VLM 仍然可能出现数字转置、凭空编造负号、跳过表格行等问题。
缺少审计线索。没有 bounding boxes、置信度分数、源文档定位。Agent 说"第三季度利润是 2.4 亿",你无法追溯这个数字来自文档哪个位置。
速率限制。API rate limits 让企业级批量处理(比如每天数万份合同)根本跑不动。
LlamaIndex 的技术主张因此指向了混合架构:
"Text Extraction + Vision Is the Right Architecture."
「文本提取 + 视觉模型,才是正确的架构。」
标准文本、字体与坐标信息从 PDF 二进制中直接提取,速度快、成本低;复杂区域——非标准表格、图表、手写批注——交给 VLM 或布局模型处理。最终输出要带细粒度 bounding boxes,让 Agent 的每个答案都能回溯到源文档的具体位置。
LiteParse:给 Agent 一个本地的、即时的文档解析工具
理念确定之后,LlamaIndex 在 3 月推出了开源工具LiteParse,定位是:本地运行、零云依赖、为 Agent 实时调用设计。
▲ LlamaIndex 博客介绍 LiteParse:本地文档解析,专为 AI Agent 设计
产品页的 slogan 简单粗暴:"Parse Any Document. Locally. Fast."不需要云服务、不消耗 LLM tokens、不需要 API key。一行命令安装:
``` npm i -g @llamaindex/liteparse lit parse anything.pdf ```
LiteParse 支持 PDF、Office 文档和图片,输出三样东西:layout-aware text(保留空间布局的文本)、页面截图、bounding boxes。它的设计思路是——能用文本解析的场景快速处理,需要更深层视觉理解时退回截图模式,交给后端模型。
LlamaIndex 也坦率划了边界:LiteParse 适合 coding agents 和实时流水线,追求速度和本地执行。如果是密排表格、多栏布局、图表、手写内容、扫描件这类高难度场景,他们建议用自家的商业产品 LlamaParse。
在 Hacker News 上,有开发者试用后的反馈是:
"Holy crap, the parsing is instant. It also parses in such a way that it matches the format of the original PDF."
「天哪,解析是瞬间完成的。而且解析出来的格式和原始 PDF 一模一样。」
Grid Projection:一个反直觉的工程选择
LiteParse 最有意思的技术细节,藏在 4 月发布的一篇深度博客里。
▲ LlamaIndex 技术博客详解 LiteParse 的 grid projection 算法
传统思路是先识别文档结构——这里是段落、那里是表格、这块是页眉——然后分别处理。LiteParse 走了另一条路:
"LiteParse instead will project text onto a monospace character grid."
「LiteParse 把文本投影到一个等宽字符网格上。」
具体来说,它从 PDF 中拿到每个字符的坐标,然后把这些字符投影到一个类似 ASCII art 的等宽网格里,尽可能保留原始的空间关系——列对齐、缩进、表格结构都通过空间位置来表达。
这个选择背后的逻辑是:与其花大力气识别文档结构(而且经常识别错),不如保留空间信息,把结构理解的任务留给下游的 LLM。大语言模型天然擅长处理这种 monospace/ASCII 风格的空间表示。
这套 grid projection 算法包含行分组、锚点提取、snap 分类、流式文本逃逸、网格投影、forward anchors、后处理等步骤,核心代码大约1,650 行 TypeScript。
ParseBench:Agent 时代需要新的评价标准
有了解析工具,怎么评价它好不好?传统 OCR 评估常用 BLEU、ROUGE、编辑距离这类文本相似度指标。LlamaIndex 认为这远远不够——
Agent 真正会被什么击穿?表格错列、图表数据缺失、格式语义丢失、无法追溯到源文档位置。这些问题用文本相似度根本测不出来。
于是他们发布了ParseBench:一个面向 Agent 场景的文档解析基准测试。
核心规格:约2,078 页人工验证的企业文档,覆盖1,211 份文件,包含169,011 条测试规则。评估不依赖 LLM-as-a-judge,全部采用确定性规则。
五个评估维度直接对应 Agent 的实际需求:
- Tables(表格)
:单元格内容、行列结构是否正确 - Charts(图表)
:数据值、标签是否准确提取 - Content Faithfulness(内容忠实度)
:是否遗漏或编造内容 - Semantic Formatting(语义格式)
:标题层级、列表、粗体等格式语义是否保留 - Visual Grounding(视觉定位)
:输出能否回溯到源文档的具体位置
在 ParseBench 的排行榜上(来源为 LlamaIndex/ParseBench GitHub 仓库,需注意项目方自评性质),LlamaParse Agentic 模式总分 84.88,表格维度达到 90.74,每页成本 1.25 美分;Cost Effective 模式总分 71.89,每页仅 0.38 美分。
一个需要注意的前提
必须指出的是,LlamaParse、LiteParse、ParseBench 都出自 LlamaIndex 之手。LlamaIndex 同时定义了赛道规则(benchmark)、提供了参赛选手(parser)、还公布了成绩单(leaderboard)。虽然 ParseBench 的数据和代码在 GitHub 和 arXiv 上公开,但这种"既当裁判又当运动员"的结构,读者在参考排名时需要保持审视。
PDF 解析赛道的竞争者远不止 LlamaIndex。社区讨论中已经有开发者提到 MinerU 等替代方案。VLM 的成本和能力也在快速变化——今天"截图太贵"的判断,明年可能就不成立了。混合架构的最优边界会随模型迭代不断移动。
但 Jerry Liu 提出的核心问题依然成立:当 AI Agent 从"辅助搜索"走向"自动决策",它的输入层必须从"大致能读"升级到"语义正确"。PDF 恰好是这条路上最大的障碍物之一。
Common Crawl 里有 13 亿份 PDF。全球企业的合同、财报、保单、医疗记录、工程图纸,绝大多数仍然以 PDF 形式存在。谁能可靠地把这些文件变成 Agent 可以信任的结构化输入,谁就拿到了 Agent 基础设施最关键的一块拼图。
— END —
