 夜雨聆风
夜雨聆风一个健忘的Agent让人沮丧,一个记错事的Agent才真正危险。
开篇
大语言模型(LLM)其实是失忆症患者。
你给它一段提示词(prompt),它回复完的那一刻,就忘了你曾经存在过。模型权重里没有"上次对话"的痕迹,每次响应都是从零开始。
那为什么现在的AI助手能"记住"我们的对话?
答案不在模型本身,而在围绕它的系统设计(Harness)。
这就是今天要聊的核心问题:AI Agent的记忆系统是如何工作的。
一、记忆的本质:不是存储,是生命周期管理
很多人以为记忆就是"把对话存起来"。错了。
真正理解了记忆的工程师会说:记忆是一个生命周期问题——写入、老化、覆盖、删除、遗忘。
想象一个场景:
用户说:"我住在伊斯坦布尔,下个月搬去柏林。"
naive追加的结果:
用户住在柏林 用户住在伊斯坦布尔(被覆盖)
问题来了:当用户问"我以前住哪?"时,Agent答不上来。
带治理的方案:
用户住在柏林(current,有效) 用户曾住在伊斯坦布尔(superseded,保留用于时序推理)
同时,一个PII过滤器会捕获信用卡号这类敏感信息,直接拒绝写入。
这就是记忆管理的精髓:不是简单的增删改查,而是维护一个可审计、可溯源、有时序语义的信息网络。
二、上下文窗口:最短的那块木板
最原始的记忆方式?直接把整段对话塞进Prompt。
只要上下文窗口够大,模型就有完美记忆。但问题就在这里:
每个模型都有固定的上下文窗口上限。
一旦对话超出限制,你必须丢弃点什么。最简单的策略是FIFO(先进先出)——丢弃最早的对话。
但FIFO是灾难性的:如果恰好是用户自我介绍的那条消息被丢弃,Agent就会陷入"你是谁?"的死循环。
真实系统会用更聪明的策略:
摘要(Summarization):定期把对话压缩成摘要 检索(Retrieval):只召回相关内容 分层(Hiearchical):热数据放内存,冷数据放磁盘
三、两种记忆:工作记忆与长期记忆
你的Agent在同一时刻处理着两件截然不同的事:
工作记忆是Agent的"桌面"——它正在处理的所有东西都在这儿。
长期记忆是Agent的"档案室"——那些"也许以后会用到"的信息存在这里。
两者之间的流转才是真正考验工程能力的地方:
什么时候把信息从工作记忆写入长期记忆? 按什么粒度写?整条消息还是提取的实体? 如何处理冲突和矛盾?
四、向量的魔法:如何让机器理解"意思"
如果说记忆是图书馆,向量就是让书籍自己找到读者的索引系统。
什么是向量嵌入?
向量嵌入是把文本通过神经网络转换成一组数字(通常1536维或3072维)。它的核心特性是:
语义相近的内容,在向量空间中距离更近。
"我喜欢在周末去徒步"和"周末我通常去爬山"——这两句话向量距离很近,即使没有共享词汇。
语义搜索的原理
当用户问"用户周末一般做什么?"时:
问题被转换成向量 在向量空间中找最近的N个记忆 返回"最相关"的历史信息
这就是RAG(检索增强生成) 的技术基础。
五、四种记忆类型:认知科学给我们的启发
AI Agent的记忆系统设计,其实大量借鉴了认知科学的研究成果:
1. 情景记忆
定义:发生了什么,什么时候发生的 例子:"周二用户问过《剑风传奇》" 检索方式:按时间、最近邻 典型应用:ChatGPT的跨会话记忆
2. 语义记忆
定义:事实和概念 例子:"用户住在洛杉矶 Highland Park" 检索方式:向量相似度 典型应用:知识库问答
3. 程序记忆
定义:学会的技能和工具使用 例子:"用户偏好简洁回答,喜欢看代码示例" 检索方式:上下文激活 典型应用:个性化回复风格
4. 工作记忆
定义:当前的"便签板" 内容:系统提示词 + 检索到的记忆 + 当前消息 特性:每次对话重置
一个实际的例子
用户走进博物馆导览Agent,说:"再给我讲讲你之前提到的那个Refik Anadol的作品。"
这一句话触发了四种记忆同时工作:
情景记忆 → 找到上次聊Refik作品的对话 语义记忆 → 从展品目录RAG出作品的完整描述 程序记忆 → 调取实时数据(当前展览状态) 工作记忆 → 把所有信息拼进Prompt,生成回答
用户感知不到任何"记忆切换"的痕迹——这正是设计的目标。
六、RAG循环:Agent的记忆是如何运转的
生产环境中的Agent,每次对话都在跑这个循环:用户消息 → 编码Query → 向量搜索 → 召回Top-K → 拼入Prompt → LLM回答 → 治理新信息 → 更新记忆
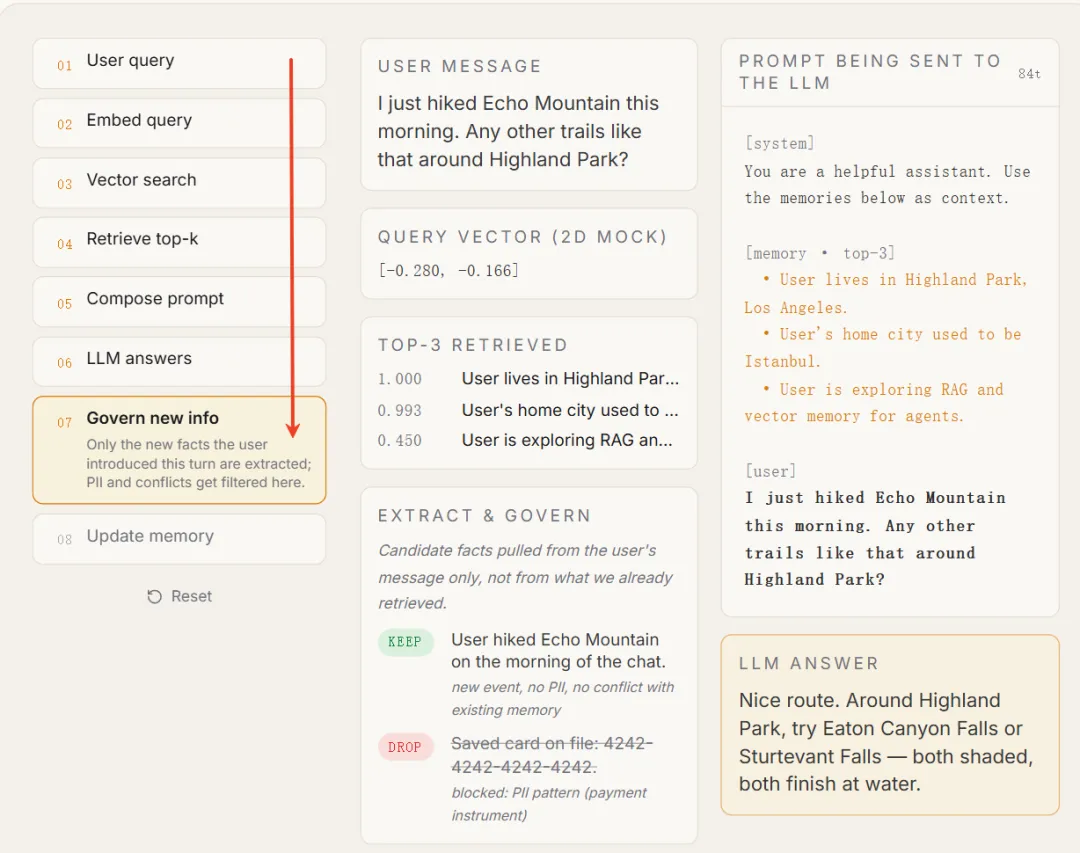
几个关键技术
1. HyDE(Hypothetical Document Embeddings)
问题:用户问"用户周末一般去哪?",直接搜可能漏掉答案。
HyDE的解法:先用LLM生成一个"假答案",然后把假答案向量化再去搜。
假答案不需要正确,只需要"像"真正的答案。
2. 混合检索(Hybrid Retrieval)
单一检索器不够。真实系统往往同时运行:
Dense检索(向量):擅长语义理解、同义改写 Sparse检索(BM25):擅长精确匹配、专业术语 Graph检索(图数据库):擅长关系推理
三种结果用RRF(互惠排名融合) 合并权重,输出统一排序。
3. 治理门控(Governance Gate)
每条新信息过"安检":
PII检测:信用卡号、手机号直接拒绝 时序标注:标记"current"还是"superseded" 权限检查:这条信息谁可以读?
七、多Agent记忆:当团队合作时
单个Agent问"我记得什么"。多Agent团队问:"哪个Agent记了什么?为谁记的?谁还能读?"
这时记忆从"存储"变成“权限图”:
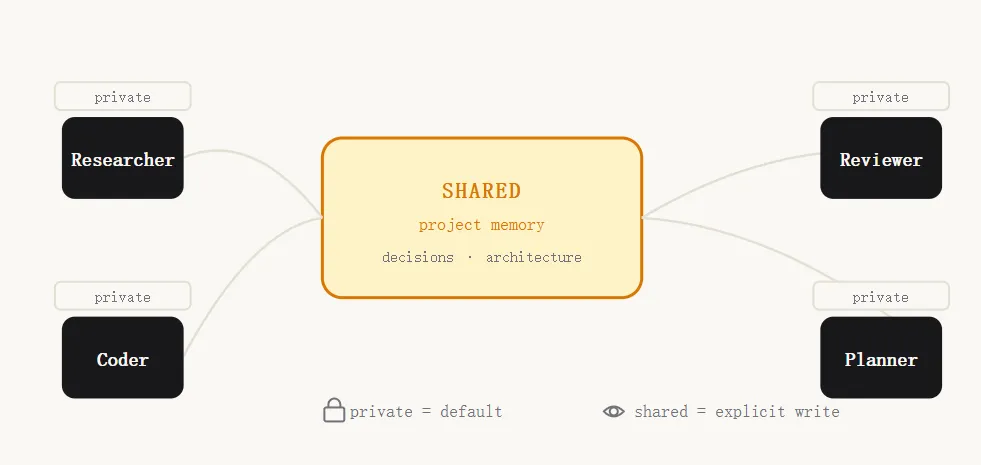
核心原则:默认私有,显式共享。
研究员Agent随手记的研究笔记,不应该自动进入项目频道。跨范围写入必须是有意为之,并且附有权限策略。
六个高频踩坑场景
十、行动指南
如果你是开发者,想要构建自己的Agent记忆系统:
1. 从向量存储开始
成熟的向量存储生态:Pinecone / Weaviate / pgvector
2. 设置治理层
PII过滤必须第一优先级 时序标记让系统"知道"信息是否过期
3. 监控这些指标
检索召回率(相关记忆被召回的比例) 上下文利用率(Prompt里多少是有效信息) 幻觉率(基于错误记忆生成的回复比例)
4. 考虑混合架构
向量库做语义召回 图数据库做关系推理 KV做高频访问缓存
结语
"记忆治理决定了你的系统是昙花一现的Demo,还是能上生产的企业级Agent。"
大模型本身是失忆的,但通过精心设计的记忆系统,Agent可以:
跨会话记住你的偏好 理解你和你的关系网络 在多Agent协作中正确共享信息 在提供便利的同时保护隐私安全
记忆不是把对话存起来,而是一套信息的生命周期管理体系。
理解了这一点,你就理解了现代AI Agent最核心的工程挑战。
参考资料:https://memory.cobanov.dev/
