 夜雨聆风
夜雨聆风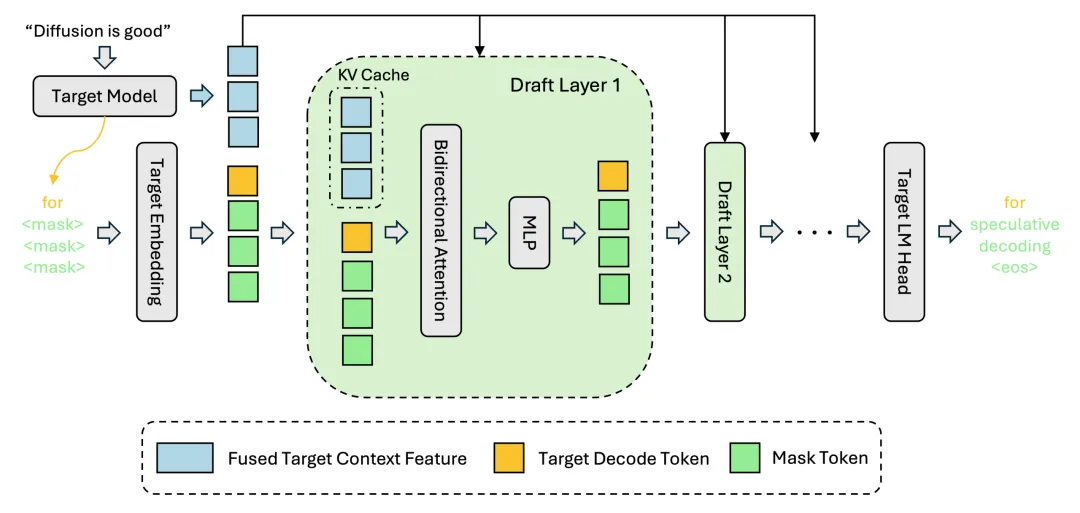
第一次用本地模型跑推理的时候,我那叫一个崩溃。GPU 风扇已经转得跟直升机起飞似的,终端里 token 还是一个一个往外蹦。我坐在那儿盯着屏幕,脑子里只有一个念头:就这速度,真有人敢拿去跑生产环境?
直到后来我在 GitHub 上刷到了一个叫 DFlash 的项目。
它到底在搞什么
DFlash 全称"Block Diffusion for Flash Speculative Decoding",名字挺唬人的。但核心思想其实特别朴素——让大模型不用每次都亲自下场,先派个小弟去猜,自己再批量把关。
这叫"投机解码"(Speculative Decoding)。打个比方:你写文章,先让实习生打草稿,你再看一遍,觉得对的留下,不对就改。好处是一次能看一大段,不用逐字逐句审。
传统投机解码的草稿小弟也有毛病——它自己是自回归的,说白了就是也得一个个字往外蹦,只是模型小一点、快一点而已。
DFlash 的狠活在于,它用了 Block Diffusion 架构,让小弟一次性就能蹦出一整段。不是逐个 token,是一整块直接出来。从"逐字打草稿"升级到了"整段复制粘贴"。
支持的覆盖面有点离谱
我翻了下文档,第一感受是:这帮人是不是不睡觉的?
推理后端覆盖了 vLLM、SGLang、Transformers,还有 MLX——对,就是那个给 Mac 用的框架。不管你用 NVIDIA 显卡还是 MacBook Pro,都能跑。
模型覆盖更离谱。Qwen、Gemma、Llama、GPT-OSS、MiniMax、Kimi、DeepSeek……听过的开源模型基本都有对应的草稿模型。我怀疑他们的训练集群是 7×24 连轴转。
而且人家有论文(arXiv:2602.06036),在 GSM8K、MATH500、HumanEval 这些硬核 benchmark 上测过。现在 3.6k star,MIT 开源。
对我们意味着啥
最直接的一点:省钱。
做 LLM 服务的都知道,推理成本是命根子。DFlash 减少大模型的前向传播次数,能降低延迟和算力消耗。同样硬件服务更多用户,或者同样用户量用更便宜的机器。
部署也省事。我最喜欢的一点是,不用改目标模型的权重,额外加载一个小型草稿模型就行。vLLM 和 SGLang 都是一行配置。已经在用这些框架的团队,接入成本几乎为零。
还有个我挺期待的:官方说训练配方即将开源。以后可以针对自己的私有模型或者特定领域模型,训练专属的草稿模型。如果你的业务场景有特殊术语或者格式要求,通用草稿模型不够用,自定义的就能精准匹配。这点对我这种经常要折腾垂直场景的人来说,吸引力挺大的。
泼点冷水
也不是没毛病。首先它面向的是已经有 LLM 部署经验的开发者。还在用 Colab 免费版跑 7B 模型的同学,暂时还用不上。
其次,虽然模型支持列表很长,但具体到你要用的那个版本,兼容性还是得确认。用的人多了 edge case 肯定冒出来。
另外投机解码的加速效果,取决于"目标模型接受草稿 token 的比例"。任务类型太刁钻的话,实际效果会打折扣。这是所有投机解码方案的共同限制,DFlash 也不例外。
但怎么说呢,我觉得 DFlash 代表了一个挺重要的趋势:大模型推理优化正在变得越来越工程化。以前投机解码更多是论文概念,现在有人做成开箱即用的工具,还配齐了主流框架支持。对整个社区都是好事。
最后
做大模型部署或者推理优化的朋友,建议去看看。就算暂时不用,了解一下 Block Diffusion 的思路也值。
我已经 star 了。你随意。
