 夜雨聆风
夜雨聆风很多子女发现父母记性越来越差,医生诊断为“轻度认知障碍”(MCI),最担心的就是——会不会很快发展成阿尔茨海默病(AD)?如果能提前准确预测,就能抓住早期干预的黄金窗口。
但现实很骨感:要预测未来3年内的转化,需要长期跟踪、反复做昂贵的影像和脑脊液检查,数据收集动辄数年,样本量少得可怜。传统预测模型动辄需要几百个样本才能“学得会”,这让很多医院和科研团队犯了难。
最近,一篇来自顶尖科研团队的重磅研究给出了一个令人惊喜的答案:一种名为TabPFN的新型AI模型,在数据极度稀缺的情况下(比如只有50个训练样本),依然能精准预测MCI向AD的转化! 这项研究利用了阿尔茨海默病神经影像学倡议(ADNI)的TADPOLE数据集,系统评估了TabPFN与传统机器学习方法的表现。原文链接附在文末。
为什么预测这么难?数据“卡脖子”是关键
预测MCI到AD的转化,是老年医学和神经科学领域的“圣杯”之一。早发现、早干预,能延缓认知衰退、提升生活质量。
但问题在于:
- 数据获取成本极高:
需要多年随访、多次MRI(磁共振)、PET(正电子发射断层扫描)、脑脊液穿刺,还要记录APOE4基因分型……一位患者完整的数据,可能要花费好几万甚至十几万。 - 样本量先天不足:
像ADNI这样的大型研究,全球也不过一两千人的完整数据可供使用。很多新成立的记忆门诊、社区医院,可能只有几十个有效病例。 - 传统模型“胃口大”:
像XGBoost、LightGBM这样的梯度提升模型,通常需要几百个训练样本才能达到临床可接受的准确率。数据少了,模型就“学不会”,预测能力大打折扣。
正是在这样的背景下,科研团队开始探索预训练基础模型——就像已经读过万卷书的“学霸”,在面对新题目时,哪怕只给很少的例题,也能举一反三。TabPFN就是这类模型中的佼佼者。
新模型TabPFN:预训练“学霸”的降维打击
TabPFN是什么?简单打个比方
传统机器学习模型是从零开始学习数据中的规律,好比一个没学过数学的人,需要做几千道题才能掌握加减乘除。而TabPFN在开发时,已经通过上千万个合成的表格数据任务进行了“预训练”,相当于它已经掌握了各种数据模式下的“解题套路”。当面对新的医疗数据时,它不需要从头训练,而是把训练集当作“上下文”——就像给你看几个例题,然后直接回答新问题。这种能力叫零样本学习或上下文学习。
论文中使用TADPOLE数据集,只保留了多模态生物标志物特征:人口统计学(年龄、性别)、APOE4基因型、MRI脑体积、脑脊液标志物、PET成像。特意排除了认知测试分数(如MMSE、CDRSB),以防“标签泄露”——因为这些分数本身就接近诊断标准,用了反而会让预测变得“取巧”,不真实。
研究设计了哪些对比实验?
研究团队比较了五种模型:经典线性模型(逻辑回归)、集成学习(随机森林、LightGBM、XGBoost以及经过超参数优化的XGBoost)、还有明星选手TabPFN。实验分三步:
- 数据效率测试:
分别用50、100、200、500、1000个训练样本,每种规模重复10次,看谁在样本少时表现好。 - 总体表现评估:
用完整保留的验证集,计算AUC(曲线下面积,衡量排序能力)和平衡准确率(BCA,平衡敏感度和特异度)。 - 阈值优化分析:
因为发现TabPFN的AUC很高但BCA低,进一步寻找最佳决策阈值。

图1:轻度认知障碍向阿尔茨海默病的转化预测:完整模型比较。XGBoost AUC最高(0.901),TabPFN紧随其后(0.892),但BCA排名却不同。
数据说话:小样本时,TabPFN一枝独秀
场景一:只有50个训练样本(相当于一家小诊所的积累)
- TabPFN的AUC达到了0.796,
超过了XGBoost的0.765、逻辑回归的0.777、LightGBM的0.713。 高出8.3个百分点!在医疗预测领域,这是一个非常显著的差距。
场景二:样本逐渐增加到500人
所有模型的AUC趋于接近(0.836~0.861),差距缩小。传统模型在数据充足时也能表现良好。 这说明TabPFN的最大优势恰恰体现在数据稀缺的场景——也就是现实中最需要它的地方。
场景三:平衡准确率背后的“隐藏秘密”
虽然TabPFN的AUC很高,但它的平衡准确率(BCA)却最低(0.684)。为什么会出现这种矛盾?
研究人员进一步分析发现:TabPFN输出的预测概率普遍偏低,大多数患者的风险分数都小于0.5(即使后来确诊为AD)。如果按照常规的0.5阈值来判断,就会把很多高风险患者漏掉。
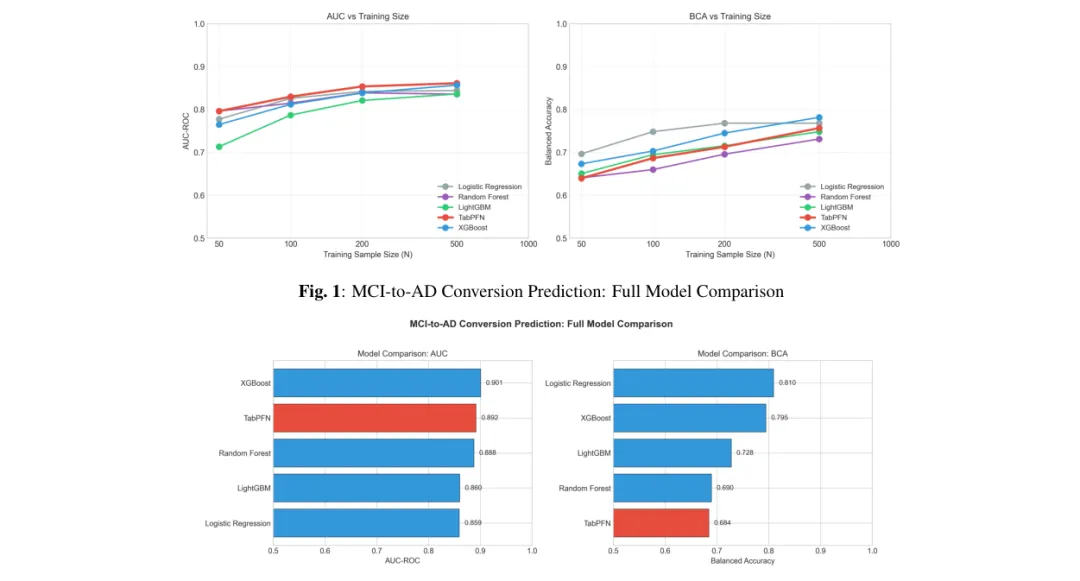
图2:在不同训练样本量下,TabPFN在小样本时AUC领先,但BCA始终落后。
阈值优化:把“及格线”降低到0.14
通过细致的阈值扫描,发现TabPFN的最佳决策阈值是0.14(远低于0.5)。在这个优化阈值下,TabPFN的BCA从0.68飙升到0.82,跟其他模型不相上下。
这意味着什么?TabPFN更适合作为一种“高灵敏度筛查工具”:只要模型给出哪怕14%的风险概率,就建议医生进一步关注。毕竟,错过一个真阳性转化患者的代价,远大于增加一些假阳性患者的随访成本。这对于早期干预的临床场景来说,是非常合理的。
对家属和康复从业者的实用价值
- 数据少也能用上AI辅助预测:
新成立的记忆门诊、社区康复中心、罕见亚型研究,都可以用TabPFN在小样本下获得有意义的预测结果。不必等到积累成百上千个病例。 - 不要直接看风险百分比:
如果医生告知“AI预测风险是0.3”,不是指30%会转化,而是一个相对风险分数。经过校准后,超过0.14就应纳入高风险管理。 - 辅助决策,不是替代诊断:
论文明确强调,这只是一种筛查工具,不能代替临床医生的综合判断、神经心理评估和必要检查。 - 未来可期:
研究团队正在探索将TabPFN扩展到其他疾病预测,以及改进其概率校准问题。以后可能会推出更易用的临床决策支持工具。
特别提醒:如果有家人正处于MCI阶段,请务必在专业神经科医生指导下进行干预,切勿自行根据AI结果停药或调整方案。本文内容基于学术研究,不能替代临床诊疗。
总结:数据稀缺不再“卡脖子”
这项研究让我们看到,预训练基础模型(如TabPFN)在处理医学“小数据”问题上具有颠覆性潜力。对于阿尔茨海默病这类需要长期纵向数据的疾病,它提供了一个实用的新思路——在数据有限时,也能尽早启动风险预测,为早期干预争取时间。
当然,模型还需要更多外部数据验证、还需要优化阈值适应不同人群。但这无疑是一个振奋人心的开始:科技正在努力让“早发现”不再那么难。
原文地址:https://arxiv.org/abs/2604.27195v1
你家老人有没有出现记忆力下降、丢三落四的情况?你了解过“轻度认知障碍”这个概念吗?欢迎在评论区聊聊你的经历和困惑~
