 夜雨聆风
夜雨聆风AI缺乏长期记忆是当前技术发展中的核心瓶颈,也是制约AI从工具进化为伙伴的关键因素。本文将剖析AI记忆的本质,揭示所谓"记得你"背后的技术真相,并提供实用的记忆管理策略。
核心结论:AI的"记忆"是工程设计的外挂能力,而非模型原生功能。每一次对话,AI都相当于从零开始,就像一张用完即丢的便签纸。
一、上下文窗口真相:AI的"记忆"只是临时缓存
1. Token是AI理解的基本单位
AI模型通过Token处理信息,其中1个Token大约对应0.75个英文单词或1个中文字符:
中文100字 ≈ 100 Token(1:1)
英文100词 ≈ 133 Token(3:4)
2. 上下文窗口的物理限制
现代大语言模型的上下文窗口可达128K Token甚至200K Token以上,但实际可用空间并非完全自由:
系统提示词:根据任务复杂度占用不等Token,设计不当可能消耗数万Token
函数定义与工具调用记录:使用AI工具链时会自动追加内容
安全过滤与格式约束:部分模型会保留内部占位
设计提示:预留20%-30%的缓冲空间,避免关键信息被截断。
3. 模型本质是无状态的概率预测器
主流大语言模型本质上是一种概率分布模型,每次交互都是独立计算,无状态存储。这意味着:
没有持续存在的"大脑":模型不会自动保存对话历史
工作记忆性质:上下文窗口更像是临时缓存而非长期记忆
外部存储依赖:AI看似"记住"用户,实际是通过外部数据库检索或显式传入历史记录
关键洞察:AI的"记忆"是工程设计的外挂能力,而非模型原生功能。每一次对话,AI都相当于从零开始。
二、长窗口三大陷阱:为何AI难以真正"记住"?
单纯依靠扩大上下文窗口无法真正解决AI的"健忘症"问题,原因在于三个深层陷阱:
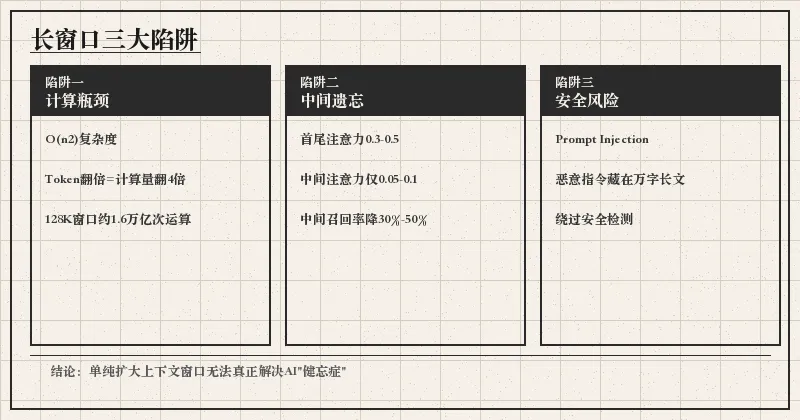
1. 计算复杂度呈N²暴增
Transformer架构的自注意力机制导致计算复杂度为O(n²),当Token数达10万时,运算量激增至100亿次级别:
4K Token上下文:约16亿次运算
32K Token上下文:约100亿次运算
128K Token上下文:约1.6万亿次运算
长上下文会显著增加延迟和计算成本,并非简单的"窗口越大越好"。
2. 中间遗忘效应:模型更关注首尾信息
依据《Lost in the Middle》等研究表明,大语言模型对长序列中的中间信息关注权重显著低于首尾位置:
首尾位置的Token平均注意力权重:约0.3-0.5
中间位置的Token平均注意力权重:约0.05-0.1
在多文档问答等任务中,当关键信息位于长文本中间时,模型的召回准确率可能下降30%-50%。
3. 安全隐患:长文本中的恶意指令注入
长上下文窗口可能被利用进行prompt injection(提示词注入)攻击:
恶意指令可隐藏在大量无关文本中
攻击者利用模型对提示词中某些模式的高响应特性
精心设计的长文本攻击指令防御较弱
三、实用技巧:如何让AI"记得对"?
1. RAG(检索增强生成)
RAG通过外部知识库检索信息,避免将所有内容塞入有限的上下文窗口:
工作原理:用户查询 → 检索相关片段 → 生成答案
优势:可处理海量数据,避免冗余信息干扰
局限:静态性,信息更新需重建索引;检索噪声导致答非所问
2. 记忆压缩技术
动态压缩关键信息,减少冗余:
KV Cache量化:如ZipCache等技术,通过降低键值缓存精度减少内存占用
摘要压缩:使用小模型(如BART)提取核心要点,将长对话浓缩为短文
重要性评分:丢弃注意力得分低的Token,保留高价值信息
3. 分层记忆架构
借鉴人脑记忆分层机制,构建多层次记忆系统:

工作记忆层:短期对话内容,保留最近3轮完整对话
情景记忆层:事件时序图,建立实体/动作间的因果关系
语义记忆层:双轨知识库(向量库+知识图谱),通过仲裁机制处理冲突陈述
程序记忆层:可执行DSL(领域专用编程语言)编译工作流,注入版本号和置信度衰减函数
用时再查资料,避免一次性加载所有信息;摘要关键信息,减少冗余;短期记当前对话,中期记交互,长期存用户画像。
四、AI记忆的未来发展趋势
1. 长期记忆的个性化演进
记忆更新机制:自动识别对话中的新事实,决定是否以及如何更新长期记忆
冲突处理:智能判断新旧信息优先级(如"用户两周前说爱吃辣,今天说不吃"应以后者为准)
遗忘建模:引入Ebbinghaus遗忘曲线,使长期记忆中的信息随时间衰减
2. 用户可控的记忆管理
记忆可视化:用户可以查看AI"记得"自己哪些信息
精确删除:支持按时间、话题、内容片段删除记忆
导出与迁移:允许用户将AI助手的记忆导出或转移到另一服务
3. 隐私与安全内嵌设计
本地存储优先:敏感记忆存储于用户设备,而非云端
GDPR风格擦除接口:支持按标识+时间范围精准删除
端到端加密:确保记忆内容在传输和存储中的机密性
五、用户端记忆管理最佳实践
隐私提醒:主动提供给AI的个人信息(如过敏史、身份证号、内部项目名称)可能被记录或发送至服务端。请避免输入高敏感数据,优先选择本地化或加密方案。
1. 结构化信息模板
将关键信息用固定格式结构化,确保模型优先处理:
## 基本信息- **称呼**:- **时区**:- **语言偏好**:## 专业背景- **职业**:- **技能**:- **工作内容**:## 兴趣爱好-## 沟通偏好- **回复风格**:简洁 / 详细- **技术深度**:入门 / 中级 / 高级- **代码风格**:## 注意事项*任何应该知道的特别事项...*
2. 位置优化策略
首尾预留空间:长对话开始时将用户画像、任务目标放在前几条消息中。
关键信息前置:避免将"用户姓名:张三"埋藏在第50轮对话中间。
定期重申重点:每5-10轮对话重复一次核心约束(如"请记住我不吃辣")。
使用锚点标记:通过###、【】等符号标记重要信息,提高注意力权重。
3. 工具与框架选择
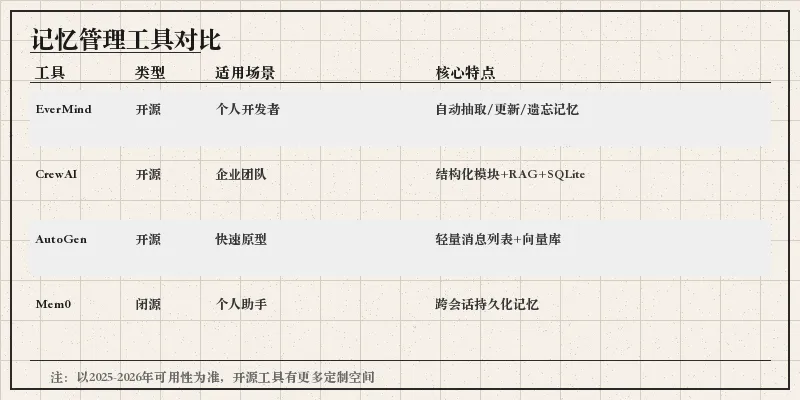
4. 长期记忆维护策略
主动记忆抽取:从对话中识别"候选事实",要求AI总结并存库
关系图谱构建:建立实体间的语义关联(如"川菜→辣→用户忌口")
冲突检测与融合:智能处理新旧信息矛盾,提示用户确认
记忆衰减控制:超过验证时间的记忆询问用户是否仍然有效
六、总结与启示
AI并非存在记忆缺陷,本身不具备原生长期记忆存储能力。大语言模型本质上是无状态的概率预测器,每次交互都是独立计算。
关键是要把重点放首尾、信息结构化,做到"记得对"而非"记不住"。
通过RAG、记忆压缩和分层记忆架构等工程技术手段,结合结构化模板、位置优化和工具框架选择,可以最大化AI的记忆效果。
未来,AI记忆技术将向用户可控、隐私保护、类人遗忘的方向发展。理解这一真相,才能让AI从"一次性工具"进化为可信赖的"长期伙伴"。
AI的记忆不是魔法,而是精心设计的工程解决方案。理解这一真相,才能更有效地与AI协作。
