 夜雨聆风
夜雨聆风Codex 进 Chrome 不是又多了一个插件。它更像一个信号,Agent 开始离开聊天窗口,进入真实工作的现场。
2026 年 5 月 7 日,OpenAI 发了一条很短的消息,说 Codex 现在可以直接在 macOS 和 Windows 的 Chrome 里工作。
如果只把它理解成一个 Chrome 插件,那就太小看这件事了。
我第一反应不是「又多了一个入口」,而是,Agent 终于开始摸到真实工作的现场了。
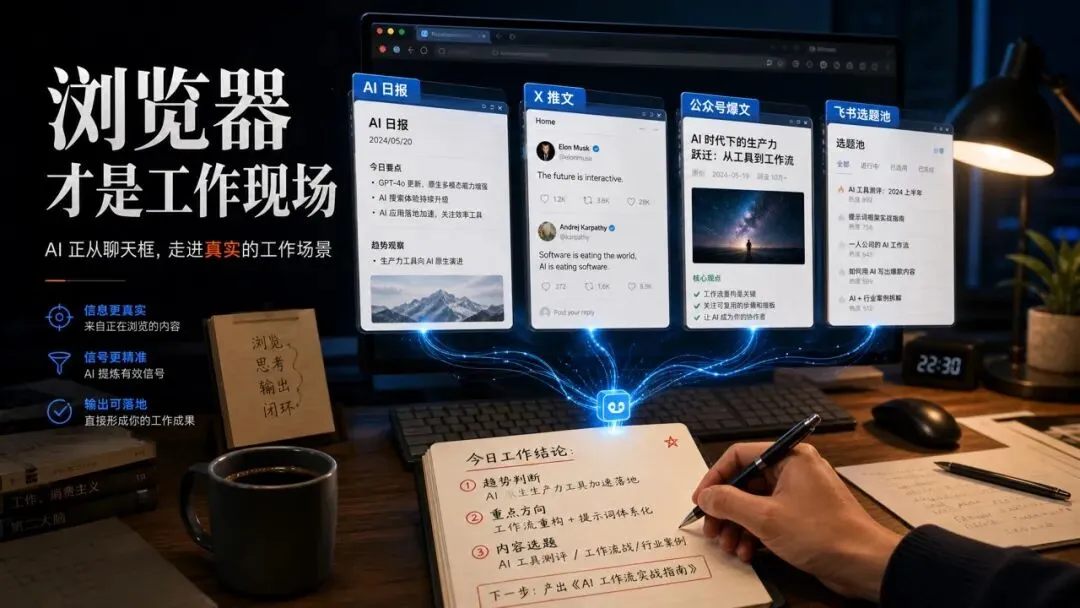
以前我们用 AI,多数时候是在聊天框里问它问题。网页里有什么,我们复制出来;表格里有什么,我们导出来;后台系统里有什么,我们截个图或者描述一下;然后让 AI 站在门外帮我们分析。这个流程当然也能用,但它有一个非常别扭的地方,AI 像一个脑子很好的人,却一直被关在会议室里,只能听我们转述外面的情况。
而大多数真实工作,偏偏不发生在聊天框里。
它发生在浏览器里。
聊天框只是入口,浏览器才是任务发生的地方。
你看 AI 日报,要打开网页。你找公众号爆文,要打开网页。你看 X 上的大佬推文,要打开网页。你查产品文档、点后台、整理飞书 Base、看 Google Sheet、翻 Notion、进 Gmail、进各种内部系统,最后又把这些东西搬回到自己的文章工作流里。
真正消耗人的,不是让 AI 帮你写一段文字,而是在这些页面之间来回切,复制、粘贴、判断、整理、再确认。
所以 Codex 进 Chrome 这件事,在我看来,不是一个产品小更新。
它是在告诉我们,Agent 的下一站不是更漂亮的聊天窗口,而是浏览器这个工作现场。
SECTION 01
为什么是浏览器
我之前搭写作流的时候,这种感觉特别明显。
正文配图:浏览器才是工作现场
比如今天我要写一篇文章,素材可能来自 AI HOT 的日报、公众号爆文、X 推文、OpenAI 文档、飞书多维表格。单看每一个来源,都不复杂。难的是把这些东西串起来,判断哪个能成选题,哪个只是素材,哪个值得沉淀成知识卡,哪个应该暂时跳过。
这个过程很琐碎,也很累。
以前的 AI 帮忙方式,通常是我把链接、截图、文字丢给它,让它帮我分析。现在如果 Agent 能直接进浏览器,它就可以在我授权的范围内自己打开页面,读取页面内容,跨标签页对比,最后把结果填回我指定的表格或文档里。
这个变化听起来没有「模型智商暴涨」那么刺激,但它可能更接近日常生产力真正发生变化的地方。
说得更直白一点,模型再聪明,如果永远只能等你投喂,它还是助手;它能进入工作现场,才开始像 Agent。
这篇文章的核心判断
Agent 不是要变成一个更会聊天的人。它要变成一个能干活的人。而干活的人,迟早要离开聊天框。
SECTION 02
Codex 怎么接进 Chrome
OpenAI 官方文档里对 CodexChrome extension 的描述很具体,它适合用在需要登录态的浏览器任务里,比如 LinkedIn、Salesforce、Gmail 或内部工具。
公开页面、本地开发预览、file-backed preview,官方更建议先用 Codex 内置浏览器;但只要任务需要你的 Chrome 登录状态,就可以考虑用 Chrome 插件。
这个区分很重要。
因为 Agent 进浏览器不是让它随便乱逛,而是让它在一个明确的工作边界内,替你完成那些必须在浏览器里发生的事。
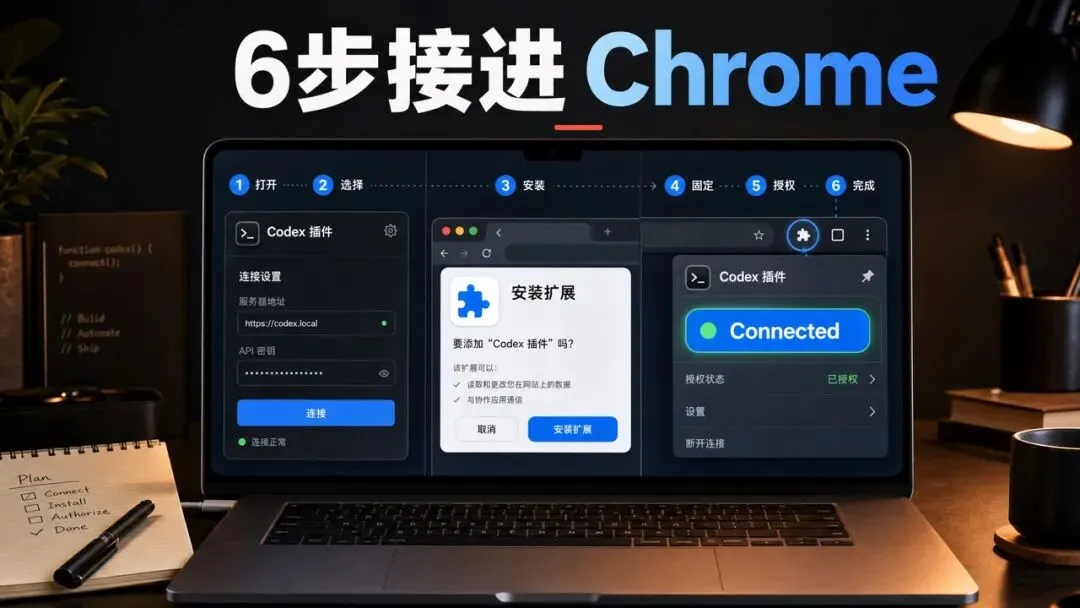
具体步骤很简单。
正文配图:Codex 接入 Chrome 的 6 步流程
1.打开 Codex App,找到 Plugins。
2.在 Plugins 里添加 Chrome plugin。
3.按引导安装或连接 Chrome 扩展。
4.接受 Chrome 弹出的权限请求。
5.打开 Chrome,在工具栏扩展图标里点开 Codex。
6.如果看到 Connected,就说明连接成功。
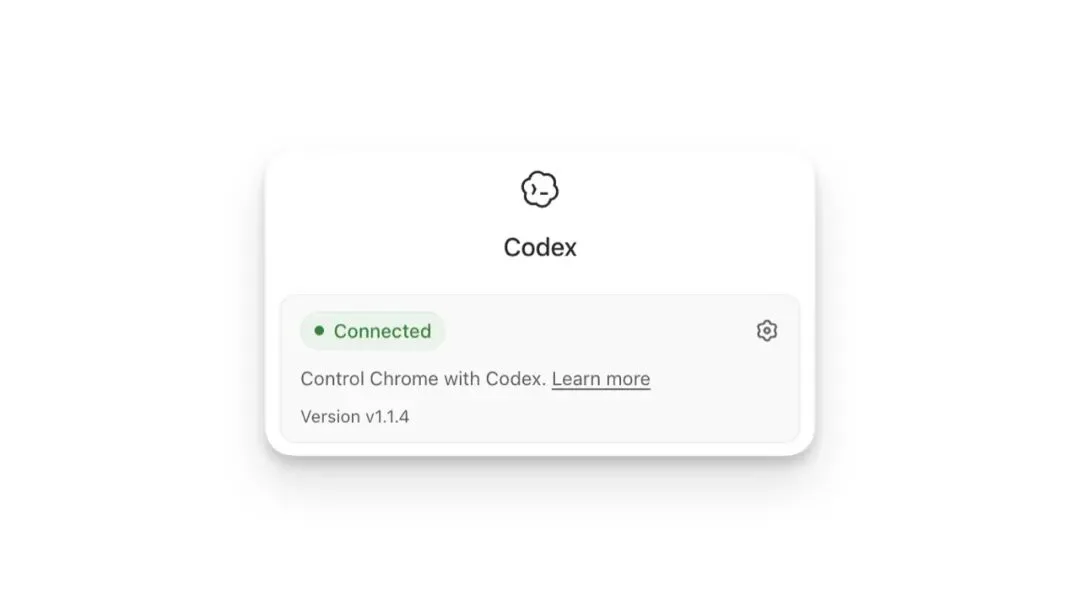
图 1:CodexChrome 扩展显示 Connected,图片来自 OpenAI 官方文档
权限这里要稍微认真一点。Chrome 会提示比较大的权限范围,比如读取和更改网站数据、读取浏览历史、管理下载、与本机应用通信、管理标签页分组等。听起来吓人,但原因也很简单,它要真的操作浏览器,就必须拿到足够的浏览器能力。
权限不是让你闭眼全给。
我的建议是,把它当成一个可以进入工作现场的实习生。你会让实习生进办公室,但不会把财务密码写在白板上;你会让它整理资料,但不会让它无确认地提交付款。Codex 进 Chrome 也是一样,先给明确任务,再看它要访问哪个网站,再决定是否允许。
连接成功后,回到 Codex,新开一个线程。官方文档建议安装完成后新开线程,因为有些连接状态需要在新线程里重新建立。你可以在 prompt 里直接 @Chrome。
比如:
PROMPT
@Chrome 打开我今天的 AI 素材网页,把页面里的 10 条更新按「事件、为什么重要、适合写什么」整理成表格。
或者更贴近我的写作流:
PROMPT
@Chrome 打开 AI HOT 今日 AI 日报和我的飞书选题池,把今天适合写公众号的 3 个选题整理出来。每个选题要包含核心问题、读者收益、参考链接和事实核查风险。
再比如,如果我要把 X 推文情报接进选题池,我会这么下任务:
PROMPT
@Chrome 打开这几条 X 推文链接,分别判断它们属于反直觉观点、工具体验、行业判断还是技术辩论。只保留能写成公众号长文的内容,把理由写清楚,并给我 3 个不撞标题的中文选题。
这里的重点不是 prompt 写得多漂亮,而是任务要窄。
不要一上来就让它「帮我运营整个账号」。这种任务太大,也不利于你审查。更好的方式是让它完成一个浏览器里的具体动作,比如读一个页面、对比两个页面、提取表格、填写一条记录、检查一个后台配置。
SECTION 03
关键不是点按钮
官方文档还提到,Codex 在 Chrome 里工作时,会把一个线程的浏览器任务放在 Chrome tab group 里。
这个设计我觉得很有意思。
因为浏览器任务最烦的就是标签页混乱。你让 Agent 开了十几个页面,最后不知道哪个是它开的,哪个是你自己的。放进 tab group,至少说明这件事不是把浏览器当一次性窗口,而是在把「一个任务的网页现场」组织起来。
接下来是网站权限。

正文配图:浏览器权限边界与操作分级
默认情况下,Codex 在接触一个新网站前会问你。你可以只允许当前对话使用这个网站,也可以把这个 host 加到 always allow,或者直接拒绝。这个地方不要图省事一律 always allow。
我的做法会比较保守,常用的公共资料站、官方文档站,可以考虑长期允许;带登录态的工作后台、邮箱、飞书、支付、客户资料,尽量按任务临时允许。
这不是胆小。
这是 Agent 时代的基本卫生习惯。
浏览器里有太多东西是你平时感觉不到敏感的。历史记录、搜索词、内部 URL、已登录页面、页面里的提示词注入,都可能被带进上下文里。OpenAI 文档里也专门提醒,浏览器历史可能包含敏感遥测、内部 URL、搜索词和跨设备活动;如果允许 Codex 读取历史,相关历史条目可能成为它使用的上下文。
我的理解很简单,能不用历史就不用历史,能只读当前页面就只读当前页面。
还有一个很实用的小设置,文件上传。
如果你的 Chrome 任务需要把本机文件上传到网页,比如上传一张图、一个 CSV、一个 Markdown,官方文档建议在 Chrome 扩展详情里打开 Allow access to file URLs。路径是 Chrome 工具栏扩展图标,Manage Extensions,找到 Codex,点 Details,然后打开这个开关。
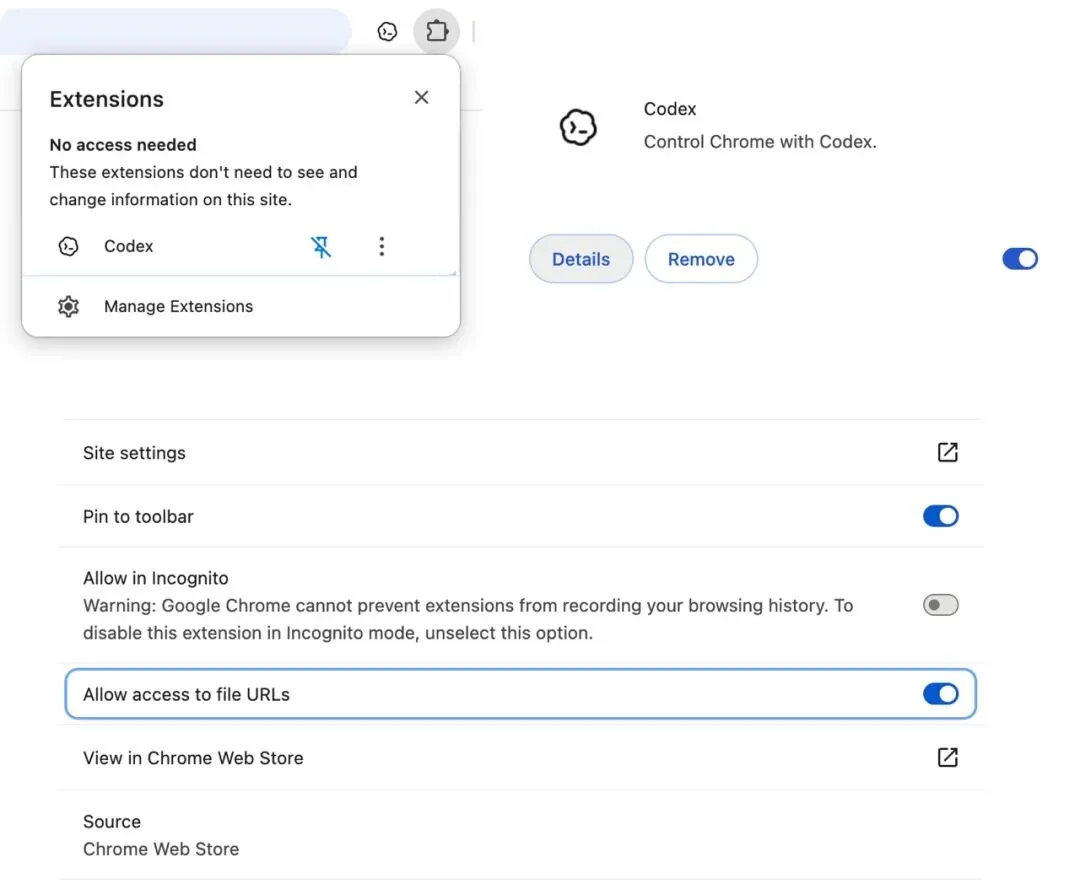
图 2:在 Chrome 扩展详情里允许 Codex 访问 file URLs,图片来自 OpenAI 官方文档
这个设置我建议平时不用就关着,需要上传本地文件时再开。不是因为它一定危险,而是没有必要长期打开所有门。
SECTION 04
怎么放进写作流
我拿自己的日常写作举例。

正文配图:AI HOT、公众号爆文和 X 推文进入选题池
以前我选题,大概是这样:先刷 AI HOT,看今天有没有大事件;再看公众号爆文,看大家都在用什么角度;再看 X,看海外一线作者和产品团队在讨论什么;然后开飞书,把素材归档,打标签,写判断,生成选题。
这套流程听起来很理性,实际执行起来很容易散。因为你在每一个页面里看到的东西都不一样,AI HOT 是事件,公众号是叙事,X 是信号,飞书是结构。人脑要在这些格式之间来回切换,最容易疲劳,也最容易偷懒。
Agent 进 Chrome 后,可以把它变成一个更自然的流程。
第一步,让它只读今天 AI HOT。
PROMPT
@Chrome 打开今天的 AI HOT 日报,只看 Agent、Codex、浏览器自动化、AI 写作流相关内容。每条只提取四个字段:事件是什么,为什么值得注意,能不能写公众号,事实核查风险是什么。
第二步,让它对齐 X 推文情报。
PROMPT
@Chrome 再打开我今天保存的 X 推文情报,把和上面主题重合的推文找出来。不要复述推文,帮我判断哪些推文能变成文章里的观点或案例。
第三步,再让它进飞书。
PROMPT
@Chrome 打开我的飞书 Base,把最值得写的两个选题填进选题池。字段按现有表结构来,不确定的地方留空,不要乱填。
这个流程的重点,是让 Agent 做「跨页面搬运与初筛」,而不是让它替你决定最后写什么。最后的判断还得人来。
比如它可以告诉我,Codex 进 Chrome、Sam Altman 说 AI 应该帮助开发者进化、OpenAI 文档强调 Chrome 适合登录态任务,这三件事可以合成一个选题。但文章真正的主线,仍然应该是我自己的判断:浏览器是工作现场。
这就避免了一个常见问题,AI 文章很容易写成产品发布复述。
什么「OpenAI 推出了 CodexChrome 插件,该插件能够提升用户效率」。这种句子看起来没错,但它没有灵魂,也没有人的判断。读者看完只会觉得,哦,又一个工具。
我真正想写的是另外一件事:为什么 Agent 会先接管网页任务。
因为网页是现代工作的公共地面。
不管你做内容、做销售、做运营、做产品,还是做程序员,最后都有大量工作落在浏览器里。聊天框只是一个入口,浏览器才是任务发生的地方。谁能进入浏览器,谁就能接触到真实流程;谁只能等人类复制粘贴,谁就永远慢半拍。
SECTION 05
我的使用边界
这不代表你应该把一切都交给它。
我现在比较推荐的使用边界是三条。
第一,让它读公开网页、官方文档、素材页,风险较低,价值很高。比如产品更新、帮助文档、榜单、日报、文章列表。
第二,让它操作登录态但低风险的页面,比如整理飞书表格、查 Gmail 里的公开通知、读取某个内部 dashboard。这里要有授权确认,也要检查它写入的内容。
第三,涉及金钱、客户隐私、账号权限、删除数据、批量提交的页面,先别让它直接动手。可以让它看,让它给步骤建议,但最后点击提交的人最好还是你。
Agent 进入浏览器之后,最重要的能力不是「它可以替我点按钮」。
按钮谁都会点。
真正重要的是,它开始理解页面和页面之间的关系。它知道这个网页是素材源,那个网页是表格,另一个网页是官方证据,再一个网页是发布后台。它可以把这些东西串成一个任务,而不是一个个孤立的对话。
这才是我觉得 Codex 进 Chrome 有意思的地方。
它不只是一个插件,它是 Agent 从聊天框走向真实工作流的一小步。这个小步不炫酷,不像发布一个新模型那样让人刷屏,但对真正每天干活的人来说,可能更重要。
以后我们衡量一个 Agent 好不好,可能不只是看它会不会写代码、会不会总结、会不会生成标题,而是看它能不能进入你的真实工作现场,能不能理解你的工作流,能不能在你授权的范围内,把那些琐碎但必要的步骤接过去。
我现在越来越觉得,AI 不是要变成一个更会聊天的人。
它要变成一个能干活的人。
而干活的人,迟早要离开聊天框。
