 夜雨聆风
夜雨聆风
点击“蓝字”,关注我们
最近要做客户的阶段性总结,我既不想手搓函数,也不想把飞书多维表格的数据看板截图出来,“如何用AI做数据分析”变成了我的刚需。
很多人觉得把表格丢给大模型,几秒钟出一份漂亮报告就是高效。我必须泼盆冷水:AI做数据分析,图表可能很漂亮,但结论很可能是“编”出来的。
今天不吹AI有多强,只聊实战中的“血泪教训”:AI做数据分析到底有哪些深坑?面对准确、深度、安全这三大核心诉求,我们该如何选择最优解?
第一性原理:为什么AI做数据分析会“翻车”?
从第一性原理来看,AI(大语言模型)本质是一个语言预测系统,而非计算引擎或审计工具。这就决定了它在处理数据时存在以下根本性问题:
计算幻觉:它是基于概率预测下一个字符,而不是真的在算数。面对10万行数据,它可能只看了局部样本就给你一个“自信”的假结论。
结果不稳定:同一份数据,今天和明天的分析结论可能完全不同。
不理解业务逻辑:它不理解字段间的业务关联,常会自作主张地进行假设。
基础算术错误:嵌套复杂的运算时,AI的表现远不如一个Excel公式。
编造数据:遇到数据缺失,它可能会悄悄填入“合理”的伪造值。
缺乏统计学常识:哪怕样本量不足,它也会一本正经地输出所谓的“趋势洞察”。
数据安全风险:企业敏感数据上传到公有云平台,存在极大的合规隐患。
我的解决方案
优先保证安全 —— 本地 Python + AI 辅助
核心逻辑:需求转代码,计算在本地
对于涉及销售额、薪酬等极其敏感的数据,绝对不能上传云端。
操作流程:
第一步
把以下命令发给:Codex/TRAE 等 Agent
安装 Python 加装的专业工具包两个Python的小插件pandas:负责处理表格数据openpyxl:负责让 pandas能读 xlsx Excel 文件
第二步
输入一下命令,在电脑中找到要分析的文件并打开import pandas as pdfrom pathlib import Pathfile_path = Path("/实际路径/表格名字.xlsx")print(file_path.exists())df = pd.read_excel(file_path)print("--- 字段信息 ---")df.info()print("\n--- 数据前3行展示 ---")print(df.head(3))
第三步
输入你需要分析的维度,此部分自然语言即可,不满意可以反复调试
我需要几个分析维度的数据,你单独做一个sheet,做以下分析,截止到4月30日,发文媒体总量,发文媒体的饼图,占比的百分比,发文的日趋势,我希望是日发文总量的折线图,以及分发文媒体的日维度的发文媒体的数量折线图日发文趋势的折线图上标注发文数量的数字最终部分效果,比手搓函数效率提升N倍
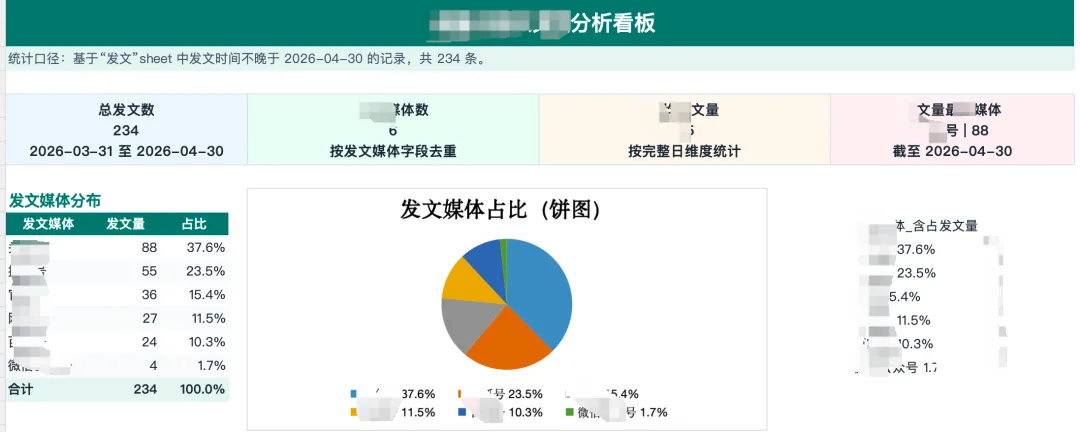
如果生成极其精美的、带有复杂计算逻辑的最终交付版 Excel,可以安装xlsxwriter ,它是高级格式与函数专家,它具备更复杂的 Excel 功能(比如条件格式、复杂的公式嵌套、甚至写入 Excel 图表),这个插件比 openpyxl 更强大且速度更快。
安装命令
pip install xlsxwriter优势:数据始终留在你的电脑里,计算由Python引擎执行而非AI预测。你不需要精通写代码,只要能看懂AI生成的逻辑即可。

AI做数据分析,不是要替代所有的传统工具,而是要实现能力重组:
AI擅长的是:翻译需求、生成代码、构建逻辑、撰写报告。
传统工具擅长的是:稳定计算、数据存储、结果呈现。
让AI写公式/代码,让Excel/Python做计算。这是目前保证数据分析准确、深度与安全的唯一捷径。
数据洞察的深度挖掘是一个更高级的话题,如果连基础准确性都无法保证,洞察就是空中楼阁。关于如何从准确数据中提炼商业价值,我们有机会再详细拆解。
