 夜雨聆风
夜雨聆风从工具化治理到智能治理闭环
核心观点 • AI 的价值不是提供自然语言问答,而是通过证据推理重构数据治理的运行机制 • AI 生成候选,人类确认生效;AI 给出推理,系统保留证据 • 五大应用场景:语义增强、同义词治理、规则推荐、资产关系发现、健康分评估 • 五维健康分模型让治理从经验判断走向量化运营 • AI 是治理引擎,不是治理主体 |
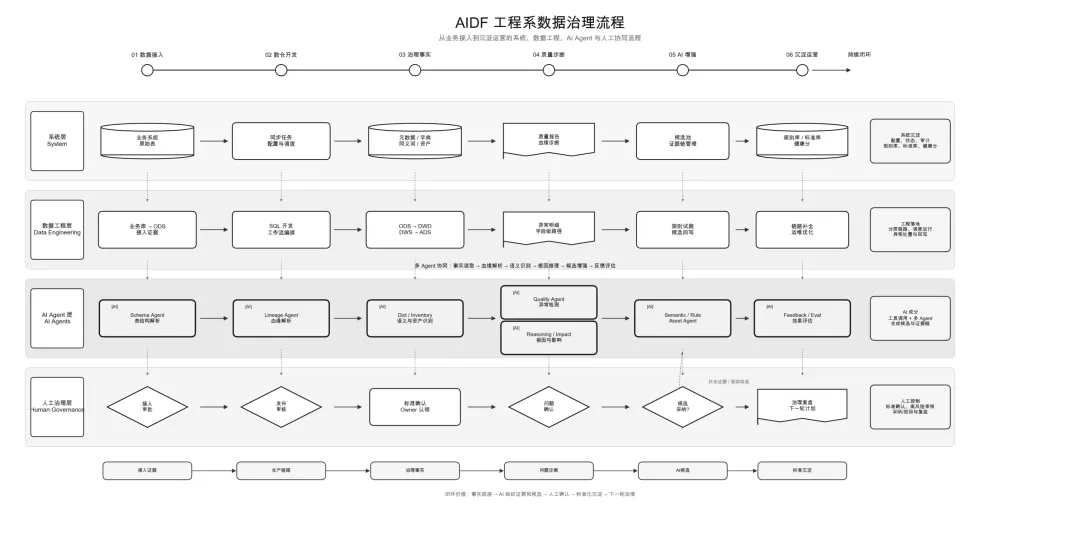
一、数据治理的痛点:“有表无谱”的困境
企业数据平台的表数量在持续增长,但表与业务对象之间的关系却越来越模糊。业务系统中的原始表是否已经进入 ODS,ODS 是否被加工成 DWD,是否继续形成 DWS 和 ADS,往往依赖开发人员的经验判断。
这带来了四个典型问题:
“有表无谱” — 大量资产存在但不可解释;
“一物多名” — 同一业务概念在不同系统中存在多种命名;
“规则滞后” — 质量规则依赖人工配置,无法及时响应新字段;
“无法度量” — 治理效果缺少可持续的评估指标。
传统治理依赖人工梳理和周期巡检,能解决早期的规范化问题,但在复杂数据环境中很容易出现治理滞后。AI 的引入,正是为了解决这一核心矛盾。
二、AI 治理不是什么:澄清常见误区
提到 AI 数据治理,很多人的第一反应是“智能问答”或“SQL 生成”。但这并不是 AI 在数据治理中的核心价值。
AI 不是问答入口,不是 SQL 生成器,不是报表解释工具。它是一种基于证据的治理推理能力。
真正有价值的方向,是以元数据、血缘、字典、同义词、质量规则和资产盘点为事实基础,让 AI 能够围绕真实的平台数据进行综合分析,而不是凭空进行泛化解释。换句话说,AI 的角色不是“替代治理人员”,而是“帮助治理人员更快发现问题、更好解释问题”。它的每一个结论都应该有证据支撑,每一个建议都应该经过人工确认。
三、AI 治理的核心:证据约束下的推理增强
当平台发现某个 ADS 指标异常时,AI 可以沿 ADS → DWS → DWD → ODS → 业务源表追踪血缘,结合任务状态、质量规则、字段同义词和历史异常记录,判断异常来源。问题可能来自同步缺失、口径不一致、字段含义漂移或规则覆盖不足。
在同义词治理中,AI 可以分析字段名、注释、上下游血缘和业务域,判断 usr_id 是否应归并为“用户唯一标识”。但最终是否合并,仍由治理人员确认。
AI 生成候选,人类确认生效;AI 给出推理,系统保留证据;AI 推动闭环,但不越权执行。
这就是 AI 治理的核心定位:发现候选问题、解释问题原因、给出证据链、生成治理建议、推动人工确认、记录反馈并持续优化。
四、五大应用场景
AI 在数据治理中的应用,可以概括为五个核心场景。每个场景都遵循同一的原则:AI 负责发现和推荐,人工负责确认和发布。
1. 字段语义增强
大多数治理问题最终都会落到字段层面:字段叫什么、表示什么业务概念、是否存在标准命名。AI 可以结合字段名、注释、数据类型和血缘关系,为字段生成语义候选。例如,device_sn 可以被识别为“设备序列号”,并关联多种同义表达。
2. 同义词治理
解决“一物多名”问题。user_id、uid、usr_id 可能都指向“用户唯一标识”,但是否完全等价需要结合业务域和使用场景判断。AI 输出时不仅要给出是否同义,还要说明适用范围、证据链和置信度。
3. 质量规则推荐
让规则配置从“人工经验驱动”升级为“语义理解驱动”。主键字段推荐唯一性和非空校验,金额字段推荐非负和波动校验,时间字段推荐新鲜度监控。AI 推荐规则时同时输出建议阈值、适用范围和推荐理由。
4. 资产关系发现
关注数据资产之间的结构性关系。AI 可以识别“断链资产”(数据进入某一层后没有继续向下游服务业务)和“孤儿资产”(存在但缺少明确业务归属的表),把资产盘点从静态清单提升为动态结构图。
5. 健康分评估
对资产完整性、数据质量、语义规范、AI 治理效果和运营闭环进行综合评价,形成面向业务域的健康分。健康分不是简单的平均值,而是结合权重、风险等级和业务重要性的综合判断。AI 还可以给出“为什么是这个分数”的治理解释。
五、五维健康分模型
没有评估体系,数据治理就难以持续。AIDF 提出五维健康分模型,将治理活动从经验判断转化为可量化、可追踪、可比较的运营体系。
维度 | 权重 | 核心指标 |
资产完整性 | 30% | 业务到 ODS 覆盖率、分层贯通率、孤儿表数量 |
数据质量 | 30% | 完整性、唯一性、一致性、及时性、稳定性 |
语义规范 | 20% | 标准词覆盖率、同义词确认率、字段注释完整率 |
AI 治理效果 | 10% | 建议采纳率、验证准确率、人工驳回率 |
运营闭环 | 10% | P0/P1 问题关闭率、平均关闭周期、复发率 |
这五个维度的设计逻辑是:资产完整性和数据质量占据最高权重,因为它们直接反映数据是否可信、可用;语义规范是跨团队协作的基础;AI 治理效果确保 AI 真正提升治理质量;运营闭环保证问题能从发现走向关闭。
健康分的目标不是制造一个绝对精确的数字,而是建立一套稳定的评价语言,让平台能够回答三个问题:当前数据资产是否健康,主要风险集中在哪里,治理工作是否正在产生改善。
六、风险与边界
AI 数据治理并非万能的。在落地过程中,我们必须清醒地认识到它的风险和边界。
● 幻觉风险:AI 可能基于不完整上下文生成看似合理但错误的结论,必须要求证据链和置信度。
● 权限风险:数据治理涉及敏感字段和用户隐私,AI 调用必须遵循最小权限和脱敏原则。
● 过度自动化风险:同义词合并、规则发布、任务变更等动作不能由 AI 直接执行,应通过人工确认。
● 责任边界:AI 可以建议,但不能成为最终责任主体。治理责任仍属于数据 Owner 和业务域负责人。
● 成本风险:大模型调用和检索任务需要成本控制,应优先处理高价值资产和高风险问题。
边界原则:AI 只生成候选,不直接发布正式治理资产;所有结论必须带证据和置信度;涉及敏感数据的动作必须走人工审核。
七、结语:AI 是治理引擎,不是治理主体
最终愿景不是让 AI 取代数据治理团队,而是让组织拥有持续治理数据的智能能力。AI 的价值在于把数据治理变成一个持续学习、持续评估、持续优化的智能系统。
