 夜雨聆风
夜雨聆风
中国 AI 实验室未必在原创科学范式上领先美国,但它们在执行力、工程化、组织纪律、学生人才密度、开源反馈、技术自主意识上,形成了一套非常适合大模型时代的追赶机制。一个美国人关于中美 AI 差别的田野调查:从模型到商业生态(原文附后)。
Nathan Lambert 是美国 AI 研究机构 Ai2 的研究员,也是 AI 领域知名通讯《Interconnects》的作者,长期关注大模型、开放模型与前沿 AI 实验室生态
最近,他访问了 月之暗面、智谱、美团、小米、Qwen、蚂蚁 Ling、01.ai 等中国主流 AI 实验室,并写下了一篇观察笔记,试图从内部视角理解中国 AI 为什么能快速追赶。
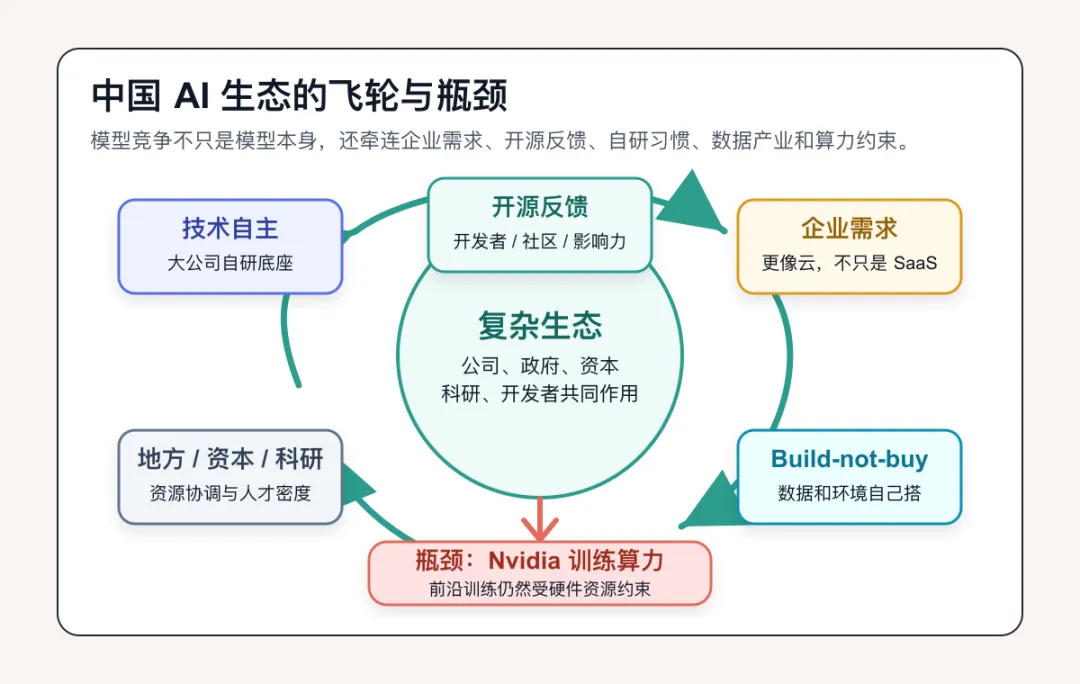
产业层面:中美 AI 公司最大的差别,不只是模型,而是商业生态。
他认为,今天 AI 公司不是单纯做模型,而是要同时处理资金、算力、数据、产品、开发者生态和商业落地。
在美国,OpenAI、Anthropic 这类公司的生态已经比较清楚:融资、云计算、数据采购、企业客户、开发者工具、闭源 API、订阅收入,形成一整套商业逻辑。
但中国的 AI 生态不完全一样。
作者总结了几个产业差异。
1.中国企业对 AI 的真实需求正在涌现,但较为初级
外界常说中国企业不愿意为软件付费,所以中国 AI 市场可能比美国小。作者认为这个判断太粗糙。
中国 SaaS 市场确实没有美国强,但中国云市场很大。问题在于,企业 AI 支出未来更像 SaaS,还是更像云?
如果更像 SaaS,市场可能受限;如果更像云,那空间很大。
作者的现场感受是,中国企业对 AI 工具的需求正在靠近云计算逻辑,而不是传统 SaaS 逻辑。也就是说,企业未必愿意为一个标准软件订阅付费,但如果 AI 嵌入业务基础设施、算力、开发、生产流程里,就可能形成大规模支出。
说白了,AI 来了,中国的 SaaS 也还是不行。还是云的逻辑。
2.中国开发者很迷 Claude
这是文章里很有意思的一点。
作者说,很多中国 AI 开发者都在用 Claude,尤其是在编程场景里。虽然 Claude 在中国名义上不可用,但大家依然很关注它,也会想办法使用它。
这说明一个问题:中国技术人非常务实。只要工具好用,就会用。过去“不愿意买软件”的习惯,未必能阻止 AI 工具消费和推理需求增长。
也就是说,AI 可能会改变中国企业和开发者对软件价值的判断。
3.中国公司有很强的“技术自主”意识
作者认为,很多西方人不理解为什么美团、蚂蚁、小米这些公司都要做自己的大模型。(美团的 Longcat,蚂蚁的 ling和 Ring-1T,小米的 mimo)
在美国,很多类似公司可能会直接买 OpenAI 或 Anthropic 的服务。但在中国,大公司更倾向于掌握自己的技术底座。
这背后不是简单的“跟风”,而是中国科技公司的深层逻辑:关键技术最好自己掌握,尤其是 LLM 这种可能成为未来产品基础设施的能力。
这个他不理解很正常,你看中国的大公司都会自己做企业 IM 就知道了。
所以美团、蚂蚁、小米做模型,不一定是为了成为下一个 OpenAI,而是为了控制未来产品栈。
这和中国制造业、互联网公司长期的“自研”和“全栈控制”倾向有关。
4.中国模型开源更多是出于实用主义
作者认为,中国公司开源大模型,不一定是因为它们有西方开源社区那种意识形态式信仰,而是因为开源很实用。
开源可以带来开发者反馈,可以提升模型影响力,可以强化生态,可以让外部社区帮助发现问题,也可以服务内部产品迭代。
所以中国 AI 圈的“open-first”更像一种工程和生态策略,而不是纯粹的价值观选择。
这点对理解 DeepSeek、Qwen、GLM、Kimi、MiniMax 等中国模型都很关键。
5. 政府支持确实存在,但不确定有多大
他说,很多人会认为中国政府在推动开源大模型竞赛。实地访问后,他感觉政府帮助是真实存在的,但形式并不清晰。
可能包括办公场地、审批便利、地方政府招商、资源协调等。但他没有看到足够证据表明最高层政府在直接干预模型技术路线。
换句话说,他不认为中国 AI 模型是一个高度集中、统一指挥的国家工程。它更像是地方政府、科技公司、资本、科研机构、开发者共同作用下形成的复杂生态。
这个对咱们来说很容易看清,对外国人来了几天就能把这个事情搞明白也挺不简单的。
6.中国的数据产业相对不成熟
美国前沿实验室会花很多钱购买高质量训练环境、RL 环境、数据服务。作者原本想知道中国是否也有类似的数据供应链。
他的观察是,中国相关数据产业质量相对不足,很多实验室更愿意自己做数据和训练环境。
这和前面说的“build-not-buy”逻辑一致:中国公司倾向于自己搭,而不是大量外包购买。
这既是优势,也是劣势。
优势是能力沉淀在内部,成本可能更可控。劣势是生态分工不成熟,很多团队要重复造轮子。
7.中国实验室依然非常缺 Nvidia 芯片
作者明确说,Nvidia 仍然是训练大模型的黄金标准。中国实验室普遍希望获得更多 Nvidia 算力。
华为等国产芯片在推理场景里被积极评价,很多实验室也能用到华为芯片。但在训练前沿模型这件事上,Nvidia 仍然是最重要的资源。
所以中国 AI 的上限依然受到算力约束。
AI 时代真正重要的竞争力,是“组织能不能把大量细碎工作系统化”。
这和用户研究团队用 AI 升级也很像。要把访谈、转写、编码、洞察、报告、知识库、业务反馈这些环节,变成一套可复用、可迭代、可协作的系统。
这也是这篇文章对中国 AI 实验室的底层评价:它们未必每一步都最原创,但它们非常擅长把复杂系统跑起来,并且越跑越快。
Nathan Lambert May 07, 2026
Staring out the window on a new, high-speed train from Hangzhou to Shanghai I’m gifted with views of dramatic ridgelines speckled with wind turbines that are silhouetted against the setting sun. The mountains cast a backdrop to a mix of spanning fields and clustered skyscrapers. I’m returning from China with great humility. It’s a very warming, human experience to go somewhere so foreign and be so welcomed. I had the honor of meeting so many people in the AI ecosystem who I knew from afar, and they greeted me with big smiles and cheer, reminding me how global my work and the AI ecosystem is.
Interconnects AI is a reader-supported publication. Consider becoming a subscriber.
Subscribe
The mentality of Chinese researchers
The Chinese companies building language models are set up as the perfect fast-followers for the technology, building on long-standing cultural traditions in education and work, along with subtly different approaches to building technology companies. When you look at the outputs, the latest, biggest models enabling agentic workflows, and the ingredients, excellent scientists, large-scale data, and accelerated computing, the Chinese and American labs look largely similar. The lasting differences emerge in how these are organized and conditioned.
I’ve long thought that a reason that the Chinese labs are so good at catching up and keeping up with the frontier is that they’re culturally aligned for this task, but without talking to people directly I felt like it wasn’t my place to attribute substantial influence to this hunch. Speaking with many wonderful, humble, and open scientists at the leading Chinese labs has crystallized a lot of my beliefs.
So much of building the best LLMs today comes down to meticulous work across the entire stack, from data to architecture details and RL algorithm implementations. All points of the model can give some improvements, and fitting them in together is a complex process where the work of some brilliant individuals needs to get shelved in favor of the overall model maximizing a multi-objective optimization.
Where American researchers are obviously also brilliant at solving the individual components, there’s more of a culture of speaking up for yourself in the U.S. As a scientist, you’re more successful when you speak up for your work and modern culture is pushing the new path to fame of “leading AI scientists”. This results in direct conflict. The Llama organization is heavily rumored to have collapsed under the political weight of these interests embedding themselves in a hierarchical organization. I’ve heard of other labs saying that it can be needed to pay off a top researcher to get them to stop complaining about their idea not making it in the final model. Whether or not that’s exactly true, the idea is clear. Ego and desires for career advancement do get in the way of making the best models. A small, directional shift in this sort of culture between the U.S. and China can have a meaningful impact on the final outputs.
Some of this has to do with who is building the models in China. There’s an immediate reality at all of the labs that a large proportion of the core contributors are active students. The labs are quite young, and it reminds me of our setup at Ai2, where students are seen as peers and directly integrated in the LLM team. This is incredibly different from the top labs in the US, where the likes of OpenAI, Anthropic, Cursor, etc. simply don’t offer internships. Other companies like Google nominally have internships related to Gemini, but there’s a lot of concern about whether your internship will be siloed and away from anything real.
To summarize how the slight change in culture can improve the ability to build models:
More willingness to do non-flashy work in order to improve the final model,
People new to building AI can be free of prior phases of AI hype cycles, allowing them to adapt to the new modern techniques faster (in fact, one of the Chinese scientists I talked to really actively attached to this strength),
Less ego enabling org charts to scale slightly, as there’s less gamifying the system, and
Abundant talent well-suited to solving problems with a proof of concept elsewhere, etc.
This slight inclination towards skills that complement building today’s language models stands in contrast to a known stereotype that Chinese researchers tend to produce less creative, field-spawning, 0-to-1 academic style research. Among the more academic lab visits on our trip, many leaders talk about cultivating this more ambitious research culture. At the same time, some technical leaders we talked to were skeptical about whether such a rewiring in the approach to science is likely in the near term, because it’ll take a redesign of the education and incentive systems that is too big to happen within the current economic equilibrium. This culture seems to be training students and engineers that are excellent at the LLM building game. They also, of course, have an extremely abundant quantity.
These students told me about a similar brain drain happening in China as in the U.S., where many who previously considered academic paths now intend to stay in industry. The funniest quote was from a researcher who was interested in being a professor to be close to the education system, but remarked that education is solved with LLMs – “why would a student talk to me!”
The students have a benefit of coming at LLMs with fresh eyes. Over the last few years we’ve seen the key paradigm of LLMs shift from scaling MoE’s, to scaling RL, to enabling agents. Doing any of these well involves absorbing an insane amount of context quickly, both from the broader literature and the technical stack at your company. Students are used to doing this and excited to humbly drop all presumptions about what should work. They dive in head first and dedicate their life to getting the chance to improve the models.
These students are also so magically direct and free of some of the philosophical chatter that can distract scientists. When asking questions on how they feel about the economics or long-term social risks of models, far fewer Chinese researchers have sophisticated opinions and a drive to influence this. Their role is to build the best model.
This difference is subtle, and easy to deny, but it is best felt when having long conversations with an elegant, brilliant researcher who can clearly communicate well in English, basic questions on more philosophical aspects of AI hang in the air with a simple confusion. It’s a category error to them. One researcher even quoted the famous Dan Wang premise of China being run by engineers, relative to the lawyers of the U.S. when probing in these areas, to emphasize their desire to build. There’s no track in China that systematically enables the growth of star power for Chinese scientists, akin to mega mainstream podcasts like Dwarkesh or Lex.
Trying to get Chinese scientists to comment on the coming economic uncertainty fueled by AI, questions beyond the capabilities of simple AGI, or moral debates on how models should behave all served to capture the upbringing and education of these scientists (edited1). They are extremely dedicated to their work, but have grown up in a system where debates and opinions on how society should be structured and changed are not encouraged.
Zooming out — Beijing especially felt much like the Bay Area, where a competitive lab is a short walk or Uber away. I got off a flight and stopped by Alibaba’s Beijing campus on the way to the hotel. Then, in 36 hours we went to all of Z.ai, Moonshot AI, Tsinghua University, Meituan, Xiaomi, and 01.ai. Travel by Didi is easy, and if you select an XL in China you’re often paired with electric mini vans that have massage chairs. We asked the researchers about the talent wars, and they said it’s very similar to what we’re experiencing in the U.S. It’s normal for researchers to bounce around, and much of where people choose to go is based on the best current vibes.
In China, the LLM community feels far more like an ecosystem than battling tribes. Across many off the record conversations, it’s nothing but respect for peers. All of the Chinese labs fear Bytedance with their popular Doubao model, which is the only frontier closed lab in China. At the same time, all of the labs have massive respect for DeepSeek as the lab with the best research taste in execution. When you meet with lab members off the record in the States, sparks fly quickly.
The most striking part of the humility of Chinese researchers is how they also often shrug on the business side, saying it’s not their problem, where everyone in the U.S. seems to be obsessed with various ecosystem-level industrial trends, from data sellers to compute or fundraising.
Where China’s AI industry differs (and matches) the Western labThe thing that makes building an AI model today so interesting is that it’s not just about getting a group of great researchers in one building together to produce an engineering marvel. It used to be this, but to sustain AI businesses, the LLMs are becoming a mix of building, deploying, funding, and getting adoption for this creation. The leading AI companies exist in complex ecosystems that supply money, compute, data and more in order to keep pushing the frontier.
The integration of these various inputs to creating and sustaining LLMs is fairly well conceptualized and mapped for the Western ecosystem, as typified by Anthropic and OpenAI, so finding big differences in how the Chinese labs think about it points at where the different companies can be making meaningfully different bets on the future. Of course, these futures can be heavily dictated by the constraints on funding and/or compute.
I’ve documented the biggest “AI Industry” level take-aways from talking to these labs:
Early signs of domestic AI demand. There’s a much-touted hypothesis that the Chinese AI market will be smaller because Chinese companies don’t tend to pay for software – thus, never unlocking a giant inference market supporting labs. This is only true for software spend that maps to the SaaS ecosystem, which is historically tiny in China, where on the other hand there is obviously still a large cloud market in China. A crucial unanswered question – one which the Chinese labs themselves debate – on if spending for AI in the enterprise tracks the SaaS market (small) or the cloud market (fundamental). On net, it feels like AI is trending closer to the cloud, and no one was actively worried about a market growing around the new tools.
Most developers are Claude-pilled. Most of the AI developers in China are obsessed with Claude and how it’s changed how they build software, despite Claude nominally being banned in China. Just because China has historically been hesitant to buy software does not give me the impression that there won’t be a massive surge in inference demand. Chinese technical staff are so practical, humble, and motivated – a fact that seems stronger than any commitment to previous habits in not spending.Some Chinese researchers mention building with their own tools, such as the Kimi or GLM CLIs, but all of them mention building with Claude. There were also surprisingly few mentions of Codex, which is definitely surging in popularity in the Bay Area.
Chinese companies have a technology ownership mentality. The Chinese culture is combining with a roaring economic engine to create unpredictable outcomes. I’m left with a lasting feeling that the numerous AI models reflect a practical, current equilibrium of the many technology businesses here. There’s no master plan. The industry is defined by a respect for ByteDance and Alibaba, the incumbents expected to win large portions of all markets with their substantial resources. DeepSeek is the respected technical leader, but far from a market leader. They set the direction, but aren’t set up to win economically.
This leaves companies like Meituan or Ant Group, where people in the West can be surprised they’re building these models. In reality, they see LLMs obviously as being central to future technology products, so they need a strong base. When they fine-tune the strong, general purpose model it hardens their stack from getting the open community to provide feedback on it, and they can keep internal, fine-tuned versions of the model for their products. The “open-first” mentality in the industry is largely defined by practicality — it helps make their models get strong feedback, it gives back to the open-source community, and empowers their mission.
Government aid is real, but unclear how big. It’s often asserted that the Chinese government is actively helping with the open LLM race. This is a government that’s decentralized across many levels, each of which doesn’t have a clear playbook for what exactly they do. Neighborhoods in Beijing compete for tech companies to house their offices there. The “help” offered to these companies almost certainly involved removing bureaucratic red tape like permits, but how far does it go? Can levels of the government help attract talent? Can they help smuggle chips? Across the visit, there were many mentions of government interest or help, but far too little to report the details as assertive or have a confident worldview of how government can bend the trajectory of AI in China.
There were certainly no hints of the top levels of the Chinese government influencing any technical decisions in the models.
The data industry is far less developed. Having heard so much about the likes of Anthropic or OpenAI spending $10M+ for single environments, with cumulative spend on the order of hundreds of millions per year to push the frontier of RL, we were eager to know if Chinese labs are either buying the same environments from companies in the U.S. or supported by a mirrored domestic ecosystem. The answer was not quite complete that there’s no data industry, but rather that their experience was that the data industry was relatively poor quality and it is often better to build the environments or data in-house. Researchers themselves spend meaningful time making the RL training environments, and some of the bigger companies like ByteDance and Alibaba can have in-house data labelling teams to support this. This all mirrors the build-not-buy mentality from the previous bullet.
Desperation for more Nvidia chips. Nvidia compute is the gold-standard for training and everyone is limited in progress by not having more of it. If supply was there, it is obvious that they would buy it. Other accelerators, including but not limited to Huawei, were spoken positively of for inference. Countless labs have access to Huawei chips.
These points paint a very different picture of an AI ecosystem, where quickly mapping how Western labs operate to their Chinese counterparts will often result in a category error. The crucial question is if these different ecosystems will produce meaningfully different types of models, or if the Chinese models will always be explained by being similar to the U.S. frontier models of 3-9 months ago.
Subscribe
Conclusion: The global equilibrium
I knew so little about China going into the trip and came out with the feeling of just starting to learn. China isn’t a place that can be expressed by rules or recipes, but one with very different dynamics and chemistry. The culture is so old, so deep, and still completely intertwined with how domestic technology is built. I have much more learning ahead.
So much of the current power structures in the US use their current worldviews of China as crucial mental devices for decision making. Having talked, in person, either formally or informally to pretty much every leading AI lab in China, there are a lot of qualities and instincts in China that’ll be very hard to model with Western decision making. Even after asking directly about why these labs release their top models openly, the intersection between ownership mentality and genuine ecosystem support is hard for me to connect the dots on.
The labs here are practical and not necessarily absolutists around open-source, where every model they build would be released openly, but there’s a deep intentionality in supporting developers, the ecosystem, and using it as a way to learn more about their models.
Almost every major Chinese technology company is building their own general purpose LLMs, as we see with the likes of Meituan (delivery service) and Xiaomi (broad consumer technology company) releasing open weight models. The equivalent companies in the U.S. would just buy services. These companies aren’t building LLMs out of a race to be relevant with the hot new thing, but a deep fundamental yearning to control their own stack and develop the most important technologies of the day. When I look up from my laptop and always see bunches of cranes on the horizon, it obviously fits in the with the broader culture and energy around building in China.
The humanity, charm, and genuine warmth of Chinese researchers is extremely humanizing. At a personal level, the cut-throat geopolitical conversation we’re used to in the U.S. hasn’t permeated them at all. The world can use more of this simple positivity. As a citizen of the AI community, I currently worry more about the fissures appearing within members and groups around labels of nationality.
I’d be lying if I said I didn’t want US labs to be clear leaders in every part of the AI stack — especially with open models where I spend my time — I’m American, and that’s an honest preference. With this, I want the open ecosystem itself to thrive globally, as this can create safer, more accessible, and more useful AI for the world, and right now the question is whether American labs will take the steps to own that leadership position.
As of finishing this piece, more rumors are swirling of executive orders influencing open models, which can further complicate this synergy between American leadership and the global ecosystem — it doesn’t fill me with confidence.
Thank you to all the wonderful people I got to talk to at Moonshot, Zhipu, Meituan, Xiaomi, Qwen, Ant Ling, 01.ai, and others. Everyone has been so welcoming and gracious with their time. I’ll keep sharing my thoughts on China as they crystallize, across culture generally and AI specifically. It is obvious that this knowledge will be directly relevant to the story unfolding at the frontier of AI development.

合作启事
2026年,产业科技金融协会将会同虹桥国际商务区优秀机构陆续开展产业首秀首发首展首投活动。请AI场景百人库成员和广大企业积极参与,协会将给予会员企业全力支持和政策项目推荐。(下图为活动场景图)
地理定位:蓝科虹桥中心

