夜雨聆风 > > 办公文件 > AI大模型 + 数据治理:简单聊聊(3+5+1)
当前时间: 2026-07-23 04:58:08
分类:办公文件
评论(0)
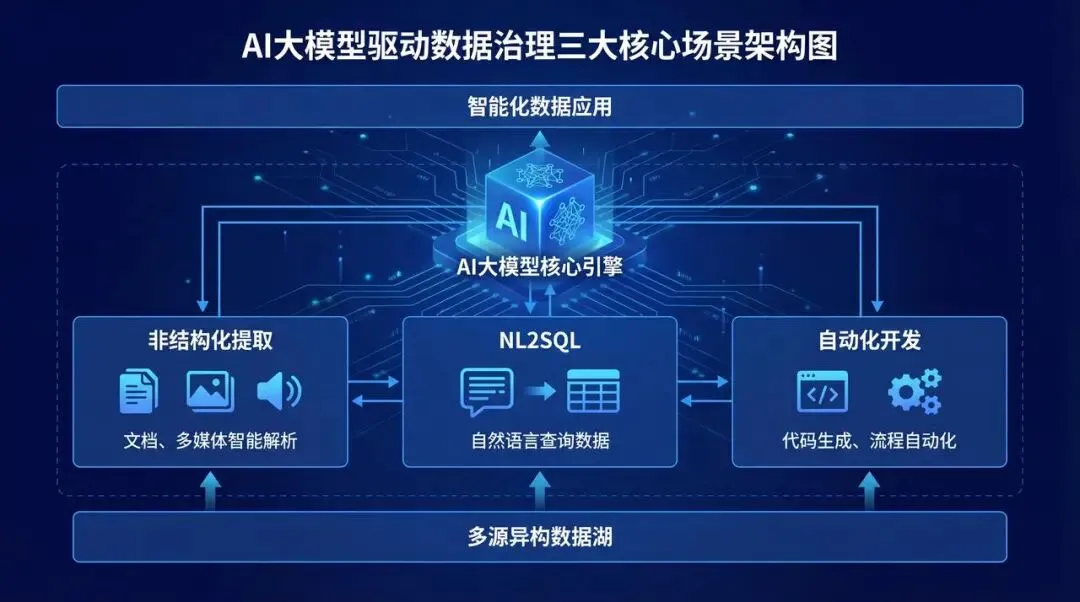
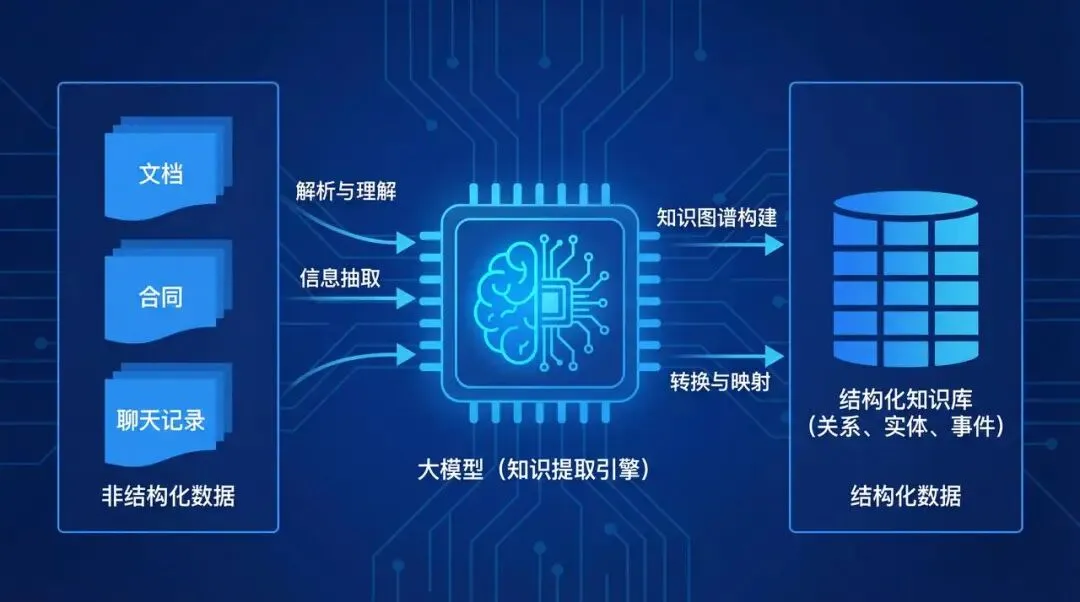
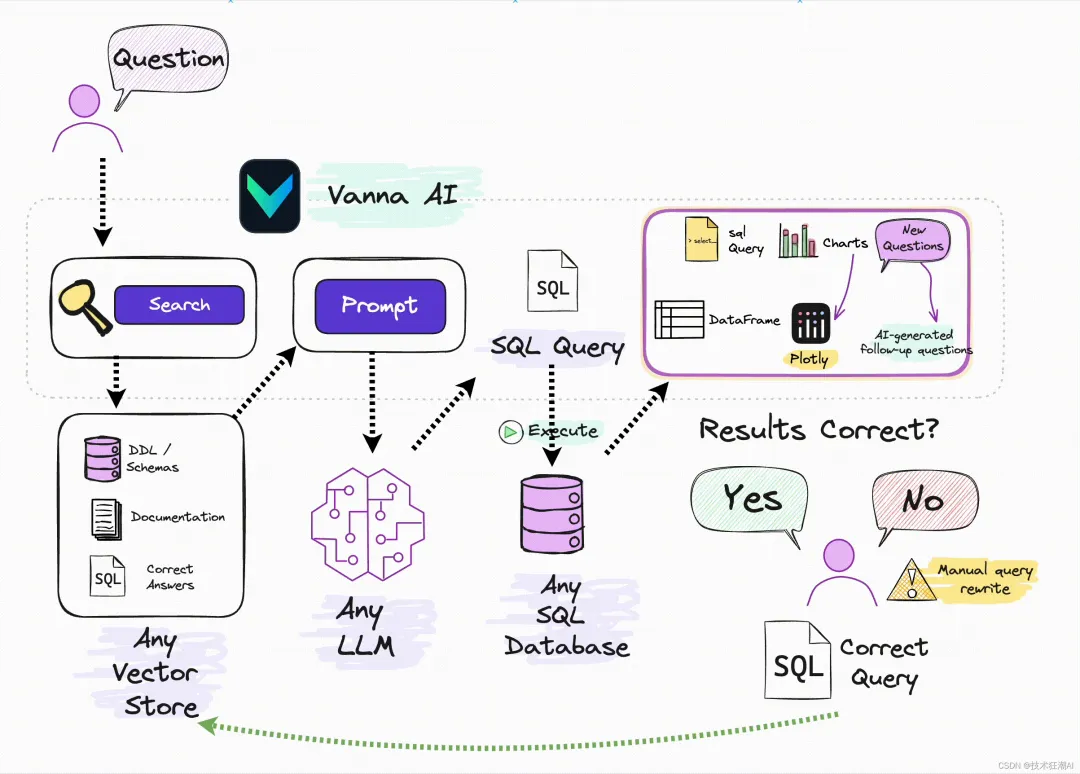
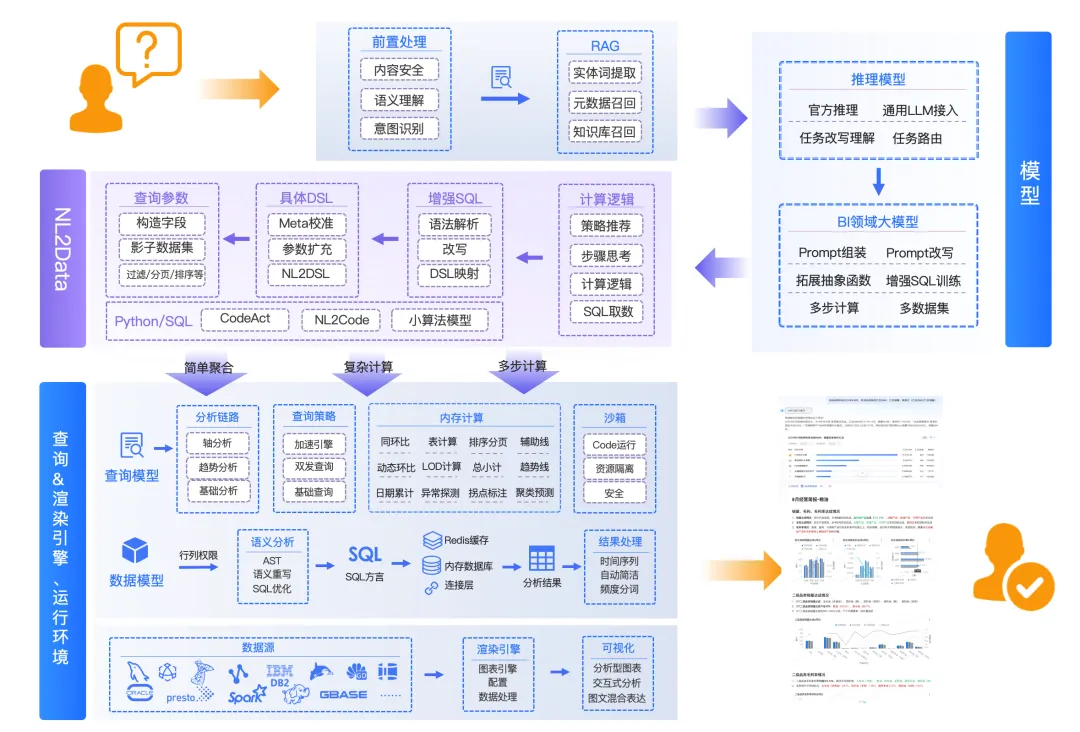
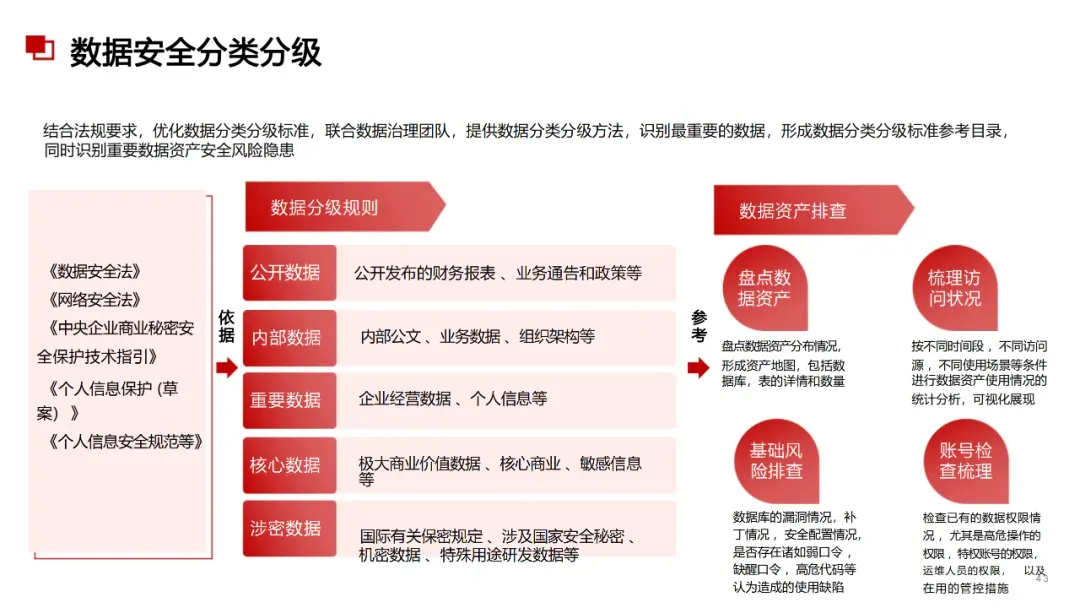
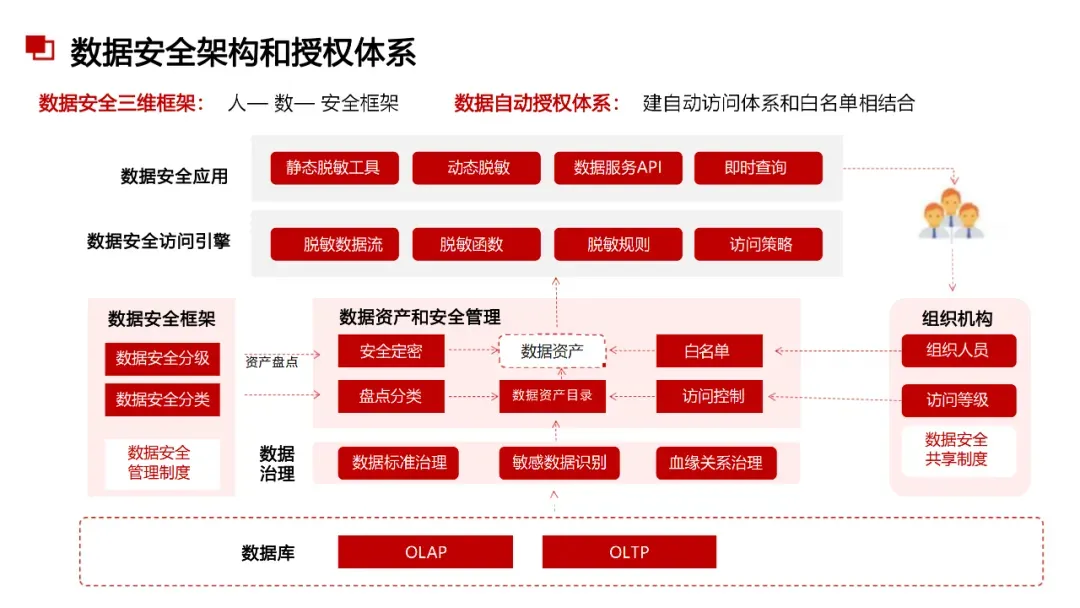
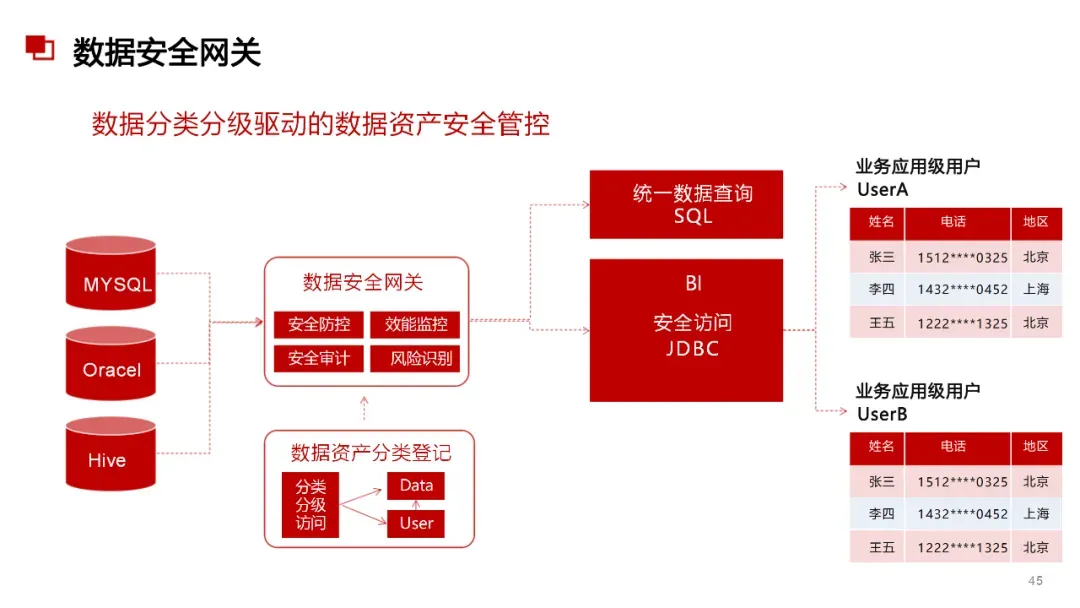
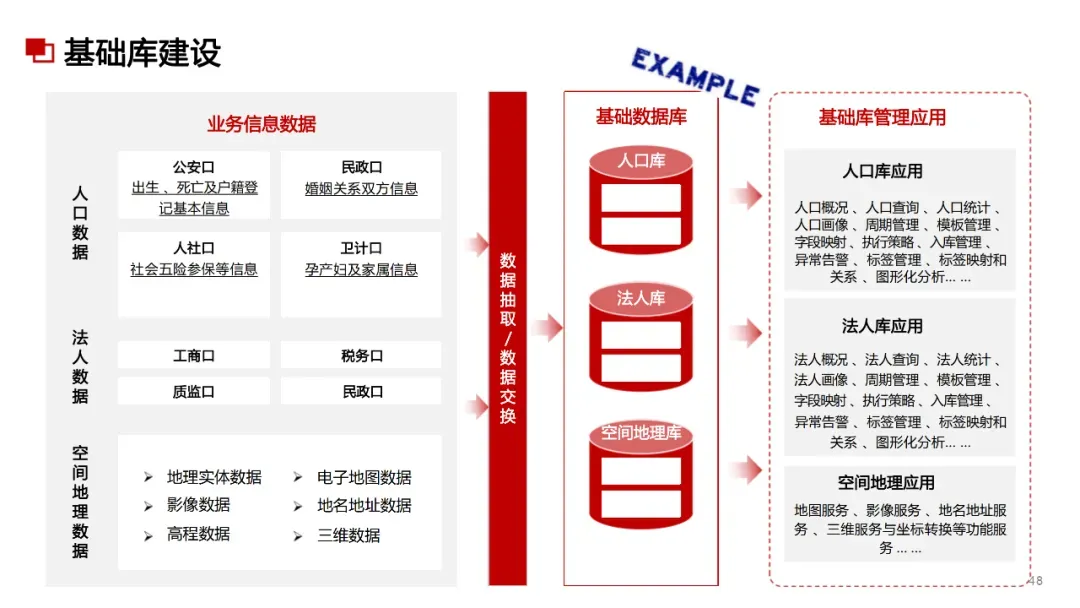
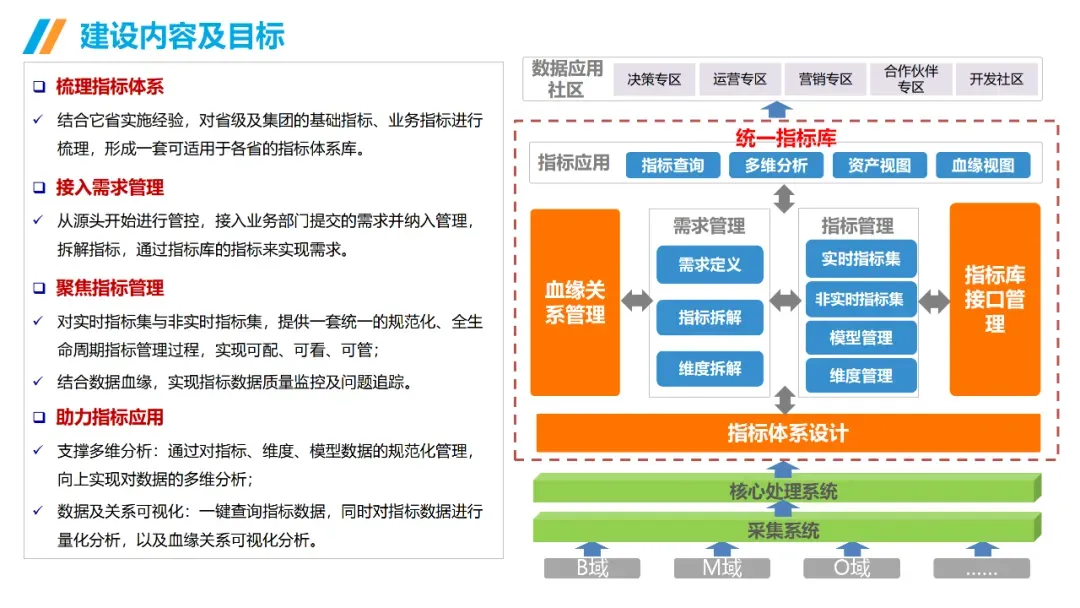
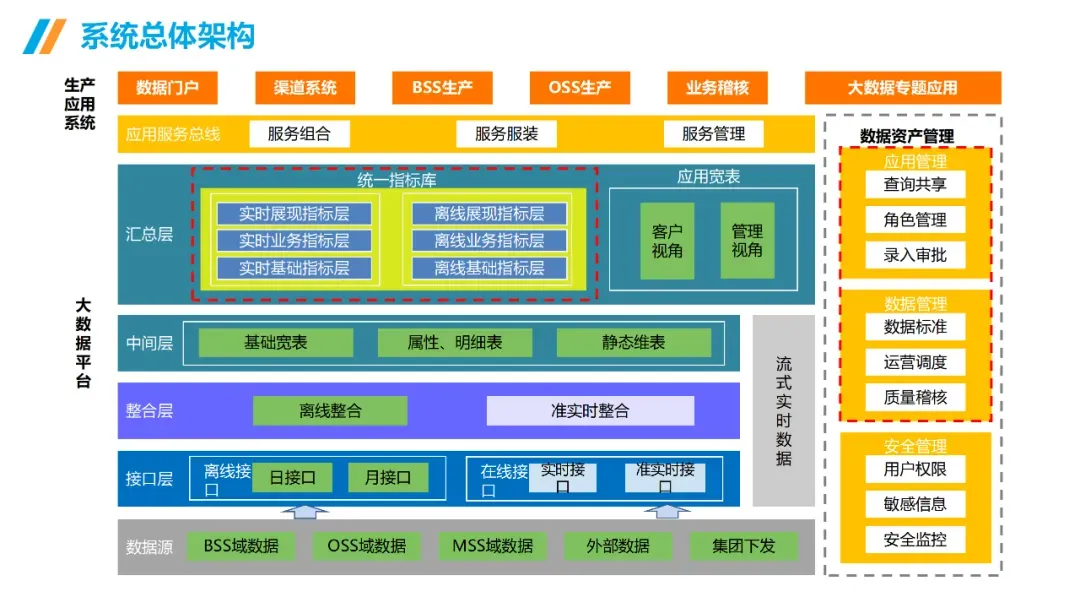
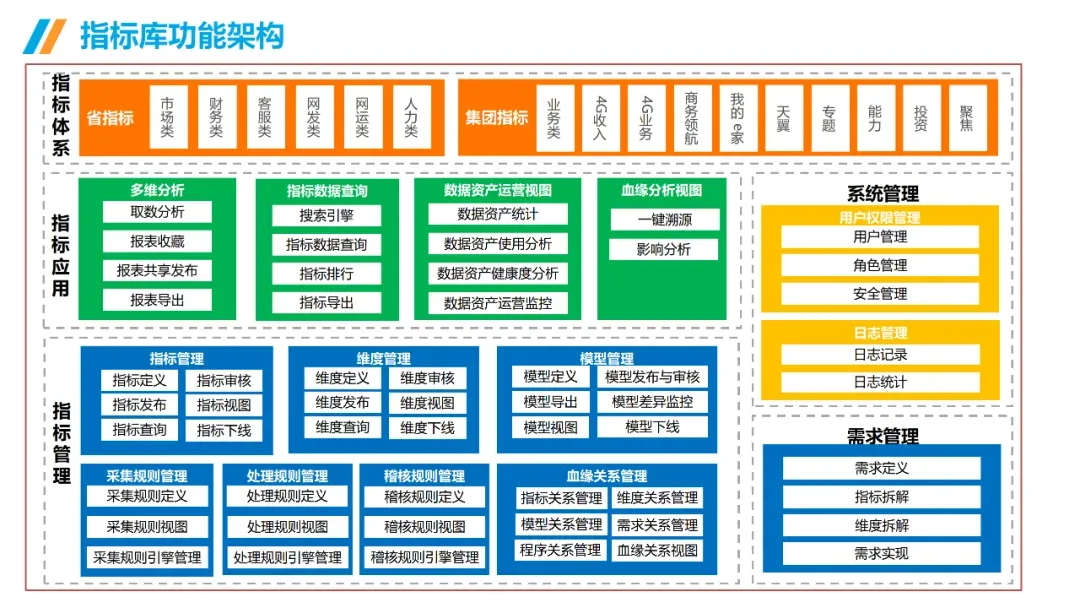
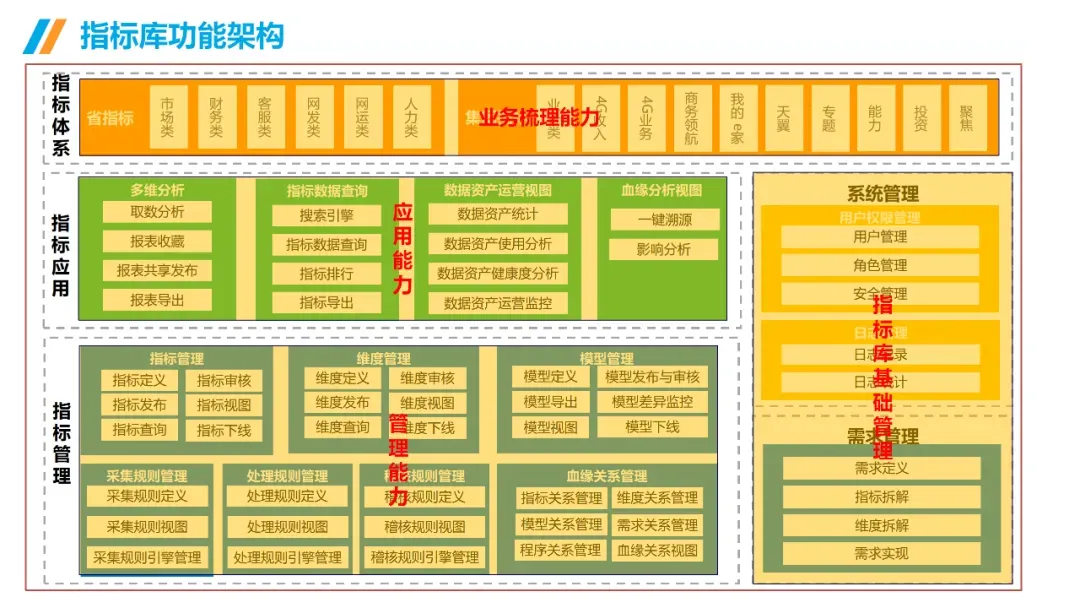
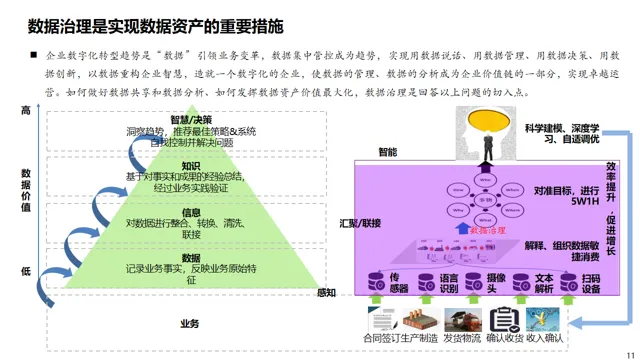
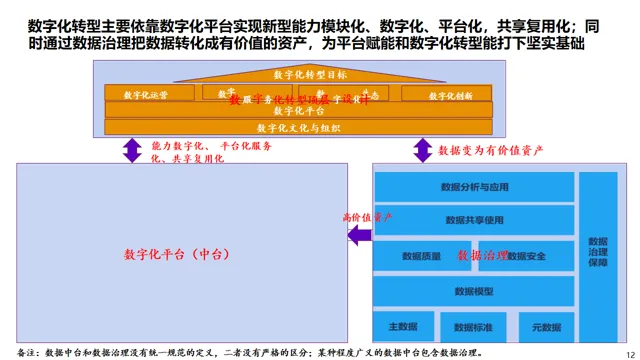
AI大模型 + 数据治理:简单聊聊(3+5+1)在朋友圈里刷到好几个数据治理圈的朋友,最近都在问同一个问题:大模型来了,数据治理到底该怎么玩?我昨晚跟一个在某大厂做解决方案的朋友吃饭,他说今年接到的需求,十个里面有八个要跟AI大模型沾边。但真落地起来,翻车的比成事儿的多。说白了,这事儿不是把大模型往数据治理流程里一塞就完事儿了。这里面坑不少,今天就把我见过、听过的干货整理出来,给打算动手的粉丝朋友做个参考。(欢迎批评指正与探讨交流!)不是所有数据治理环节都适合扔给大模型。我观察下来,目前能直接产生价值的,主要就是这三个场景。传统数据治理,面对企业里堆积如山的PDF文档、合同、会议纪要、客服聊天记录,基本上是束手无策——人工梳理成本太高,规则引擎又太死板。大模型来了之后,这个问题迎刃而解。用Claude或者GPT-4,直接以prompt的形式对大量文档进行信息提取,把杂乱的非结构化数据变成结构化的知识入库。一个在券商做数据治理的朋友,他们基本就是这么干的,把过去十年积累的几千份研究报告全部处理了一遍,原来要一个团队干三个月,现在两周搞定(PS:不知道是不是他在吹牛0.0)2. NL2SQL自然语言转SQL,让业务人员自己查数这个场景现在已经有不少落地案例了,特别是在金融行业。某大型金融机构合作的项目里,他们发现市面上大多数NL2SQL项目只给大模型喂数据库Schema,效果一直上不去。真正有效的做法,是把元数据、实体关系、数据标准、指标标准这些治理好的数据全部整合进去,给大模型完整的业务上下文。这么一搞,SQL准确率直接从不到60%提升到了80%以上。过去业务人员要个数据,得找数据开发提需求,排个两三天是常事儿。现在好了,业务人员用自然语言问一句,大模型直接生成SQL跑出来结果,几分钟就能拿到。这效率提升,懂的都懂。某个厂商的工程实践统计过:引入大模型之后,数据开发效率粗估能提升约~20%,成本降低~30%。数据治理项目里,数据处理环节本来就占了很大的成本,写SQL、写Python脚本全靠人工。大模型天生就是干这个的好手,你把需求说清楚,它直接给你写好,你改改就能用。讲完场景,该说坑了。我见过太多团队,上来就兴致勃勃搞大模型+数据治理,结果踩了坑,项目做不下去,钱也打了水漂。很多老板的思路是:既然大模型这么厉害,那干脆把数据治理团队砍一半,剩下的让AI干。这绝对是误区。上周跟一个咨询圈的老法师聊天,他说他见过一个客户,上来就要搞全流程AI自动化,结果生成的元数据标注错漏百出,最后还是得重新找人返工,花了两倍的钱。真实的情况应该是:大模型是增效工具,不是替代工具。让大模型干脏活累活(写代码、生成初稿),让人干判断和决策的活。分工明确,才能出成果。这是第二个常见坑。不少企业是:数据治理归IT部门做,大模型应用归算法部门做,两边各干各的,互不沟通。之前分享过一个金融企业的反例,因为训练数据没做脱敏,模型上线后泄露了用户隐私,直接触发监管罚单,项目被叫停,负责人都挨了处分。还有更常见的,大模型训练用的数据,质量参差不齐,有些数据还是好几年前的,结果模型学了一堆错误知识,输出结果根本没法用。问题出在哪?就是数据治理和大模型没有一体化。正确的姿势是:数据治理为大模型提供高质量数据,大模型反馈优化数据治理规则,形成闭环。做企业级应用,幻觉是致命的。你给业务部门输出了错误的结论,人家拿着去做决策,出了问题谁担责?我接触过一个项目,他们一开始直接用通用大模型回答业务问题,结果大概有15%的概率会生成错误的数据关系,业务部门用了一次就再也不用了。现在行业里的共识是用RAG检索增强生成来解决这个问题,但RAG也不是银弹——RAG效果好不好,核心还是看你检索出来的东西质量高不高,而这恰恰依赖数据治理。没有治理好的数据资产,RAG也巧妇难为无米之炊。你每一次让大模型处理数据,都是要token的,都是要花钱的。数据量一大,你会发现月度API账单直接吓死人。我听说有个团队,处理几千万条文档,光API调用费就花了几十万,预算直接干穿了。所以这里有个最佳实践,小批量验证的时候用调用第三方API,规模化落地的时候,一定要考虑本地化部署大模型,或者用混合架构——高频简单查询用本地小模型,复杂查询才调用大模型。这样成本能控制住。很多数据治理项目,本来就容易犯"为了治理而治理"的毛病,现在加上大模型,更容易变成"为了AI而AI"。上了一堆技术,搞了一堆功能,最后业务部门说:你这东西到底能帮我解决什么问题?讲真,如果你不能回答这个问题,那这个项目十有八九要黄。某三甲医院要做AI辅助诊断,需要从海量电子病历里训练模型。但电子病历大部分都是医生手写的自由文本,非结构化程度非常高,直接拿去训练模型,准确率一直上不去。第一步,构建全生命周期的数据治理体系,从采集、清洗、标注到存储,每个环节都有质量管控。用大模型自动把非结构化的自由文本转化为标准化的数据元。第二步,建立数据质量量化评估机制,从完整性、一致性、时效性三个维度给数据打分,分数不够的数据打回去重新处理。第三步,把数据治理和模型训练深度耦合,模型训练过程中,如果发现某类数据准确率下降,自动触发数据质量复核流程,动态调整治理策略。结果怎么样?诊断模型准确率直接提升了23%,现在已经在临床辅助诊断中用起来了。这个案例告诉我们什么?不是说有了大模型就不用做数据治理了,恰恰相反——大模型对数据质量要求更高了。大模型是发动机,数据治理就是汽油,你加劣质汽油,再好的发动机也跑不起来。大模型给数据治理这个传统行业带来了新的可能性,这一点没人否认。过去数据治理一直被人吐槽"周期长、成本高、价值不显",投入很大,但是见效很慢,很多企业望而却步。大模型来了之后,这个局面正在改变。你可以用更低的成本、更快的速度见到价值,这对整个行业都是好事。但我也要泼一盆冷水:别瞎炒作概念,别上来就颠覆这个颠覆那个。把一个一个具体场景的问题解决了,让业务部门真真切切感受到效率提升了,成本降下来了,这才是真的。我那个做解决方案的朋友说的好:大模型和数据治理是双向奔赴,不是谁干掉谁。大模型给数据治理降本增效,数据治理给大模型保驾护航,二者螺旋式上升,这才是未来真正的方向。- 目前真正能落地的核心场景主要有3个:非结构化数据知识提取、NL2SQL自然语言查询、自动化数据开发与文档生成,每个场景都能带来明确的效率提升
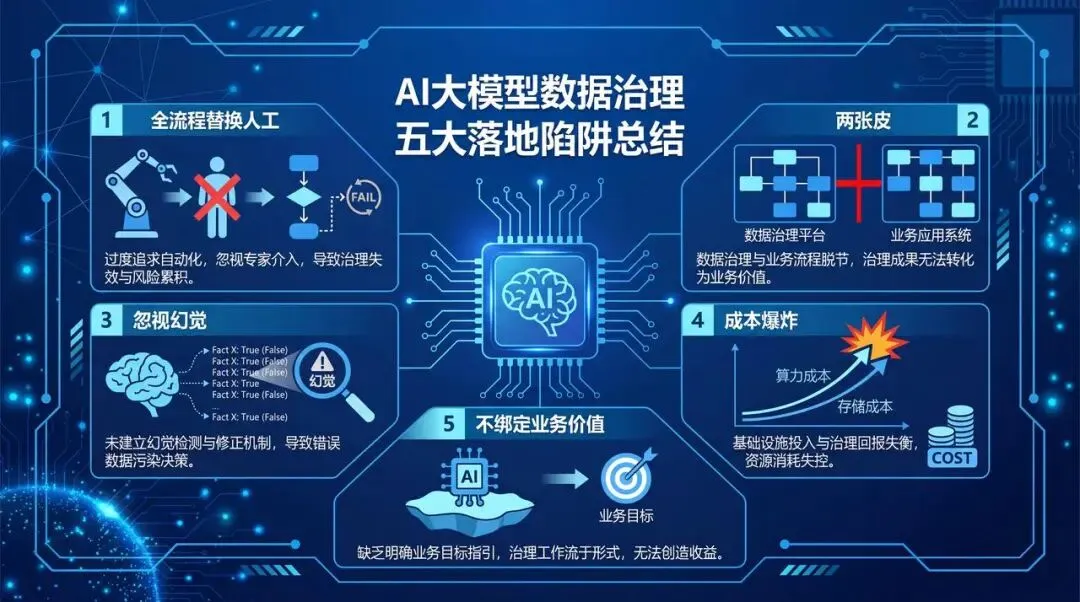
- 5个常见落地陷阱:全流程替换人工、数据治理与大模型两张皮、忽视幻觉问题、成本失控、不绑定业务价值。避开这些坑,项目成功率能提升一大截
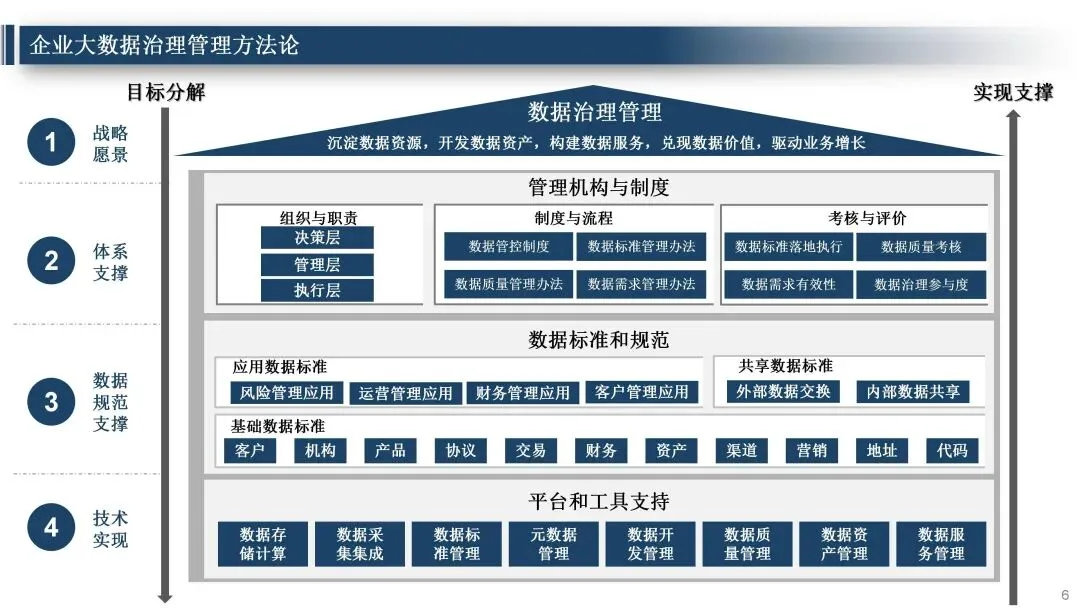
- 最佳实践的核心是1体化:数据治理为大模型提供高质量数据底座,大模型反馈优化治理规则,形成闭环,最终业务效果才能上去
长按扫码加入VIP社群【AI·大数据资料库】知识星球,获取本文所有及更多关于AI、大数据专业内容,有任何问题随时后台与我沟通
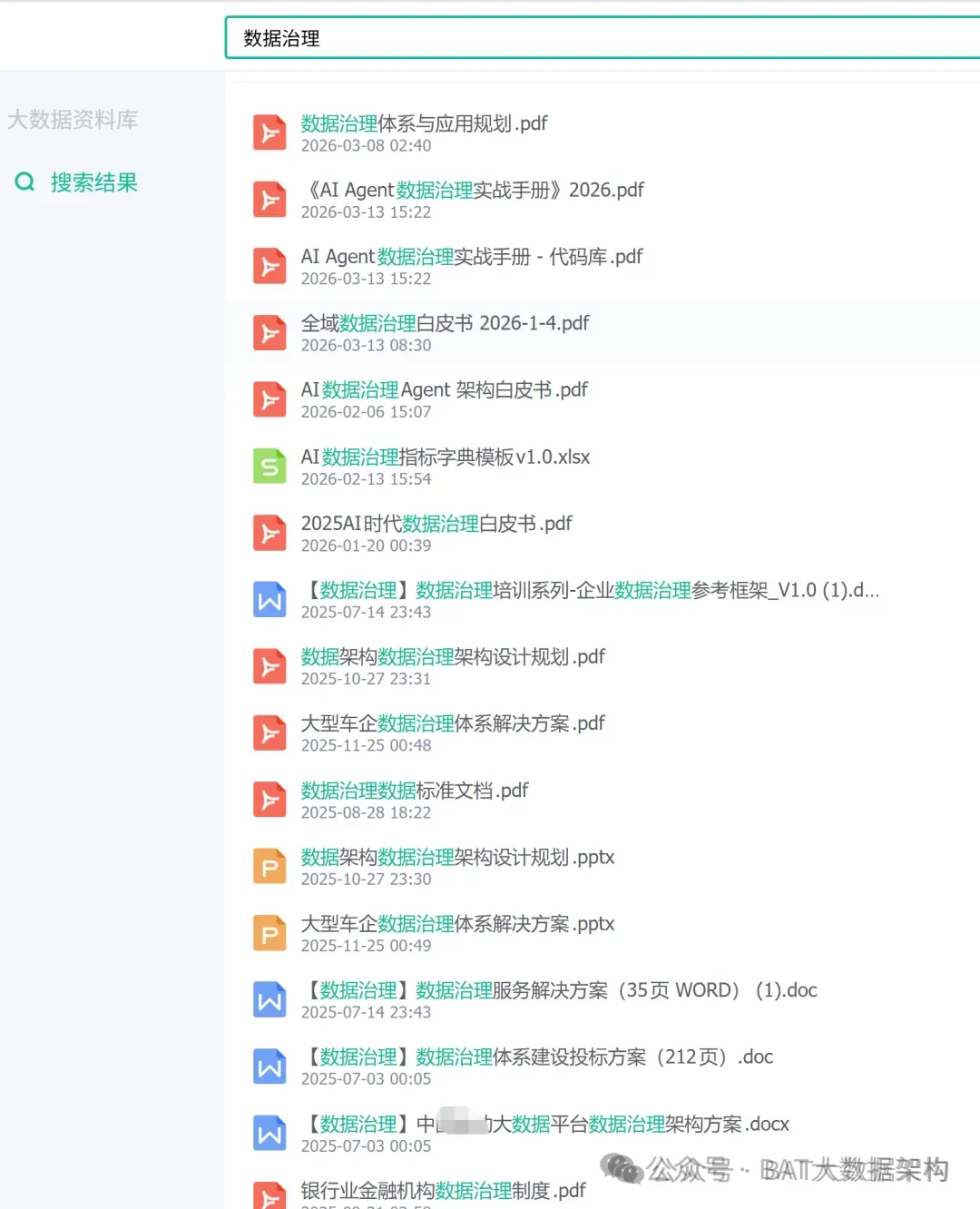
长按扫码上方二维码加入 大数据资料库·知识星球 ,搜索大模型、数据治理等关键词,任意下载全部资料文档与方案附2:数据治理与数据指标库规划指南| 各种PPT
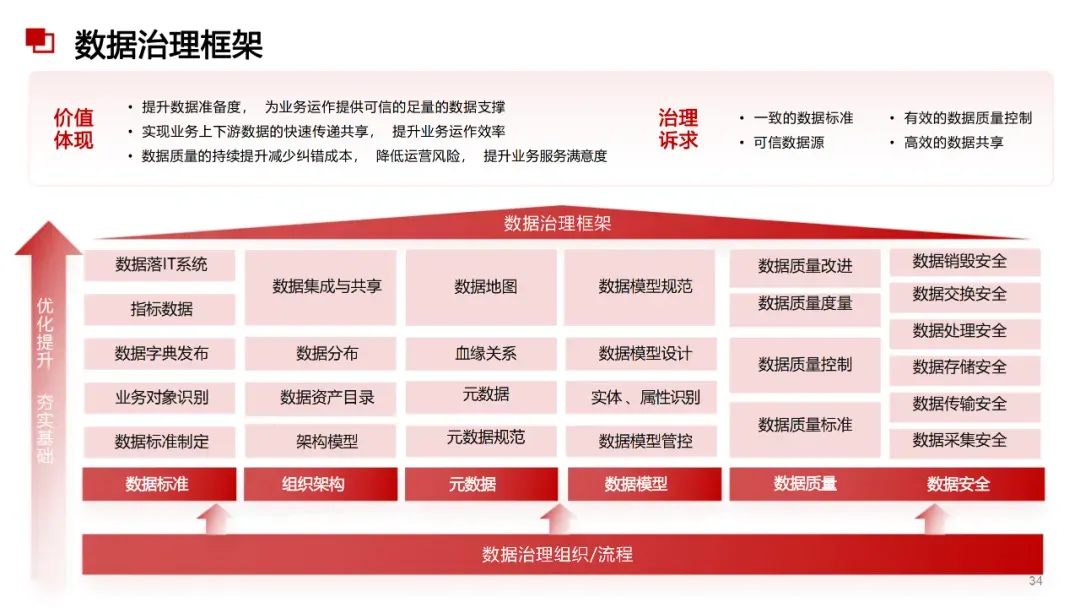
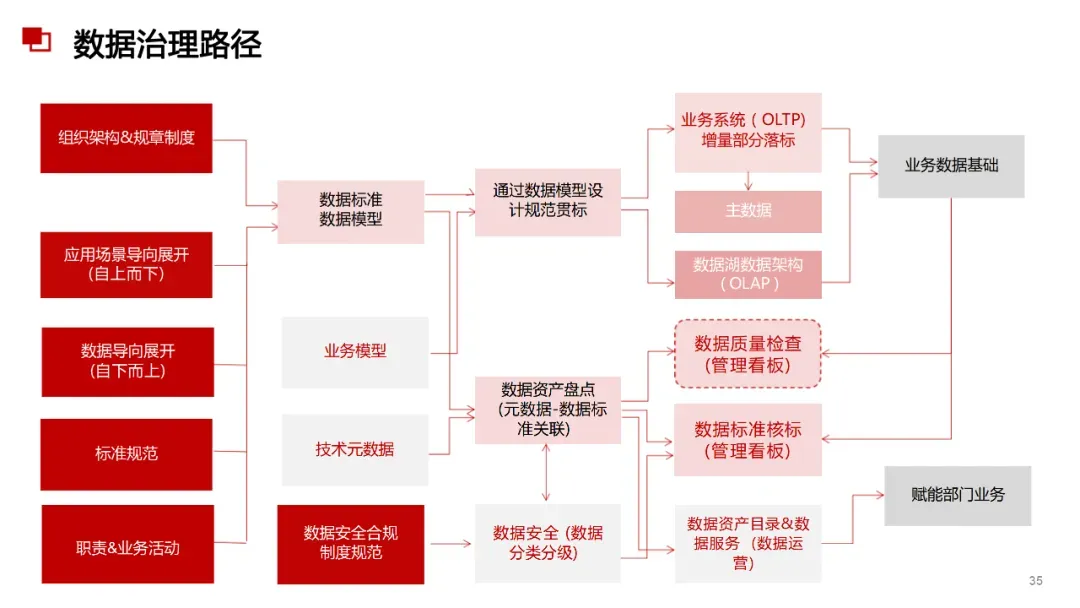
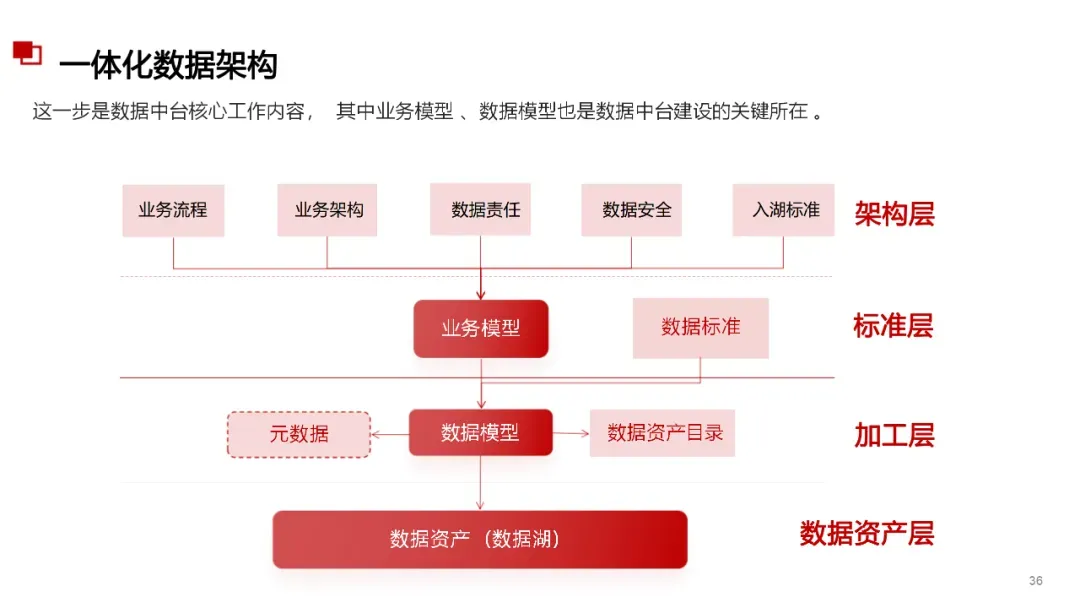
数据治理&数据标准&数据管理& 数据资产&数智化&解决方案&研究报告等 宝贵资料,都是干货供大家研习参考使用:(扫码加入星球可获取所有资料) 博主推荐,更精彩! 品质服务,质量保障。加入星球,您说话!有任何问题,随时加我微信+V:bat6188沟通。数据治理&数据治理体系&平台&AI大模型&投标方案&建设方案&数字化转型&技术方案&操作指南&行业报告&数据中台&大数据可视化 的核心内容与优秀方案,万字材料深度剖析业界标杆行业典范《数据治理体系建设投标方案(212页).doc 《数据治理总体设计方案2.docx《企业大数据治理平台建设方案(45页).docx《 企业大数据治理平台需求规格说明书(288页).docx《 企业大数据治理平台建设规划应用技术方案(68页).docx《大数据治理服务平台建设项目实施方案(238页精华版). 《数据治理全过程域工具包研究(27页 PPT).pptx 《 数据治理与数据安全防护方案(59页 PPT).pptx《数据中台与数据治理服务及案例(51页).pdf 《 数据综合治理项目技术标书.docx《 数据治理框架技术方案.docx《 大数据可视化平台采购项目招标方案.docx《 数据中心项目招标技术方案.docx《 数据治理操作指南.doc 《 数据治理体系文档.docx《 数据治理服务解决方案.docx《 数据治理咨询方案和报价.docx《 数据治理工具项目投标书-V1.6.docx《 数据平台建设项目投标书_V1.0.docx.....” 如需要1对1服务、商业咨询、技术指导、简历修改、面试指导、商务合作的朋友, 也可以以长按下方二维码加我个人微信详细对接沟通。备注来源和诉求。
关注我们,获取更多数据治理实战干货! 如上部分资料一览,获取全套资料,请加入 大数据资料库·知识星球 ,长按扫描下方二维码进入星球下载 ⏬
博主留言 :加入VIP知识星球,您说话。有任何问题,随时与我沟通,有求必应 ! 限时优惠,马上要涨价,最后几天了,兄弟们,如有需要,建议尽早加入,决策成本,不等人。需要简历优化、项目讲解、面试辅导、内推大厂的朋友,可带简历私我。微信ID:bat6188后续也会在【大数据资料库】社群知识星球,组织直播、分享会等专项活动。本文部分图片或内容来源于网络,供读者朋友研习交流使用,如有侵权,请联系删除~
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-07-24 02:08:32 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/599974.html
- 运行时间 : 0.206189s [ 吞吐率:4.85req/s ] 内存消耗:4,828.87kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=dcca4593d3a62fa211fbf9677e9313e8
- CONNECT:[ UseTime:0.000973s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.001597s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000754s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000693s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.001418s ]
- SELECT * FROM `set` [ RunTime:0.000495s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.001545s ]
- SELECT * FROM `article` WHERE `id` = 599974 LIMIT 1 [ RunTime:0.001132s ]
- UPDATE `article` SET `lasttime` = 1784830113 WHERE `id` = 599974 [ RunTime:0.015295s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.000724s ]
- SELECT * FROM `article` WHERE `id` < 599974 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.001202s ]
- SELECT * FROM `article` WHERE `id` > 599974 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.001083s ]
- SELECT * FROM `article` WHERE `id` < 599974 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.001755s ]
- SELECT * FROM `article` WHERE `id` < 599974 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.002000s ]
- SELECT * FROM `article` WHERE `id` < 599974 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.004799s ]

0.207987s

 夜雨聆风
夜雨聆风