 夜雨聆风
夜雨聆风很多人谈 agent 时,喜欢把重点放在 prompt 或模型能力上。
但如果你认真看 Claude Code 的源码,会发现它下了很多功夫在 harness engineering 上:把模型、工具、权限、状态、流式输出、恢复机制、会话生命周期,全都装进一个可运行的工程壳里。
这篇上篇先回答一个更基础的问题:Claude Code 是怎么把用户输入一步步送进运行时主循环的?
系列回顾:
先解释几个会反复出现的术语
模型调用:可以粗略理解成一次向 Claude API 发请求。很多人会把它直接等同于“一次 query”,但在 Claude Code 里两者并不完全一样。 turn:一次回合。模型产出内容、可能调用工具、工具结果被回填,再决定是否继续,这一整段更接近一个 turn。 tool_use:模型在回复里发出的“请调用某个工具”的结构化请求,不是普通文本。 transcript:会话的持久化运行记录,不只是当前传给模型的 messages,还包括恢复和重放所需的关键轨迹。harness:围绕模型建立起来的运行时框架。它处理的往往不是“模型会不会回答”,而是“这个系统能不能稳定跑下去”。
什么叫 harness engineering
你可以把它理解成:围绕模型建立一套可执行、可控、可恢复、可扩展的运行时框架。
模型本身主要负责推理;Claude Code 负责决定什么时候发请求、这次请求带哪些上下文、能调用哪些能力、工具结果如何回填、权限怎样放行或拦截,以及会话如何被记录、压缩和恢复。真正把系统撑起来的是这些模型外的工程机制。
一张图看懂 Claude Code 的 runtime harness
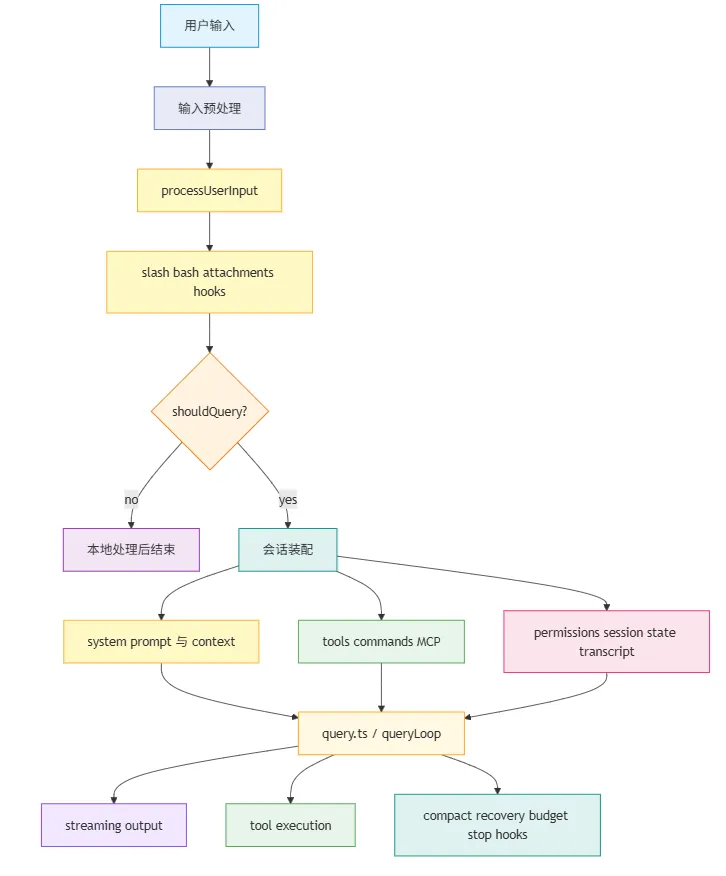
这张图的重点在于:Claude Code 不会让模型“裸跑”。 它会先处理输入,再装配会话,再进入主循环。后面很多你在源码里看到的复杂逻辑,本质上都是围绕这条链展开的。
先把入口边界画完整:用户输入不会直接进入 queryLoop
在 Claude Code 里,用户输入通常不会直接掉进 query.ts。在真正进入 queryLoop 之前,还有一段明确的输入预处理链。
这里的
query.ts可以先粗略理解成 Claude Code 的主循环内核:它负责驱动每一轮请求如何进入模型、何时执行工具、出现错误后如何恢复,以及在什么条件下继续或结束当前回合。如果再说得更准确一点:
query()本身并不等于一次单独的 LLM call。底层的callModel()才更接近“单次模型请求”;query()包住的则是一个可能包含多次模型调用、工具执行、结果回填和状态推进的运行时闭环。而
queryLoop则是query.ts里面那条真正按轮推进的核心循环:它会在每一轮里整理上下文、发起模型请求、处理tool_use、回填工具结果,并根据 hooks、budget 和错误恢复逻辑决定下一步怎么走。
以 QueryEngine.submitMessage() 为例,它首先会调用 processUserInput(),把原始输入转换成系统真正能消费的消息和控制信号。这个阶段做的事情并不少:
解析输入类型:区分普通 prompt、slash 命令、bash 命令、桥接消息、带图片的多模态输入。 处理附件与图片:提取 attachment、规范化 image blocks、必要时做 resize/downsample,并把元数据补成 isMeta消息。执行输入期 hooks: UserPromptSubmithooks 可以附加上下文、阻断请求,或者直接阻止 continuation。决定是否进入主循环:本地 slash 命令、某些本地处理路径会返回 shouldQuery: false,这类输入根本不会进入queryLoop。回传入口期控制信号:例如 allowedTools、model override、resultText,这些都会影响后续会话装配。
可以把这条链理解成:
raw user input // 原始用户输入 -> processUserInput // 输入预处理 -> messagesFromUserInput + shouldQuery + allowedTools + model override // 生成消息与控制信号 -> transcript persistence // 先写入 transcript -> session/tool context assembly // 再做会话装配 -> query() // 进入运行时闭环这里的 transcript 可以先简单理解成会话的持久化运行记录。它不只是当前传给模型的 messages,还承担了记录用户输入、assistant 输出、工具结果和恢复边界的作用,所以在真正进入 query() 之前先写入 transcript,核心是为了让这次会话可追踪、可恢复。
把这个边界讲清楚很有必要,因为 Claude Code 的 harness 会先经过一层输入规范化、局部执行和准入判断,之后才进入 agent loop。
QueryEngine 负责会话装配,但不是唯一入口
QueryEngine 依然很重要,不过它更像会话层的 harness 封装,并不是整个系统唯一的 runtime 入口。
先解释一下“会话装配”这个说法。它不是简单地拼几个参数,而是把这一轮运行需要的上下文、能力和状态准备齐:这次对话已有的 messages、可用工具列表、system prompt、当前会话的权限语义,以及恢复和持久化相关的状态,都会在这里被整合到一起。
来看 submitMessage() 的实际签名:
// src/QueryEngine.tsasync *submitMessage( prompt: string | ContentBlockParam[], options?: { uuid?: string; isMeta?: boolean },): AsyncGenerator<SDKMessage, void, unknown> {它做的事情主要包括:
承接输入预处理后的消息与控制信号,必要时短路本地路径。 把 messagesFromUserInput先写入 transcript,保证即使 API 尚未返回、进程中途退出,也可以从“用户输入已被接受”的时点恢复会话。**组装 systemPrompt、userContext、systemContext**。**构造 ToolUseContext**,把工具、命令、MCP、AppState、缓存、预算等能力装配进来。**包装 canUseTool**,把权限拒绝记录、headless/SDK 语义接到工具执行链路上。维护会话级状态,例如 transcript 持久化、file history、累计 usage、permission denials。
但这里有一个重要边界要讲清:**QueryEngine 不是 Claude Code 的唯一入口。**
在 SDK 或 headless 路径里,它确实承担了会话层入口的角色;而在交互式 REPL 路径里,UI 侧仍然会直接驱动 query()。Claude Code 的分层更接近下面这样:
入口层:REPL、CLI、SDK 各自有自己的接入方式。 会话层: QueryEngine负责其中一部分入口的会话装配与状态持有。执行内核: query.ts的queryLoop负责真正的 runtime 推进。
这个区分能避免把 QueryEngine 误读成“整个 harness 的全部”。
如果把两条主要入口并排来看,关系会更清楚一些:交互式 REPL 不会直接把输入塞进 queryLoop,而是先经过提交处理和输入预处理,再由 onQuery() 接到 query();SDK / headless 则会先经过 QueryEngine.submitMessage(),在完成输入预处理与会话装配后再进入同一个 query()。

更贴源码的理解大概是:
输入层先做预处理与短路判断。 会话层再决定本轮要带着什么上下文和权限进入执行。 执行层最后由 queryLoop推动模型、工具和恢复逻辑往前走。
进入执行内核:query.ts 的 queryLoop
如果只挑一个文件来理解 Claude Code 的 harness,可以先看 src/query.ts,尤其是里面的 queryLoop。
Claude Code 的核心在于维护一个可持续推进的回合状态机。这里的“状态机”不是教科书里的那种形式化定义,而是说:系统每完成一步,就会根据当前消息、工具执行结果、停止条件和错误恢复状态,决定下一步往哪里走。
从 query.ts 里的 loop-local State 就能看出这一点:
// src/query.tstype State = { messages: Message[] toolUseContext: ToolUseContext autoCompactTracking: AutoCompactTrackingState | undefined maxOutputTokensRecoveryCount: number hasAttemptedReactiveCompact: boolean maxOutputTokensOverride: number | undefined pendingToolUseSummary: Promise<ToolUseSummaryMessage | null> | undefined stopHookActive: boolean | undefined turnCount: number transition: Continue | undefined}这个状态在驱动整个回合的推进。queryLoop 每次迭代大致都会做这些事:
整理本轮输入:取 compact boundary 之后的消息,应用 tool result budget、snip、microcompact、context collapse、autocompact。 发起模型请求:把 messages、systemPrompt、userContext、tools、taskBudget等交给callModel()。处理流式响应:持续接收 assistant blocks、收集 tool_use、在需要时启动StreamingToolExecutor。执行工具并回填结果:把 tool_result重新变成后续轮次的输入,而不是只留在 UI 上展示。做恢复与重试:处理 prompt-too-long、 max_output_tokens、model fallback、streaming fallback。决定回合是否结束:检查 stop hooks、token budget、 maxTurns、abort 状态,以及是否还需要 follow-up。
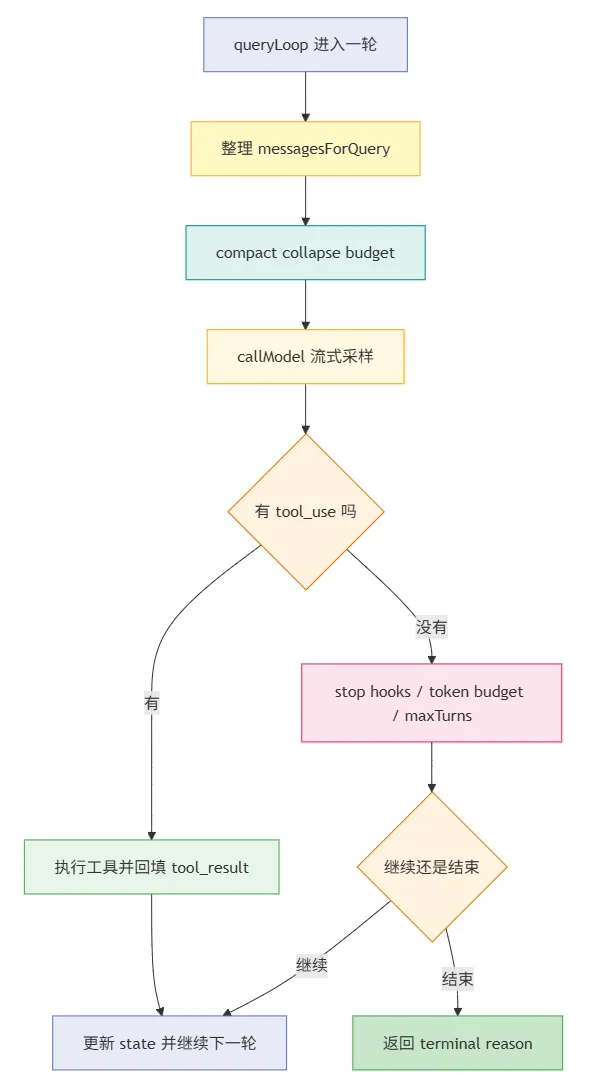
所以更准确地说,Claude Code 的 harness 重心落在 queryLoop 这个持续演化的 runtime 上,而不只是 QueryEngine 外面包一层工程代码。
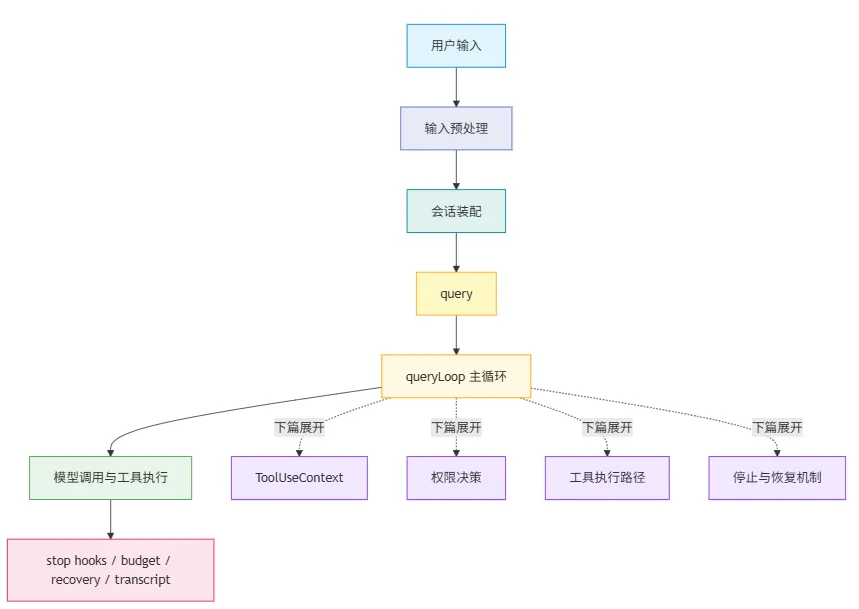
这里也顺手交代一下上下篇的组织方式:上篇基本沿着 Claude Code 的主运行链往下讲,从输入预处理、会话装配一路走到 queryLoop;下篇再把这条主链里的关键机制拆开来看,比如 ToolUseContext、权限、工具执行、stop hooks、budget 和 recovery。也就是说,下篇各节更多是围绕主链做展开,并不都是严格按时间顺序发生的步骤。
源码锚点
如果你想顺着上篇这条主运行链自己跟一遍源码,基本可以按这个顺序看:
src/screens/REPL.tsxsrc/utils/handlePromptSubmit.tssrc/utils/processUserInput/processUserInput.tssrc/QueryEngine.tssrc/query.ts
上篇小结
如果把上篇压缩成一句话,可以这样理解:Claude Code 的 harness 先把用户输入变成系统可消费的消息和控制信号,再由 QueryEngine 或 REPL 路径完成会话装配,最后把一切交给 queryLoop 这个持续推进的执行内核。
到这里为止,主运行链已经比较清楚了。下篇会先从 ToolUseContext 这个运行时容器开始,再往下看:进入主循环之后,这些能力是怎么被权限、工具执行器、stop hooks、budget、compact、recovery 和 transcript 共同治理的。
