 夜雨聆风
夜雨聆风我曾经以为把 Agent 跑起来就算上线了,直到第一个真实用户来了……
本地测试跑得溜溜的,换一个真实用户,立刻给你表演各种崩法——超时、乱答、成本飞涨、报错找不到原因。那一刻你才发现,原型和生产之间,不是一步,是一道沟,而且还挺深的。
原型和生产,差的不是一点点
先直观感受一下这条鸿沟有多宽:
| 维度 | 原型阶段 | 生产环境 |
|---|---|---|
| 用户规模 | 就你自己测 | 成千上万并发 |
| 错误处理 | 报错了看看日志 | 错误难复现,上下文依赖 |
| 成本控制 | 随便跑 | Token/API 费用飞涨 |
| 可见性 | 本地看输出 | 完全黑盒,靠猜 |
| 性能要求 | 跑得出来就行 | 延迟、准确性都得过关 |
说白了,原型是你一个人在自嗨,生产环境是要对真实用户负责的。用户不管你背后用的是什么模型、什么框架,他们只在乎「这东西好不好用」。
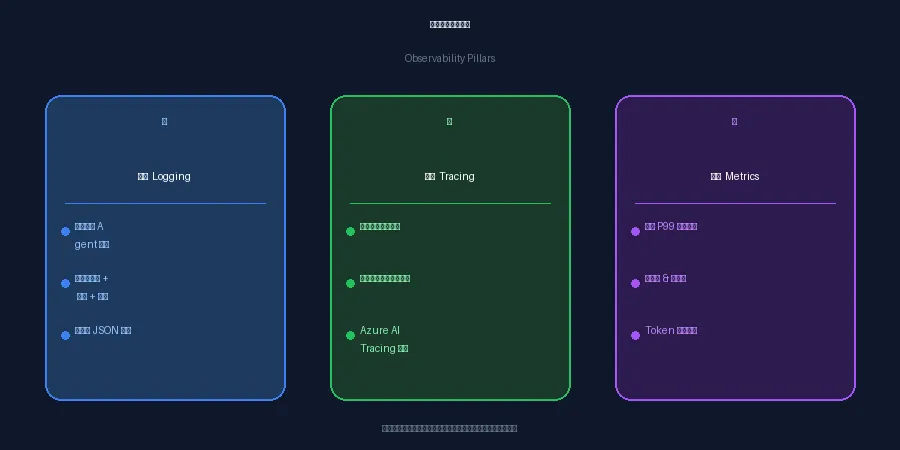
你看不见,才是最大的麻烦——可观测性三支柱
上生产最怕的不是出问题,是出了问题你根本不知道哪里出了问题。这就是「可观测性」要解决的事。
它有三个核心支柱:日志、追踪、指标。缺哪一个,你的 Agent 基本就是在黑暗里裸奔。
日志(Logging)没有日志的情况是这样的:用户投诉 Agent 给了个明显错误的答案,你打开系统一看——啥记录都没有。不知道它当时调用了哪些工具,不知道走了哪条推理路径,不知道哪一步拐歪了。就像飞机出事了,找不到黑匣子,只能猜。
日志要记的不是"程序跑了",是"Agent 在这一刻在干什么、用什么信息做了什么决定"。
追踪(Tracing)没有追踪的情况:一个调了好几个工具的 Agent,某天延迟突然从 2 秒飙到 20 秒。是模型推理变慢了?是某个工具 API 超时了?是网络抖了?你完全不知道。
开启追踪(比如 Azure AI Tracing)之后,每一步的耗时都清清楚楚——第一步调了搜索工具,0.3 秒;第二步喂给模型,18 秒。哦,问题在模型这里。马上锁定,不用猜。
指标(Metrics)没有指标的情况:你以为 Agent 一直在正常运行,其实成功率已经悄悄从 95% 跌到 60% 了。等用户开始批量投诉,黄花菜都凉了。
指标是你的体检报告,得定时看,不能等出事了才想起来查。
怎么知道 Agent 干得好不好——评估框架
可观测性告诉你「发生了什么」,评估框架告诉你「干得好不好」。
评估分两个阶段:
离线评估——上线之前,准备一批测试案例,用 Azure AI Evaluation SDK 跑一遍,看质量达不达标。就像考试前做模拟题。 在线评估——上线之后,A/B 测试不同版本,看用户的真实反应(点赞、踩、留存)。评估时有 5 个指标值得重点关注:
| 指标 | 大白话含义 |
|---|---|
| Groundedness | 回答有没有乱编?是不是基于真实信息说的 |
| Relevance | 答的是不是问的那个问题? |
| Coherence | 说的话是不是连贯,读起来是不是像个正常人说的 |
| Fluency | 语言是否流畅,有没有奇怪的断句或语法错误 |
| Task Completion | 用户要做的事情,做成了没有 |
这些指标不是让你背的,是让你上线前有个检查清单用的。每一项都对应一类真实问题,提前对照一遍,能省你不少事后救火的力气。
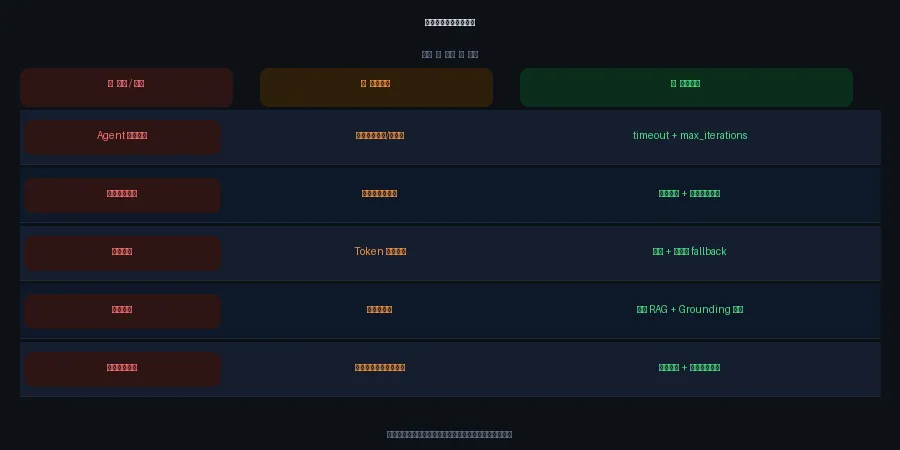
生产环境最常见的五个坑
理论讲完了,来点实的。我研究了一圈,生产环境的坑归来归去就那几类,挑五个最常踩的说一说。
 问题1:Agent 卡住不动
问题1:Agent 卡住不动
用户等了 30 秒,啥反应都没有,以为系统挂了,直接关掉走人。实际上可能是工具调用超时了,也可能 Agent 进了死循环,一直在"思考"出不来。
解法直接:设 timeout + max_iterations。超过时间或者超过推理步数,强制返回一个"我搞不定",比让用户傻等强多了。
问题2:输出质量突然下降Agent 开始答非所问,或者明明聊了半天,突然"忘记"了你说过什么。这不是模型变笨了,是上下文窗口撑不住了——早期的对话被截断,Agent 真的失忆了。
解法:压缩历史记录,把关键信息做成摘要放进上下文,别把每一句原话都塞进去。
问题3:成本爆炸月底看账单,Token 消耗比预期多出 5 倍。往往是因为每次调用都把完整对话历史带上去了,重复内容大量浪费。
解法:加缓存,同样的查询直接命中缓存不重复调用;非关键任务用更小的模型来跑,没必要每次都上最贵的。
问题4:幻觉越来越多Agent 开始自信地说错误的事情,用户投诉"你在乱编"。根源通常是 RAG 检索回来的内容质量太差,Agent 找不到可靠信息就开始发挥想象力。
解法:改进检索质量,加 Grounding 验证,每个回答都要能追溯到信息来源,不能空口说白话。
问题5:用户投诉突然变多技术指标看起来一切正常,但用户越来越不满意。这说明你监控的指标跟用户真正在意的东西对不上。你盯着延迟,用户其实在意准确性;你盯着成功率,用户其实在意回答有没有用。
解法:完善日志覆盖,主动收集用户反馈——哪怕只是加个点赞/踩按钮也行。
3 行代码开启全链路追踪
说了这么多,追踪怎么开?其实挺简单的,Azure AI Tracing 就这几行:
`python
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
# 启用追踪——之后所有 Agent 调用都会自动记录到 Azure Monitor
project_client = AIProjectClient.from_connection_string(...)
project_client.telemetry.enable()
`
就这样。之后你的 Agent 每次执行,完整调用链路、每一步耗时、输入输出,全都自动记录到 Azure Monitor。出了问题,直接查记录,不用靠猜,也不用在日志里大海捞针。
不开追踪就是盲飞。开了,至少你知道自己在哪儿。
✅ 上线前必须确认的10件事
走到这里,给你一张清单,上线前对照着过一遍:
- ✅ 所有工具调用都设置了 timeout 和重试机制
- ✅ 开启了 Tracing,能看到完整执行链路
- ✅ 设置了 Logging,关键动作有记录
- ✅ 核心指标有监控告警(成功率、延迟 P99)
- ✅ 上下文窗口有压缩策略,不会因超长而截断
- ✅ 用离线评估集测试过,5个关键指标都达标
- ✅ 设置了 max_iterations,防止死循环
- ✅ 有成本控制机制(缓存 + 模型降级)
- ✅ RAG 检索质量经过验证,有 Grounding 机制
- ✅ 有用户反馈收集渠道(哪怕只是个点赞/踩按钮)
10条都打钩了,可以上线。打钩不到 8 条,再等等。
💡 留给你的思考题
- 可观测性和评估,你觉得哪个更重要?如果资源有限,优先做哪个?
- 评估指标设计得好不好,直接决定你能发现什么问题。你会怎么设计一套符合你自己场景的指标?
- 生产环境的很多问题,其实在原型阶段就能预防。你觉得哪些「原型好习惯」能减少上线后的坑?
第11课预告:Agent 协议三巨头——MCP、A2A、NLWeb,它们正在定义 AI 的互联网,期待的扣1。
AI 的世界每天都比昨天更陌生一点,但也更有意思一点。我们明天见。
