夜雨聆风
夜雨聆风到底什么才叫会写代码?
这几年来人类一直在挑战AI-Coding:你们到底懂不懂写代码?
2026年5月5日,Meta FAIR 联合斯坦福、哈佛等机构又发布了一个 ProgramBench,重新定义AI-Coding的评估方式。
答案很简单,暂时还不太行。ProgramBench 测试了9个语言模型,结果是——没有任何一个模型完全解决哪怕一个任务。 表现最好的模型也只做到了在3%的任务上通过95%的测试。而且模型倾向于生成单文件的“大泥球”式实现,和人类写的模块化代码截然不同。

这次和以前有什么区别?
你给了AI一个可执行应用文件、一个使用说明,它能不能自己仿照这个应用程序把整个软件项目从头搭起来——不是修一个bug,不是写一个函数,而是从零开始做架构决策、选语言、拆模块、定义接口,最后跑起来和原始程序一样?
这个问题听起来像是给AI设了个“图灵测试2.0”。但真要做这件事,必须先搞清楚一个更基本的问题:你拿什么标准判断AI做对了?检测它是不是抄了源代码?还是只看它做出来的东西能不能跑、跑出来的结果对不对?
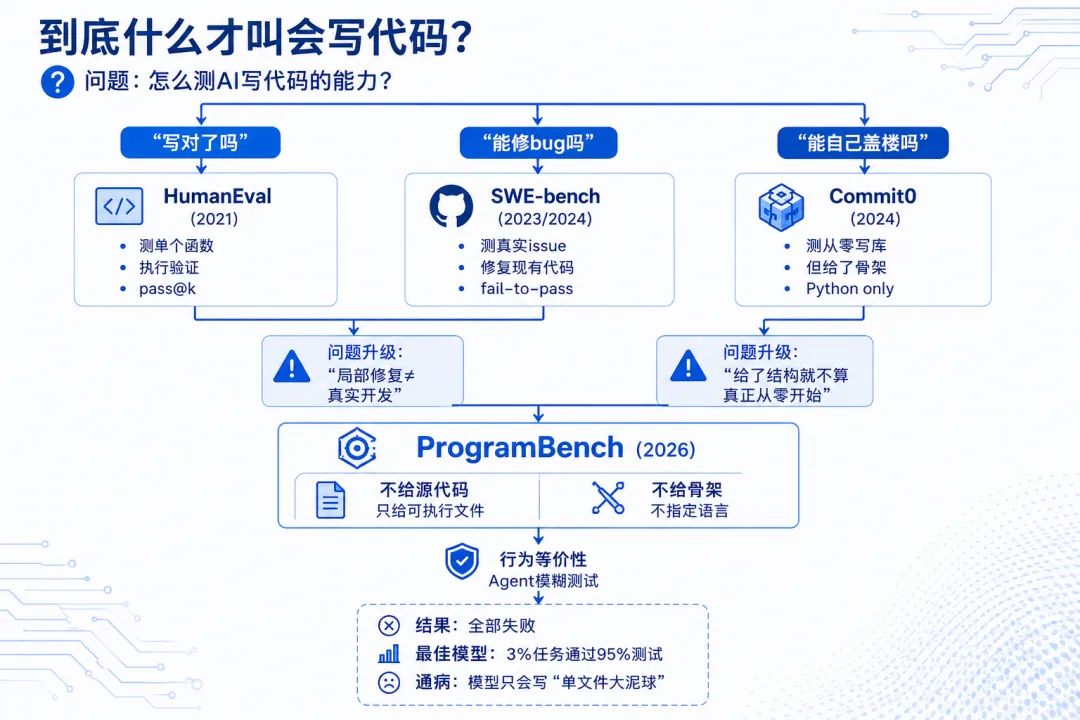
ProgramBench 就是冲着这个问题来的。但这个问题不是凭空冒出来的——它是一连串“被逼出来的进化”的最新一站。每次大家觉得“AI写代码已经够强了吧”,就有人发现:不对,现有的衡量标尺太窄了,测的不是真本事。

2021 | HumanEval / MBPP / APPS:给AI一个函数声明,让它填空
它看到了什么问题
在2021年之前,衡量“AI写代码”这件事根本没有统一的标尺。大部分评测要么用BLEU这样的文本相似度指标——这相当于用“学生写的字和标准答案像不像”来判断数学题答对了没有,荒唐但没人在意;要么就是一些在小范围论文里定义的自制任务,谁跟谁都不好比。
OpenAI 在2021年同时甩出两篇论文(HumanEval 和 MBPP),直接把问题挑明了:以前的评测方式在作弊。 你拿BLEU去比两段代码,哪怕语义一模一样,换了个变量名或者换了种写法,BLEU就给低分。这根本不是在测“能不能写对”,是在测“能不能背下来”。
它的解法
HumanEval 的思路极其简单粗暴:设计164道手写的Python编程题,每个题一个函数声明(比如 def add(a, b):)加上一段描述这个函数该做什么的文档字符串(比如 """Return the sum of a and b."""),让模型补全函数体。然后不是看长得像不像——直接跑测试用例,跑过了就算对。这就引出了 pass@k 这个指标:给模型生成k个候选,只要有一个跑通了就算过。
MBPP 也类似,974道题,但题目更简单、由众包工作者编写,覆盖更多基础编程场景。APPS 则走了另一条路:从编程竞赛里扒题,难度上天,但评测思路一致——执行验证。
为什么这招管用以及又挖了新坑
pass@k + 执行验证的组合拳太有效了,从此成了代码生成评测的事实标准。到今天几乎所有论文还在用这个范式。
但问题很快暴露了:这164道题的难度天花板太低了。 到2022年底,GPT-3.5 在 HumanEval 上已经接近满分。HumanEval 变成了一个“及格线”——你可以拿来证明“我的模型也能写代码”,但已经分不出谁更强了。更致命的是,这些题都是一次性填空,给一个函数声明、补一个函数体——这跟真实世界写软件差了十万八千里。真实场景是你面对几十万行代码,要从一个模糊的需求描述里找到改哪里、怎么改。
2023/2024 | SWE-bench:从 GitHub 真实 issue 到补丁
它看到了什么问题
在2023年底,所有代码模型都能在 HumanEval 上刷到不错的分数,但没人知道它们在真实工作中到底行不行。一个程序员日常工作的大部分时间不是在写一个新函数,而是在读别人的代码、理解一个bug报告、找到要改的地方、改对了还不引入新bug。HumanEval 把“写一个函数”从真实工作场景里抽离了出来,让它变得像一道考试题——但软件开发不是考试。
SWE-bench 的作者 Jimenez 等人把这个问题说得更具体:之前的评测都把“代码生成”当成一个独立动作,但真实世界的软件工程是一个“理解-定位-修改-验证”的闭环。 没有哪个 benchmark 在测这个闭环。
它的解法
SWE-bench 的构造方法是一记重锤:从12个流行Python仓库(django、sympy、flask、matplotlib...)的真实 GitHub issue 和对应 PR 中,筛选出2294个任务。每个任务给出三样东西:
- 一个完整的代码仓库
- 一个真实的 issue 描述(用户报告的问题)
- 评价标准:PR 里自带的测试用例
模型要做的:理解 issue,定位到代码的哪部分需要改,生成补丁,跑测试验证。测试分两种:fail-to-pass(在修复前失败、修复后通过的测试——这才是真正验证“修好了”的)和 pass-to-pass(之前和之后都通过的——验证“没引入回归”)。
为什么这招管用以及又挖了新坑
SWE-bench 一出,所有模型都掉了一大截。GPT-4 在 HumanEval 上90%+,在 SWE-bench 上不到5%。它真正把评测的难度拉升到了“真实问题”的级别。
但它也有一个先天局限:它测的是修修补补,不是从零搭建。 每个任务的前提是“你已经有了一个巨大的现有代码库,只需改一小块”。这当然反映了一大类真实工作,但忽略了另一种越来越重要的场景:AI能不能自己搭一个完整的项目?如果任务根本不是“修一个现成的库”,而是“老板说咱们要做一个新工具,你先搭个原型出来”呢?
这个问题不是 SWE-bench 该回答的,但它是下一个问题。
2024.12 | Commit0:测测你能不能从零写一个库
它看到了什么问题
SWE-bench 火了之后,大家发现AI修bug的能力确实在进步。但 Zhao 等人注意到另一个方向几乎没人碰:让AI从零生成一个完整的库。 这不是修修补补,是要设计API、组织模块、处理跨文件依赖。
不过,Commit0 也看到了 SWE-bench 的另一个问题:SWE-bench 的任务对资深工程师来说是“可以完成的工作”。 如果AI持续进步,这些修修补补的任务早晚会被彻底攻克。但“从零写一个库”的复杂度是另一个量级——你要处理的是长程依赖、跨函数的协调、数百页的API规范。
它的解法
Commit0 选取了54个Python库,做法是:把每个库的所有函数和类的实现擦掉,只保留声明和骨架,然后给AI一份规范文档和测试用例。AI需要做的是:把这个库的实现重新填回去,跑通全部测试。
更重要的是,Commit0 设计了一个交互式反馈循环——AI不是一次生成完所有代码,而是先写一部分、跑测试、看反馈、再改。这更接近真实开发者的工作方式。
为什么这招管用以及又挖了新坑
Commit0 往前走了一大步,但 ProgramBench 的作者们指出一个关键的、微妙的问题:它还是给了骨架。 所有的函数声明、类结构、模块划分都已经定好了。AI只是把内容填进去。
这就相当于考试的时候,试卷上不仅写了题目,还写了“第一题用函数A,第二题用类B,模块结构是C”。架构决策——什么抽象该引入、功能怎么拆分、模块间用什么协议通信——这些最核心的软件设计问题,Commit0 替AI做了。模型依然没有被测到“做架构决策”的能力。
此外,Commit0 只覆盖Python,而现实世界的软件生态远比这丰富。
2026.05 | ProgramBench:只给一个可执行文件,你重写一遍
它看到了什么问题
到了2026年,软件工程Agent已经开始被部署来自动化种子项目、维护代码库、甚至在长周期内自主迭代。这些场景要求模型能做高层次架构决策——不是填空,是从头设计。但所有现有 benchmark 不管怎么进化,都共享一个隐含假设:“结构已经被定义了,你只要实现它”。
ProgramBench 的作者们把这个问题推到了极致:如果你连“用什么语言写”都不能告诉模型,让它完全自由发挥,它还能不能做出来一个功能上等价的东西?
它的解法
ProgramBench 做了一个激进的设定:不给你任何源代码,不给你任何骨架,甚至不指定语言。 它只给你两样东西:
- 一个参考程序的可执行文件
- 这个程序的文档
你的任务:造一个代码库,跑起来的行为和那个可执行文件一模一样。至于你用什么语言、拆几个模块、定义什么数据结构——完全自己定。
评估方式也跟上了这个设定:不用预定义的测试套件(因为测试套件也是针对特定实现写的),而是用Agent驱动的模糊测试(fuzzing)——让Agent自动生成测试用例,比较参考实现和模型实现的输出是否一致。这叫“行为等价性测试”:只要行为一样,任何实现都是对的。
200个任务从简单的CLI工具一路覆盖到FFmpeg、SQLite、PHP解释器这种大型软件,跨越 C/C++、Rust、Go、Java、Haskell 等多语言生态。
结果(相当震撼):
ProgramBench 测试了9个语言模型,结果是——没有任何一个模型完全解决哪怕一个任务。 表现最好的模型也只做到了在3%的任务上通过95%的测试。而且模型倾向于生成单文件的“大泥球(Big Ball of Mud)”式实现,和人类写的模块化代码截然不同。
什么是Big Ball of Mud?
这个词最早出自 Brian Foote 和 Joseph Yoder 在 1997 年发表的同名论文 《Big Ball of Mud》,发表后很快就在软件开发领域流传开来。
根据这篇经典定义,“大泥球”指的是一个随意结构化、蔓延、不经心、意大利面条式代码的乱七八糟混合体。它最核心的特征是:缺乏清晰、可认知的架构。
在 ProgramBench 的论文和相关报道中,对这种现象的英文描述是:
Models favor monolithic, single-file implementations that diverge sharply from human-written code.
https://arxiv.org/abs/2605.03546
翻译过来就是:模型倾向于生成单体式、单文件的实现,与人类编写的代码截然不同。
我们可以这样理解这个事儿:人类倾向于把系统设计得像一个组织严密的图书馆,书架、标签、分区清清楚楚;而当前的主流模型更像是把所有图书不加分类地堆在一个巨大的房间里,虽然可能找得到,但维护和扩展起来极其困难。
下一步演化是什么呢?
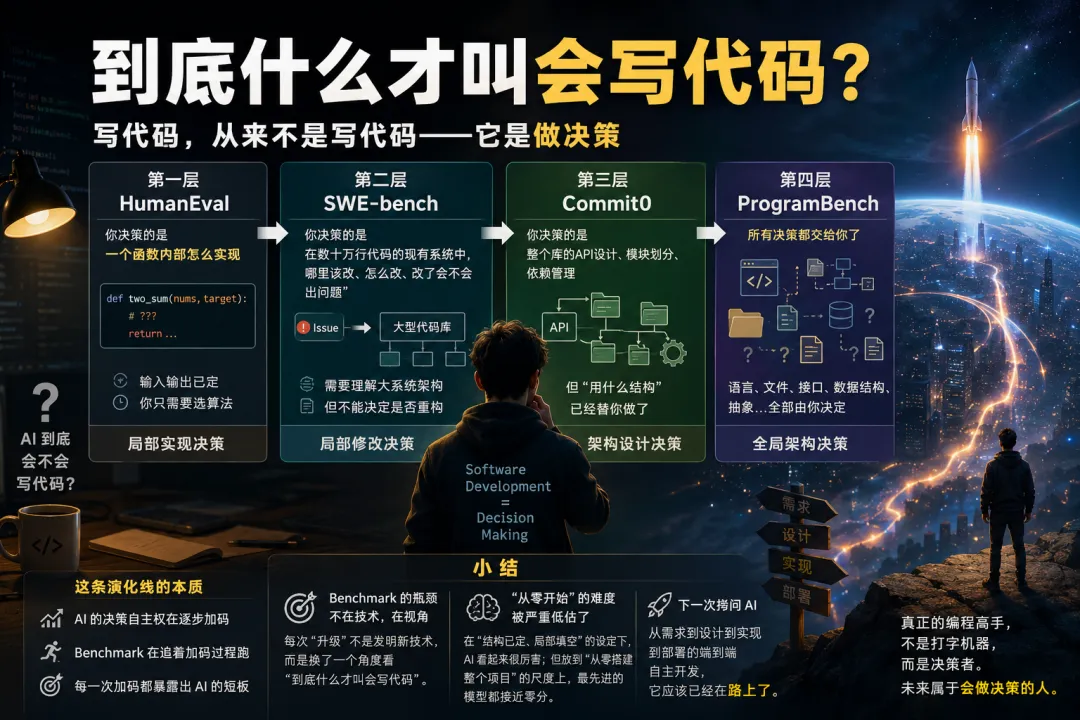
都说程序员要失业,但是几十年来程序员一直在做的一件事正在逐渐被正名:“写代码”从来不是“写代码”——它是“做决策”。
人类拷问AI你到底会不会写代码,这条演化路线有一个清晰的递进逻辑:
第一层(HumanEval):你决策的是一个函数内部怎么实现。输入输出已定,你只需要选算法。
第二层(SWE-bench):你决策的是“在数十万行代码的现有系统中,哪里该改、怎么改、改了会不会出问题”。你已经需要理解一个大系统的架构了,但“要不要重构”这个级别的决策你还做不了——你只是在现有架构上修修补补。
第三层(Commit0):你决策的范围扩展到整个库——怎么做API设计、模块怎么切、依赖怎么管。但最大的决策——“这个库该用什么结构”——已经替你做了。你仍然是个高级填空者。
第四层(ProgramBench):所有决策都交给你了。用什么语言、拆几个文件、定义什么接口、选什么数据结构、做什么抽象——这才是真正的软件架构决策。
这条线背后真正的变化是:AI的决策自主权在逐步加码,而 benchmark 在追着这个加码过程跑。每一次加码都暴露出AI在更高层次的决策能力上的短板。
下一步最可能的方向有两个:
- 架构质量评测——ProgramBench 发现模型只会写“单文件大泥球”,那下一个问题就是:怎么定义“好的软件架构”?怎么量化它?能不能让AI学会它?这个方向会催生“代码架构美学”的 benchmark。拷问AI你懂不懂什么叫做“美”。
- 多Agent协作建软件——既然单模型做不了,那多个模型协作呢?一个做架构设计、一个写底层实现、一个负责测试——这已经开始贴近真实软件团队的运作方式。
小结
- benchmark 的瓶颈不在技术,在视角。每次“升级”都不是发明了新的评测技术,而是有人换了一个角度看“到底什么才叫会写代码”。
- “从零开始”的难度被严重低估了。所有人都觉得AI写代码已经很厉害了,但放到“从零搭建整个项目”的尺度上,连最先进的模型都接近零分。这提醒我们:我们看到的“AI写代码很厉害”,大部分是在“结构已定、局部填空”的设定下。
- 下一次拷问AI——可能是“从需求到设计到实现到部署的端到端自主开发”——它应该已经在路上了。