 夜雨聆风
夜雨聆风

来源:朝阳资本论
作者:沙华
互联网时代,中国公司多少抄了点“美国作业”,学雅虎、亚马逊、谷歌。但到了AI大模型时代,这个剧本翻篇了。
摩根大通研报将2026年定义为中国企业AI需求能否复制2025年美国增长曲线的关键一年。市场普遍也习惯于用“时间轴”讨论中国AI还需要追赶美国AI多久。
但这个判断预设了一个前提:中美在同一个赛道上赛跑,只是速度有快慢。
事实恰恰相反。
美国AI关键词是“集中”。
随着马斯克将Colossus超算集群转租给Anthropic,加速了寡头格局。Anthropic手握谷歌、亚马逊、英伟达的资金,OpenAI绑定微软,谷歌Gemini依托自家生态。三足鼎立之势已成。
中国却是另一番群雄并起的格局。
继大模型双雄上市,DeepSeek首轮融资估值冲到450亿美元,阶跃星辰筹划分拆赴港IPO,月之暗面半年融了39亿美元。与此同时,豆包上线付费订阅,智谱连续提价,Kimi也在涨价,说明头部大模型都很有商业竞争力。
与其说在追赶,不如说中国AI正在用一种差异化的姿态,推进颇具中国特色的产业化,迎来“资本+应用”的新拐点。
中国大模型不再以美国为坐标系追赶,那该用什么标准定义这场科技长跑?

中美大模型走出完全不同的叙事,并不那么意外。
美国的商业环境天然倾向赢家通吃,资本市场高度集中,风险投资的逻辑是押注头部、快速退出,加上几家云计算巨头手里握着天量算力资源,最终必然走向寡头。
根据美国金融科技公司Ramp报告,截至2026年3月,OpenAI企业客户份额为35.2%,Anthropic为30.6%,再加上谷歌Gemini,三家公司基本锁死了市场的大部分空间。
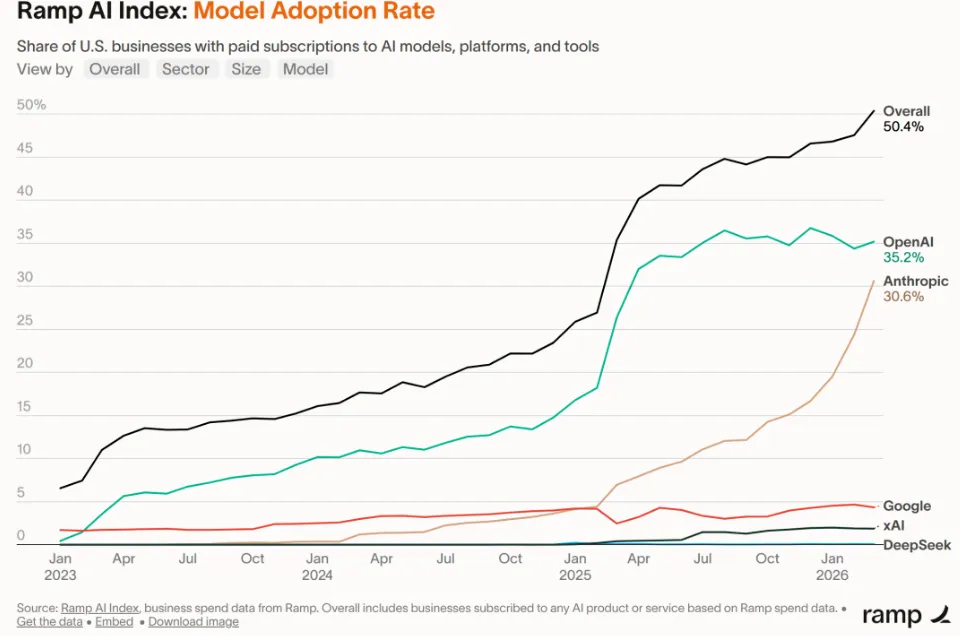
进一步促成这个格局的关键事件之一,就是马斯克把Colossus超算集群租给了Anthropic。毕竟在资本眼里,算力成本太高了,单打独斗不划算。类似的事情也在谷歌、亚马逊、微软身上上演。
美国巨头的逻辑是用资本和算力做杠杆,撬动一个寡头市场,然后再用规模效应去拿企业订单,年化收入很快就能冲到百亿美元级别。
这种集中度,和当年搜索、社交、电商领域最终的终局很像,巨头掌控资源,客户生态需要“自适应”。
而中国的产业生态更加碎片化,资本市场有大量产业资本,加上制造业、消费互联网等场景极其丰富,模型公司更容易通过绑定具体行业来找到生存空间。
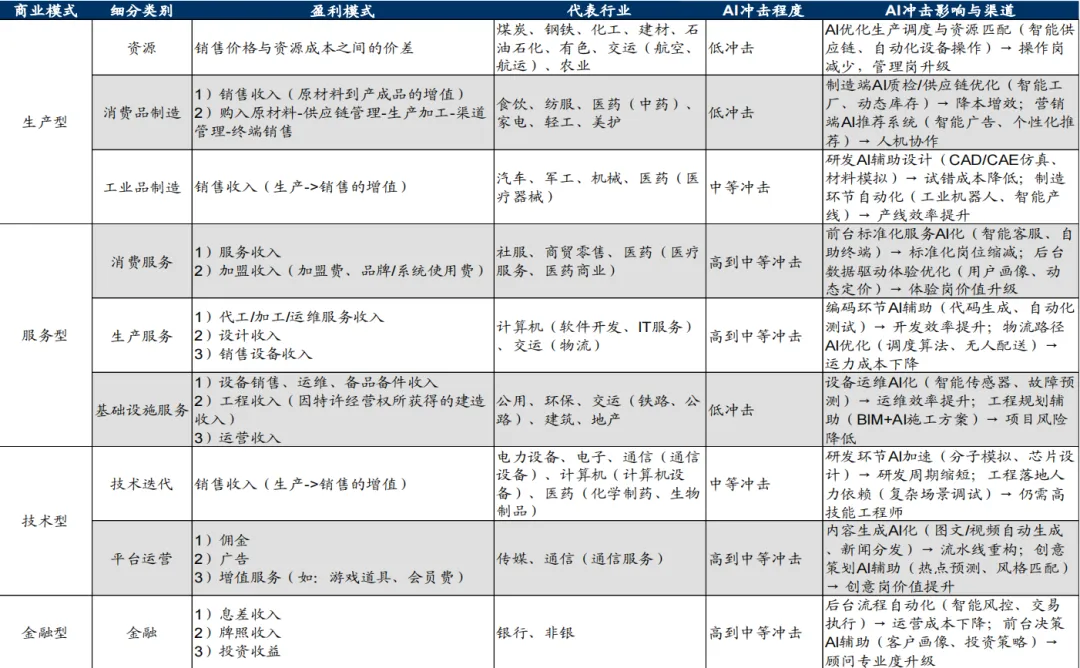
图源:华创证券
看中国大模型公司的融资名单,阶跃星辰投资方里排在前面的是华勤、龙旗、豪威、中兴这些消费电子产业链上的公司。月之暗面拿了20亿美元,背后站着的是阿里巴巴、小红书、美团这些既有场景又有流量的平台方。DeepSeek首轮融资估值冲到450亿美元,接洽的是国家大基金。
这些钱的共同特点是,带有产业资源。
中国大模型公司主动或者被动地融入了中国庞大的产业生态。不是说融了钱就可以随便烧算力,投资人会问,模型能不能装进我的手机?能不能跑在我的芯片上?能不能帮工厂的产线降本?
产业资本进来,不单纯是追求财务回报,更是为了把自己的业务用AI重做一遍。
所以中美AI的格局差异,不是谁更先进谁更落后的差异,而是底层驱动逻辑的差异。
美国是寡头带着资本和算力自上而下塑造生态,中国是大模型公司深入产业自下而上寻找闭环。
一种是用规模定义赢家,一种是用场景验证价值。

理解中国大模型为什么没有走美国的寡头路线,关键在于一个更深层的判断:技术代差的时间窗口正在关闭。
过去,AI竞争信奉“最强模型=最高溢价”,各项基准测试中的SOTA就是风向标。
但当模型差距从“代际”缩至“月级”,比拼的重心就转向了成本、应用、产业三条战线。
成本侧,美国大模型的竞争逻辑建立在算力军备竞赛之上,谁的GPU多,谁的模型就强。但中国公司在做的,是系统性地降低Token的单位成本。
一个最直观的数据:据公开信息,MiniMax的API定价约为美国同类模型的二十二分之一。
中国公司用二十二分之一的成本做到七八成的效果,美国模型的那点智力领先在商业上就不再是不可逾越的壁垒。
与此同时,国产算力也在快速追赶。华为昇腾系列芯片的生态正在完善,虽然单卡性能与英伟达最顶尖产品仍有差距,但通过集群调度和模型并行策略,可以在整体成本上做出更有竞争力的方案。
应用侧,中国拥有全球最丰富的工业体系和最复杂的消费互联网生态。
从抖音的短视频,到阿里巴巴的电商搜索,再到美团的外卖调度,这些场景每天产生海量、高频、多元的真实交互数据。

图:豆包视频生成模型Seedance 2.0
模型进入这些场景,不需要在实验室里刷榜,而是在这些场景里被用户骂、被用户纠正、被用户训练。
摩根大通在最新研报中给了一个关键判断,中国AI行业智能体场景中“任务完成率”远比“Token单价”更能决定客户留存。
这种应用侧的红利,是美国那套以程序员工具和企业软件为核心的生态不具备的。
最后看产业侧。摩根大通有一个判断正在被验证:AI正从消费端功能进化为直接创造企业收入的工具。
中国的特殊性在于,大模型厂商与本土产业不是甲方乙方的关系,而是深度绑定的共生关系。
据中国通信工业协会数据中心委员会联合发布的《AI智能体赋能行业决策白皮书(2026)》显示,金融、工业、医疗的AI渗透率均超过百分之五十,AI智能体已经深度融入风控、设备巡检、辅助诊断等核心业务流程。
庞大的产业体系,给了大模型企业八仙过海的机会空间。
比如,DeepSeek走的是全开源路线,阶跃星辰深度绑定OPPO、荣耀、吉利等厂商,阿里千问直接长在淘宝、高德、飞猪的生态里。此外,智谱聚焦MaaS平台,API调用量在涨价后反而暴涨,证明企业客户对它的依赖已经形成。
图:阶跃星辰端到端语音模型
开发者社区、嵌入硬件、消费生态、MaaS,中国AI企业各自找到了一条产业链里的“插座”,然后把模型能力插进去,变成那个生态里不可或缺的一部分。
产业侧的深度绑定,让中国能够形成“应用反哺模型”的正向循环:场景越多,数据越多;数据越多,模型越准;模型越准,场景就能进一步扩展。
因此,中国大模型行业不是被动地追赶美国的技术领先,而是在主动开辟一条美国没有走的赛道。
这条赛道的未来是更低成本、更高频次、更深嵌入的AI基础设施。

从资本化到商业化加速,2026年是中国AI价值兑现的关键之年。
但这条兑现路径和美国有着显著区别。
随巨头格局形成,美国AI下一步将是价值链的纵向整合。利润集中在掌握了最高定价权的模型层和算力层,包括上游的英伟达,中游的OpenAI、Anthropic、谷歌。
未来两到三年,美国AI产业的价值会继续向上游集中,而应用层的价值释放需要等到算力成本和模型调用的边际成本进一步下降之后。
相比之下,中国这边正在发生的是一场更深层的规则重建。
从国家网信办、国家发展改革委、工信部三部门联合印发《智能体规范应用与创新发展实施意见》,到工信部、国家数据局联合启动2026年“模数共振”行动,面向钢铁、汽车、医疗装备、消费电子等二十多个行业,顶层设计的逻辑就是AI是用来赋能的。
就像电力革命催生了无数个使用电力的工厂、设备和商业模式,扎根产业的中国大模型也会走这条路。
拆开来看,最底层是基础设施层,一个多层次、多极化的生态格局。
中国大模型行业在出现类似操作系统时代的分层。DeepSeek是开源的基础能力提供方,类似Linux;智谱是标准化的MaaS中间层平台,类似一个企业级的“模型操作系统”。这些公司可以长期共存,实现层层嵌套的生态分工。
中间层是超级入口和垂直应用,这一层会诞生真正的国民级AI工具。
比如,千问、豆包作为超级应用入口,控制用户接触AI的第一界面。
图:阿里千问APP订机票
与此同时,在金融、制造、医疗这些垂直领域,也会有大量垂直应用跑出来,它们调用DeepSeek或智谱的API,这一层的玩家会非常分散。
最上面一层是生态赋能层。
腾讯、阿里、字节这些拥有完整商业闭环的巨头,会把AI内化成自己生态的底层能力。这类公司的价值不在于拥有最强模型,而在于拥有最会使用模型的庞大生态。
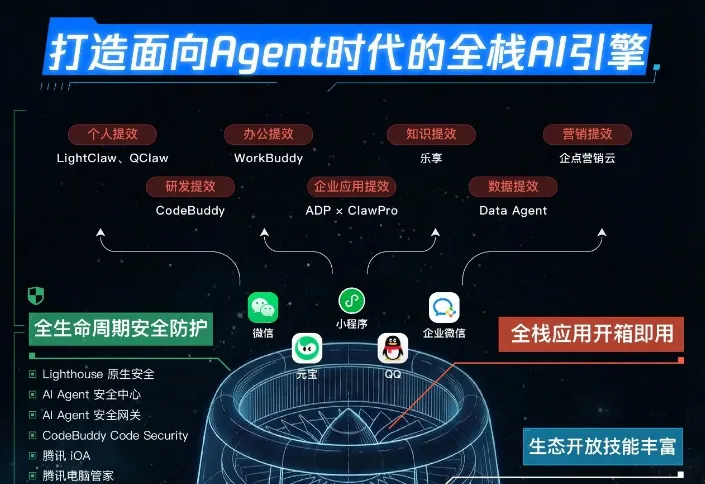
图:腾讯云Agent产品全景图(部分)
把这三个层次放在一起看,会发现AI的红利正在从技术提供者手中,流向应用创新者和生态构建者。
接下来几年,大模型企业抢的是谁能用模型做出最好的产品、服务最具体的场景。模型本身会越来越像一种公用事业,重要,但不再稀缺。
稀缺的反而是那个能说出“需要AI做什么”的洞察力。
从这个角度看,中国大模型行业的战国争霸不会以少数几个赢家通吃收场,而是会演变成一场生态位分化的竞赛。
一张由开源基础设施、垂直应用、超级生态交织成的网络里,AI像电力一样,流进每一个工厂、每一家医院、每一部手机。
中国AI产业正在书写的,是一部关于如何将超级智力转化为普惠生产力的全新产业规则。




