 夜雨聆风
夜雨聆风
April 13th - April 26th, 2026 - Big Data & AI Industry Newsletter
Editor's Take
01
Tech & Products
02
Data & Analytics Platforms
2.1
●Snowflake Product Releases and Updates:
○ Snowflake releases database engine version 10.14:
■ Security Updates:
● Session policy adds maximum session lifespan: Session policies now support terminating sessions after a fixed duration, not just idle timeout control. Two new properties, SESSION_MAX_LIFESPAN_MINS and SESSION_UI_MAX_LIFESPAN_MINS, apply to programmatic access/client and Snowsight respectively; configurable range is 0–43200 minutes, where 0 means no enforced maximum lifespan. This capability helps administrators require users to re-authenticate after a fixed period, enhancing long-term session security governance.
■ Data Governance Updates:
● Schema-level Data Metric Functions (GA): Data Metric Functions (DMFs) now support association at the schema level, allowing ROW_COUNT or FRESHNESS system DMFs to be applied to all table-like objects in a schema with a single SQL statement. Supports anomaly detection, exclusion of specific object types, and overrides for individual tables/views, reducing configuration complexity for large-scale data quality monitoring.
● New fields in DATA_METRIC_FUNCTION_REFERENCES: INFORMATION_SCHEMA.DATA_METRIC_FUNCTION_REFERENCES function and ACCOUNT_USAGE.DATA_METRIC_FUNCTION_REFERENCES view now include level and exclude_table_types fields to distinguish whether a DMF is directly configured at the table level or inherited through schema-level configuration, and to show excluded object types.
■ New Features:
● Dynamic table support for outer joins extended: Incrementally refreshed dynamic tables now support more outer join scenarios, including joins where both sides are the same table, and joins where both sides include GROUP BY subqueries, enhancing dynamic table adaptability to complex query patterns.
● New ACCUMULATE aggregate function: ACCUMULATE allows computation of custom aggregate values using user-defined SQL Lambdas for initialization, accumulation, merging, and termination stages, based on a map-reduce model. Usage is consistent with built-in aggregate functions and can be combined with GROUP BY, HAVING, and subqueries.
○ Trust Center Data Security Features Generally Available (GA): The Trust Center data security experience in Snowsight is now GA. This feature automatically classifies sensitive data in the database without SQL, identifying PII, PCI, PHI, and other regulated or high-risk data categories, and centrally displays data locations, potential compliance mappings, and whether masking policies are applied.
○ Snowflake announces major updates to Snowflake Intelligence and Cortex Code on April 21, positioning itself as the "control plane for the agentic enterprise." Snowflake Intelligence now acts as a personalized work agent with Skills for natural-language multi-step workflow automation, Artifacts for saving and sharing analyses, MCP connectors for Gmail, Jira, Salesforce, and Slack, plus an iOS mobile app. Cortex Code expands with connectors for AWS Glue, Databricks, and Postgres, plus a VS Code extension, Claude Code plugin, and Python/TypeScript Agent SDK. (src: Snowflake Expands Snowflake Intelligence and Cortex Code to Power the Control Plane for the Agentic Enterprise)
○ Cortex AI Guardrails Generally Available (GA): Cortex AI Guardrails, part of Snowflake Horizon Catalog, is now GA. It provides runtime protection for Cortex Code, reducing risks from prompt injection and jailbreak attacks, enhancing security boundaries for AI development and execution scenarios.
○ arctic-extract Model Fine-Tuning Generally Available (GA): Users can fine-tune the arctic-extract model using their own documents and business domain for more stable structured information extraction. The fine-tuned model can be used for inference via AI_EXTRACT. Fine-tuning tasks now support an options parameter, e.g., max_epochs for controlling training iterations; training datasets can reference files from internal or external stages.
○ Cortex Search Request Monitoring (Preview): Cortex Search request monitoring enters public preview. Users can enable request logs on Cortex Search Service to collect detailed information for monitoring and debugging query patterns, response times, and request details. Logs are stored in SNOWFLAKE.LOCAL.AI_OBSERVABILITY_EVENTS event table, accessible via snowflake.local.get_ai_observability_events or directly queried by ACCOUNTADMIN.
○ Cortex Search Service Replication Generally Available (GA): Cortex Search Service replication is now GA, supporting copying from source accounts to one or more target accounts within the same organization via replication or failover groups, enhancing cross-account deployment, disaster recovery, and high availability.
○ Cortex Agents SQL Generation Improvements: Cortex Agents using Cortex Analyst semantic views can now generate SQL directly without delegating SQL generation to Cortex Analyst service, improving query accuracy and reducing latency. No Agent configuration or semantic view changes are required; cortex_analyst_text_to_sql blocks in response format are replaced by system_execute_sql; tokens and credits in observability data are unified under cortex_agents.
○ Snowflake Data Clean Rooms Updates:
■ Clean Rooms API Version 14.6: Data providers can now use VIEW_DATA_OFFERINGS to view the names and column policies of Freeform SQL data products, improving visibility into product configurations; includes private preview updates.
■ Clean Rooms API Version 14.4: This update includes general performance optimizations, bug fixes, and private preview updates. Clean Rooms UI updates take effect automatically after the user re-logs and starts a new session; API updates can be applied manually or automatically to the account.
○ Snowpipe Streaming High-Performance Architecture Generally Available (GA) in China: Snowpipe Streaming's high-performance architecture is now GA in China, extending regional coverage for high-throughput, low-latency streaming ingestion.
○ Snowflake Connector for Kafka 4.0 Generally Available (GA): Kafka Connector 4.0, rebuilt on Snowflake high-performance Snowpipe Streaming architecture, supports up to 10 GB/s per table, 5–10 second end-to-end latency, exactly-once and ordered delivery semantics. GA version includes throughput-based pricing, server-side validation and schema evolution via PIPE objects, in-transit transformation via COPY syntax, pre-clustering, error tables, dead-letter queues, Iceberg table ingestion, and seamless migration from 3.x.
○ Openflow Connector for HubSpot (Preview): Openflow Connector for HubSpot enters preview, ingesting HubSpot CRM data into Snowflake via HubSpot API. The connector performs an initial full load, then incrementally merges new and changed records based on last run timestamps.
○ Dynamic Tables Support Primary Keys (GA): Snowflake now supports using primary keys in dynamic tables to track row-level changes and supports incremental refresh downstream of full-refresh dynamic tables. Capabilities include using RELY attribute primary keys in base tables for change tracking; deriving primary keys automatically from dynamic table query definitions (e.g., GROUP BY or QUALIFY ROW_NUMBER() = 1 scenarios); and allowing incremental refresh dynamic tables to read upstream full-refresh dynamic tables with system-derived primary keys.
○ Apache Iceberg Tables Support External Catalog and Column Description Two-Way Sync (GA): Snowflake can now synchronize tables and column descriptions bidirectionally between external Iceberg REST Catalogs and catalog-linked databases. Sync updates description values but does not overwrite non-empty descriptions with empty values. If the external catalog has a description and the Snowflake object is empty, refresh copies the external description; if Snowflake sets a description via COMMENT and the external is empty, it propagates back.
○ Apache Iceberg Tables Support Snowflake Storage (Preview): Users can now create Apache Iceberg tables using Snowflake storage, with Snowflake managing Iceberg table files without separate external cloud storage configuration. Like standard Snowflake tables, these Iceberg tables support Fail-safe data protection for permanent tables, can be transient to reduce storage costs, and are accessible by external query engines via Snowflake Horizon Catalog.
○ Dynamic Apache Iceberg Tables Support PARTITION BY, TARGET_FILE_SIZE, and PATH_LAYOUT (GA): Dynamic Apache Iceberg tables now support additional table property configurations, including Iceberg partition expressions for PARTITION BY, TARGET_FILE_SIZE for controlling Parquet file write size, and PATH_LAYOUT to choose flat or Hive-style hierarchical directory layouts. This improves flexibility in data organization, file size control, and partition-aware path writing for dynamic Iceberg tables.
○ Storage Lifecycle Policies Support Google Cloud: Storage lifecycle policies now support Google Cloud archiving. Google Cloud accounts can create archive policies using COOL or COLD storage tiers. COOL now covers AWS, Microsoft Azure, and Google Cloud; COLD supports AWS and Google Cloud.
○ Snowflake Native Apps Support Consumer-Controlled Maintenance Policies (Provider Side, Preview): Native Apps providers can configure release instructions to follow consumer maintenance policies, e.g., setting UPGRADE_IN_MAINTENANCE_WINDOW; can also use AUTOMATIC_APPLICATION_MAINTENANCE to align Snowpark Container Services compute node maintenance with consumer maintenance windows.
○ Performance Explorer Experience Enhancements: Snowsight Performance Explorer now has Queries, Warehouses, and Tables tabs for easier switching between metrics; supports saving filter presets and setting default presets; allows exporting sidebar detail tables to CSV; supports keyword search in sidebar details, e.g., username or query text snippets.
○ Snowflake Documentation Optimized for AI Agents and LLMs: Snowflake documentation now has a structure better suited for AI coding assistants, agents, and large language models. llms.txt changed to hierarchical structure linking to document partition indexes for on-demand context retrieval, reducing token consumption and improving relevance; each page can be accessed in Markdown by appending .md to the URL, reducing HTML navigation and scripts. (src: All release notes)
● Databricks
○ Databricks Platform:
■ Confluence Connector Generally Available (GA). The managed connector in Lakeflow Connect for ingesting Confluence data is now officially GA.
■ Supervisor Agent can be programmatically managed via Databricks SDK, currently in Beta. Users can create and manage Supervisor Agents and their tools using Databricks SDK for Python.
■ OpenAI GPT-5.5 and GPT-5.5 Pro are now available as Databricks managed models. Mosaic AI Model Serving now supports access to these models via Foundation Model APIs with pay-per-Token pricing.
■ Databricks Excel Add-in now requires workspace administrators to enable the Excel Connector preview on the Previews page.
■ Workspace Base Environments Generally Available (GA). Workspace admins can create and manage prebuilt, cached base environments for serverless notebooks.
■ Lakeflow Designer enters public preview. Users can build data transformation workflows using drag-and-drop canvas and natural language.
■ Catalog Explorer AI-generated annotations now support language selection. Users can change the default language of AI-generated comments, which is saved in local browser storage.
■ AI Runtime supports 1xH100 accelerator, currently in Beta.
■ Model Serving adds CPU_MEDIUM and CPU_LARGE workload types, currently in Beta, allowing higher per-worker memory on the same CPU hardware in exchange for concurrency.
■ Databricks Data Classification Generally Available (GA). Agentic AI can automatically identify and tag sensitive data in Unity Catalog.
■ Lakebase supports OpenTelemetry export, currently in Beta, allowing Postgres metrics and logs to be exported to OTLP-compatible observability backends.
■ Supervisor API enters Beta, allowing agents to be built by defining models, tools, and instructions in a single API call.
■ Power BI connector removes BI compatibility mode; reports depending on this mode for Unity Catalog metric views will no longer work.
■ Modify catalog or schema managed storage location functionality Generally Available (GA).
■ Databricks Connector for Google Sheets Generally Available (GA), enabling import and query of Unity Catalog data, including metric views.
■ Anthropic Claude Opus 4.7 available as Databricks managed model, supporting reasoning and vision models via Foundation Model APIs.
■ ai_parse_document function Generally Available (GA), parsing structured content from PDF, image, Word, PowerPoint, etc., with limits of 500 pages / 100 MB.
■ Spark driver, worker, and event logs delivery to Unity Catalog volumes Generally Available (GA), recommended as the logging storage approach.
■ Customer-managed keys now support Model Serving, encrypting Databricks-managed registry container images and model artifacts.
■ Lakeflow Connect query-based connectors enter public preview, enabling direct querying of source databases via cursor columns without CDC or ingestion gateway; supports Oracle, Teradata, SQL Server, MySQL, MariaDB, PostgreSQL, and Lakehouse Federation sources.
■ Sample Data Explorer with Genie Code Generally Available (GA), allowing natural language queries on Unity Catalog tables with returned SQL queries.
■ Databricks Apps console navigation updated for improved app editing, deployment, and monitoring; accessible via workspace top-right app switcher.
■ AI Gateway can now govern MCP servers, currently in Beta, enabling access control, usage monitoring, and auditing for MCP interactions within workspace.
■ AWS custom usage tag character limits updated: tag key/value cannot contain spaces or /, tag key cannot be ., .., or _index only.
■ Lakebase Autoscaling supports customer-managed keys, allowing project data encryption via user-managed cloud KMS.
■ Unity REST API supports external Delta clients reading, writing, and creating Unity Catalog external tables; creation and write of managed Delta tables in Beta.
■ SAP BDC column-level personal data governance tags can sync to Unity Catalog, including fieldSemantics, isPotentiallyPersonal, and isPotentiallySensitive, usable for ABAC policies.
■ Lovable-hosted apps can connect to Databricks workspace and query Lakehouse data via REST API with OAuth machine-to-machine authentication.
■ Mosaic AI Vector Search adds built-in retrieval quality evaluation, allowing measurement and comparison of retrieval strategy relevance, currently in Beta.
■ Databricks SQL reference adds five governed tag management statements: CREATE, ALTER, DROP, DESCRIBE, SHOW GOVERNED TAGS.
○ AI/BI:
■ Dashboard enhancements and fixes:
● Tables support cross-filtering and drill-through.
● Counters support custom prefixes and suffixes.
● Adding a table from schema browser to dashboard now defaults to creating a local metric view, not SQL dataset, currently in public preview.
● Fixed issue where dashboards briefly continued working after disabling service principal.
■ Genie search enhancement: can directly search Databricks Apps from Genie search bar.
■ Genie Code adds Space configuration capabilities to update Genie Space descriptions, example questions, and metadata.
■ Dashboard experience improvements:
● Shows explanation if warehouse overload causes rendering delays.
● Email subscriptions can include table attachments.
● Exiting fullscreen on published dashboards returns previous scroll position.
● Fixed issue where a single widget failure in a query batch caused other widgets to fail.
■ Visualization enhancements: line style supports dashed and dotted, configurable in Pattern section.
■ Genie Space enhancements:
● Access Genie reasoning traces via API, currently public preview.
● Add and list message comments via API, currently public preview.
● Agent mode conversation maximum token limit increased for improved long-turn dialogue performance and context retention.
■ Metric view enhancements: creating or editing measures and dimensions defaults to Builder mode, currently in public preview.
○ Databricks Runtime:
■ April 20 release included maintenance updates for multiple supported runtimes covering bug fixes, security patches, and performance improvements.
■ Databricks Runtime 18.1: fixes GEOMETRY(102100) CRS authority from EPSG:102100 to ESRI:102100; includes Spark-related fixes, rollbacks, and OS security updates.
■ Databricks Runtime 18.0: same GEOMETRY(102100) CRS authority fix; includes OS security updates.
■ Databricks Runtime 17.3 LTS: fixes GEOMETRY(102100) CRS authority; resolves data correctness issues with NULL struct incorrectly expanded to non-NULL struct in MERGE, UPDATE, and streaming writes.
○ Serverless Compute:
■ Serverless Compute Version 18.1 released April 20, roughly corresponding to Databricks Runtime 18.1.
■ New support: Microsoft Azure Synapse DATETIMEOFFSET type, BigQuery table comments mapping, INSERT ... WITH SCHEMA EVOLUTION, Delta Sharing multi-statement transaction, parse_timestamp, max_by/min_by optional limit, vector functions, SQL cursor, approximate top-k sketch, tuple sketch, and multiple geospatial functions.
■ Behavioral changes: observation metric collection errors no longer cause query failure; DESCRIBE FLOW now available; SpatialSQL boolean set operations implemented faster; SQLSTATE exception types updated. (src: update overview)
● Greenplum Product Releases and Updates:
○ Greenplum 7.8.0 Release:
■ New Features:
● VMware Tanzu Greenplum Companion Products and Connector Adjustments: PXF, GPSS, Greenplum Text, GemFire, Apache Spark, and Apache NiFi connectors are no longer included in the Greenplum 7.8.0 download package. They must be separately downloaded via the Broadcom Support portal and version compatibility verified.
● Introduction of pg_stat_statements Extension: Tracks execution statistics of all SQL statements on the server and provides cluster-level views and functions in Greenplum clusters.
● New gpctl start Tool: Starts database clusters based on the gpservice framework, providing clearer progress display, unified logging, enhanced error handling, and performance optimization.
● New gpctl movesegment Tool: Moves primary/mirror segments between hosts, enabling segment consolidation, migration, and configuration-driven placement.
● Introduction of Segment Groups (seggroups): Allows table data storage and query to be restricted to a subset of segments, enabling workload isolation, resource partitioning, and hardware allocation. Created via CREATE SEGGROUP; tables can specify via gp_default_table_seggroup parameter, roles, or tablespaces.
● Expanded gpservice Functionality: Added gpservice add-hosts command to register new hosts without reinitializing the service.
● New gp_toolkit.gp_copy_part_stats(source, destination): Copies statistics in partitioned tables, improving query plan quality before analyzing new partitions.
● New gpctl delete mirrors and gpctl init mirrors Tools: Support deleting or adding mirror segments in the cluster, enabling conversion between mirrored and non-mirrored clusters.
● New gpctl tde rewrap and gpctl tde status: Manage Transparent Data Encryption (TDE) segment key wrappers, supporting KMS key rotation and status checks.
● GPORCA Optimizer Enhancements:
○ Supports multi-level partitioned table queries without falling back to Postgres Planner.
○ Extends support for “Ghost Indexes,” including additional optimizations and columnar tables.
○ Provides experimental cost model for more accurate index cost estimation.
○ Supports plan hints to control ghost index generation.
● New PostGIS 2.5.4 Extension: Ensures GPDB 6 and 7 upgrade compatibility and supports later upgrades to PostGIS 3.3.2.
● Provides DataDirect ODBC Driver 08.02.0821.
■ Enhancements:
● gpload defaults to AO staging tables instead of heap tables, improving load performance; configurable via STAGING_TABLE_ACCESS_METHOD.
● GPORCA improves multi-segment execution plan generation for complex analytical workloads; Inner Nested Loop Join performance doubled.
● ANALYZE skips columns with statistics target 0, reducing coordinator memory usage.
● gpsupport log collection optimized to only capture logs within a specified timestamp range, reducing support package size.
● GPORCA adds NULL filtering for joins to reduce network traffic and skew.
● Major-version upgrade from GPDB 6 to GPDB 7 optimizes verification of hundreds of thousands of partitions using batch operations, speeding up the upgrade.
● TDE enhancements: covers WAL segments and temporary spill files, strengthening static data protection.
■ Resolved Issues:
● Fixed PostGIS extension creation failure (appendonly=true scenario).
● Fixed gpbackup failure in DR clusters caused by temporary tables.
● Fixed gpsupport log collection continuing after interrupt command.
● Fixed PostGIS crash when handling invalid address strings.
● QE query cancellation and termination responsiveness improved.
● Fixed partitioned table ANALYZE merge statistics issue.
● Coordinator prioritizes handling unlogged table reset errors.
● Fixed backup and restore data distribution errors due to gp_use_legacy_hashops differences across versions.
● Fixed cluster expansion failure involving pointcloud objects.
● Fixed inconsistent direct dispatch query results.
● Fixed GPORCA estimation and UNION query infinite loop.
● Fixed user-defined function failures under specific scenarios.
● Fixed gpcheckcloud HTTP POST header rules.
● Upgraded PostgresML to 2.8.5+greenplum.2.0.2; fixes single-row insert issues and adds batch control GUC.
● Upgraded PL/Container Python3 image to 3.2.4, resolving CVEs.
● Upgraded DataSciencePython3 to 3.0.5, resolving CVEs.
● Fixed gpcheckcat output ambiguity for segments.
■ Deprecated Features:
● Executor global work_mem GUC is no longer an independent per-operator memory limit; replaced by dynamic distributed query-level memory budget operatorMemKB, with fallback to old mode controlled by gp_enable_work_mem GUC.(src: VMware Greenplum 7.x Release Notes)
Enterprise AI Agents
2.2
● OpenAI
○ ChatGPT
■ GPT-5.5 in ChatGPT
● GPT-5.5 is built to understand complex goals, use tools, check its work, and carry more tasks through to completion. The model can help write and debug code, research online, analyze data, create documents and spreadsheets, and move across tools until the work is done.
● In addition, GPT-5.5 performs better on complex terminal workflows, real-world GitHub issue resolution, and long-horizon coding tasks. The model is better at holding context across large systems, reasoning through ambiguous failures, checking assumptions with tools, and carrying changes through the surrounding codebase.
● Currently, GPT-5.5 Thinking is available in ChatGPT for eligible paid plans. GPT-5.5 Pro is available to Pro, Business, Enterprise, and Edu plans.
■ Fast answers in ChatGPT
● In some cases, users just want to get the right answer as quickly as possible. For this, ChatGPT is rolling out Fast answers. This is a quicker way to get responses to common information-seeking questions in ChatGPT. Note that Fast answers do not reference past chats or memory.
■ ChatGPT for Clinicians
● ChatGPT for Clinicians is a free version designed for verified clinicians in the United States. It is designed to support real clinical work at the time of care, including evidence review, documentation, and medical research. It provides trusted clinical search, citations, reusable skills, deep research across medical literature, and support for earning CME credits on eligible clinical questions.
● Users who already have a ChatGPT account can use that same account to sign up. After signup, ChatGPT for Clinicians appears as a separate workspace under the same login, and the existing regular ChatGPT workspace remains available.
■ ChatGPT Images 2.0 in ChatGPT
● ChatGPT has officially rolled out a new image generation model, ChatGPT Images 2.0. Currently, ChatGPT Images 2.0 is available on all ChatGPT plans.
● At the same time, this update also introduces the Images with thinking feature. When given more time to think, it can plan and refine image outputs before generating them. Images with thinking is available on all paid ChatGPT plans. It is available when you select Thinking and Pro models in the interface. (src: ChatGPT — Release Notes)
○ ChatGPT Enterprise & Edu
■ ChatGPT Workspace Agents for Enterprise and Business
● ChatGPT Workspace Agents are rolling out gradually over the next few weeks to ChatGPT Business and Enterprise workspaces.
● Workspace Agents let organizations build and use agents for repeatable tasks and automate business workflows leveraging all your connected apps & can run in ChatGPT and/or Slack. Workspace agents can be created, previewed before publishing, shared within a workspace, and run on a schedule.
● Eligible workspaces can now:
○ Create agents from templates or build from scratch.
○ Connect agents to tools and apps such as Google Drive, Google Calendar, Slack, and SharePoint.
○ Add skills, files, and custom MCP servers.
○ Share agents privately, by link, or in the workspace directory.
○ Schedule recurring runs in ChatGPT.
○ Use agents in connected Slack channels.
○ View version history and analytics for agents.
● Workspace admins can also manage access to agent building, publishing, and Slack usage through admin controls. ChatGPT workspace agents are off by default at launch, and admins can enable them for eligible workspaces. (src: ChatGPT Enterprise & Edu - Release Notes)
● Anthropic Claude
○ The Rate Limits API has been released, allowing administrators to programmatically query the rate limits configured for their organization and workspaces.
○ Memory for Claude Managed Agents is now in public beta and can be called using the standard managed-agents-2026-04-01 header. See "Using agent memory" for the full integration guide.
○ Claude Opus 4.7 has been released. As the most capable generally available model, it is designed for complex reasoning and agentic coding, with pricing maintained at $5 / $25 per MTok, the same as Opus 4.6. See "What's new in Claude Opus 4.7" for capability improvements, new features, and the updated tokenizer. Opus 4.7 includes API breaking changes versus Opus 4.6; see "Migrating to Claude Opus 4.7" before upgrading.
○ Claude in Amazon Bedrock is now open to all Amazon Bedrock customers. Users can self-serve Claude Opus 4.7 and Claude Haiku 4.5 models via the Bedrock console through the Messages API endpoint at /anthropic/v1/messages, in 27 AWS regions with global and regional endpoints. (src: Claude Platform - Release notes)
● Deepseek
○ DeepSeek-V4 Release
■ The models are available in two versions based on size:
■ DeepSeek-V4-Pro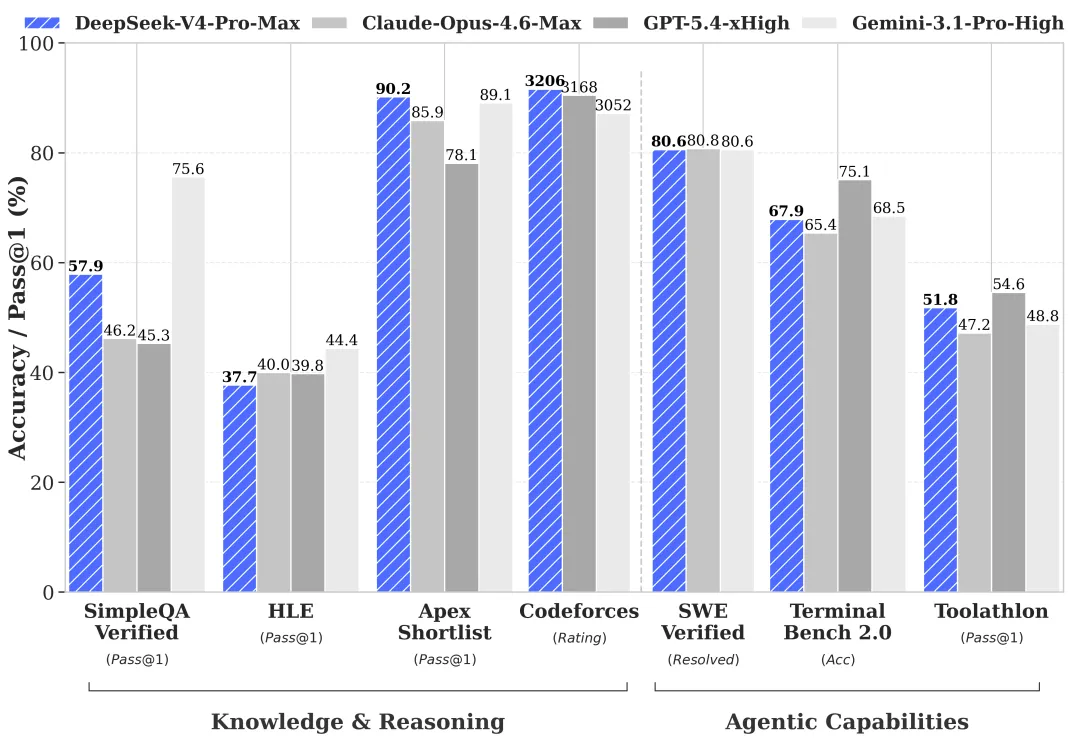
● Significant Improvement in Agent Capabilities: Compared to the previous generation, the agent capabilities of DeepSeek-V4-Pro have been significantly enhanced. In Agentic Coding evaluations, V4-Pro has reached the top level among current open-source models and demonstrates excellent performance in other agent-related benchmarks.
● Rich World Knowledge: In world knowledge benchmarks, DeepSeek-V4-Pro leads other open-source models, trailing only the top closed-source model, Gemini-Pro-3.1.
● World-Class Reasoning Performance: In evaluations of mathematics, STEM, and competitive programming, DeepSeek-V4-Pro surpasses all currently publicly evaluated open-source models, achieving performance comparable to the world's top closed-source models.
■ DeepSeek-V4-Flash
● Compared to DeepSeek-V4-Pro, DeepSeek-V4-Flash has slightly less world knowledge but exhibits similar reasoning capabilities. Due to its smaller model parameters and activation, V4-Flash offers faster and more cost-effective API services.
● In agent evaluations, DeepSeek-V4-Flash is on par with DeepSeek-V4-Pro for simple tasks, though there remains a gap in high-difficulty tasks.
■ API Access (Pricing):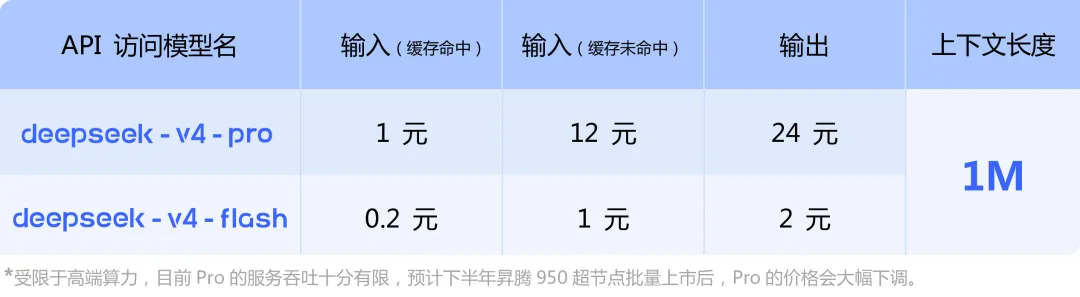
● The DeepSeek API now supports both V4-Pro and V4-Flash, with compatibility for both OpenAI ChatCompletions and Anthropic interfaces. When accessing the new models, the base_url remains the same, while the model parameter should be updated to deepseek-v4-pro or deepseek-v4-flash. (src: DeepSeek-V4 预览版:迈入百万上下文普惠时代)
Startup Spotlight
2.3
○ TopK is a search and retrieval infrastructure company for the AI era. Its core positioning has evolved from an AI-native / true hybrid search engine to an Agent-oriented Context Engine: transforming enterprise unstructured, multimodal data into searchable, referenceable, and auditable context for AI agents, human users, and enterprise applications. Earlybird, one of its investors, describes it as “a document database with native multi-vector, keyword, and faceted search,” and notes that it was founded in 2024 with headquarters in San Francisco.
○ Founding Team
■ Marek Galovič (Co-founder & CEO): Previously worked at Pinecone on data plane and control plane engineering, and at Shopify on fraud detection and predictive algorithms. He also conducted research in game theory, adversarial machine learning, and computer security at CTU/Avast.
■ Jerguš Lejko / Jergus Lejko (Co-founder & CTO): Previously worked at Pinecone on developer tooling, CI/CD optimization, and managed cloud infrastructure across major cloud providers. Earlier, he collaborated with ML and bioinformatics teams to build large-scale data pipelines and automation systems.
○ Core Products
■ Context Engine / End-to-end Search: Positioned as a context engine for agents, emphasizing the ability to understand unstructured documents and return evidence-backed answers. It can process PDFs, tables, charts, images, and complex layouts while preserving structural information, enabling agents to “see” what humans see.
■ TopK Database / Search Engine for the AI era: A search engine designed for the AI era, supporting semantic search, vector search, BM25 keyword search, sparse vector search, multi-vector search, hybrid search, and reranking. It is accessible via Python SDK and JavaScript SDK.
■ Three Core Workflows:
● Ingest: Upload documents (PDFs, images, Markdown, HTML, etc.) via CLI, Python SDK, or JavaScript SDK. TopK parses, chunks, and indexes the data to support Ask, Search, and Research workflows.
● Search: Returns the most relevant document snippets for natural language queries, including document IDs, dataset references, page citations, and metadata. Search “provides evidence, not interpretation.”
● Ask: Generates grounded answers with citations for natural language questions. The process includes understanding the question, retrieving relevant documents, generating answers based on evidence, and returning source references.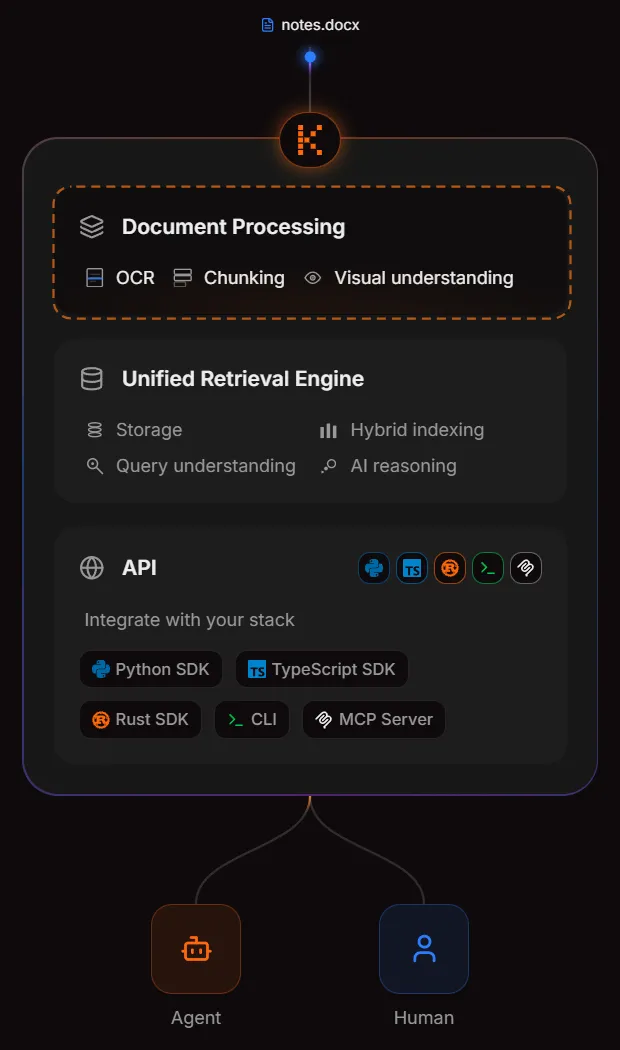
○ Innovations
■ From “Vector Database” to “Unified Search Query Layer”: TopK’s core insight is that real-world retrieval goes beyond vector similarity and requires combining vectors, keywords, metadata filtering, domain-specific ranking rules, and custom scoring.
■ True Hybrid Retrieval: Instead of traditional late fusion (e.g., RRF combining dense and keyword results), TopK combines dense/sparse scores, text filtering, metadata filtering, and custom scoring within a single query, reducing recall loss caused by early truncation. On BEIR benchmarks, TopK Hybrid improves nDCG@10 by an average of 4.58%, and by 7.84% on TREC-COVID compared to RRF.
■ Programmable Ranking & Business Signal Fusion: Developers can define custom expressions combining vector similarity, BM25, document attributes, quality scores, time, and geolocation. This is critical for verticals like e-commerce, finance, healthcare, and legal, where relevance cannot be determined by semantic similarity alone.
■ Multimodal & Complex Document Understanding: Emphasizes preserving structure in PDFs, images, tables, charts, and complex layouts, positioning it closer to an “enterprise knowledge base + RAG/Agent retrieval infrastructure” rather than just a vector index.
■ Scalability with Low Operational Complexity: Supports collections with billions of documents while maintaining predictable low latency for hybrid search, dense/sparse vectors, keyword queries, and metadata filters—without requiring manual sharding or complex infrastructure management.
■ Decoupled Storage & Compute with Read/Write Separation: Architectural decisions include log-structured write paths, read/write decoupling, object storage for persistence, elastic compute, and a vectorized query engine (reactor), improving throughput, reducing cost, and maintaining stable tail latency under hybrid workloads.
■ Security & Private Deployment: Supports encryption in transit and at rest, RBAC, audit logs, and private cloud/VPC deployment. It is SOC 2 Type I certified, and allows storage, inference, and query agents to run within the customer’s VPC to meet data residency and compliance requirements.
○ Funding
■ In July 2025, TopK announced a $5.5 million seed round, with investors including Earlybird, KAYA, Irregular Expressions, and several angel investors. The funding is intended to expand the team, hire engineering talent, and accelerate platform development. (src:topk,We Raised $5.5 Million to build an AI-Native Search Engine for Enterprises)
● Tavily is a real-time web access and Agentic Search infrastructure company built for AI Agents. It originated from the open-source project GPT Researcher in 2023 and became more formally commercialized around 2024, entering enterprise scenarios such as AI Agent web access, retrieval, crawling, and information extraction. Its positioning is not that of a traditional search engine designed for “human clicks,” but rather a programmable Web Access Layer for large language models, RAG systems, and agentic workflows, enabling Agents to obtain fresh, reliable, and structured web context through APIs.
○ Founding Team:
■ Rotem Weiss(Founder & CEO):Co-founded GPT Researcher, an Autonomous AI Agent / Deep Research Agent project designed for online research tasks. The project has gained 25K+ GitHub stars, built a developer community of 6K+ active members, and has been cited in multiple academic papers. He also previously served as Co-founder and CTO of The Bulletin, where he helped build a centralized platform for students to discover campus events, applications, and student organizations, available on both desktop and iOS.
○ Core Product: Tavily’s core product is a unified Web Access API for AI Agents, covering five major capabilities: search, extract, research, crawl, and map.
■ Search: Used to retrieve fresh and reranked Web Context for Agents. Tavily emphasizes that search results are distilled into information-dense snippets, reducing token waste caused by low-value web noise. Its Search API supports automatic parameter configuration; when auto_parameters is enabled, the system automatically adjusts search parameters based on the query content and intent. It also supports controls such as safe_search.
■ Extract: Used to extract clean, model-consumable content from web pages. Instead of simply returning a list of URLs, Tavily processes web information into structured and contextualized outputs that are more suitable for LLM/RAG pipelines.
■ Crawl / Map: Used for crawling, navigating, and discovering the structure of target websites. These capabilities are suitable for enterprise knowledge collection, competitor/company research, documentation site crawling, and RAG data preparation.
■ Research: Designed for more complete automated research tasks, generating synthesized research results or reports. It is suitable for Deep Research, market research, company intelligence, sales intelligence, meeting preparation, and other agentic workflows.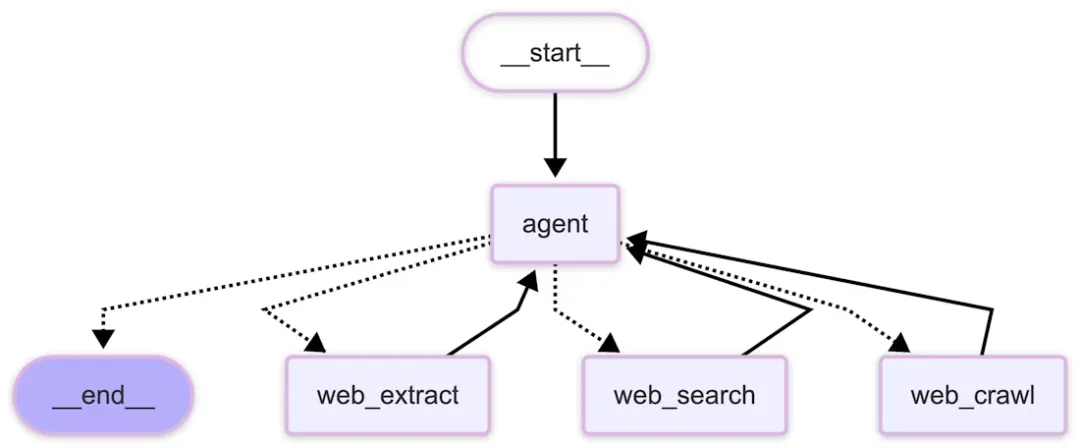
○ Innovation Points
■ Tavily’s key innovation lies in reconstructing “search” from a human-browser-oriented scenario into a production-grade infrastructure layer for AI Agents. Traditional search systems serve a process of “human enters keywords — browses results — clicks webpages,” whereas Tavily serves a process of “Agent automatically determines the task — calls search/crawl/extract tools — sends structured context into model reasoning.” As a result, it places greater emphasis on freshness, structure, controllability, low latency, security compliance, and observability. Its production-grade retrieval stack includes real-time search, intelligent caching, and indexing to maintain predictable latency; requests also pass through security, privacy, and content validation layers to block PII leakage, prompt injection, and malicious sources.
■ “Machine-consumable search layer” for Agents: Tavily does not merely return web links; instead, it transforms web content into structured, chunked, RAG-ready context suitable for model reasoning, enabling Agents to reason based on facts rather than hallucinations.
■ Enterprise-grade security and governance: One of Tavily’s key differentiators is controllable web access in enterprise environments. Tavily allows enterprise Agents to search, crawl, and extract structured insights from public and private sources while complying with company policies. This is particularly relevant for high-risk or high-value scenarios such as financial risk control, sales intelligence, enterprise operations, and research.
■ High-quality factual grounding: The system achieved 93.3% accuracy on the OpenAI SimpleQA benchmark using real-time Web Retrieval.
○ Financing / Acquisition
■ Financing: In August 2025, Tavily announced that it had raised $25 million in funding. According to TechCrunch, this included a $20 million Series A round led by Insight Partners, bringing the company’s total funding to $25 million.
■ Acquisition: In February 2026, Nebius announced that it had entered into an agreement to acquire Tavily, integrating Tavily’s real-time Agentic Search infrastructure into the Nebius AI Cloud platform. Nebius disclosed that the Tavily team, including Founder and CEO Rotem Weiss, would join Nebius and continue leading Tavily’s product development. Tavily would continue operating under its existing brand. The transaction value was not officially disclosed.(src:tavily,Big News from Tavily: Announcing 25M Series A to Power the Internet of Agents,Nebius announces agreement to acquire Tavily to add agentic search to its AI cloud platform)
Open Source Picks
2.4
○ Project Overview: DuckLake is an integrated, open-source Lakehouse and catalog format developed by the DuckDB team. It represents a "radically simplified" approach to table formats by using a SQL database (DuckDB) as the catalog instead of traditional manifest file structures (like those used in Iceberg or Delta Lake). DuckLake stores metadata directly in a .ducklake catalog file while persisting data in Parquet files. This architecture solves the "manifest sprawl" and metadata inconsistency pain points commonly found in large-scale data lakes, providing ACID-compliant transaction semantics and native SQL accessibility without the operational overhead of a distributed metadata service. It is specifically designed for high-performance local or cloud-native analytical workloads where simplicity and zero-configuration are prioritized.
○ Project Attention Level: Publicly launched and gaining significant traction in early 2026, the project has reached 2,700+ GitHub stars as of April 2026. It is currently categorized as one of the most promising "breakout" table formats for the DuckDB ecosystem.
○ Developer: DuckDB Labs & The DuckDB Foundation
■ Mark Raasveldt & Hannes Mühleisen: Co-founders of DuckDB Labs and researchers from Centrum Wiskunde & Informatica (CWI) in Amsterdam. Mark Raasveldt holds a PhD in database systems focusing on vectorized query execution; Hannes Mühleisen is a senior researcher specialized in analytical database architectures. Their research focuses on making data management resilient, versatile, and high-performance in resource-constrained environments.
○ Application Architecture: DuckLake employs an extension-based architecture integrated with the DuckDB core. The architecture consists of: (1) Metadata Catalog Database: A specialized DuckDB file (metadata.ducklake) that tracks table versions, schema history, and file pointers using standard relational tables; (2) Storage Layer: Data is persisted in optimized Parquet files organized in a medallion structure (Raw/Silver/Gold) within a specified directory or object storage path; (3) Consistency Engine: Uses DuckDB's internal MVCC (Multi-Version Concurrency Control) to ensure ACID properties for concurrent SQL operations; (4) Extension Interface: Allows users to interact with the Lakehouse via standard ATTACH and SQL syntax, requiring no external daemons or JVM-based services.
○ Key Features:
■ Zero-Manifest Design: Unlike Iceberg, DuckLake does not rely on a chain of JSON/Avro manifest files. By using a SQL database as the catalog, it reduces metadata lookup latency by $10\times$ to $50\times$ and eliminates "small file" metadata overhead.
■ Native SQL Catalog: Metadata itself is queryable using standard SQL. Users can join system tables to analyze partition distribution, storage size, and transaction history directly through the DuckDB engine.
■ Embedded ACID Transactions: Supports atomic commits and snapshot isolation natively. A single SQL UPDATE or INSERT across multiple tables is handled as a single transaction within the catalog database.
■ Unified Extension Model: Ships as a single binary extension for DuckDB. It can be loaded in Python, R, Java, or the CLI, making the Lakehouse accessible across any environment where DuckDB runs.
■ Multi-Cloud Parquet Storage: While metadata is centralized in the catalog file, data can be distributed across AWS S3, GCS, or local NVMe drives, supporting tiered storage strategies.
○ Application Scenarios:
■ Local-First BI & Analysis: Analysts can build a full-featured Lakehouse on their laptop to process multi-terabyte datasets using DuckDB’s efficiency, providing a "Data Lake in a Box" experience.
■ Embedded Edge Analytics: Ideal for IoT and edge computing where a lightweight, durable, and SQL-compliant storage format is required to manage local data buffers before syncing to the cloud.
■ Fast Lakehouse Prototyping: Enables data engineers to test medallion architectures and complex ETL logic locally with full ACID support before deploying to larger-scale formats like Iceberg or Delta.(src: DuckLake)
● Apache Paimon
○ Project Overview: Apache Paimon is a high-performance, stream-native data lakehouse format designed to bridge the gap between real-time streaming and batch analytical workloads. It fills a critical void left by batch-oriented formats (like Iceberg) by offering native, high-frequency upsert capabilities and real-time CDC (Change Data Capture) ingestion. Paimon allows users to treat their data lake as both a message queue for streaming consumption and a structured table for OLAP queries. It solves the performance degradation issues typical of "Merge-on-Read" architectures during heavy update workloads by utilizing a Log-Structured Merge-tree (LSM) storage structure.
○ Project Attention Level: Graduated to an Apache Top-Level Project (TLP) with a surge in adoption in 2025-2026. As of April 2026, it has reached 4,000+ GitHub stars and is a core component of the "Streaming Lakehouse" stack at major enterprises including Alibaba and TikTok.
○ Developer: Apache Software Foundation (originally incubated by Alibaba)
■ Jingsong Lee (Project Lead): A Principal Engineer at Alibaba and a core PMC member of Apache Flink. He is a pioneer in the "Streaming Lakehouse" paradigm, focusing his research on unifying stream processing and storage layouts to minimize end-to-end data latency.
○ Application Architecture: Paimon is built on an LSM-tree (Log-Structured Merge-tree) architecture adapted for distributed object storage. The architecture includes: (1) LSM-Tree Storage Layer: Tables are partitioned and divided into buckets, where data is organized in sorted files (SST-like) to enable efficient primary key updates; (2) Snapshot Manifests: Periodic snapshots capture the state of the table, stored as immutable files in S3/HDFS; (3) Changelog Production: Automatically generates changelogs during the write process, allowing downstream consumers (like Flink) to consume incremental updates; (4) Integrated Compaction: Background processes merge small files and handle tombstone records to optimize read performance without blocking incoming streams.
○ Key Features:
■ Streaming-Native Upserts: Capable of handling $100,000+$ write operations per second with latencies under 1-5 minutes, significantly outperforming traditional lakehouse formats that recommend hourly commit intervals.
■ Native CDC Ingestion: Provides built-in connectors for Flink CDC, allowing seamless synchronization of MySQL, PostgreSQL, and Oracle databases directly into the lakehouse with schema evolution support.
■ Primary Key & Append-Only Support: Offers dual-mode storage. Primary key tables optimize for updates/deletes, while append-only tables optimize for high-throughput log ingestion and analytical scanning.
■ Write-Optimized Compaction: Implements a pluggable compaction strategy (Size-tiered or Leveled) that can be offloaded to dedicated worker nodes to prevent "write stalls" during peak ingestion periods.
■ Universal Engine Integration: Native support for Apache Flink, Spark, Trino, and StarRocks, allowing the same Paimon table to be used for real-time dashboarding and heavy batch reporting simultaneously.
○ Application Scenarios:
■ Real-Time Data Warehousing: Companies like TikTok use Paimon to maintain real-time user profiles and advertising metrics, reducing data latency from hours to seconds.
■ CDC Lakehouse Ingestion: Serves as the central landing zone for all operational database changes, providing a consistent, queryable "Mirror" of production databases in the data lake for downstream analytics.
■ Unified Stream-Batch Processing: Simplifies architectures by replacing separate Kafka (streaming) and Hive (batch) silos with a single Paimon table that serves both use cases, reducing infrastructure costs by up to 40%. (src: Apache Paimon)
● Kestra (Version 2.0)
○ Project Overview: Kestra is a next-generation, event-driven orchestration and data management platform designed to automate complex data pipelines and business workflows. The recently released Kestra 2.0 represents a major architectural shift toward a decentralized, cloud-native control plane. It differentiates itself from legacy tools like Airflow by using a declarative YAML-based API, allowing both developers and data analysts to build pipelines without writing complex Python code. It solves the scalability and security bottlenecks of monolithic schedulers by separating the orchestration logic from the execution environment, enabling "Bring Your Own Worker" (BYOW) models for high-security or multi-cloud deployments.
○ Project Attention Level: Following the launch of Version 2.0 and a $25M Series A funding round in March 2026, Kestra has exploded to 26,600+ GitHub stars. It is currently the highest-trending orchestration project in the Modern Data Stack.
○ Developer: Kestra Technologies
■ Ludovic Dehon & Emmanuel Drouin: Co-founders with extensive backgrounds in building large-scale data platforms for retail giants (Leroy Merlin). Ludovic, as CTO, focuses on building high-concurrency Java architectures and declarative orchestration engines that minimize operational overhead for platform teams.
○ Application Architecture: Kestra 2.0 introduces a decoupled gRPC-based architecture. The core components include: (1) Control Plane: An API-first server that handles scheduling, workflow parsing, and state management, utilizing a high-performance database (PostgreSQL/MySQL) or Kafka for queueing; (2) Stateless Workers: Lightweight agents that execute tasks in isolated environments (Docker, Kubernetes, or Bare Metal) and communicate with the control plane exclusively via gRPC; (3) Internal Storage Layer: A pluggable layer (S3, GCS, Azure Blob) used to persist large execution outputs and artifacts between task steps; (4) Event-Driven Trigger System: A native subsystem that responds to real-time events (webhooks, file arrivals, message queue pulses) to initiate workflows instantly.
○ Key Features:
■ Declarative YAML API: Workflows are defined in YAML with a rich UI editor that provides real-time validation and documentation. This eliminates "dependency hell" associated with Python-based orchestrators.
■ gRPC Worker Isolation: Workers are completely stateless and can be deployed in segregated networks. In 2.0, the "BYOW" (Bring Your Own Worker) feature allows workers to run on-premise while the control plane remains in the cloud, ensuring sensitive data never leaves the local network.
■ Native Multi-Language Support: Unlike Airflow which is Python-centric, Kestra orchestrates Python, SQL, Shell, Node.js, and Java as first-class citizens. Each task can run in its own containerized environment with specific dependencies.
■ Sub-Second Event Triggers: Built for the "Real-Time Data" era, Kestra can trigger workflows based on Kafka messages or API calls with sub-100ms latency, making it suitable for operational automation beyond simple batch ETL.
■ Enterprise-Grade Governance: Includes built-in role-based access control (RBAC), multi-tenant namespaces, and secret management, which are typically "bolted-on" in other open-source alternatives.
○ Application Scenarios:
■ Hybrid-Cloud Data Orchestration: A global enterprise can manage a single Kestra control plane while deploying workers in AWS (for AI model training), GCP (for BigQuery ETL), and on-premise (for legacy DB access).
■ Automated Data Quality Pipelines: Orchestrates ingestion from sources like dlt or Airbyte, triggers transformation in dbt, and runs validation checks, automatically halting the pipeline and alerting via Slack if quality thresholds are missed.
■ Self-Service Data Platforms: Platform teams use Kestra’s declarative nature to empower data analysts to build their own pipelines safely within predefined namespaces, reducing the "Data Engineering bottleneck."(src: Kestra)
Research Watch
2.5
● Transformers are Inherently Succinct (ICLR 2026 Outstanding Paper)
○ Primary Authors:
■ Pascal Bergsträßer: He is currently a postdoctoral researcher at the University of Kaiserslautern. Prior to his postdoctoral appointment, he completed his PhD at the same institution between 2020 and 2025. His primary research interests include logic, automata theory, and formal verification.
■ Anthony W. Lin: He is currently a Full Professor (W3) of Theoretical Computer Science (Automated Reasoning) and a Max-Planck Fellow at the University of Kaiserslautern-Landau. Previously, he served as an Associate Professor in the Department of Computer Science at the University of Oxford and a Governing Body Fellow at Kellogg College, an Assistant Professor at Yale-NUS College in Singapore, and an EPSRC Postdoctoral Research Fellow at the University of Oxford. He completed his PhD in Informatics at the University of Edinburgh, and holds an MSc from the University of Toronto and a BSc (Honours) from the University of Melbourne.
■ Ryan Cotterell: He currently serves as a tenure-track assistant professor in the Department of Computer Science at ETH Zürich and is a member of the Institute for Machine Learning (Institut für maschinelles Lernen). Previously, he served as a Lecturer at the University of Cambridge Computer Laboratory. He has also conducted academic research at Google AI, Facebook AI Research, and the Ludwig Maximilian University of Munich (LMU). He earned his PhD in Computer Science at Johns Hopkins University.
○ Core Problem:
■ Previous research indicates that transformers with fixed precision can only recognize a small subclass of regular languages known as "star-free languages". This is in sharp contrast to Recurrent Neural Networks (RNNs), which can recognize all regular languages. Therefore, using "expressivity as a language recognizer" alone as a criterion for evaluating large language model architectures might not be the most effective or comprehensive perspective.
■ The core problem faced by the field is finding a new perspective to truly understand and measure the expressive power of transformers, as well as the computational challenges this power poses to their verifiability.
○ Proposed Solution: The authors propose "succinctness" as a novel metric for measuring the expressive power of a transformer in describing a concept.
■ Here, "succinctness" refers to the smallest model size or the minimum number of symbols required to recognize a specific language or describe a concept.
■ By focusing on succinctness, researchers can more intuitively compare the efficiency differences in encoding information between transformers and standard representations of formal languages (such as finite automata and Linear Temporal Logic).
○ Technical Implementation:
■ In terms of theoretical assumptions, the study restricts both transformers and RNNs to fixed (finite) precision arithmetic, which is faithful to real-world hardware implementations.
■ To make the conclusions more compelling, the research primarily relies on "Unique-Hard Attention Transformers" (UHATs), a class of transformers known to be theoretically the weakest in terms of expressive power.
■ During the demonstration, the authors show how transformers can implement counting up to extremely large values through a subtle encoding of the attention mechanism.
■ To derive the lower bounds of complexity, the research team utilized Boolean RASP programs as an intermediate transition model. They reduced a highly complex tiling problem into a non-emptiness checking problem for transformer languages, thereby establishing the baseline for computational difficulty.
■ To establish the upper bounds of complexity, the authors proposed a novel approach to translate fixed-precision transformers into exponential-sized Linear Temporal Logic (LTL) formulas.
○ Final Results:
■ The research conclusively proves that transformers are exponentially more succinct in describing complex patterns than LTL and RNNs (including state-of-the-art State-Space Models). When compared with finite automata, the succinctness advantage of transformers even reaches a doubly exponential level. This indicates that, with the same descriptional size, transformers can encode complex patterns that would require exponentially or doubly exponentially larger descriptional sizes for other traditional models.
■ As a direct by-product of this astounding expressive power, formally analyzing and verifying various properties of transformers is proven to be computationally intractable. Specifically, verifying basic problems, such as whether the model recognizes a trivial language or whether two transformers are equivalent, falls into the extremely high complexity class of EXPSPACE-complete. (src: Transformers are Inherently Succinct)
● DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence
○ Primary Authors: DeepSeek-AI R & D team
○ Core Problem:
■ Computational Bottleneck of Attention Mechanisms: The vanilla attention mechanism suffers from quadratic computational complexity, creating a prohibitive bottleneck when processing ultra-long contexts and complex reasoning.
■ Scaling Limitations: This fundamental inefficiency constrains the potential gains from test-time scaling. It also hinders the model's application and progress in long-horizon scenarios and tasks, such as complex agentic workflows and massive cross-document analysis.
○ Proposed Solution:
■ Million-Token Context Support: The release of the DeepSeek-V4 series preview natively and efficiently supports a context length of one million tokens. The series features two Mixture-of-Experts (MoE) models: V4-Pro with 1.6 trillion parameters (49 billion activated) and V4-Flash with 284 billion parameters (13 billion activated).
■ Core Architectural Upgrades: To break the efficiency barrier for ultra-long sequences, the models introduce a hybrid attention architecture combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). Additionally, Manifold-Constrained Hyper-Connections (mHC) are introduced to strengthen modeling capability, and the Muon optimizer is utilized to enhance the training process.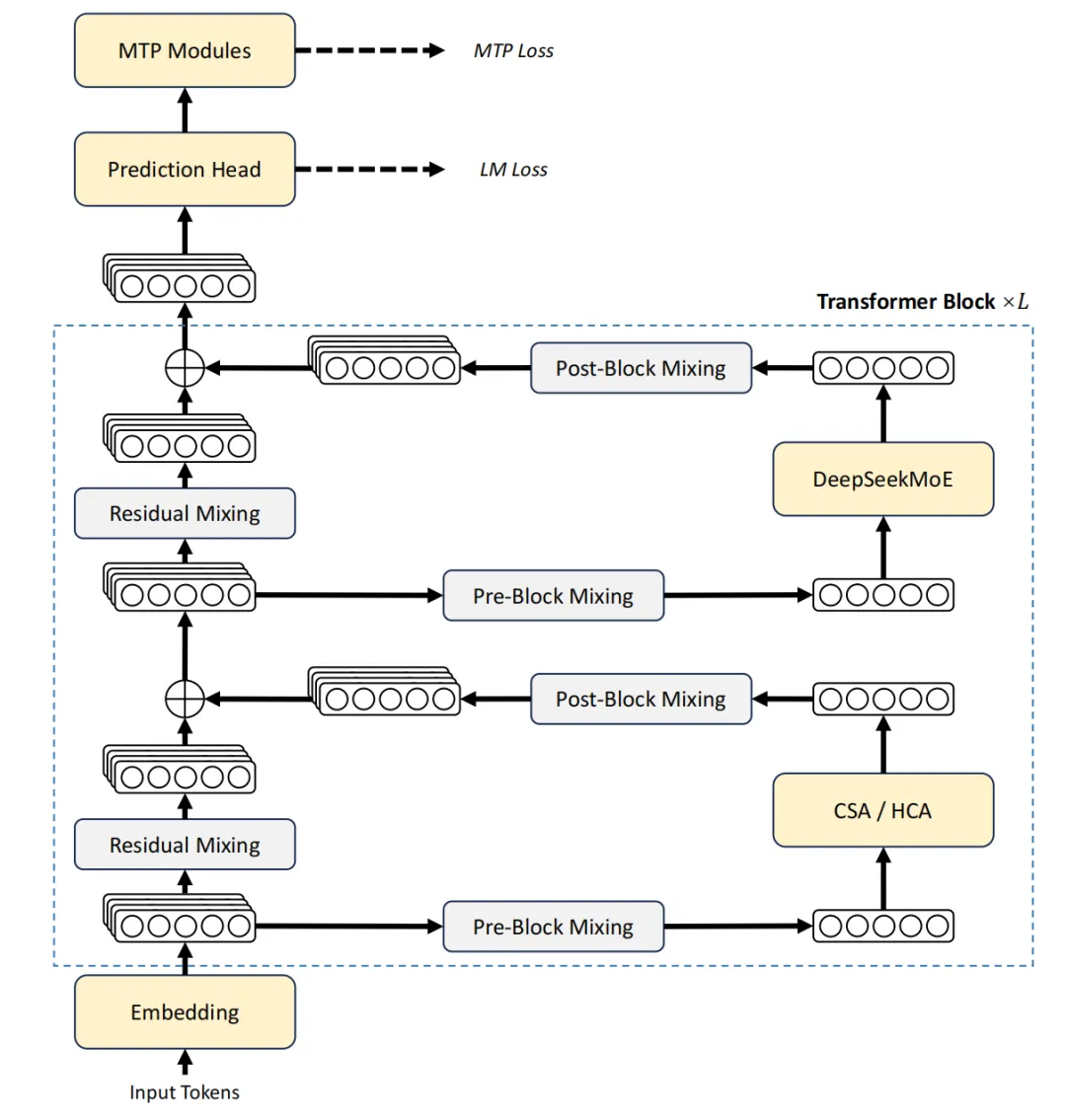
○ Overall architecture of DeepSeek-V4 series
○ Technical Implementation:
■ Hybrid Attention Mechanism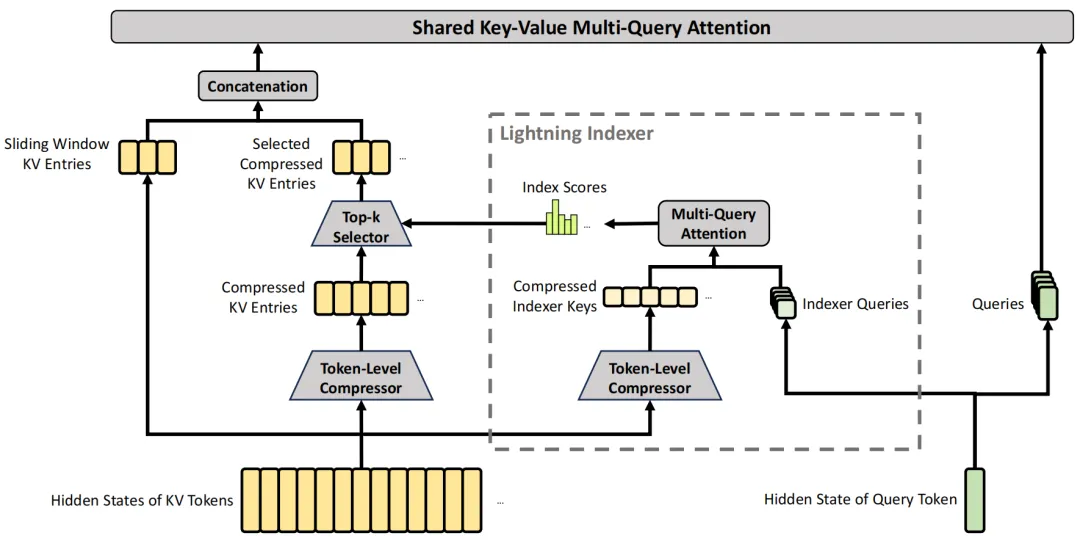
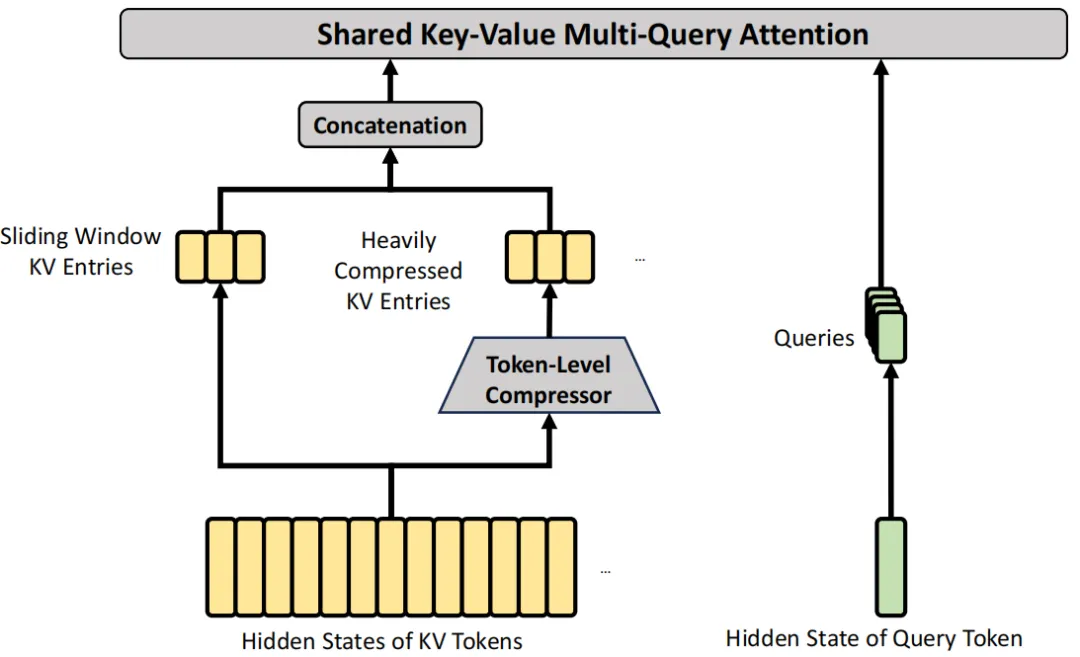
● CSA compresses the Key-Value (KV) cache along the sequence dimension and subsequently applies DeepSeek Sparse Attention (DSA) to improve long-context efficiency.
● HCA applies more aggressive compression to the KV caches but maintains dense attention. This hybrid architecture, paired with low-precision storage, substantially reduces computational FLOPs and KV cache sizes.
■ Manifold-Constrained Hyper-Connections (mHC)
● This technique is designed to strengthen conventional residual connections between adjacent Transformer blocks.
● By constraining the residual mapping matrix onto the manifold of doubly stochastic matrices, it ensures the residual transformation is non-expansive, significantly increasing numerical stability during signal propagation across deep layers.
■ Training and Optimization Innovations
● The Muon optimizer is employed across most modules, leading to faster convergence and improved training stability.
● FP4 Quantization-Aware Training (QAT) is implemented for MoE expert weights and the indexer QK path, effectively reducing memory and computational costs without sacrificing performance.
■ Infrastructure Optimizations
● A fine-grained Expert Parallelism (EP) scheme was developed, fusing communication and computation into a single pipelined kernel to effectively hide communication latency.
● TileLang, a Domain-Specific Language (DSL), is utilized for kernel development to balance development productivity with runtime efficiency.
● High-performance, batch-invariant, and deterministic kernel libraries were developed to ensure bitwise reproducibility between training and inference.
● A heterogeneous KV cache structure and on-disk storage mechanisms were designed to efficiently manage long texts and shared-prefix requests.
■ Post-Training Paradigm
● A two-stage post-training pipeline is utilized: first, independent cultivation of domain-specific experts (e.g., mathematics, coding, instruction following) through supervised fine-tuning and reinforcement learning.
● Subsequently, the traditional mixed RL stage is entirely replaced by full-vocabulary On-Policy Distillation (OPD), which efficiently consolidates the specialized capabilities of these experts into a single unified model.
○ Final Results: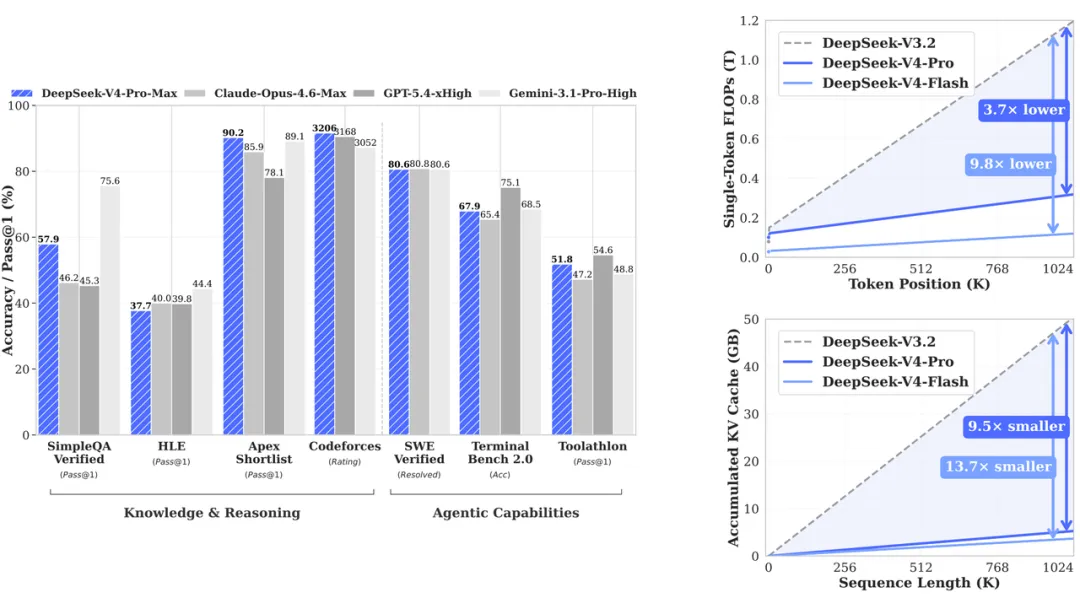
■ Extreme Inference Efficiency
● In a 1-million-token context setting, V4-Pro requires only 27% of the single-token inference FLOPs and 10% of the KV cache size compared to the previous DeepSeek-V3.2.
● The more compact V4-Flash pushes efficiency even further, requiring only 10% of the single-token FLOPs and 7% of the KV cache size relative to V3.2.
■ Setting Open-Source Benchmarks
● DeepSeek-V4-Pro-Max (the maximum reasoning effort mode) redefines the state-of-the-art for open models.
● It significantly outperforms existing open-source models in broad world knowledge tasks (e.g., SimpleQA) and educational knowledge evaluations (e.g., MMLU-Pro, HLE, GPQA).
■ Rivaling or Surpassing Proprietary Giants
● In complex tasks like coding competitions (Codeforces), its performance is comparable to the state-of-the-art closed model, GPT-5.4.
● On academic benchmarks measuring 1-million-token context retrieval and understanding (MRCR and CorpusQA), it surpasses Gemini-3.1-Pro.
■ Strong Agentic and Real-World Capabilities
● It performs on par with leading open-source models on public agentic benchmarks.
● In internal human evaluations for diverse Chinese white-collar workflows (covering analysis, generation, and editing tasks), V4-Pro-Max outperforms Claude Opus 4.6. (src: DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence)
Real-World Deployments
03
Stories from the Field
3.1
● Databricks x Mercedes-Benz
○ Customer Information
■ Customer Name: Mercedes-Benz / Mercedes-Benz Group AG, a globally renowned premium passenger car and luxury automobile company headquartered in Stuttgart, Germany. In 2025, the company had approximately 164,000 employees, sold around 2.16 million vehicles, and generated approximately €132.2 billion in group revenue.
■ Key Related Teams: The original article explicitly involves the R&D team, After-Sales team, Marketing team, Sales team, Azure-side data consumers, AWS-side data producers, and the data platform/data product teams responsible for data exchange, permission management, synchronization jobs, and cost attribution.
○ Scenario Description
■ Mercedes-Benz is facing two major industry shifts at the same time: digitalization and electrification. The Databricks article describes this stage as the era of the “data-defined vehicle,” meaning that vehicles are no longer defined only by hardware or software. Vehicle telemetry data, customer information, after-sales data, and other data assets have become core resources for driving product improvement, customer experience optimization, and business innovation.
■ Cross-cloud data sharing and data product consumption: Mercedes-Benz adopts a multi-cloud architecture across AWS and Azure, operating multiple data platforms across different clouds and regions. Some core after-sales data is mainly stored on AWS, while a large number of business use cases run on Azure, requiring cross-cloud access to this data.
■ After-sales data supporting R&D and warranty analysis: The key data mentioned in the original article includes vehicle OTA event data and workshop visit data. This type of after-sales data is used by the R&D department to improve vehicle components and is also used to analyze warranty cases.
■ Building a data foundation for the data-defined vehicle: To support the “data-defined vehicle” strategy, Mercedes-Benz needs to enable business units such as R&D, After-Sales, Marketing, and Sales to share data securely, smoothly, and cost-effectively, replacing previous data transfer methods such as FTP and email, which were inefficient or insecure.
■ Cross-cloud data marketplace / data mesh construction: Mercedes-Benz aims to build a cross-cloud, cross-region data mesh and use a centralized data sharing marketplace to make data products from different business domains discoverable, authorized, shareable, and reusable.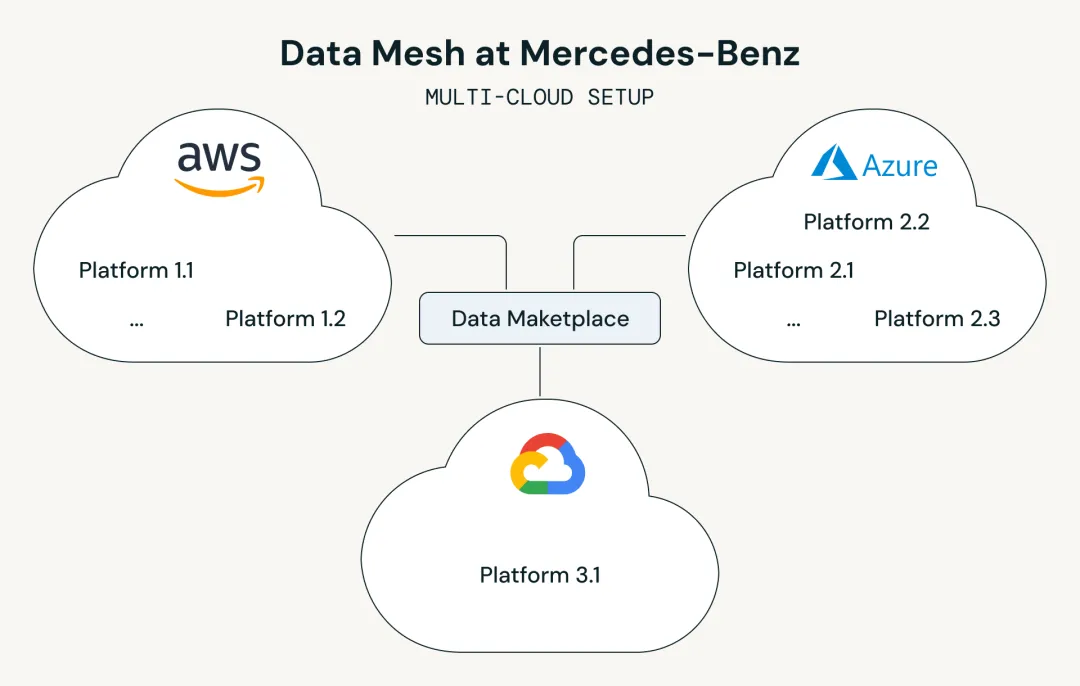
○ Core Challenges
■ Before adopting the new Databricks solution, Mercedes-Benz mainly faced the conflict between “data sharing cost, data freshness, and governance controllability under a multi-cloud architecture”:
● High cross-cloud egress costs: When Azure-side consumers directly queried large-scale after-sales data on AWS, it generated high cross-cloud data egress costs. For cost-sensitive use cases, direct cross-cloud access was not economical.
● Large and continuously growing data volume: The original article mentions that Mercedes-Benz’s core after-sales data volume is large, with a subset of approximately 60 TB required to serve dozens of use cases on Azure, and the data volume continues to grow.
● Insufficient data freshness: The previous approach typically involved a full replication once a week. Business consumers wanted to obtain new data more frequently, but daily full replication was too expensive; meanwhile, a 7-day delay could have a critical impact in scenarios such as warranty case response.
● Data format compatibility issues: The original data on the AWS side used the Iceberg format, while many consumers on the Azure side expected Delta-compatible formats, creating format adaptation pressure for cross-platform consumption.
● Traditional transfer methods were not suitable for scaled data collaboration: Mercedes-Benz wanted to use a more robust centralized data sharing marketplace to replace insecure or inefficient data transfer methods such as FTP and email.
○ Solution
■ Mercedes-Benz adopted the Databricks Data Intelligence Platform, using Unity Catalog + Delta Sharing + Delta Deep Clone as the core to build a hybrid data mesh architecture of “cross-cloud sharing + local incremental replication.” The overall idea was not simply to move all data across clouds in real time, but to select data consumption methods in layers according to the data freshness and cost requirements of different use cases.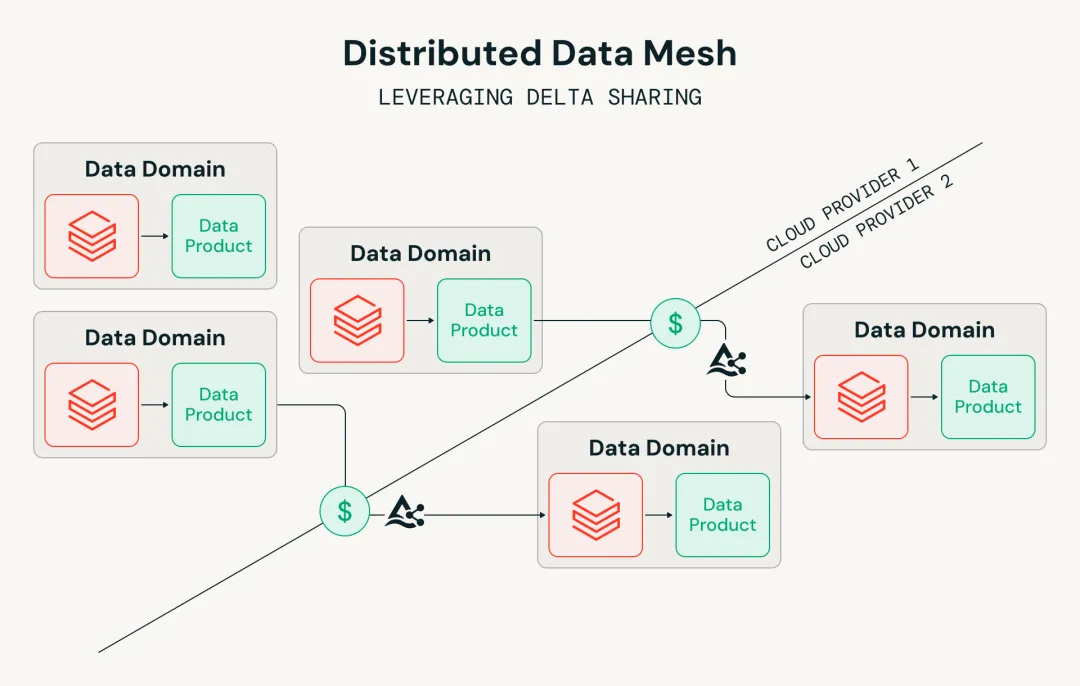
■ Using Unity Catalog as the enterprise-level data product catalog and governance foundation:
● Unity Catalog serves as the global data catalog in the solution, used to uniformly manage metadata, access permissions, and governance policies for enterprise-wide data products.
● The solution adopts a governance model similar to “hub-and-spoke”: data assets can be discovered and consumed by other teams, while data producers still retain control.
● The original article also mentions that Unity Catalog can register tables from AWS Glue into Unity through federation, thereby triggering subsequent data sharing processes.
■ Using Delta Sharing to enable secure cross-cloud, cross-region, and cross-organization sharing:
● Delta Sharing is used as an open protocol to securely exchange data between different Unity Catalog Metastores, covering data sharing from AWS to Azure, across different regions, and between different Metastores.
● Mercedes-Benz chose Delta Sharing because it is an open-source technology and supports incremental data updates.
● In Mercedes-Benz’s data mesh, Delta Sharing mainly supports three types of sharing patterns:
○ Cross-cloud / cross-hyperscaler sharing: For example, data sharing between AWS and Azure, which is the core scenario of this case;
○ Cross-region / cross-Metastore sharing: Data sharing between different regions and different Metastores within the same cloud;
○ External partner sharing: Enabling more secure data sharing with external partners such as suppliers, avoiding transfers through keys, FTP, and similar methods.
■ Using local replication for high-frequency large datasets to reduce repeated egress costs:
● For high-frequency large datasets that do not require sub-hour-level real-time freshness, Mercedes-Benz did not allow Azure-side consumers to continuously read AWS data directly across clouds. Instead, it designed a controlled incremental replication mechanism.
● Specifically, Mercedes-Benz first established a sharing relationship between the AWS Provider Metastore and the Azure Recipient Metastore through Delta Sharing, and then used periodic Sync Jobs with Delta Deep Clone to persist copies of shared tables into object storage on the recipient cloud.
● Subsequent updates are incremental rather than full replication each time; Azure-side consumers query local copies, thereby significantly reducing cross-cloud data movement and egress costs.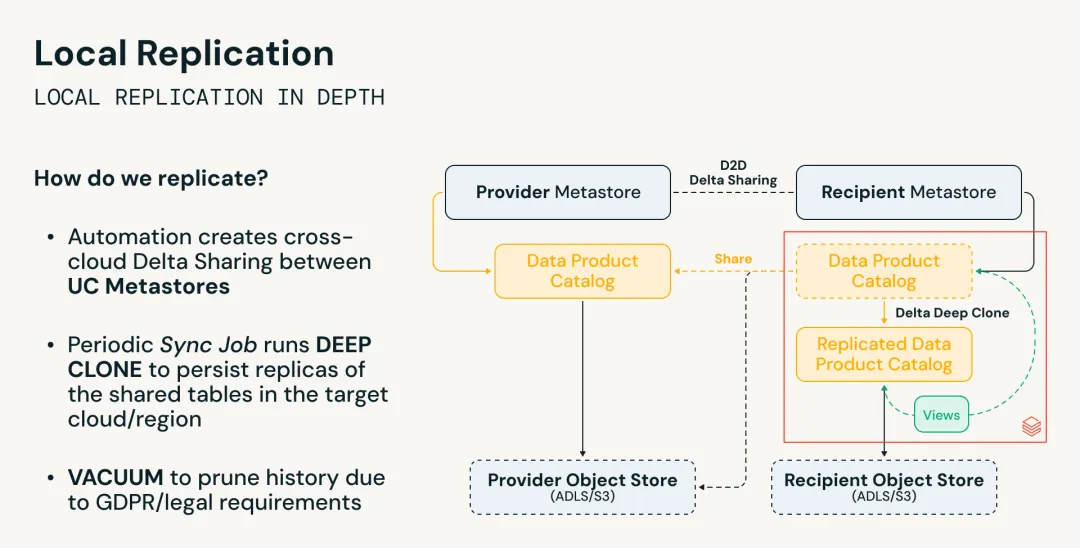
■ Using DDX Orchestrator to enable self-service data exchange and automated governance:
● Mercedes-Benz introduced Dynamic Data eXchange(DDX)Orchestrator as a self-service meta-catalog.
● DDX is responsible for tasks including automated permission management, authorization through microservices and Databricks APIs, Sync Job management, and orchestration of data sharing and replication processes.
■ Using Databricks Asset Bundles and Azure DevOps to achieve deployment automation:
● Sync Jobs and configuration deployments are automated through Databricks Asset Bundles(DABs)and combined with YAML-driven Azure DevOps deployment processes, forming a complete DevOps-style delivery approach.
■ Establishing cost tracking, attribution, and internal chargeback mechanisms:
● Sync Jobs record the actual amount of data transferred.
● An independent Reporting Job aggregates transfer data daily, calculates approximate egress costs for each Data Product, and is used for cost attribution or internal chargeback to upstream data producers.
● The cost dashboard also tracks the compute costs of Sync Jobs, making the cost of cross-cloud data sharing more transparent.
■ Using mechanisms such as VACUUM to balance GDPR compliance and data deletion consistency:
● To meet GDPR and legal compliance requirements, the solution uses Delta Lake’s VACUUM function to process historical data in replicated tables, ensuring that deletions at the source are reflected in the replicated data at the recipient side.
○ Final Outcomes
■ Significant reduction in cross-cloud egress costs: For the first 10 data products, Mercedes-Benz reduced egress costs by 66% through Delta Sharing’s incremental update capability and Deep Clone’s intelligent replication mechanism.
■ Stronger ROI at larger scale: The original article states that, based on a cost estimation scenario in which 50 use cases consume data directly from AWS, approximate annual egress costs were reduced by 93%.
■ Improved data freshness: Azure-side consumers no longer had to wait for a full replication every 7 days. Instead, they could obtain new data more frequently, such as every two days, thereby reducing critical delays in scenarios such as warranty case response.
■ Reduced IT operations costs: The synchronization process uses Serverless Databricks Jobs, reducing compute costs and operational burden; the original article states that these jobs can basically run reliably without significant manual intervention.
■ Enhanced data productization and cost visibility: Through DDX, Sync Jobs, Reporting Jobs, and cost dashboards, Mercedes-Benz transformed cross-cloud data sharing from “project-based data movement” into a data product operating mechanism that is governable, authorizable, measurable, and attributable.
■ Supporting the “data-defined vehicle” strategy: Delta Sharing and the data mesh help Mercedes-Benz connect previously relatively isolated data sources, such as after-sales data with R&D, Marketing, and Sales teams, thereby creating a more complete vehicle and customer view and supporting its digitalization and electrification transformation.(src:Mercedes-Benz Builds a Cross-Cloud Data Mesh with Delta Sharing and Intelligent Replication, Cutting Costs by 66%)
● Alibaba Cloud PolarDB-X x Geo-Distributed Multi-Active Customer Case: State Taxation Administration and China Unicom New Customer Service System
○ Customer Information
■ Customer Name 1: State Taxation Administration
● Business System: Individual income tax system.
● Business Attribute: A major national fiscal and taxation informatization project, carrying sensitive data such as nationwide natural person basic information and tax filing data. It is a large-scale government cloud platform and an important strategic information asset.
● Data Scale: Centrally manages basic information for 780 million natural persons nationwide and tax filing information for 360 million active individual taxpayers.
■ Customer Name 2: China Unicom New Customer Service System
● Business System: China Unicom’s nationwide customer service business system.
● Business Attribute: Supports nationwide customer service operations, with extremely high requirements for continuous high availability, and serves as an important starting point for China Unicom’s evolution toward full-site high availability.
● Business Characteristics: Primarily Transaction Processing.
○ Scenario Description
■ Geo-distributed multi-active disaster recovery: To address disaster risks such as fire, flood, earthquake, regional power outage, and human-induced damage, customers need to build a high-level disaster recovery system to ensure continuous availability and data security for mission-critical business systems. Alibaba Cloud documentation states that geo-distributed multi-active architecture is a next-generation disaster recovery solution that can ensure continuous high availability, optimize costs, and enable region-level horizontal scaling.
■ High-level compliance and business continuity: The national standard GB/T 20988-2007, Information System Disaster Recovery Specification, defines six levels of disaster recovery capability for information systems. Traditional approaches such as intra-city disaster recovery, intra-city active-active, remote disaster recovery, and two-region three-center architectures face challenges in meeting high-level requirements, while also potentially causing resource redundancy, cost waste, and insufficient robustness of disaster recovery units.
■ Multi-business-center and multi-region traffic management:Geo-distributed multi-active architecture isolates and routes business traffic from the top down, allocating different business traffic to different regional units based on routing dimensions. It is applicable to scenarios such as regional nearest access, data center allocation based on user information, and phased gray release for major business launches.
○ Core Issues
■ Traditional disaster recovery architectures struggle to meet high-level disaster recovery requirements:
● In traditional remote disaster recovery or two-region three-center architectures, the disaster recovery center usually does not carry production traffic during normal operations. Once a region-level disaster occurs, the success rate and practical availability of failover remain uncertain.
● For mission-critical businesses such as the State Taxation Administration’s individual income tax system and China Unicom’s nationwide customer service system, a purely standby data center cannot meet requirements for continuous high availability and second-level failover.
■ Significant resource redundancy and cost waste:
● If the disaster recovery center is built to handle 100% of business traffic, the production center and disaster recovery center together may create nearly 200% resource redundancy.
● For a large-scale government cloud platform or a nationwide customer service system, the traditional disaster recovery model amplifies infrastructure investment pressure.
■ Single-center architecture faces scalability bottlenecks:
● As business grows rapidly, resources in a single region are limited, and the data layer can easily become a single-point performance bottleneck.
● Except for geo-distributed multi-active architectures, traditional disaster recovery architectures usually still require write operations to be concentrated in the primary production center, which is not conducive to cross-region horizontal scaling.
■ Complex businesses require fine-grained traffic governance:
● The State Taxation Administration’s individual income tax system involves different business modules, such as online services and offline list queries, requiring traffic routing by dimensions such as natural person archive number and region.
● China Unicom’s new customer service system covers multiple business centers, including access centers, outbound call centers, and business support, requiring a highly available architecture that coordinates multiple businesses across multiple regions.
○ Solution
■ Overall Solution: Alibaba Cloud PolarDB-X-based geo-distributed multi-active database solution
● Based on the capabilities of RDS, PolarDB-X, ADB, DTS, DMS, DBS, MSHA, and other products, the solution builds a cross-region, traffic-switchable, synchronizable, and operable high-availability system for data and business.
● Multi-active traffic control routes business requests to different regional units according to defined rules.
● DTS enables cross-region real-time synchronization and intra-cloud synchronization.
● MSHA enables multi-active traffic control, disaster recovery failover, and traffic scheduling in fault scenarios.
● DMS manages routine O&M changes and data changes.
● DBS provides data backup capabilities for third-party platforms.
● Overall Architecture: The geo-distributed multi-active architecture is organized around “units,” splitting the business system into multiple regional units. Each unit includes an access layer, service layer, and data layer. One unit may serve as the logical center, providing centralized capabilities such as Sequence distribution and strongly consistent reads.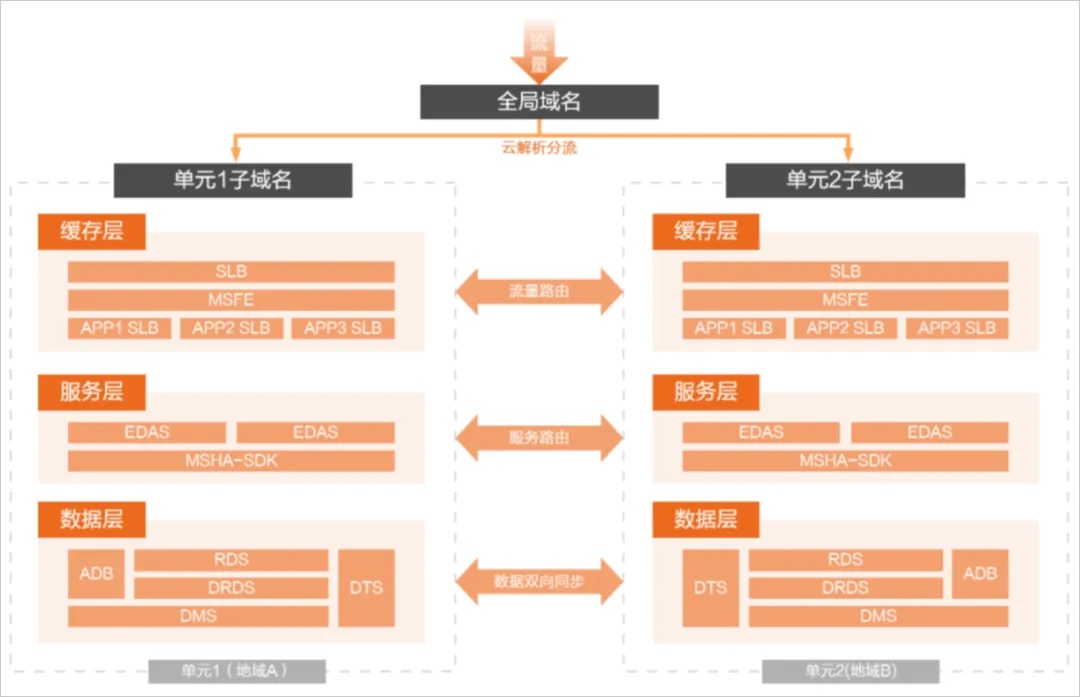
■ State Taxation Administration Individual Income Tax System Solution
● Based on this geo-distributed multi-active solution, the State Taxation Administration integrated multi-active capabilities for TP/AP scenarios and used RDS, PolarDB-X, ADB, DTS, DMS, MSHA, and other products to build a disaster recovery architecture that meets Level 6 requirements under the national standard.
● Architecture division of responsibilities includes:
○ RDS and PolarDB-X: Carry TP transactional processing data.
○ ADB: Carries AP analytical processing data.
○ MSHA: Responsible for multi-active traffic control and disaster recovery failover.
○ DTS: Responsible for cross-region real-time synchronization and intra-cloud synchronization.
○ DMS: Responsible for routine O&M change management and data change management.
○ DBS: Responsible for third-party platform data backup.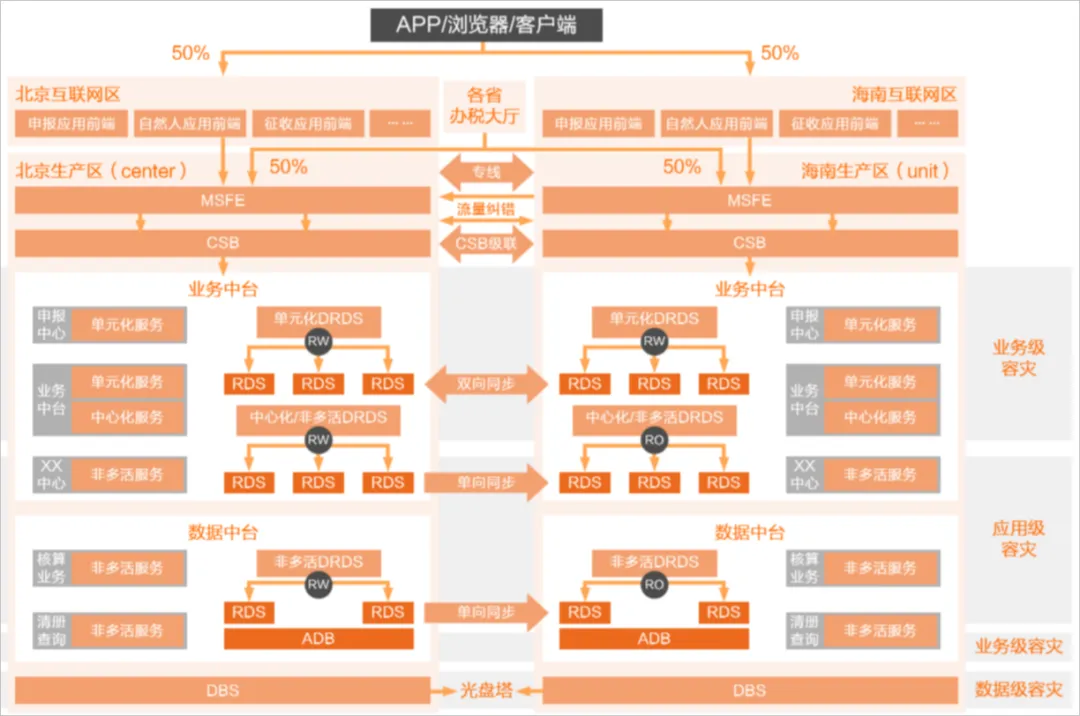
■ China Unicom New Customer Service System Solution
● China Unicom’s new customer service system uses the capabilities of RDS, PolarDB-X, DTS, MSHA, and other products to enable multi-active capabilities for seven business centers in the new customer service system.
● Architecture division of responsibilities includes:
○ RDS and PolarDB-X: Carry business data and connect with the multi-active control system.
○ DTS: Enables cross-city real-time synchronization and status reporting.
○ MSHA: Enables multi-active traffic control and disaster recovery failover.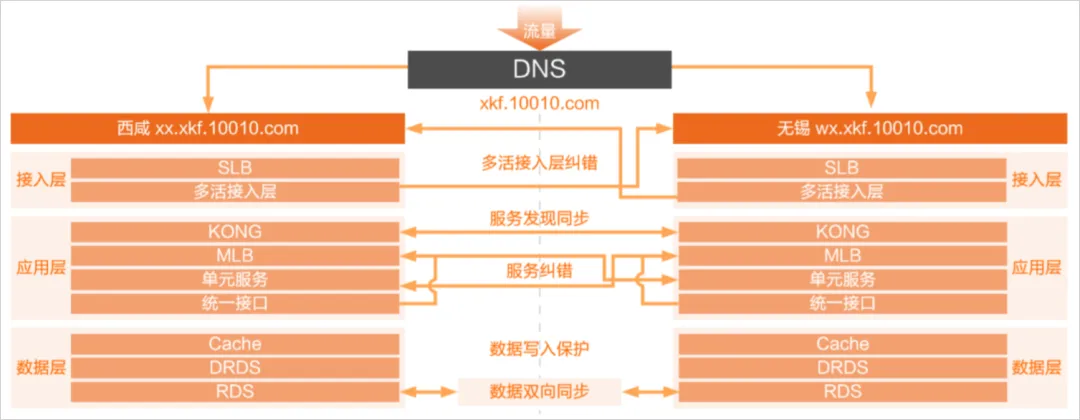
○ Final Outcomes
■ State Taxation Administration:
● Implemented multiple routing strategies for different business modules:
○ Online services of the Natural Person Electronic Tax Bureau: Routed based on natural person archive number.
○ Offline list query services: Routed by region.
● Achieved Level 6 disaster recovery capability under the national standard.
● Achieved second-level disaster recovery failover with zero data loss.
● The customer deployed two units, with each unit carrying 50% of business traffic during normal operations, improving resource utilization.
● Leveraged flexible traffic allocation strategies of multi-active control to enable gray release for major business launches.
■ China Unicom New Customer Service System:
● Seven business areas, including access centers, outbound call centers, and business support, implemented region-based multi-active traffic routing.
● Completed multiple disaster recovery drills and supported traffic switching for multiple provinces.
● Achieved second-level failover and zero data loss.
● Deployed two units, with both units carrying business traffic during normal operations, improving resource utilization and avoiding long-term idleness of disaster recovery resources. (src: Alibaba Cloud PolarDB-X Solutions and Customer Cases)
RFPs & Tenders
3.2

Awarded Projects
3.3
Industry Pluse
04
Industry Research & Reports
4.1
● Gartner forecasts worldwide semiconductor revenue to exceed $1.32 trillion in 2026, with AI semiconductors capturing 30% of total market value.
○ Released April 8, 2026, the Gartner forecast projects 64% annual growth, driven by hyperscale AI infrastructure capital expenditure increasing over 50% year-on-year.
○ Memory revenue is expected to triple, with DRAM annual prices rising 125% and NAND flash prices surging 234%—a phenomenon Gartner terms “memflation.” The non-memory segment is forecast to reach $686.9 billion, while memory climbs to $633.3 billion.
○ Gartner Senior Principal Analyst Rajeev Rajput notes that memflation, while profound, is not perennial, though meaningful pricing relief is unlikely before late 2027.
○ AI accelerators—including GPUs and custom non-GPU chips—are identified as the primary demand driver, with the analysis warning that non-AI semiconductor demand will be delayed into 2028 as capacity and capital prioritize AI workloads.
○ Key Takeaway: The $1.32 trillion forecast redefines the semiconductor demand pyramid: AI is consuming such a large share of advanced node and memory capacity that traditional computing and consumer segments face 18–24 month procurement delays.(src: Gartner Forecasts Worldwide Semiconductor Revenue to Exceed $1.3 Trillion in 202, Gartner Forecasts Worldwide Semiconductor Revenue to Exceed $1.3 Trillion in 2026)
● Omdia revises its 2026 semiconductor growth forecast upward to 62.7%, citing an AI-driven memory supply crunch that will persist through 2027.
○ Published April 23–24, 2026, the Omdia update anticipates the DRAM market nearly doubling in value and the NAND segment quadrupling versus 2025. A critical supply-side dynamic identified is the industry’s prioritization of High Bandwidth Memory (HBM) production, which consumes approximately three times the wafer area of standard DRAM per bit output. HBM3e and emerging HBM4 stacks—with 12-layer and 16-layer architectures—exhibit lower yields, further constraining total memory bit supply.
○ Omdia notes that standard DRAM supply-to-demand ratios have hit a five-year low. Computing and data storage semiconductor revenue is projected to rise 90% year-on-year, exceeding $700 billion. Enterprise server refresh cycles, coinciding with elevated hyperscaler capex, are pushing average selling prices upward across the board.
○ Key Takeaway: HBM’s physical yield and area intensity is creating a structural supply diversion: standard DRAM and NAND shortages are no longer cyclical but architectural, meaning memory-dependent industries must plan for 18+ months of elevated pricing.(src: Omdia Raises 2026 Semiconductor Forecast to 62.7% as AI Drives Global Memory Crunch, Omdia Raises 2026 Semiconductor Forecast to 62.7% as AI Drives Global Memory Crunch)
● Deloitte’s State of AI in the Enterprise, April 2026 edition, documents a 25-percentage-point production gap and a fundamental rebuild of IT operating models.
○ Released April 23, 2026, the report finds that only 25% of organizations have moved 40% or more of AI experiments into production, though 54% plan to do so within six months. Transformative AI impact has more than doubled from 12% to 25% year-on-year, while 84% of executives are increasing AI budgets.
○ A parallel April 22 announcement established the Deloitte-Google Cloud Agentic Practice, with Gemini Enterprise positioned as the reference architecture for Fortune 500 deployments. Deloitte’s internal “Sidekick” tool reports verified time savings of two hours per employee per week. Drawing from the firm’s 17th annual Tech Trends framework, the analysis notes that token costs have dropped 280-fold in two years, yet enterprise inference bills remain in the tens of millions monthly—indicating that usage growth has outpaced cost declines. Critically, 99% of surveyed IT leaders report major operating model changes underway, with AI architect roles expected to nearly double from 30% to 58% penetration within two years.
○ Key Takeaway: Enterprise AI has shifted from technology adoption to organizational reconstruction; the gap between pilot and production is now a workflow-design problem, not a model-capability problem, demanding CIOs to rebuild processes rather than automate legacy ones.(src: Deloitte State of AI 2026 from April 23: Three Numbers for the Next IT-Committee Paper)
● Research Nester publishes its data governance market analysis, projecting a 21.2% CAGR to $38.3 billion by 2035 as AI readiness reshapes enterprise data architecture.
○ Dated April 6, 2026, the report establishes the 2025 data governance market baseline at $5.6 billion, driven by the need to govern unstructured data growing at 30% annually and to enable AI-compliance pipelines. North America is projected to hold a 42.4% share by 2035, while large enterprises account for 62.5% of spend. The analysis identifies Informatica, Microsoft, IBM, SAP, Oracle, and Collibra as dominant platform vendors, with demand acceleration stemming from computational governance solutions—automating standards enforcement, deployment acceleration, and end-to-end compliance for data products at scale. The report underscores that data governance is transitioning from passive cataloging to active enforcement layers required for agentic AI and autonomous workflows.
○ Key Takeaway: Data governance is being redefined as an AI-readiness control plane; the 21.2% CAGR reflects not regulatory caution, but the operational necessity of governing data products that feed autonomous enterprise agents.(src: Key Data Governance Market Insights Summary)
Events & Conferences
4.2
● Google Cloud Next '26, themed "The Agentic Cloud," took place from April 22–24, 2026, at the Mandalay Bay Convention Center in Las Vegas, NV, drawing approximately 32,000 participants. Thomas Kurian, CEO of Google Cloud, delivered the opening keynote titled "The Agentic Cloud," while Sundar Pichai, CEO of Google & Alphabet, contributed a pre-recorded strategic address. Core Announcements:
○ Agentic Data Cloud rearchitects enterprise data for agentic AI. The Knowledge Catalog autonomously tags, maps, and connects enterprise data using Gemini — eliminating manual data engineering. Cross-Cloud Lakehouse, standardized on Apache Iceberg, lets agents query data in-place across clouds (including AWS and Azure) without migration. The architecture shifts enterprise data from a passive "system of record" to an active"system of action." Speaker: Thomas Kurian
○ Gemini Enterprise Agent Platform launches as the unified replacement for Vertex AI. Presented by Thomas Kurian during the opening keynote, the platform delivers a full-lifecycle stack for building, governing, and scaling AI agents — covering Agent Studio (low-code/natural-language development), Agent Runtime, Agent Registry, Agent Identity, Agent Gateway (governance and guardrails), and Agent-to-Agent Orchestration. It provides access to 200+ models including Gemini 3.1 Pro (optimized for complex multi-step workflows), Gemini 3.1 Flash Image (codenamed "Nano Banana 2" for visual asset generation), Lyria 3 (professional audio), and Anthropic Claude Opus 4.7. Google confirmed Vertex AI's roadmap will converge into the Agent Platform; Vertex AI will not remain a standalone service. Speaker: Thomas Kurian
○ Eighth-generation TPUs adopt a dual-chip architecture splitting training and inference. The TPU 8t (training-optimized) scales to 9,600 chips per Superpod with 2 PB of shared high-bandwidth memory, delivering 121 ExaFLOPS at FP4 — 3x the processing power of Ironwood with up to 2x performance per watt. The TPU 8i (inference-optimized) connects 1,152 chips per pod with 3x more on-chip SRAM, designed for low-latency, high-throughput concurrent agent execution at 80% better inference performance per dollar. Google also unveiled the Virgo Network, a custom-built "campus-as-a-computer" interconnect system for massive AI supercomputers, alongside Managed Lustre storage hitting 10 TB/s throughput. Speaker: Sundar Pichai
○ A2A (Agent-to-Agent) Protocol hits v1.0 production-ready status, adopted by 150+ organizations. Originally developed by Google and donated to the Linux Foundation, the A2A protocol enables cross-framework agent interoperability with native support for LangGraph, CrewAI, LlamaIndex, AutoGen, and Semantic Kernel. It complements MCP (Model Context Protocol) — MCP handles Agent-to-Tool communication; A2A handles Agent-to-Agent communication. Google launched Managed MCP Servers with Apigee serving as the bridge between traditional APIs and agents, forming a unified connectivity layer. Speaker: Thomas Kurian
○ Wiz integration delivers Agentic Defense across code-to-cloud runtime. Following the $32B acquisition, Wiz AI Application Protection Platform (AI-APP) provides autonomous protection across multicloud, hybrid, and AI environments — adding dynamic AI-BOM capabilities that automatically inventory AI frameworks, models, and IDE extensions to detect shadow AI. Google Security Operations introduced three new security agents: Threat Hunting Agent (proactive threat hunting and autonomous rule-writing), Detection Engineering Agent (coverage-gap identification and auto-creation of detections), and Third-Party Context Agent (third-party data enrichment). Speaker: Thomas Kurian
○ Workspace Intelligence goes GA, unifying Workspace apps under a semantic layer. The release enables cross-app context spanning Gmail, Docs, Drive, and Meet — allowing users to invoke Ask Gemini inside Chat to query and act across all Workspace data (schedule meetings, draft briefs). Rapid Enterprise Migration (preview) accelerates migrations from Microsoft 365 by 5x. Agent Designer, a no-code tool, lets non-technical users build custom trigger-based workflows via natural language. Speaker: Thomas Kurian
○ Sundar Pichai reveals Google's internal AI adoption metrics: 75% of all new code at Google is now AI-generated and engineer-approved, up from 50% last fall. The company is shifting to fully agentic development workflows — a recent complex code migration completed 6x faster via human-agent collaboration versus engineers alone. The Gemini app for MacOS was prototyped from idea to native Swift app in days using the internal agentic development platform Antigravity. Security Operations Center agents auto-triage tens of thousands of unstructured threat reports monthly, cutting threat mitigation time by over 90%. Gemini Enterprise paid monthly active users grew 40% QoQ in Q1. Speaker: Sundar Pichai
○ Google Cloud commits $750M partner fund to accelerate agentic AI deployment. The fund targets Google Cloud's 120,000+ partner ecosystem (including Accenture, BCG, Deloitte, McKinsey) to provide AI value assessments, agent prototyping, technical training, and embedded engineering support. The goal is to move enterprise customers from AI experimentation to production deployment at scale. Speaker: Thomas Kurian
○ Apple-Google Cloud partnership confirmed on keynote stage. Google serves as Apple's "preferred cloud provider," co-developing next-generation Apple Foundation Models using Gemini technology to power the personalized Siri experience scheduled for late 2026. The architecture combines Apple's Private Cloud Compute with Google Cloud servers in a hybrid deployment. Speaker: Thomas Kurian(src: 7 highlights from Google Cloud Next ‘26, Cloud Next ‘26: Momentum and innovation at Google scale)
● ISIG Executive Summit USA 2026 convenes C-suite leaders across the semiconductor value chain to define AI-era packaging and interconnect roadmaps.
○ Held April 20–22 at the Plug and Play Tech Center in Silicon Valley, this invitation-only summit carries the theme “Scaling AI: Hardware Innovation, Compute Acceleration and Next-gen Infrastructure.” The agenda zeroes in on advanced packaging, co-packaged optics (CPO), High Bandwidth Memory (HBM) scaling, silicon photonics, and test automation for AI accelerators.
○ Confirmed participants span Marvell, Intel, Microsoft, Meta, Micron, and Amkor, with panel discussions covering the shift from monolithic dies to chiplet-based architectures and the optical interconnect transition required for next-generation AI clusters.
○ The summit directly shapes procurement and R&D priorities for foundry services, OSATs, substrate suppliers, and EDA vendors across the global supply chain.
○ Key Takeaway: Advanced packaging and optical interconnect are now the bottleneck variables for AI compute scaling; decisions made at this summit influence capital allocation across the OSAT, materials, and photonics ecosystem through 2027.(ISIG Executive Summit USA 2026,E&R Engineering to Feature Advanced Packaging and CPO Innovations at ISIG 2026)
● ODSC AI East 2026 delivers the largest practitioner-focused technical program for production-grade AI, data engineering, and agentic systems.
○ Running April 28–30 at the Hynes Convention Center in Boston, the conference features 250+ speakers and 300+ hours of hands-on training across tracks including Large Language Models (LLMs), Generative AI & RAG, Agentic AI & Workflow Automation, Data Engineering, MLOps, and AI for Robotics.
○ Speakers include representatives from OpenAI, Databricks, Anthropic, MIT, and LangChain.
○ Unlike strategy-heavy vendor conferences, ODSC East targets implementation depth—covering retrieval-augmented generation architectures, autonomous agent orchestration, scalable data pipeline design, and robotics-specific physical AI. Co-located events include the AI X Leadership Summit for executives and an AI Expo & Demo Hall showcasing enterprise-ready platforms.
○ The conference signals where data science teams are shifting budgets from experimental pilots to production infrastructure.
○ Key Takeaway: Agentic AI and LLM deployment at scale are moving from proof-of-concept to engineering discipline; the tooling and talent priorities showcased here filter into enterprise data-stack procurement cycles within the next two quarters.(src: ODSC AI East 2026 Conference | Open Data Science Conference)
● infra/CAPITAL 2026 unites European hyperscale operators, investors, and AI infrastructure leaders to address the continent’s data center capacity and energy constraints.
○ Taking place April 15–16 at the Kimpton St Honoré in Paris, the summit is jointly curated by Structure Research and The Tech Capital. The program centers on hyperscale AI strategy, neocloud and alternative cloud growth, public funding for sovereign AI projects, and the energy bottlenecks limiting European deployment.
○ Confirmed speakers include representatives from Mistral AI, the European Commission, Ardian, Data4, NTT GDC, Iron Mountain Data Centers, and SMBC Bank International.
○ Sessions dissect where data center capacity will and will not be built across Europe, the role of nuclear and renewable energy in powering AI clusters, and the post-first-wave build-out economics of AI infrastructure. For semiconductor and equipment vendors, the summit offers a demand-side read on European compute expansion timelines.
○ Key Takeaway: European AI infrastructure build-out is entering a capital-constrained second wave; location, energy access, and regulatory frameworks are becoming harder constraints than silicon availability for continental AI capacity scaling.(src: infra/CAPITAL 2026 Paris - Meet TYTEC AB at Europe’s AI Infrastructure and Data Centre Summit)
● Data Center World 2026 addresses the operational reality of AI-driven facilities, from power architecture to robotic automation.
○ Held April 20–23 at the Walter E. Washington Convention Center in D.C., the flagship Informa Tech event draws 2,000–5,000 practitioners with a program focused on next-generation power infrastructure, liquid cooling, sustainable operations, and AI-driven data center management.
○ A featured panel, “The Two-Day Imperative: Automating Data Center Operations Beyond the Build,” includes Microsoft and Americase, emphasizing that robotic automation is now a necessity rather than a luxury for maintaining 99.9% uptime amid AI-driven expansion. With 200–499 exhibitors, the event covers the full stack of facility hardware, DCIM software, thermal management, and physical security—directly influencing procurement standards for enterprise and colocation operators.
○ Key Takeaway: AI workload density is forcing a facilities-level transition: liquid cooling, robotic automation, and modular power architectures are becoming baseline requirements for new data center deployments.(src: Data Center World 2026)
● 2026 RISC-V Now! by Andes marks a pivot point for commercial RISC-V deployment in AI, automotive, and data center silicon.
○ Held April 15 at the Sheraton Hsinchu Hotel in Taiwan, this ecosystem conference focuses on transitioning RISC-V standards into shipping products. Tracks span AI acceleration, automotive SoCs, datacenter processors, and IoT endpoints—addressing architecture decisions, software enablement, and system integration at commercial scale.
○ As the industry seeks alternatives to proprietary ISA dominance in AI silicon and heterogeneous compute, the event provides a demand signal for IP vendors, EDA toolchains, and foundry process nodes supporting RISC-V cores.
○ Key Takeaway: RISC-V is crossing the chasm from standards discussion to volume silicon; the AI and automotive tracks indicate where alternative-ISA chips will challenge incumbent architectures in edge and embedded compute.(src: 【Finished】2026 RISC-V Now! by Andes Hsinchu)
Corporate Updates
4.3
● MongoDB announced an expansion of its product leadership team, appointing Pablo Stern as Chief Product Officer, AI and Emerging Products, while also appointing longtime MongoDB executive Ben Cefalo as Chief Product Officer, Core Products. Current CTO Jim Scharf will continue to lead the engineering organization and the Global Security Office. All three will report to MongoDB President and CEO CJ Desai.
○ The core objective of this adjustment is to split MongoDB’s product management structure into two clearer strategic directions: continuing to drive innovation in its core database products on one hand, and accelerating iteration in AI and emerging products on the other. MongoDB stated that by assigning dedicated leaders to different focus areas, the company aims to better support customers in standardizing both core applications and AI workloads on the MongoDB platform.
○ Under the new structure, Pablo Stern will oversee MongoDB’s AI product portfolio, including Search, Vector Search, Voyage, as well as future AI products and strategic initiatives with AI-native companies and foundation model companies. Stern previously served as EVP & GM of Technology Workflow Products at ServiceNow, where he helped grow the IT Operations Management business from $100 million to more than $1 billion in five years.
○ Ben Cefalo will oversee MongoDB’s core product portfolio, including MongoDB Atlas and Enterprise Advanced. He joined MongoDB in 2017 and previously served as SVP, Head of Core Products and Atlas Foundational Services. MongoDB’s database products are the primary driver of the company’s growth, with FY26 revenue reaching $2.46 billion and a global customer base of more than 65,200.
○ Jim Scharf will continue to serve as CTO, leading the engineering organization and the Global Security Office. He will be responsible for driving the product strategy and roadmap execution for both core and emerging products, while ensuring that the platform meets the requirements of large enterprise customers in terms of security, durability, availability, and performance. (src: MongoDB Expands Product Leadership to Accelerate Growth and Innovation)
Funding & Deals
4.4
● ArcheBase (智域基石), a provider of data infrastructure for embodied AI, recently completed an angel funding round backed by several robotics manufacturers and investment firms, aiming to address the shortage of high-quality interactive data for embodied AI systems.
○ Regarding its core business, ArcheBase focuses on building foundational data systems for embodied AI. The company has independently developed a five-stage data processing pipeline encompassing quality inspection, data foundation, compilation, retrieval, and delivery. This technology transforms unstructured, highly sequential, and multimodal raw records from the physical world into stable, structured samples through spatio-temporal alignment and semantic annotation. This breakthrough significantly reduces data acquisition costs and accelerates the commercial deployment of robotic models in complex scenarios such as manufacturing and warehousing.
○ Regarding the team background, the core members hail from top-tier data infrastructure and tech giants including PingCAP, Tencent, and Huawei.
■ CEO Yang Zhexuan, an early core member of PingCAP, specializes in large-scale distributed systems and underlying architecture.
■ CTO Xu Liangwei brings a composite background in robotics and algorithms, with expertise in hardware-software integration and embodied model training.
■ COO Zhang Jiye, a former regional general manager at Huawei and head of ecology at Noematrix, oversees industrial implementation and strategic partnerships.
○ Regarding financing details, the round raised tens of millions of yuan, with investors including PsiBot (灵初智能), Noematrix (穹彻智能), Zhejiang Humanoid Robot Innovation Center, AI² Robotics (智平方), and Xiaomiao Langcheng. The fact that this round was led by multiple robotics OEMs (Original Equipment Manufacturers) underscores the industry's urgent demand for standardized data processing capabilities. It also signals a strategic shift in the embodied AI landscape—moving beyond hardware and model competition toward a focus on underlying data infrastructure. (src: 没等VC下场,机器人厂商先投了一家具身数据基础设施公司)
● Deta Intelligence (德塔智能), a provider of underlying technology for embodied AI, has completed three consecutive rounds of financing totaling over 100 million RMB within just three months of its establishment, receiving significant backing from GL Ventures and several leading humanoid robot manufacturers.
○ Regarding its core business, Deta Intelligence focuses on the research and development of native Humanoid Foundation Models (HFMs). Its technology relies on a native human-like "brain-cerebellum" architecture and a native 3D spatial reasoning world engine, combined with a self-developed Loco-manipulation hybrid force-position control framework. By addressing the fragmented nature of robot perception, decision-making, and motion control at the logic level, the company enables long-horizon, whole-body coordinated operations in complex dynamic environments.
○ Regarding the team background, the core members are alumni of Tsinghua, Peking University, UCLA, and Columbia, bringing together scientists and engineers from elite institutions such as Google, DeepMind, Amazon, NVIDIA, and FAIR.
■ Founder & CEO Ma Xiaojian: A Tsinghua CS graduate with a PhD from UCLA; formerly with Google Robotics and NVIDIA Research. He previously led the development of the first native spatial generalist embodied agent at BIGAI.
■ Co-founder Liu Hangxin: A PhD from UCLA and Assistant Professor at Peking University; previously involved in DARPA and NSF projects and led the R&D of F-TAC, the world’s first visual-tactile dexterous hand.
■ Co-founder & Chief Scientist Huang Siyuan: A PhD from UCLA and Director of the Embodied Robotics Center at BIGAI; formerly with DeepMind and Meta. He proposed the first unified "Generation-Understanding-Planning" model for spatial intelligence and received the CoRL Best Paper Award.
○ Regarding financing details, the company has cumulatively raised over 100 million RMB (specific round amounts undisclosed). In addition to continued investment from GL Ventures (高瓴创投), the round rarely introduced top-tier humanoid hardware manufacturers—including Leju Robotics (乐聚机器人), AgiBot (智元机器人), and Galaxea (星海图)—as strategic investors. The funds will primarily be used to accelerate HFM iterations, scale up technical closed-loop construction, and advance commercial trials in industrial and service scenarios alongside strategic partners. (src: 创业3个月,融3轮,几个亿,高瓴、乐聚、智元与星海图都投了)
● Google announced an investment of up to $40 billion in AI unicorn Anthropic. Based on the latter's latest valuation of $380 billion, $10 billion will be paid immediately, while the remaining $30 billion is tied to performance milestones.
○ As a leading enterprise that developed the Claude series of foundational large models, Anthropic is facing immense infrastructure pressure brought by its annualized recurring revenue (ARR) surging to $30 billion. The core objective of this massive capital injection is directed at underlying computing power. Google Cloud has committed to delivering up to 5GW of TPU computing capacity over the next five years, which will successively come online starting in 2027, to support Anthropic's exponentially expanding model training and application needs.
○ This rare investment move by a tech giant has had a disruptive impact on the landscape of the AI industry.
■ It reveals Google's astute hedging strategy: against the backdrop of its own Gemini model facing pressure in the enterprise market, by binding its strongest competitor through both capital and computing power, Google can not only share the dividends of Claude's commercial explosion but also successfully transform Anthropic into a super customer for its own TPU capacity, consolidating the commercial moat of its underlying infrastructure.
■ This event marks the complete end of the former tripartite standoff among the AI "Big Three." As Anthropic rapidly amasses over 11GW of computing power commitments from multiple tech giants, computing power has clearly become the core strategic resource that will determine the winner in the second half of the AI race. In contrast, OpenAI, whose computing power supply is highly tethered to long-term infrastructure plans, is facing the risk of being partially isolated.
■ The competitive focus of large models has officially escalated from a mere contest of algorithm parameters to a comprehensive bipolar confrontation driven by infrastructure and capital ecosystems. (src: 谷歌跪了?400亿砸向死敌!AI御三家终结,OpenAI孤立无援)
● Fluidstack, a startup dedicated to building customized data centers for AI companies, is in talks to raise a $1 billion funding round at an $18 billion valuation, with Jane Street as the potential lead investor.
○ Notably, just a few months ago, the company completed a transaction raising approximately $700 million at a $7.5 billion valuation, meaning its valuation has more than doubled in a short period.
○ Fluidstack's core business lies in building infrastructure optimized specifically for AI needs. Differentiating itself from general-purpose cloud service providers like AWS, its data centers feature deep customization in hardware and architecture tailored for large model training and inference.
○ The funds from this round are expected to be used to expand data center deployment and order delivery in the U.S. market. The company recently signed a partnership agreement worth up to $50 billion with Anthropic to build exclusive data centers for them in Texas and New York. Consequently, Fluidstack has relocated its headquarters from the UK to New York, while simultaneously withdrawing from a ten-billion-euro-scale AI project in France. (src: AI data center startup Fluidstack in talks for $1B round at $18B valuation months after hitting $7.5B, says report)
● InsightFinder recently completed a $15 million Series B financing round led by Yu Galaxy, marking the addition of a significant player to the AI observability sector.
○ Founded by North Carolina State University professor Helen Gu and built upon 15 years of academic research, the company has been leveraging machine learning to monitor and proactively repair IT infrastructure issues since 2016. Its latest product, "Autonomous Reliability Insights," employs a technological approach that combines unsupervised machine learning, purpose-built large/small language models, predictive AI, and causal inference. This enables full-stack diagnostics and analysis across data, model, and infrastructure layers—for instance, helping a major credit card company identify model drift caused by an expired server node cache.
○ The new funding will be used to further expand the end-to-end reliability assurance capabilities of AI agents in production environments. Regarding industry impact, InsightFinder's core proposition lies in breaking the misconception that "AI observability is limited to evaluation during the LLM development and testing phases," emphasizing instead the support for a closed feedback loop across the entire pipeline of development, evaluation, and production. In a market surrounded by numerous competitors such as Grafana Labs, Datadog, and Dynatrace, the company has built a differentiated competitive moat relying on nearly a decade of cross-stack diagnostic experience, a data-agnostic architecture, and customized insight capabilities. (src: InsightFinder raises $15M to help companies figure out where AI agents go wrong)
Voices & Perspectives
4.5
● Freda Duan, Partner at Altimeter Capital, conducts a deep-dive review of the three core themes in U.S. tech investment, deconstructing the commercial moats and competitive dynamics of star companies such as OpenAI, Anthropic, and Robinhood. She analyzes the underlying logic behind the shift in AI investment from compute infrastructure to the application layer, and provides a forward-looking perspective on 2026 market trends and disruptive innovation opportunities. Key takeaways follow below:
○ Three Core Themes of the U.S. Investment Market
■ AI: Primarily focused on chips and cloud infrastructure.
■ Reindustrialization: This includes the reshoring of manufacturing, rare earths, data center infrastructure, and in the long term, robotics to level the playing field regarding labor costs. Foreign investments (such as Japanese and Korean investments in the U.S.) driven by tariffs will also flow into energy and data centers, creating a closed loop with AI compute demands.
■ Digitization of Finance: Specifically, compliance and payment integration of stablecoins and cryptocurrencies. In the future, combining stablecoin payments with "Agentic Commerce" (AI agents purchasing on behalf of users) will unlock massive potential.
○ Deep Dive into Core Star Companies
■ OpenAI & the Foundation Model Track
● Business Model Essence: Large models are a capital-intensive "negative snowball" business (similar to early Netflix). Training costs grow by 10x annually according to Scaling Laws. Only when model training hits a physical bottleneck or the ROI no longer justifies a 10x investment—causing the cash burn to slow—will the income statement experience explosive positive cash flow.
● Valuation & Revenue: Valued at a staggering $500 billion, though due to severe equity dilution, the per-share value growth isn't as exaggerated. Annualized revenue is projected to hit $20 billion by the end of the year.
● Core Competitiveness: OpenAI's biggest rival is Google. It aims to become a "Super Portal," and its potential in the enterprise (B2B) market is vastly underestimated by the public. Future monetization paths include Subscriptions, APIs, Agent commissions, Advertising (high potential), and Compute Cloud Services.
■ Anthropic (Claude)
● Business Focus: Over 80% of its business is B2B, boasting extremely high user stickiness (showing a "smile curve" in retention).
● Financial Highlights: Excellent gross margin control; expected to catch up to OpenAI by year-end. Its financial forecasting assumes a rapidly increasing "Return on Investment (ROI)" year-over-year, rather than just relying on cost-cutting.
● Product Roadmap: Focusing on high-margin vertical sectors (like coding, finance, life sciences, and law) and providing the best foundational model for the AI Agent ecosystem.
■ Robinhood (HOOD)
● Non-Consensus Investment: The market mistakenly believed retail brokerages only earn "Beta" money during bull markets, but Robinhood has demonstrated strong "Alpha."
● Core Logic: It is not just a trading app, but the "all-in-one financial account for the next generation of U.S. young and middle-aged adults." As its user base (average age 34) enters their peak wealth-building years, Robinhood is evolving into the "next Charles Schwab" by aggressively grabbing market share, diversifying operations (wealth management, prediction markets, expansion into the European tokenization market), and executing strict cost control.
■ Autonomous Driving (Waymo vs. Tesla) & Robotics
● Waymo: Progress has vastly exceeded expectations, having already achieved per-vehicle profitability in San Francisco. The core pain point is high hardware costs (sensors + chips), which requires mass production to drive down.
● Tesla: Its advantage is zero hardware scaling pressure, but its pure-vision software approach (for driverless Robotaxis) still needs to fundamentally prove itself.
● Robotics: Still in its very early stages (transitioning from research to engineering). It severely lacks data, and there is no consensus on hardware/software paths. It will likely take another 2-3 years to reach a "GPT moment" where robots can perform basic general tasks (like folding clothes or organizing).
○ Silicon Valley VC Ecosystem & Investment Logic
■ VC vs. Public Markets: Venture Capital relies on "consensus investing" (needing the market to continuously fund the cash burn). It is incredibly hard to scale, and the industry's overall returns are much lower than the public perceives. Public markets, however, rely on "non-consensus investing" to earn alpha, with infinite capacity.
■ Concentrated Portfolio Strategy: The best investment approach is to "put all your eggs in one basket and watch it closely." Outsized returns come from taking heavy positions in a very small number of thoroughly understood companies, rather than diversifying risks away.
■ Preferred Founder Personas: Silicon Valley favors "Bad Boys/Rebels" (who dare to break the rules, like Robinhood's CEO), "Hedgehogs" (who spend their whole lives digging one hole), and "Nezha-types" (trauma-driven founders determined to prove the world wrong).
○ AI Application Layer & The "Bubble" Debate
■ Most Promising AI Application Tracks
● Coding: Growing the fastest. Generated over $5 billion in annualized revenue within a single year (e.g., Cursor).
● Video Generation: Video is the highest-bandwidth information format. Short-form video (including AI-generated mini-dramas) will further cannibalize long-form video watch time, likely giving birth to decacorn companies.
● Agentic Commerce: AI agents making purchasing decisions and executing payments for users. This will completely disrupt the current internet traffic distribution and advertising landscape. Ad-dependent platforms (like Google and Amazon) will suffer, while long-tail merchants (like the Shopify ecosystem) will benefit.
■ Is AI a Bubble?
● Short-term verdict: Absolutely not. ChatGPT reached in less than three years the adoption rate that took the internet a decade. We can already track roughly $70 billion in pure AI revenue.
● Macro Logic: Ultimately, AI is going after the $15 trillion U.S. labor cost market, not just the $400 billion internet advertising market. As long as models (like the ones trained on Blackwell) continue to improve and ROI increases, massive investments in compute infrastructure are economically justified.
○ 2026 Market Outlook & Mega 7 Rankings
■ Core Prediction for 2026: The market will "reward profits." The AI Application layer will outperform the AI Infrastructure layer. Capital will flow toward companies with tangible, materialized AI revenues.
■ Tech Giants (Mega 7) & Key Targets Outlook:
● Tesla (Autonomous Driving): It all depends on whether they can completely remove the safety driver and deploy true Robotaxis. The "grand narrative" of disruptive tech is always most profitable to invest in during the 18 months right before it fully materializes.
● Apple (Edge AI): Worth anticipating a potential "double-click" rerating—with the new Siri in 2026 and potential foldable phones, a fundamental turnaround (similar to Google's recent rebound) is possible.
● Google (Multimodal/Search): It possesses SOTA (State-of-the-Art) models and excellent positioning, but its cash-cow search ad business faces an existential threat from OpenAI and Agentic Commerce.
● Meta (Multimodal): Facing a severe CapEx test. If obvious AI revenues aren't generated, cash flow will be heavily pressured. Their next-gen multimodal model's performance is crucial to watch.
● The Three Clouds (Microsoft, Amazon, Google): Maintaining strong growth, but the competitive landscape is worsening. With new players like Oracle and various "neo-clouds" entering the fray, profit margins will be squeezed by price wars.
● Traditional Industry Leaders (AI Beneficiaries): These are the dark horses for next year. Companies like Walmart (supply chain prediction), financial institutions (loan approval efficiency), and logistics giants are already seeing clear margin expansion directly attributed to AI implementation.
● Other Hot Sectors: Space stocks (driven by SpaceX's potential IPO) and Prediction Markets (like Polymarket, capitalizing on major events like the World Cup). (src: 一家投资OpenAI的硅谷基金的深度研究)
● In this in-depth dialogue, Luo Fuli—former senior researcher at Alibaba DAMO Academy and DeepSeek, and currently head of Xiaomi’s Large Model Team—provides a comprehensive review of the 2026 seismic shift in AI technology. She analyzes the paradigm shift from Chat to Agent, deconstructs the R&D logic of the MiMo-V2 series and competitive strategies in the "post-training" era, reveals an organizational paradigm for extreme innovation free of hierarchical constraints, and looks ahead at the evolutionary path toward AGI. The following are the key takeaways:
○ Core Theme: The global large model arms race has comprehensively shifted from the Chat era dominated by Pre-training to the Agent era dominated by Post-training. During this massive paradigm shift, the boundaries of AI capabilities have been vastly expanded, even beginning to show the evolutionary potential of "AI training AI."
○ The "OpenClaw Moment": A Catalyst for Activating Swarm Intelligence
■ Framework Reshaping Perception: Luo initially doubted the open-source Agent framework OpenClaw, but after deep usage, was blown away by its autonomy, EQ, and fine-tuned context orchestration. It is not just a product, but an "epoch-making agent framework."
■ Bridging Model Shortcomings: OpenClaw's strength lies in its complex framework design (e.g., persistent memory, multi-message channels, proactive cron tasks), which greatly compensates for the action deficits of mid-tier models, allowing them (e.g., those at 85% of the top-tier level) to reach an astonishing upper limit.
■ Open Source Spurs Collective Evolution: Compared to the closed-source Claude Code, OpenClaw's open-source nature allows developers worldwide (even non-AI researchers) to collaboratively improve its architecture. This "swarm intelligence" drastically accelerates the iteration speed of Agent frameworks.
○ Technical Paradigm Shift: From Chat to Agent
■ 1T Scale is the Ticket to Entry: To reach the level of top-tier models (like Claude Opus 4.6) in the Agent era, a base model with 1 Trillion (1T) parameters is a mandatory ticket to entry.
■ The Decisive Role of Post-training: * In the past (Chat era), the compute allocation ratio might have been Pre-train:Post-train = 5:1. Now, a reasonable ratio is approaching 1:1.
● The current match point is: How to execute Reinforcement Learning (RL) scaling effectively on Agents.
■ Long-horizon Tasks and the Generalization Power of Code: Software development (Code) is one of the very few scenarios that can provide high-quality long-context data at the 1-Million (1M) token level. Mastering the Code scenario allows its long-horizon reasoning capabilities to generalize to other complex, high-value daily tasks.
○ Xiaomi MiMo-V2's Technological Bets and Breakthroughs
■ Ultimate Cost-Effectiveness and Speed (Flash/Pro):
● Architecture Choice: Abandoned the then-mainstream MLA (Multi-head Latent Attention) architecture in favor of Hybrid Attention paired with MTP (Multi-Token Prediction).
● Advantage: This design provides extremely high inference efficiency and low cost for Long Contexts, perfectly aligning with the Agent era's demand for ultra-fast inference and massive contexts.
■ Omni-Modal Exploration (Omni/TTS):
● Insisted on discretizing modalities like audio and unifying them into the language model paradigm. Although the improvement in the pure "intelligence ceiling" from multi-modality hasn't fully manifested on benchmarks yet, it significantly enhances the model's perception of real-world details and its "EQ."
○ "Egalitarian Organization" to Inspire Emergence
■ Breaking Boundaries: Encouraging those doing pre-training to do post-training, because pre-trainers naturally possess a perspective on "data diversity," which is urgently needed to break through post-training bottlenecks.
■ Driven by Passion and Environment: Not relying on traditional KPI management, but driven by "experience and passion." Building a highly active internal communication environment that allows trial and error and is full of a geek spirit.
■ Tolerating Ambiguity: The infrastructure for Reinforcement Learning (RL) is full of uncertainties and gray areas. The team must tolerate various "breakages" during the system's rollout process, which demands extremely high technical agility.
○ Predictions for the AGI Endgame
■ Timeline: Luo predicts AGI could be realized within two years (around 2028). By then, the work patterns of the vast majority of humanity will be upended.
■ The Strategic Value of Open Source: Realizing AGI requires massive amounts of chips and compute, which a single company cannot monopolize. Open source is not just a technical choice, but an inevitable path to accelerate AGI and catalyze an explosion in the hardware/software ecosystem.
■ AI's Self-Evolution: A shocking yet brutal reality is that large models can not only complete high-value tasks, but can already participate in the scientific research of "training stronger models," achieving a self-bootstrapping evolutionary leap. (src: 独家对话罗福莉:AI范式已然巨变)
● Dowson Tong, Senior Executive Vice President of Tencent and CEO of Tencent Cloud and Smart Industries Group, provides an in-depth analysis of AI’s official entry into the "Harness" era. He dissects the new collaborative paradigm of "Engine-Harness-Driver," explores the critical shift from pure model capabilities to engineering implementation (Agent working environments), and examines its impact on AI development models, organizational productivity, and the future value of human-machine interaction. The key takeaways are as follows:
○ Core Positioning: The Engine, the Wiring Harness, and the Driver
■ Understanding the current AI ecosystem can be vividly compared to the automotive industry:
● Large models are the "engine": They provide raw, surging intelligent power but cannot directly execute operations themselves.
● The Harness is the "wiring harness": It encompasses code, configurations, feedback loops, and safety constraints, translating the model's thinking into actual operations and a usable system.
● The user is the "driver": Responsible for setting goals, controlling the direction, and verifying the results.
■ In the past, the industry's attention was focused on building stronger engines. Now, the focal point of competition is shifting toward how to better utilize the engine (the Harness).
○ Drivers Behind Harness Stepping to the Forefront and Engineering Discoveries
■ As AI evolves from a "one-off dialogue tool" to an "agent" that continuously executes tasks, it needs to remember context, call upon tools, and self-correct when making mistakes. This transition from "answering questions" to "executing work" inevitably requires a complete working environment. In specific engineering practices, four key conclusions have emerged:
● The capability ceiling lies outside the model: With the model remaining unchanged, optimizing the external Harness alone (e.g., providing better toolchains and working environments) can significantly improve task success rates and actual performance.
● Constraints guide intelligence: Setting clear boundaries and limits for AI actually reduces ineffective exploration, improving its efficiency and productivity in converging on the correct answers.
● External systems guarantee safety: Unconstrained models pose uncontrollable risks. The Harness, through mechanisms like sandbox isolation, permission settings, and manual approval, equips AI with the safety conditions necessary to truly enter enterprise production environments.
● Independent evaluation mechanisms are indispensable: AI cannot reliably and objectively evaluate its own work quality; an effective quality-control closed loop must be established outside the model.
○ The Awakening of the Driver: The Elevation of the Human Role
■ The leap in AI capabilities has not lowered the requirements for humans; instead, it has raised the bar. In the Harness era, humans still ultimately determine the quality of output.
● High-level judgment: The core competitiveness of humans is no longer execution, but "taste," an understanding of boundaries, and the ability to build a bridge between human wisdom and machine intelligence.
● The inclusive two-tier structure of AI: Top-tier users will produce works of extremely high value relying on their outstanding judgment; meanwhile, the general public, without needing to understand underlying technologies, can leverage configured Harnesses to employ 24/7 "digital employees," achieving a leap in capabilities as "super individuals."
○ Future Trends: When Models Internalize Capabilities. With technological evolution, the context windows and reasoning capabilities of large models are continuously strengthening. Functions currently undertaken by the Harness, such as tool calling and memory management, may gradually be internalized by the models themselves. The external "scaffolding" will become thinner, and the human role will upgrade from an "operator" guiding the steps to a "delegator" who merely points out the direction. However, no matter how far models evolve, they can never generate a "destination" on their own. Deciding where to go, why to go there, and measuring the value of the journey will always be the core responsibility of humans. The true value of AI lies not in the sheer strength of its raw power, but in how humans harness this power to precisely serve real-world scenarios and needs. (src: 汤道生:人工智能正式进入 Harness 时代)
On the Radar
05
Supply Chain & Ecosystem Moves
5.1
● Microsoft and OpenAI announce an amended partnership on April 27 that ends Azure's exclusive distribution rights to OpenAI models. Microsoft remains OpenAI's primary cloud partner with first-shipping rights through 2032, while OpenAI can now deploy products across any cloud provider. Microsoft retains a non-exclusive IP license through 2032 and its roughly 27% equity stake. The restructuring removes the controversial AGI clause and caps OpenAI's revenue share payments to Microsoft through 2030. (src: The next phase of the Microsoft-OpenAI partnership )
● OpenAI and AWS announce an expanded partnership on April 28, making GPT-5.5, GPT-5.4, gpt-oss-20b, and gpt-oss-120b available on Amazon Bedrock in limited preview — the first time OpenAI proprietary models run outside Azure. Codex, OpenAI's coding agent with over 4 million weekly users, also lands on Bedrock. AWS and OpenAI co-develop a "Stateful Runtime Environment" built on Bedrock AgentCore for long-running agents with persistent context. The launch follows a $38 billion, seven-year compute commitment signed in November 2025, giving OpenAI access to hundreds of thousands of NVIDIA GB200 and GB300 GPUs. (src: OpenAI models, Codex, and Managed Agents come to AWS)
● OpenAI releases GPT-5.5 on April 23, its most capable flagship model, seven weeks after GPT-5.4. The model features a 1 million token context window (400K in Codex), native full multimodal support including video, and production-ready computer use capabilities. Key benchmarks: Terminal-Bench 2.0 at 82.7%, OSWorld-Verified at 78.7%, BrowseComp at 84.4%, and FrontierMath Tier 1-3 at 51.7%. API pricing doubles to $5.00 per million input tokens and $30.00 per million output tokens. (src: Introducing GPT-5.5)
● OpenAI agrees to spend more than $20 billion over three years on Cerebras Wafer-Scale Engine AI chips, securing up to 750 megawatts of compute capacity (250MW annually from 2026-2028) with an option for an additional 1.25 gigawatts through 2030. OpenAI receives warrants for up to 33.4 million shares of non-voting Class N stock — approximately 10% dilution if fully exercised — and provides Cerebras a $1 billion working capital loan at 6% annual interest to build data center infrastructure. The deal includes co-designing future OpenAI models for Cerebras hardware. (src: OpenAI to Spend More Than $20 Billion on Cerebras Chips, Receive Equity Stake)
● Meta announces plans on April 23 to cut approximately 8,000 employees, roughly 10% of its workforce, with cuts beginning May 20. The company leaves approximately 6,000 open roles unfilled. Meta guides 2026 expenses to $162-169 billion, driven by AI infrastructure costs and highly compensated AI-expert hires. The restructuring arrives days after Meta debuts Muse Spark, a new proprietary AI product from its Meta Superintelligence Labs division. (src: Meta to cut 10% of jobs, or 8,000 employees, report says)
● Google Cloud announces a $750 million fund on April 22 at Cloud Next '26 to accelerate agentic AI development across its 120,000-member partner ecosystem, targeting consulting firms, systems integrators, and software vendors. Select partners including Accenture, BCG, Deloitte, and McKinsey receive early access to Gemini models. Google also unveils its eighth-generation TPU 8i inference chip (80% better performance per dollar, 288GB HBM) and the TPU 8t training chip, which scales to 9,600 TPUs in a superpod. Enterprise-ready agents from Adobe, Atlassian, Oracle, Salesforce, ServiceNow, and Workday debut on the Gemini Enterprise Agent Platform. (src: Google Cloud Commits $750 Million to Accelerate Partners' Agentic AI Development)
● DeepSeek releases preview versions of DeepSeek-V4-Pro (1.6 trillion total parameters, 49 billion active parameters per token) and V4-Flash (284 billion total parameters, 13 billion active parameters) on April 24, both featuring a 1 million token context window and MIT-licensed open weights on Hugging Face. The models train on and optimize for Huawei's Ascend 950 series chips using Huawei's CANN software stack rather than Nvidia's CUDA. V4-Pro is priced at approximately $3.48 per million output tokens and V4-Flash at approximately $0.28 per million output tokens. Huawei announces mass production of the 950PR chip beginning in April, with full-scale shipments expected in H2 2026; Huawei aims to ship 750,000 units this year. (src: Huawei Ascend supernode to support Deepseek V4)
● Tencent and Alibaba are in parallel negotiations to invest in DeepSeek's first-ever external funding round, with the valuation escalating from an initial $10 billion to more than $20 billion within 48 hours, per Bloomberg and The Information reports on April 22. Tencent proposes acquiring up to 20%, which DeepSeek refuses as too concentrated; the most likely scenario is a two-headed round with Tencent and Alibaba each capped at approximately 9.9%. The first tranche targets raising at least $300 million, implying less than 2% dilution. (src: Tencent, Alibaba in Talks to Join DeepSeek's First Funding Round)
● China's Cyberspace Administration of China (CAC) publicly calls out three ByteDance-owned platforms — CapCut, the Catbox app, and the Dreamina AI platform — on April 28 for failing to properly label AI-generated content. The CAC cites violations of China's Cybersecurity Law, the Interim Measures for the Management of Generative Artificial Intelligence Services, and the Measures for the Labeling of AI-Generated Synthetic Content. Enforcement actions include summoning platform operators, ordering rectification, issuing warnings, and imposing strict penalties on responsible personnel. (src: China regulator flags AI labeling failures at ByteDance appsl)
● TSMC debuts the A13 process at its North America Technology Symposium in Santa Clara on April 22. A13 is a direct shrink of A14 providing 6% area savings, with backward-compatible design rules and production scheduled for 2029. TSMC also previews A12 with Super Power Rail backside power delivery for AI/HPC, N2U offering 3-4% speed gains or 8-10% power reduction for 2028, 14-reticle-size CoWoS packaging integrating 10 compute dies and 20 HBM stacks for 2028, and 40-reticle-size SoW-X System-on-Wafer technology for 2029. The company confirms neither A13 nor A12 requires High-NA EUV lithography, relying instead on design-technology co-optimization. (src: TSMC Debuts A13 Technology at 2026 North America Technology Symposium)
● NVIDIA launches Ising on April 14, the world's first family of open-source quantum AI models targeting processor calibration and error correction decoding. The suite includes Ising Calibration, a 35-billion-parameter vision-language model outperforming Gemini 3.1 Pro by 3.27%, Claude Opus 4.6 by 9.68%, and GPT 5.4 by 14.5% on the QCalEval benchmark. It also includes Ising Decoding, a pair of 3D CNN models delivering 2.5x faster speed and 3x higher accuracy for quantum error correction versus state-of-the-art alternatives. NVIDIA CEO Jensen Huang calls Ising the "operating system of quantum machines." (src: NVIDIA Ising Introduces AI-Powered Workflows to Build Fault-Tolerant Quantum Systems)
● AMD and the French government sign a multi-year Letter of Intent in Paris on April 16 to accelerate France's National Strategy for AI. AMD provides hardware, software, and training via its University Program, AI Developer Program, and AI Academy. A centerpiece is the Alice Recoque supercomputer — France's first and Europe's second exascale system — powered by AMD EPYC "Venice" generation CPUs and Instinct MI430X accelerators, delivering more than one exaflop of HPL performance. AMD also deepens collaboration with GENCI and CEA through a planned Center of Excellence. (src: AMD and the French Government Announce Plans to Advance AI Innovation, Research and Open Ecosystem Development in France)
● Alphabet's Google is negotiating with Marvell Technology to develop two new custom AI chips on April 19, according to The Information. One is a Memory Processing Unit to complement Google's existing TPU infrastructure, and the other is a new TPU tailored for efficient AI model inference. The MPU design is planned for completion next year with test production to follow. The move signals Google's strategy to diversify its AI silicon supply chain beyond Broadcom, which signed a long-term Google chip deal through 2031 earlier in April. (src: Google in Talks With Marvell to Build New AI Chips for Inference)
Reference
06
● Snowflake Expands Snowflake Intelligence and Cortex Code to Power the Control Plane for the Agentic Enterprise - https://www.snowflake.com/en/news/press-releases/snowflake-expands-snowflake-intelligence-and-cortex-code-to-power-the-control-plane-for-the-agentic-enterprise/
● All release notes: https://docs.snowflake.com/en/release-notes/all-release-notes?bundle=true
● update overview: https://docs.databricks.com/aws/en/resources/
● VMware Greenplum 7.x Release Notes: https://techdocs.broadcom.com/us/en/vmware-tanzu/data-solutions/tanzu-greenplum/7/greenplum-database/relnotes-release-notes.html
● ChatGPT Enterprise & Edu - Release Notes: https://help.openai.com/en/articles/10128477-chatgpt-enterprise-edu-release-notes
● Claude Platform - Release notes: https://docs.anthropic.com/en/release-notes/overview
● DeepSeek-V4 预览版:迈入百万上下文普惠时代: https://api-docs.deepseek.com/zh-cn/news/news260424
● topk:https://www.topk.io/,We Raised $5.5 Million to build an AI-Native Search Engine for Enterprises:https://www.topk.io/blog/seed-round
● tavily:https://www.tavily.com/,Big News from Tavily: Announcing 25M Series A to Power the Internet of Agents:https://www.tavily.com/blog/big-news-from-tavily-announcing-25m-series-a-to-power-the-internet-of-agents,Nebius announces agreement to acquire Tavily to add agentic search to its AI cloud platform:https://nebius.com/newsroom/nebius-announces-agreement-to-acquire-tavily-to-add-agentic-search-to-its-ai-cloud-platform
● DuckLake: https://github.com/duckdb/ducklake
● Apache Paimon: https://github.com/apache/paimon
● Kestra: https://github.com/kestra-io/kestra
● Transformers are Inherently Succinct: https://arxiv.org/abs/2510.19315
● DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
● Mercedes-Benz Builds a Cross-Cloud Data Mesh with Delta Sharing and Intelligent Replication, Cutting Costs by 66%:https://www.databricks.com/blog/mercedes-benz-builds-cross-cloud-data-mesh-delta-sharing-and-intelligent-replication-cutting
● Alibaba Cloud PolarDB-X Solutions and Customer Cases: https://help.aliyun.com/zh/polardb/polardb-for-xscale/solutions-and-cases-2
● Gartner Forecasts Worldwide Semiconductor Revenue to Exceed $1.3 Trillion in 2026: https://www.gartner.com/en/newsroom/press-releases/2026-04-08-gartner-forecasts-worldwide-semiconductor-revenue-to-exceed-us-dollars-one-point-3-trillion-in-2026, Gartner Forecasts Worldwide Semiconductor Revenue to Exceed $1.3 Trillion in 2026: https://www.eletimes.ai/gartner-forecasts-worldwide-semiconductor-revenue-to-exceed-1-3-trillion-in-2026
● Omdia Raises 2026 Semiconductor Forecast to 62.7% as AI Drives Global Memory Crunch: https://www.barchart.com/story/news/1493317/omdia-raises-2026-semiconductor-forecast-to-62-7-as-ai-drives-global-memory-crunch, Omdia Raises 2026 Semiconductor Forecast to 62.7% as AI Drives Global Memory Crunch: https: //finance.yahoo.com/sectors/technology/articles/omdia-raises-2026-semiconductor-forecast-070000102.html
● Deloitte State of AI 2026 from April 23: Three Numbers for the Next IT-Committee Paper: https://www.digital-chiefs.de/en/deloitte-state-of-ai-2026-three-numbers-for-it-committee-paper
● Key Data Governance Market Insights Summary: https://www.researchnester.com/reports/data-governance-market/8501
● 7 highlights from Google Cloud Next ‘26: https://blog.google/innovation-and-ai/infrastructure-and-cloud/google-cloud/google-cloud-next-26-recap/, Cloud Next ‘26: Momentum and innovation at Google scale:https://blog.google/innovation-and-ai/infrastructure-and-cloud/google-cloud/cloud-next-2026-sundar-pichai/
● ISIG Executive Summit USA 2026: https://www.marvell.com/company/events/isig-executive-summit-usa-2026.html,E&R Engineering to Feature Advanced Packaging and CPO Innovations at ISIG 2026: https://www.barchart.com/story/news/1333416/er-engineering-to-feature-advanced-packaging-and-cpo-innovations-at-isig-2026
● ODSC AI East 2026 Conference | Open Data Science Conference: https://www.eventbrite.com/e/odsc-ai-east-2026-conference-open-data-science-conference-tickets-1780200771429
● infra/CAPITAL 2026 Paris - Meet TYTEC AB at Europe’s AI Infrastructure and Data Centre Summit: https://www.tytec.se/events/infra-capital-2026-paris
● Data Center World 2026: https://datacenterworld.com
● MongoDB Expands Product Leadership to Accelerate Growth and Innovation: https://www.mongodb.com/press/mongodb-expands-product-leadership-to-accelerate-growth-and-innovation
● 没等VC下场,机器人厂商先投了一家具身数据基础设施公司: https://mp.weixin.qq.com/s/ECDGXexNHb2IFU4szKoPww
● 创业3个月,融3轮,几个亿,高瓴、乐聚、智元与星海图都投了: https://mp.weixin.qq.com/s/9XsfJRvbZRPO1-NonB3KIg
● 谷歌跪了?400亿砸向死敌!AI御三家终结,OpenAI孤立无援: https://mp.weixin.qq.com/s/mUDP1t3yVSwaPZg9SzdgGg
● AI data center startup Fluidstack in talks for $1B round at $18B valuation months after hitting $7.5B, says report: https://techcrunch.com/2026/04/14/ai-datacenter-startup-fluidstack-in-talks-for-1b-round-at-18b-valuation-months-after-hitting-7-5b-says-report/
● InsightFinder raises $15M to help companies figure out where AI agents go wrong: https://techcrunch.com/2026/04/16/insightfinder-raises-15m-to-help-companies-figure-out-where-ai-agents-go-wrong/
● 一家投资OpenAI的硅谷基金的深度研究: https://mp.weixin.qq.com/s/uUKGLg15xw4EfOezVc7ZOQ
● 独家对话罗福莉:AI范式已然巨变!: https://mp.weixin.qq.com/s/zqnJuv5OVsNGEefM7RguqQ
● 汤道生:人工智能正式进入 Harness 时代: https://mp.weixin.qq.com/s/nJS1qMGiR7gWl1A7tchy1Q
● The next phase of the Microsoft-OpenAI partnership - https://blogs.microsoft.com/blog/2026/04/27/the-next-phase-of-the-microsoft-openai-partnership/
● OpenAI models, Codex, and Managed Agents come to AWS - https://openai.com/index/openai-on-aws/
● Introducing GPT-5.5 - https://openai.com/index/introducing-gpt-5-5/
● OpenAI to Spend More Than $20 Billion on Cerebras Chips, Receive Equity Stake - https://www.theinformation.com/articles/openai-spend-20-billion-cerebras-chips-receive-equity-stake
● Meta to cut 10% of jobs, or 8,000 employees, report says - https://techcrunch.com/2026/04/23/meta-job-cuts-10-percent-8000-employees/
● Google Cloud Commits $750 Million to Accelerate Partners' Agentic AI Development - https://www.googlecloudpresscorner.com/2026-04-22-Google-Cloud-Commits-750-Million-to-Accelerate-Partners-Agentic-AI-Development
● Huawei Ascend supernode to support Deepseek V4 - https://finance.yahoo.com/sectors/technology/articles/huawei-ascend-supernode-support-deepseek-044352075.html
● Tencent, Alibaba in Talks to Join DeepSeek's First Funding Round - https://finance.yahoo.com/sectors/technology/articles/deepseek-talks-raise-20-billion-021934042.html
● China regulator flags AI labeling failures at ByteDance apps - https://www.chinadaily.com.cn/a/202604/28/WS69f09178a310d6866eb46041.html
● TSMC Debuts A13 Technology at 2026 North America Technology Symposium - https://pr.tsmc.com/english/news/3302
● NVIDIA Ising Introduces AI-Powered Workflows to Build Fault-Tolerant Quantum Systems - https://developer.nvidia.com/blog/nvidia-ising-introduces-ai-powered-workflows-to-build-fault-tolerant-quantum-systems/
● AMD and the French Government Announce Plans to Advance AI Innovation, Research and Open Ecosystem Development in France - https://www.amd.com/en/newsroom/press-releases/2026-4-16-amd-and-the-french-government-announce-plans-to-advance.html
● Google in Talks With Marvell to Build New AI Chips for Inference - https://www.theinformation.com/articles/google-talks-marvell-build-new-ai-chips-inference
