 夜雨聆风
夜雨聆风在复杂代码库里用 AI 编程工具,遇到的第一个问题往往不是代码写不出来,而是工具一开始就看错了地方。
你让 Agent 改权限逻辑,它只看到前端按钮;你让 Agent 补测试,它没找到项目里原来的测试写法;你让 Agent 改发布脚本,它漏掉了 CI 里的另一套配置。模型再努力,也是在不完整的上下文里推理。
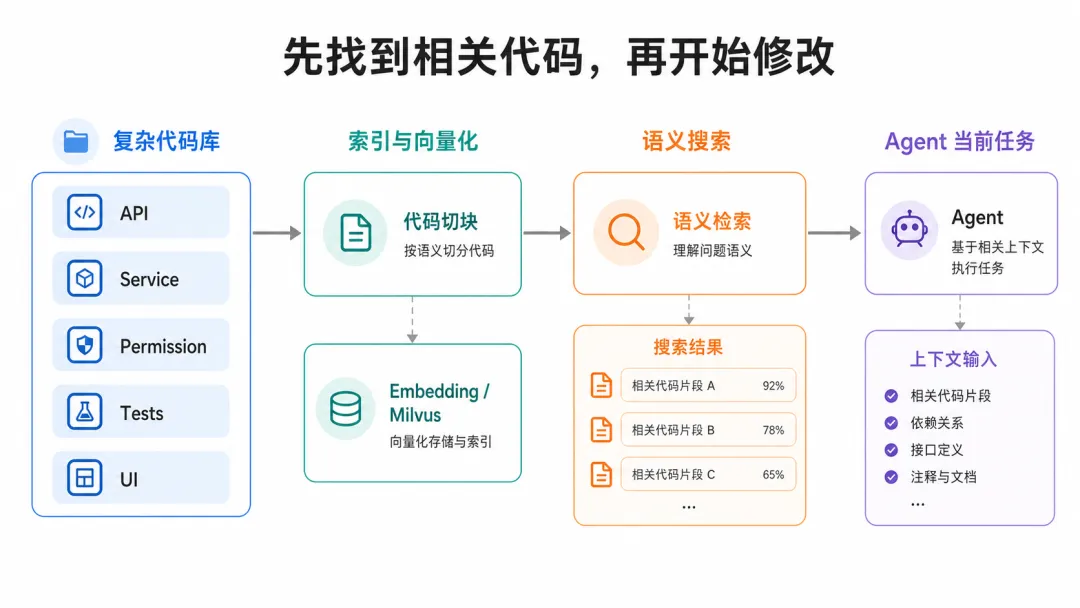
小项目里这不是问题,几个文件贴过去就够了。但项目一大,一个功能可能横跨前端页面、后端接口、权限校验、数据库迁移、任务队列、测试用例和历史兼容逻辑。你让 Agent 改一个看似简单的字段,如果它没有找到真正相关的代码,要么只改了眼前文件、遗漏调用链上的其他位置,要么为了稳妥把一大堆目录都塞进上下文,token 烧了不少,模型反而抓不住重点。
所以在复杂项目里,不一定要急着让 Agent 写代码。更稳的做法是先让 Agent 知道:这个任务应该看哪些代码。
claude-context 关注的,正是代码上下文怎么被找到、怎么被带进当前任务。
claude-context 是 Zilliz 开源的 MCP 项目,给 Claude Code 和其他支持 MCP 的 AI 编程工具加上语义代码搜索能力。
Zilliz 是做向量数据库的公司,背后最有名的项目是开源的 Milvus,一个开源向量数据库。所以 claude-context 本质上就是把代码库变成可检索的向量化上下文。
README 里有句话很直接:把整个代码库变成 Claude 的上下文。
听着有点大,但实际做法不是一次性塞给模型,而是先把代码库索引起来。等你真正提问或让 Agent 执行任务时,再从索引里检索出相关代码放进当前上下文。
这和平时用 grep 或 ripgrep 不太一样。传统搜索靠关键词——你知道要找 auth、payment、createOrder,它很好用。但很多时候我们并不知道函数叫什么,只知道要找"处理用户登录态的地方""订单支付成功以后更新状态的逻辑""创建 workspace 时默认权限在哪里设置"。这类问题更适合语义搜索。
claude-context 不是只按关键词搜索。它会先把代码拆成适合检索的片段,生成 embedding 后写入向量数据库。等你提问时,它再结合关键词和语义相似度,把更可能相关的代码片段找出来,交给 AI 编程工具使用。
所以在实际开发里,claude-context 不负责替你改代码。它更像一个代码检索层,在 Agent 动手之前,先把相关文件和代码片段找出来。真正的分析和修改,还是由 Claude Code 这类工具里的模型完成。
很多人第一次用 AI 编程工具时,看到 Agent 改错、漏改、反复找文件,容易把问题归到模型本身——改错了是不是模型不够强?漏掉边界是不是推理不行?反复找文件是不是工具调用能力差?
这些都有可能。但在真实项目里还有个更常见的原因:上下文拿错了。
你让 Agent 修权限问题,它只看到页面层判断,没看到后端的真实鉴权逻辑;你让 Agent 补测试,它只看到当前函数,没找到项目已有的测试风格;你让 Agent 改发布流程,它只看到脚本,没看到 CI 里还有另一套配置。在这种情况下,模型继续分析、继续修改,反而可能把错误方向加工得更完整。
所以一个面向复杂代码库的 AI 编程工作流,至少该多一个前置步骤:
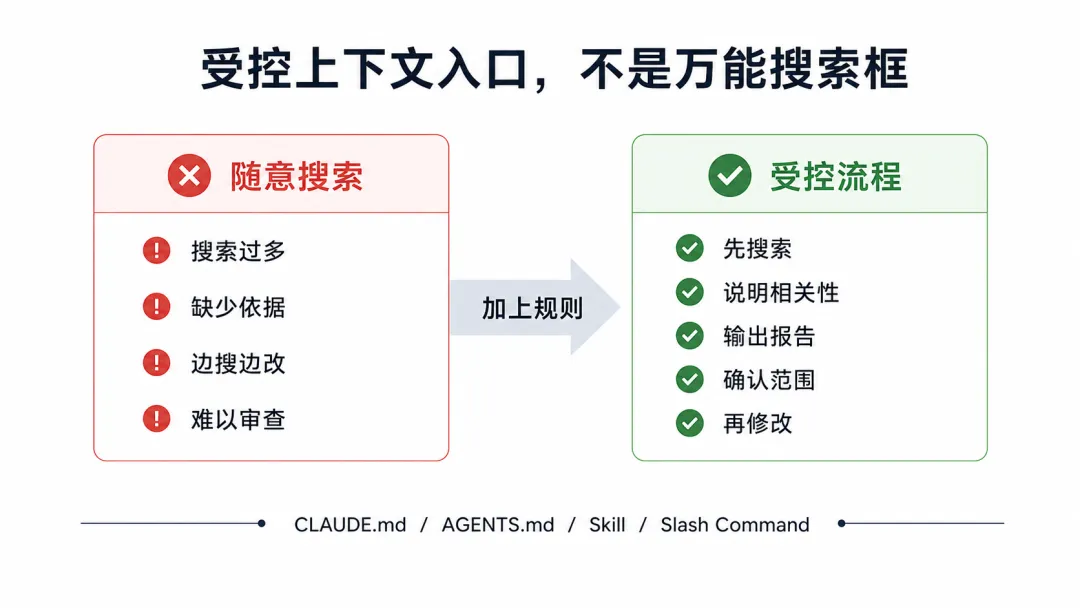
先检索相关代码 -> 形成修改计划 -> 动手改文件 -> 跑验证claude-context 的价值就在这第一步。
假设现在有个 SaaS 协作产品。产品里有很多 workspace,每个 workspace 下面有成员、项目、文档、账单和自动化任务。删除 workspace 是一个高风险动作,一旦误删,可能会影响整个团队的数据和历史记录。
因此产品规则很明确:普通成员只能查看和参与协作,不能删除 workspace;只有 owner 和 admin 才能执行删除操作。
现在有个需求:
普通成员不能删除 workspace,只有 owner 和 admin 可以删除。
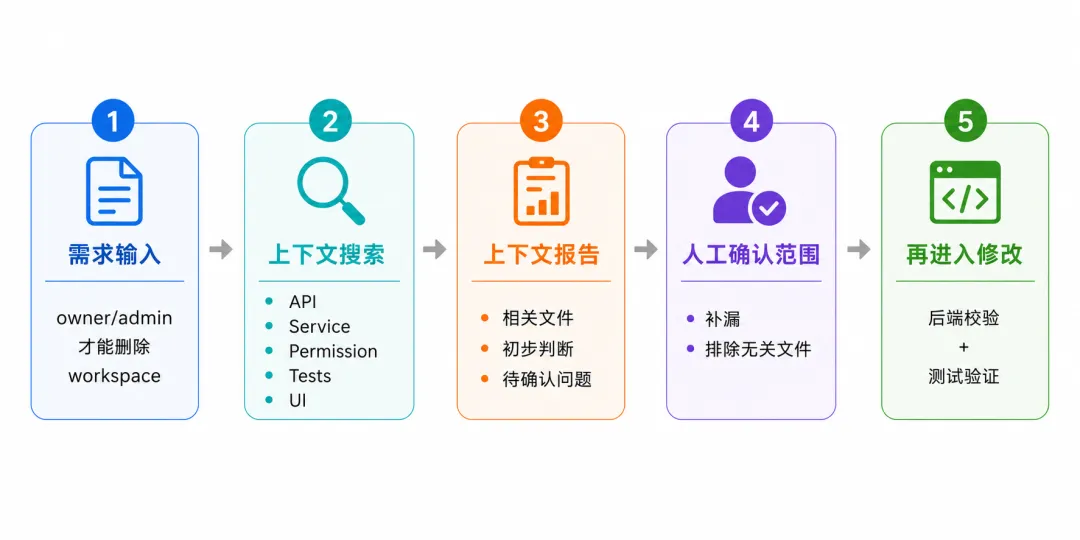
请检查当前逻辑,并补齐必要的测试。这个需求写在文档里可能只有两句话,但真正实现时,至少要看几类代码:前端删除按钮在哪里展示,后端删除接口在哪里处理,service 层有没有统一的权限校验,成员角色存在哪里,删除后是否还要清理任务、写审计日志,以及测试里有没有覆盖 owner、admin、member 三种角色。
直接丢给 Agent,它可能在当前目录里找 deleteWorkspace,也可能根据文件名猜位置。运气好能找到主入口,运气不好就只改到其中一层。
最常见的错误,是只把前端按钮隐藏了,看起来普通成员不能点删除,但后端接口仍然可以被直接调用。另一种错误,是后端加了判断,但测试没有覆盖 member 直接请求接口的情况。这样的改动看起来完成了需求,但真正的权限漏洞还在。
更稳妥的做法,是先让 Agent 通过代码索引找到相关上下文。
这里的关键是要把任务拆成两个明确阶段:第一阶段只做搜索和判断,不允许改文件;第二阶段在确认范围以后,再开始修改。
第一阶段可以这样下指令:
请先做 workspace 删除权限的上下文检查。
要求:
1. 使用代码搜索工具查找相关文件;
2. 只搜索和分析,不要修改任何文件;
3. 至少搜索以下几个方向:
- workspace 删除入口;
- workspace 成员角色定义;
- owner/admin/member 权限判断;
- 删除 workspace 的 API 或 service;
- 相关测试用例。
4. 输出一份上下文报告,按"相关文件 / 初步判断 / 修改前需要确认"三个部分组织。接入 claude-context 后,Agent 可以通过 MCP 调用语义搜索。它实际发起的搜索问题,可能类似这样:
查找 workspace 删除权限校验相关代码
查找 workspace 成员角色在哪里定义
查找 owner/admin/member 权限相关测试
查找删除 workspace 的 API 或 service 入口这几个搜索问题对应的目标也很清楚:
删除 workspace 的 API 或 service 入口
owner、admin、member 角色的定义
当前权限校验函数
已有权限测试用例
可能受影响的前端按钮或菜单逻辑
搜索完成以后,不要让 Agent 直接进入修改阶段,而是先让 Agent 按刚才约定的格式输出上下文报告。理想情况下,报告应该像这样:
## 相关文件
- apps/web/components/workspace-delete-button.tsx
相关原因:前端删除入口,控制按钮展示和点击行为。
- apps/api/routes/workspace.ts
相关原因:删除 workspace 的 API route。
- packages/auth/permissions.ts
相关原因:集中定义 workspace 角色和权限判断。
- tests/workspace-permission.test.ts
相关原因:已有 owner/admin/member 权限测试。
## 初步判断
权限校验不能只放在前端,必须在 API 或 service 层做最终判断。
## 修改前需要确认
1. admin 指的是 workspace admin,还是系统 admin;
2. owner 转让后,原 owner 是否还能删除 workspace;
3. 删除 workspace 是否需要写审计日志或触发异步任务。这份报告的价值,不在于它一定完全正确,而是先把本次修改需要关注的代码范围摆出来。开发者可以在这个阶段纠偏:哪些文件不相关,哪些路径漏掉了,哪些业务规则还没说清楚。
没有这一步时,Agent 很容易沿着最显眼的文件往下改,比如只看到前端删除按钮,就把按钮隐藏掉,却没有补后端校验。接入 claude-context 以后,语义搜索能把后端 service、权限函数和测试文件一起找出来,至少让开发者有机会在修改前确认范围是否完整。
确认上下文以后,再进入修改阶段。这个时候给 Agent 的指令可以更明确:
基于刚才确认的文件范围,请完成修改:
1. 后端删除 workspace 前必须校验当前用户角色;
2. 只有 owner 和 admin 可以删除;
3. member 直接请求接口时必须返回权限错误;
4. 前端删除按钮继续保留展示控制,但不能作为唯一校验;
5. 补充 owner/admin/member 三类测试;
6. 不要修改无关模块。这样做的好处,是把"找上下文"和"改代码"分成两个阶段。
第一阶段解决"应该看哪里",第二阶段再解决"应该怎么改"。如果中间发现搜索结果不完整,可以先补搜索,而不是让 Agent 接着在不完整的代码范围里修改。
最后还要加一轮验证:
请运行或说明需要运行的验证:
1. 权限相关单元测试;
2. 删除 workspace 的 API 测试;
3. 前端删除按钮展示逻辑测试;
4. 如果无法运行测试,请说明原因,并列出需要人工验证的路径。到这里,claude-context 就不只是一个额外的搜索工具,而是进入了开发流程的前置环节。它不是替你完成整个需求,而是在最容易出错的第一步,帮 Agent 找到正确的代码区域。
claude-context 通过 MCP 接入 Claude Code,基本配置如下:
claude mcp add claude-context \
-e OPENAI_API_KEY=sk-your-openai-api-key \
-e MILVUS_ADDRESS=your-zilliz-cloud-public-endpoint \
-e MILVUS_TOKEN=your-zilliz-cloud-api-key \
-- npx @zilliz/claude-context-mcp@latestOPENAI_API_KEY 用来调用 embedding 模型。默认示例里使用 OpenAI,如果你用的是 OpenAI embedding,填自己的 OpenAI API Key 就可以。README 里也提到可以使用 VoyageAI、Ollama、Gemini 等 embedding provider,不过这些通常需要换成对应的配置示例和环境变量,不是简单把 OPENAI_API_KEY 换个值就结束。
MILVUS_ADDRESS 是向量数据库地址。如果用 Zilliz Cloud,就填控制台里的 public endpoint;如果是自己部署的 Milvus,就填自己的 Milvus 服务地址。
MILVUS_TOKEN 是访问向量数据库的凭证。用 Zilliz Cloud 时,一般填 API Key 或 token;如果是本地 Milvus,具体要看你有没有开启鉴权。
这里要注意一点:claude-context 当前 README 里写到的向量数据库主要是 Milvus 和 Zilliz Cloud。Zilliz Cloud 可以理解成托管版 Milvus,适合不想自己维护 Milvus 集群的团队;自建 Milvus 更适合希望把数据完全放在自己环境里的团队。至于 Pinecone、Weaviate、Qdrant 等这类常见向量数据库,官方没有提供现成配置,不能直接拿来用。
Node.js 版本也需要注意。官方要求 Node.js >=20.0.0。本地版本太旧的话,要先升级 Node版本,否则 MCP server 可能起不来。
配置完成后,第一件事不是直接搜索,而是先索引代码库。官方 README 给的使用方式很简单:进入项目目录,打开 Claude Code,然后让它执行索引。
索引当前代码库索引完成前,搜索结果可能不完整,所以可以接着查一下状态:
查看索引状态等索引完成后,再开始搜索:
查找处理用户鉴权的代码
查找 workspace 删除权限校验相关代码从 MCP 工具角度看,claude-context 暴露出来的能力主要有四个:
index_codebase:索引代码库
search_code:搜索已索引代码
get_indexing_status:查看索引状态
clear_index:清理索引index_codebase 用在第一次接入项目,或者代码库有较大变化时。它会把代码切块、生成 embedding,并写入向量数据库。
get_indexing_status 用来确认索引是否完成。复杂项目里索引可能需要一些时间,不建议索引还没完成就让 Agent 基于搜索结果做判断。
search_code 是最常用的工具,用自然语言搜索相关代码。比如"查找处理用户鉴权的代码""查找 workspace 删除权限校验""查找已有的权限测试用例"。
clear_index 用来清理某个代码库的索引。比如项目结构大改、索引结果明显不对,或者你想重新索引时,可以先清掉旧索引。
所以不要把 claude-context 理解成"自动开发插件"。它是一个上下文检索层,帮 AI 编程工具回答一个问题:这个任务开始之前,应该先看哪些代码。
接入语义搜索以后,并不意味着 Agent 就一定会按你想要的方式使用它。
claude-context 解决的是"能不能更快找到相关代码",但它不会自动解决另外几个问题:什么时候必须先搜索,搜索到多少才算够,搜索结果怎么汇报,什么时候可以开始改文件。
这些规则需要单独写进工作流里。
如果是 Claude Code,可以把长期规则写进项目级 CLAUDE.md。这个文件会在项目会话开始时被 Claude Code 读取,适合放团队约定、架构说明、常用命令和禁止事项。也可以把更具体的流程做成 slash command 或插件里的 command,比如 /context-check。
如果是 Codex,可以把项目规则写进 AGENTS.md,或者把高频流程沉淀成 skill。前者适合放项目级开发约定,后者适合放可复用任务流程,比如"改动前上下文检查""发布前检查""线上问题排查"。
也就是说,规则不一定每次都要重新写一遍。长期稳定的规则,应该放进项目说明或 skill 里;每次任务特有的信息,比如这次要改 workspace 删除权限、这次只看某个模块,则放在当前提示词里补充。
长期规则可以写成这样:
处理跨文件改动前,必须先搜索相关代码。
搜索结果需要列出文件路径、相关原因和置信度。
没有看过相关测试前,不要直接修改实现。
如果搜索结果不足,必须说明缺少什么,而不是猜测。
修改前先给出计划,修改后必须跑对应验证。单次任务再补充具体范围:
这次只处理 workspace 删除权限。
请重点搜索:
1. 删除 workspace 的 API 或 service;
2. owner/admin/member 角色定义;
3. 权限校验函数;
4. 已有权限测试;
5. 前端删除入口。
在输出上下文报告前,不要修改文件。这和 Harness 思路是相通的:工具越强,越要放进流程里。
如果没有这些规则,搜索结果越多,反而越容易干扰判断。Agent 可能列出很多看似相关的文件,却没有说明它们和当前任务的关系;也可能在索引没有更新的情况下参考旧代码;更麻烦的是,它一边搜索一边修改,最后开发者很难判断这次改动到底基于哪些文件。
所以 claude-context 更适合放在受控流程里使用:先搜索,先说明依据,确认范围以后再修改。它不是一个可以随便发散使用的万能搜索框。
如果要把 claude-context 放进团队工作流,建议先从一个很小的流程开始:改动前上下文检查。
这个流程的目标不是让 Agent 写代码,而是让它在动手前先回答几个问题:
这次改动可能涉及哪些文件?
哪些文件必须先读完?
哪些测试可以证明改动是对的?
哪些模块暂时不要碰?
当前搜索结果有没有明显缺口?
流程可以设计成这样:
根据需求搜索相关代码 -> 列出候选文件和原因 -> 标记必须阅读的测试文件 -> 确认修改范围 -> 再开始改代码如果只是偶尔使用,可以直接在当前对话里写清楚:
在修改代码前,请先使用代码搜索工具完成上下文检查。
请输出:
1. 你搜索了哪些问题;
2. 找到了哪些相关文件;
3. 每个文件为什么相关;
4. 哪些文件必须先读完;
5. 哪些地方暂时不要修改。
在我确认之前,不要修改文件。这段提示词的重点,不是让 Agent "更认真一点",而是明确限制它的动作:当前阶段只允许搜索、阅读、整理报告,不允许修改文件。
如果团队经常遇到这类任务,就不应该每次都手写这段提示词,可以把它固定成一个命令。
/context-check在 Claude Code 里,这类命令可以做成 slash command,放在团队插件或项目命令里。这样团队成员只要输入 /context-check,就会触发同一套上下文检查流程。
在 Codex 里,也可以把它沉淀成 skill,或者写进项目的 AGENTS.md,约定遇到跨文件改动时先执行上下文检查。
不管放在哪个工具里,这个命令背后的规则都应该写清楚:
你是代码修改前的上下文检查助手。
你的任务不是改代码,而是确认这次改动应该阅读哪些文件。
执行要求:
1. 至少提出 3 个搜索问题;
2. 每个搜索问题都要说明目的;
3. 相关文件按"必须阅读 / 建议阅读 / 可能相关"分组;
4. 对每个必须阅读文件,说明它和任务的关系;
5. 标出可能遗漏的上下文;
6. 在用户确认前,不要修改文件。输出也要固定下来,否则每次报告格式都不一样,后面很难审查。可以用下面这个模板:
## 我搜索了什么
- 搜索问题:
- 搜索目的:
## 必须阅读
- 文件:
- 相关原因:
- 需要重点看的位置:
## 建议阅读
- 文件:
- 相关原因:
## 可能遗漏
- 还需要确认的模块:
- 为什么可能相关:
## 下一步建议
- 建议修改范围:
- 暂时不要修改的范围:实际使用时,可以这样做:
/context-check
需求:普通成员不能删除 workspace,只有 owner 和 admin 可以删除。
请先检查相关代码范围,不要修改文件。Agent 交付上下文报告以后,开发者先看报告是否合理。如果漏了后端权限校验,就要求它继续搜索;如果测试文件找错了,就先纠正范围。确认范围以后,再进入实现阶段。
这样能避免 Agent 一边搜索一边修改,最后你很难判断它到底是基于哪些文件做出的决定。比一上来就说"帮我实现这个需求"稳得多。
claude-context 最适合代码量大、跨模块多、历史包袱重的项目:
不熟悉的老项目
多服务或 monorepo
权限、支付、发布、配置这类高风险模块
需要补测试但不知道项目测试风格
新人接手代码库
AI 编程工具经常反复找文件的项目
几十个文件的小工具就不用了,直接用现有搜索和上下文够了,没必要额外引入向量数据库。
它也不能替代代码审查——语义搜索只是帮你更快找到相关代码,改动正不正确,还是要靠后面的计划、修改、测试和人工确认。
AI 编程工具越强,越容易让人忽略一个前提:它必须先看对东西。上下文错了,后面写得再快也可能只是在错误方向上加速。
claude-context 这类项目提醒我们,复杂代码库里的 AI 编程不会只靠更长上下文窗口解决。更现实的做法是把代码库索引起来,让 Agent 在需要时检索相关部分,在明确边界内完成任务。
它回答的不是"AI 能不能写代码",而是一个更工程化的问题:当代码库越来越大时,Agent 怎么知道自己该看哪里?
这个问题解决不好,Agent 越主动风险越大。解决得好,AI 编程工具才有机会从临时帮手,变成真正能进入团队流程的开发协作者。
觉得这篇有收获的话,欢迎点个关注,也顺手来个一键三连:点赞、转发、点亮小心心。
我会持续追踪 AI 领域的热点变化,AI 编程工具的最新进展,以及背后的技术逻辑和实战经验。也欢迎在评论区留言,一起交流你的看法。
公众号 · 智享科技社
