 夜雨聆风
夜雨聆风(基于 OpenClaw、Claude Code、Hermes Agent 的架构横评)
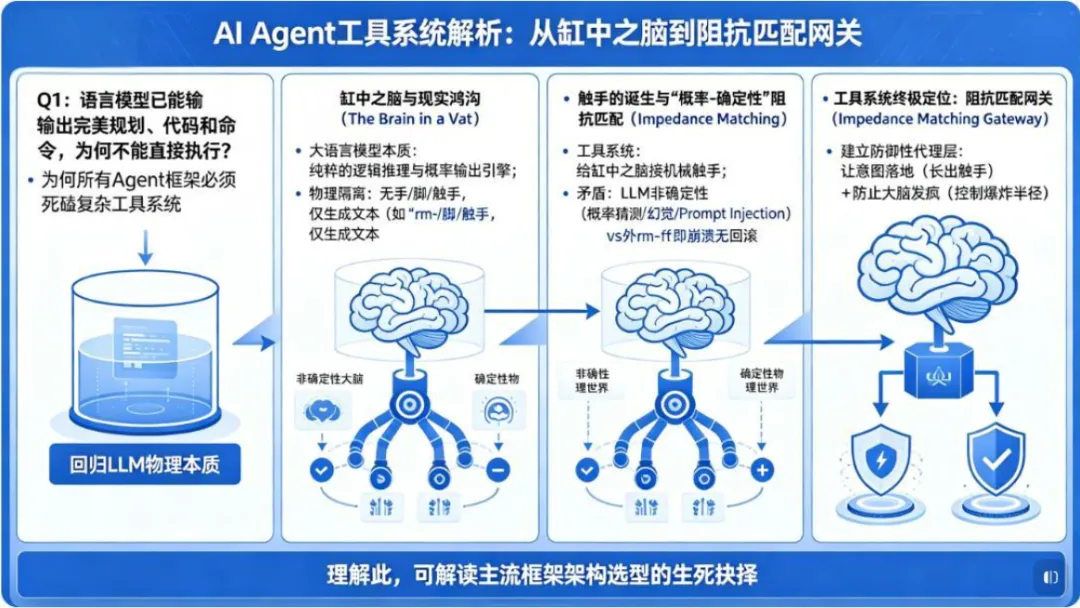
一、 第一性原理:工具系统存在的终极根因是什么?
Q1:语言模型已经能输出非常完美的规划、代码和命令了,为什么不能直接让它去执行?为什么所有 Agent 框架都必须死磕一套复杂的“工具系统”?
要回答这个问题,我们必须回归大语言模型(LLM)的物理本质。
1. 缸中之脑与现实鸿沟(The Brain in a Vat)
大语言模型本质上是一个**“纯粹的逻辑推理与概率输出引擎”**。它在多维的向量空间里“思考”,理解人类的意图,规划任务的步骤,并用最符合概率的 Token 输出结果。
但是,这个大脑是被物理隔离的。它没有手,没有脚,没有“触手”。它想删除一个临时文件,它只能生成一句“rm -rf /tmp/cache”的文本,这句文本在屏幕上闪烁,但文件依然纹丝不动。纯粹的“意图(文本)”无法直接产生“物理/系统的副作用(Side Effects)”。
2. 触手的诞生与“概率-确定性”阻抗匹配(Impedance Matching)
所以,我们需要工具系统。工具系统,就是给这个“缸中之脑”接上的“机械触手”。
但在架构层面,接上触手会产生一个致命的矛盾:
- 大脑(LLM)是“非确定性”的
:它靠概率猜测,它会幻觉,它会被 Prompt Injection 欺骗。 - 外部世界(操作系统/API)是“绝对确定性”的
:执行了 rm -rf,系统就真的崩溃了,没有任何回滚的余地。
结论:
工具系统在架构上的终极定位,不是一个简单的API调用封装,而是一个“阻抗匹配网关(Impedance Matching Gateway)”。它必须在“非确定性的大脑”和“确定性的物理世界”之间,建立一道既能让意图落地(长出触手),又能防止大脑发疯毁灭世界(控制爆炸半径)的防御性代理层。
理解了这一点,我们再来看三个主流框架的架构选型,就能看懂它们在“控制这根触手”上,做出了怎样截然不同的生死抉择。
二、 架构流派拆解:三种截然不同的“触手控制”哲学
任何工具调用的底层架构都逃不开这条神经反射弧:大脑生成意图 (文本) -> 运动皮层解析 (Harness) -> 免疫/安全审查 (PEP) -> 触手执行 (沙盒) -> 痛觉反馈 (Result)
这三个框架的根本差异,在于它们把**“安全审查和限制(护栏)”**建在了神经反射弧的哪一个层级。
流派一:Unix 哲学与级联策略路由(OpenClaw)——“赋予上帝之手,后果自负”
底层逻辑: 相信使用者的判断,默认给大脑安装最锋利的触手。
- 架构选型:全局暴露 + 六层级联策略引擎(Cascading Policy Engine)
OpenClaw 默认提供 exec(执行任意 Shell)等核弹级工具。它把触手的威力开到了最大,但把“要不要给触手带上镣铐”的决定权交给了用户。
它的安全架构类似路由器的防火墙规则,是一个六层级联架构:全局策略 -> 模型供应商策略 -> Agent策略 -> 群组策略 -> 沙箱策略 -> 继承规则
Q2:这种“默认宽松”的架构设计,代价是什么?
- 深度设计透视:Opt-out 安全机制的架构债务
这是一种典型的“Time-to-Value(最快产生价值)”优先的架构。它让开发者能瞬间感受到 Agent 的强大。但架构代价是惨痛的:把复杂的网关鉴权交给了最不了解底层逻辑的用户。
这导致了 OpenClaw 历史上巨大的安全漏洞(十几万个实例裸奔在公网)。它的工具拦截依赖于“事件订阅(Event-driven Hook)”,这种机制在架构上很优雅,但因为是非强制的(Opt-in),违背了“默认安全(Secure by Default)”的系统架构铁律。
流派二:零信任与“盲人反射弧”(Claude Code)——“触手自带神经节”
底层逻辑: 大脑是不可信的(容易被骗),必须在每根触手内部植入独立的“审查神经节”。放弃全局权限,采用零信任(Zero Trust)。
- 架构选型:权限内聚于工具(Micro-contracts)
在 Claude Code 的源码中,没有庞大的全局策略表。 BashTool(执行命令,高风险)和FileReadTool(读文件,低风险)在类的定义层面,就硬编码了完全不同的权限等级(只读、需确认、阻断)。风险画像直接内聚在工具对象本身。
Q3:如果大脑被恶意注入(Prompt Injection),试图用极其合理的逻辑说服系统放行高风险操作,Claude Code 的架构怎么防御?
- 深度设计透视:控制面隔离与“盲人分类器(Blind Classifier)”
这是 Claude Code 最绝妙的架构设计(Auto Mode)。它引入了一个独立的、基于 Sonnet 4.6 的分类器来进行权限审批。
这个审批组件在架构上是**“物理隔离”**的:它只能看到“触手打算干什么(参数)”,绝对看不到大脑的推理过程(模型之前的输出逻辑),也看不到执行结果。
这就好比切断了大脑和安全网关之间的“语言交流”,只看行为动作。大脑再怎么花言巧语伪装,也无法绕过这个“只看参数不听解释”的盲人审查员。这是从架构层面根治 Prompt Injection 的极佳实践。
流派三:计算解耦与感知闭环(Hermes Agent)——“安全下沉物理层,触手即传感器”
底层逻辑: 在应用层(代码里)做安全拦截永远防不胜防,不如把触手关进物理防爆箱;同时,触手不应只是执行器,更应是经验收集器。
- 架构选型一:执行后端解耦(Execution Decoupling)
Hermes 最强悍的架构是不在代码层纠结“正则匹配危险命令”,而是将“工具定义”和“执行后端(Compute Backend)”彻底解耦。
同样的exec触手,可以在 6 种不同的环境中运行:Local / Docker / SSH / Daytona / Serverless GPU。
架构深度:这叫“安全防御下推(Shift-Down)”。把不可控的非确定性大脑输出,直接扔进隔离的容器(Docker/Modal)中执行。哪怕大脑疯了输入rm -rf,炸掉的也只是一个瞬态的沙盒,宿主机安然无恙。用基础设施的物理隔离,降维打击了应用层的逻辑拦截。
Q4:上一篇提到了 Hermes 重视“情景记忆(Skills)”,这和工具系统有什么关系?
- 架构选型二:操作即遥测(Telemetry for the Learning Loop)
在其他框架里,触手伸出去,干完活,流程就结束了。
而在 Hermes 的架构中,工具系统是一个双向网关。它不仅是“效应器(做动作)”,更是“传感器(收集痛觉/经验)”。
当它检测到 Agent 进行了连续 5 次以上的复杂工具调用,工具系统的底座会自动将“用了什么工具、失败了几次、最后怎么绕过的”打包成结构化日志,反向喂给“记忆系统”,形成全新的 SOP(Skill)。
这才是最极致的架构闭环:工具系统为大脑提供了从“试错”向“进化”跃迁的基础设施。
三、 总结:触手控制工程的终极推演
回望工具系统的架构演进,本质上是人类在试图驯服一个“拥有无限逻辑能力但毫无常识的异星大脑”。三个框架给出了三个层次的架构答案:
- OpenClaw 代表“自由与责任”:
适合专家级玩家或绝对信任的内部局域网。它提供了最自由的工具扩展能力(事件 Hook),但也要求人类承担最高级别的安全运维责任。 - Claude Code 代表“零信任微服务化”:
适合边界清晰的工程场景。它通过**“工具内聚权限”+“隔离的盲人审查器”**,在应用代码层做到了极致的安全防御,是一种典型的现代企业级安全架构。 - Hermes 代表“物理隔离与自我进化”:
它指明了未来 Autonomous Agent 的方向。不信任应用层的逻辑防线,把风险下放到容器物理层(Docker/Serverless);同时将工具系统升级为神经网络的“感受器”,让大脑通过每一次触手挥动的成功与失败,实现真正的自我进化。
当我们把工具系统看作“非确定性大脑”连接“确定性世界”的唯一网关时,你就会明白:优秀的工具系统架构,从来不是比谁接的 API 多,而是比谁能在“赋予毁灭性力量”的同时,提供最优雅的安全降级与学习闭环。
