 夜雨聆风
夜雨聆风
AI大模型的底层本源!Transformer:注意力机制重塑AIoT,万物智联的核心底座
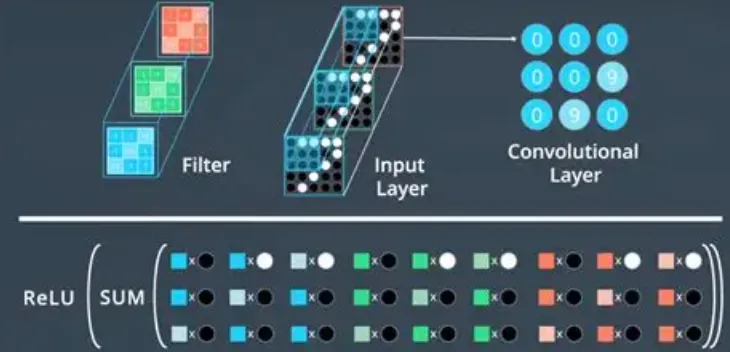
当下爆火的大语言模型、多模态工业大模型、智能AI交互,全部源自同一个底层架构:Transformer。无论是GPT、BERT行业大模型,还是工业视觉、时序预测高端算法,核心都是自注意力机制。它彻底颠覆CNN空间提取、RNN循环记忆的老旧逻辑,凭借全局注意力、并行计算、长序列建模能力,成为2026年AIoT高端智能化的绝对核心。
很多行业从业者只知道Transformer很强,却不懂它为什么能改变物联网产业。不同于传统串行、局部提取的神经网络,Transformer依靠自注意力机制,一次性关联全局数据,远距离特征联动、长时序依赖捕捉、多模态融合能力全面碾压传统模型。如今高端工业质检、超长时序预测、设备智能问答、多传感融合分析,全部基于Transformer架构迭代。
Transformer核心原理通俗解析,最核心创新就是自注意力机制。CNN只看局部像素、RNN按时间串行计算,而Transformer可以同时扫描全部数据,自动计算任意两个数据节点的关联权重。通俗举例:分析设备全年运行数据,它能直接关联冬季低温、高负载、老化磨损等远距离特征,无需逐层传递,精准捕捉隐性耦合关系。
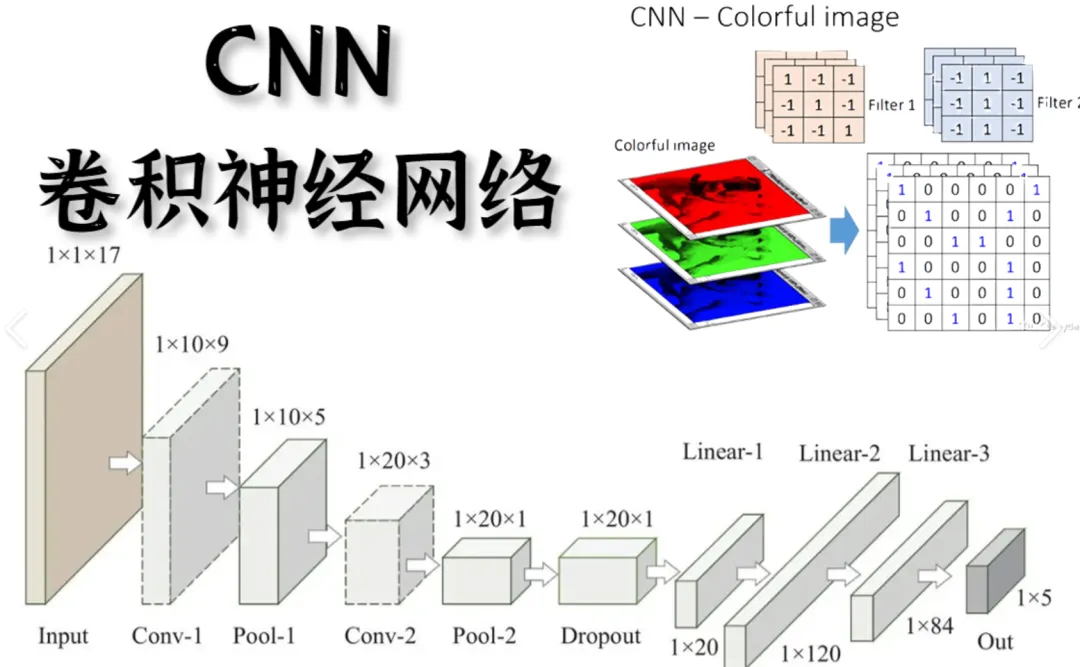
整体架构分为编码器与解码器两大模块,编码器负责特征提取、全局关联分析,适配检测、分类、研判业务;解码器负责生成预测、智能输出,适配趋势推演、文本交互、策略生成业务。同时摒弃循环结构,实现并行计算,训练速度、推理效率远超RNN类时序模型。
对比CNN、RNN,Transformer适配复杂IoT工况有四大颠覆性优势。第一,全局关联建模,远距离特征无损耗联动,适配多维度、长周期工业数据;第二,并行计算提速,摆脱串行依赖,训练推理效率提升数倍;第三,多模态天然适配,图像、文本、传感数值、音频数据可融合分析;第四,可无限堆叠扩容,支撑大模型海量参数迭代升级。
目前AIoT行业四大高端场景全面普及Transformer架构。第一类是超长时序预测,分析设备半年至一年运行数据,预判慢性老化、季节性能耗波动;第二类是多模态故障诊断,融合振动、图像、声音、温度多维数据,精准判定复合型故障;第三类是工业智能交互,设备运维问答、故障溯源文本生成、自动化运维报告撰写。
某大型能源集团落地案例,依托轻量化Transformer搭建电站设备监测模型,汇总变压器、开关柜全年多维传感数据。模型全局关联环境温湿度、负载率、运行时长,精准预判绝缘老化隐患,故障预判提前周期拉长至45天,设备非计划停机损失减少37%,智能化效果远超传统时序算法。
工程部署必须注意适配痛点。第一,原生Transformer算力消耗大,终端禁止部署,优先下沉边缘服务器或云端;第二,工业IoT场景需裁剪简化,减少注意力头数、压缩网络层数;第三,短序列、简单工况不要盲目使用,避免算力浪费;第四,数据量不足千条的项目,不建议训练原生Transformer模型。
Transformer是AIoT产业升级的革命性架构。它打破传统深度学习的算力与逻辑瓶颈,既是所有大模型的底层本源,也是高端工业智能、多模态融合、长时序分析的最优解。2026年IoT智能化比拼,本质就是Transformer架构优化与轻量化落地能力的比拼。

欢迎关注"AIoT智联慧讯"
免责声明 :
本文档可能含有预测信息,包括但不限于有关未来的财务、运营、产品系列、新技术等信息。由于实践中存在很多不确定因素,可能导致实际结果与预测信息有很大的差别。因此,本文档信息仅供参考,不构成任何违约或承诺。可能不经通知修改上述信息,恕不另行通知。
