 夜雨聆风
夜雨聆风最近有个问题我听到过不止一次:
"AI 工具我们接了不少,但感觉越用越乱,到底哪里出了问题?"
问这个问题的人,往往已经认真试过了。
用过 Cursor、接过 Copilot、搭过 Claude 的 API、跑通过几个自动化 workflow。
不是没投入,也不是不认真。
但系统就是没变有序。
我后来想清楚了一件事:这不是工具问题。
AI 不是均衡器,它是放大器。你的系统有边界,它就放大有序;你的系统没边界,它就放大混乱。
第一反应往往是找工具的问题
大多数人的诊断路径是这样的:
是不是工具选错了?换一个试试。
是不是 workflow 没设计好?重新梳理一遍。
是不是模型还不够强?等下一个版本。
这条路走下去,你会发现一件事:工具换了,依然乱。新 workflow 跑了一段时间,又乱了。
因为工具不是问题所在。
真正的原因:AI 放大了你已有的结构
最近看到 Keras 作者 Fchollet 的一个观察:
AI 放大能动性差距——低能动性的使用者越用越失去掌控,高能动性的使用者越用越强。
我觉得这句话换一个角度说,对工程场景更准确:
AI 不是均衡器,它是放大器。你的系统有结构,它就放大结构;你的系统没有边界,它就放大混乱。
这不是能力高低的问题,而是系统本身有没有建立清楚。
AI 工具本质上是一种执行能力。你告诉它做什么,它去做。
问题是:如果你的系统本身就没有边界,AI 只会把这种模糊更快地放大出来。
原来一个人花两小时理不清的事情,现在用 AI 花二十分钟,输出了五倍体量的内容,但还是理不清。
速度变快了,混乱变大了。

边界缺失在工程里的三个症状
我总结了一下,边界模糊通常会以三种方式出现在工程系统里:
第一,输入没有边界。
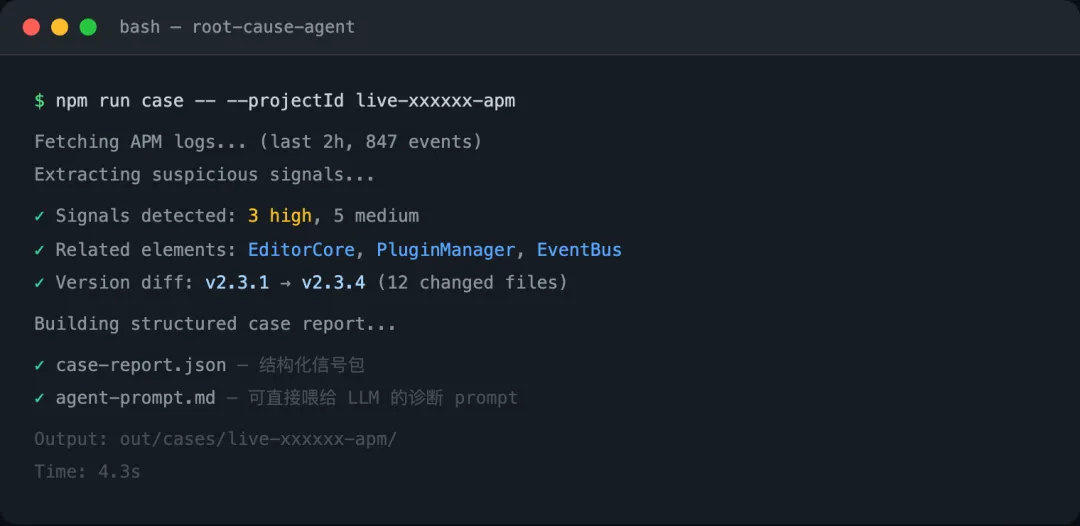
我在搭线上编辑器的根因分析 Agent 时,第一版的方案是:把 project 的全量日志、错误堆栈、代码上下文全部打包进 prompt,让 LLM 来找问题。
LLM 给了很多分析,看起来有模有样。但工程师拿到这份分析之后,面临的问题是:不知道哪几条可信,哪几条是噪音。因为输入是什么、输入的边界在哪里,连我自己都不够清楚。
这就是输入没有边界的典型状态:AI 永远在给你答案,但你永远在怀疑这个答案。
后来我花了更多时间在这一步:先定好信号提取规则,把可疑操作、错误堆栈、版本 diff 结构化处理,再打包成清晰的 case report。输入边界清楚了,LLM 的输出才开始稳定下来。
(这个系统的完整设计和踩坑过程,在上一篇《我做了一个线上 bug 根因分析 Agent,最大的坑不在模型,在这 3 个节点》里有详细拆解。)
我做了一个线上 bug 根因分析 Agent,最大的坑不在模型,在这 3 个节点
第二,执行没有边界。
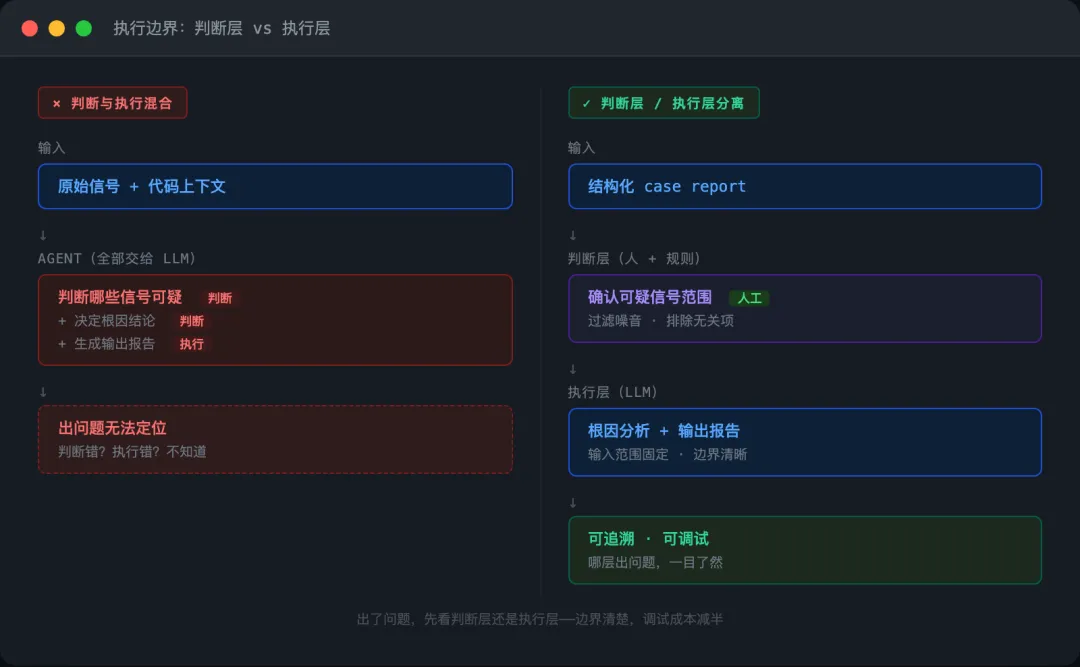
另一个更隐蔽的问题:AI 该做判断的地方在做执行,该做执行的地方在做判断。
同样是这个 Agent,中间有一段时间,我让它既负责判断哪些信号可疑,又负责决定最终输出什么结论。判断层和执行层混在一起,结果是出了问题根本定位不了——是判断错了,还是执行错了?
这两者的边界没分清,调试成本远高于重写一遍。
第三,输出没有边界。
AI 输出的结果没有明确的验收标准。
"大概是这个意思"、"感觉差不多"——这类验收在人工流程里勉强能用,在 AI 自动化流程里会很快把误差放大。没有明确格式、没有拒绝条件,每次输出都要人工重新判断,工具链的可靠性就没有办法建立在这上面。
这三个地方只要有一个没建立清楚,工具链就会持续产出混乱。
建立边界,从"先定哪些不做"开始
很多人的思路是:先接进去,再慢慢收拢。
这个顺序往往行不通。
因为 AI 工具一旦开始产出,你就会面临海量输出,你的注意力和判断力都会开始被消耗,边界就更难建立。
更稳的起点是反过来:
先确定这个 AI 工具不做什么,再决定让它做什么。
具体来说:
• 哪些判断必须由人来做,不能交给 AI? • 哪些输入条件不满足,就直接不触发 AI? • 哪些输出格式不对,直接拒绝不进下一步?
这三个问题想清楚,边界就有了起点。
这不是在限制 AI,而是在给 AI 一个能稳定执行的工位。
只有工位定了,它才能真正有效地干活。
工具链有没有序,前提是系统先有边界
我最后的判断很明确:
工具链混不混乱,和你用了多少工具、工具多不多强,关系不大。
真正决定工具链状态的,是你的工程系统有没有边界。
有边界,AI 工具就是在一个清晰结构里执行,它放大的是你的有序。
没有边界,AI 工具就是在一团模糊里加速,它放大的是你的混乱。
让工程系统具备 AI 能力,这件事本身没问题。
但前提是:这个系统得先具备边界。
下一步,我会继续拆如何在实际工程里一步步建立这三类边界——不是理论,而是从真实项目里提炼出来的具体做法。
如果这篇对你有用,点个 ❤️ 推荐给更多工程人。
关注「架构师的AI实验室」,持续记录 AI 进入工程系统的真实过程。
