 夜雨聆风
夜雨聆风
正在面试?别一个人死磕
如果你正在准备数仓面试,或者已经面了几轮但总拿不到满意的 offer,可能不是你能力不够,而是差一个有经验的人帮你把关。
我们开设了「数仓面试训练营」,由面过 500+ 候选人的资深面试官,带你做系统化的面试准备:
简历重塑 — 挖掘你的项目亮点,用面试官看得懂的语言重新包装
模拟实战 — 1v1 还原真实面试场景,暴露问题比面试现场翻车强
回答技巧 — 教你用 STAR 法则讲故事,把经历变成面试官想听的答案
能力补齐 — 业务思维、建模方法、数据治理、指标体系,哪块弱补哪块
全程跟进 — 从投递到拿 offer,每一轮面试都帮你复盘、调整策略
扫码 / 长按添加微信,备注「面试」即可咨询
(咨询免费,聊完再决定,没有任何套路)
想获取更多数仓面试干货?
加入知识星球「AI·大数据」,一起成长
面试真题拆解 / 简历优化 / 模型设计案例 / 一对一答疑 / 更多折扣价

— END —
AI数据开发学习路线图
2026版 · 从数据管道到智能应用
2026年5月 · 第3期
2026年了,AI早就不是"未来趋势",而是实打实的生产力工具。大模型遍地跑,RAG成了标配,AI Agent开始真正干活——但这一切背后,都离不开一个核心角色:AI数据开发工程师。
说白了,大模型再牛,没有高质量的数据管道,它就是个"没有燃料的火箭"。从数据采集、清洗、特征工程,到向量化、RAG流水线、MLOps部署,整个链路都是AI数据开发的活儿。
这篇文章,我就把2026年AI数据开发的完整学习路线梳理出来,分成6个阶段,每个阶段都有明确的目标、技能清单和实战项目。不管你是刚毕业的学生、想转行的程序员,还是已经在做传统数据开发想升级的老手,都能找到自己的位置。
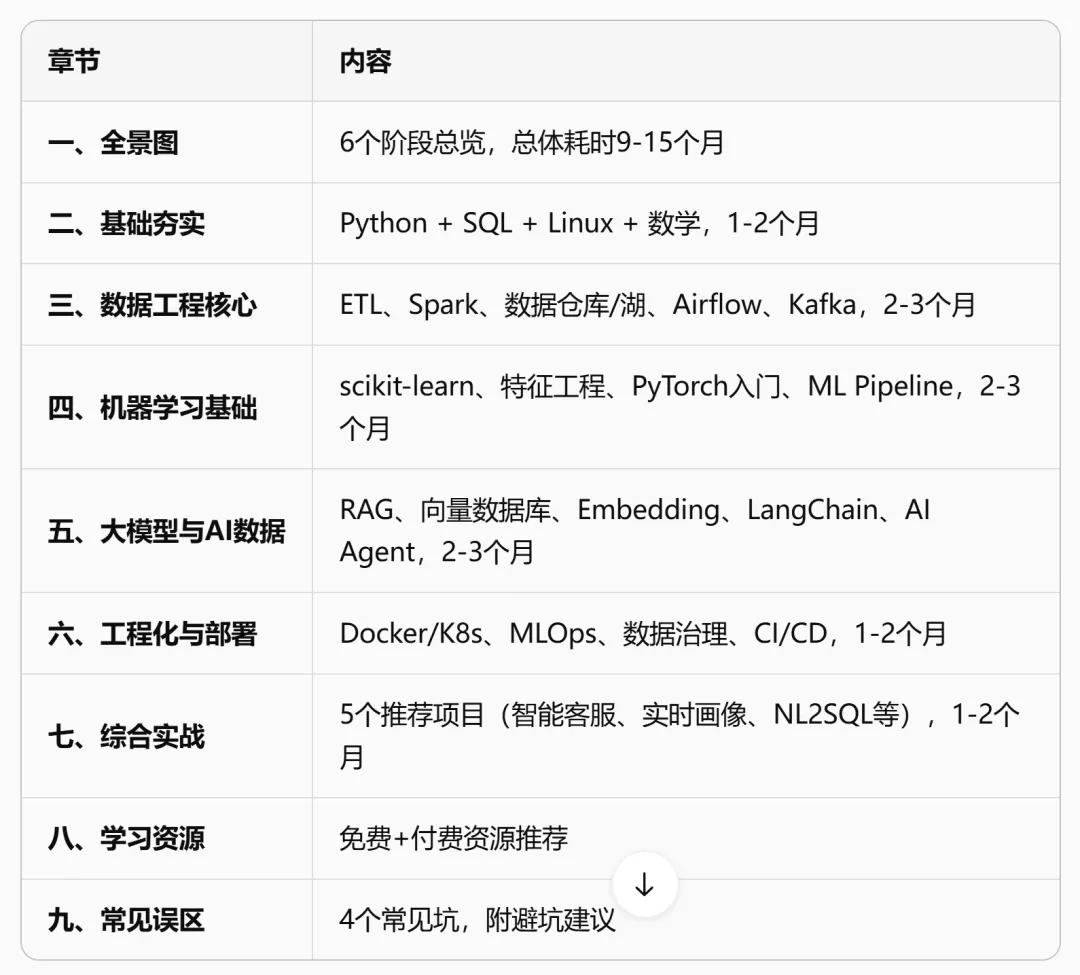
一、先看全景图
在正式开讲之前,先上一张全景图,让你对整个路线有一个整体感知:
阶段 | 核心目标 | 关键技能 | 预计时间 |
阶段一 | 基础夯实 | Python、SQL、Linux、数学基础 | 1-2个月 |
阶段二 | 数据工程核心 | ETL、数据仓库、Spark、数据建模 | 2-3个月 |
阶段三 | 机器学习基础 | ML Pipeline、特征工程、模型评估 | 2-3个月 |
阶段四 | 大模型与AI数据 | RAG、向量数据库、Prompt工程 | 2-3个月 |
阶段五 | 工程化与部署 | MLOps、数据治理、监控告警 | 1-2个月 |
阶段六 | 综合实战 | 完整项目落地 | 1-2个月 |
全部走下来大约9-15个月。不用焦虑,每个人基础不一样,关键是每个阶段都要有产出,边学边做。
二、阶段一:基础夯实(1-2个月)
目标:能独立完成数据获取、清洗和分析的基础工作 |
不管是传统数据开发还是AI数据开发,基础就是三板斧:Python + SQL + Linux。这三样不过关,后面的什么都搞不了。
1. Python —— 核心中的核心
Python是AI生态的通用语言,必须熟练。重点学:
• 基础语法:数据类型、控制流、函数、面向对象。不用花太久,两周足够
• 数据处理三件套:(数据处理)、(数值计算)、(可视化)。这仨是吃饭的家伙
• 进阶必备:(爬数据)、/(配置文件)、(日志)、(类型注解)
小建议:别从"Hello World"死磕语法,直接找一份真实数据集(比如Kaggle上的Titanic或房价预测),用pandas做数据探索,边做边学效率最高。 |
2. SQL —— 数据开发的基本功
很多AI项目的数据最终都存放在数据库或数仓中。SQL你至少要掌握:
• 联表查询(JOIN)、聚合查询(GROUP BY)、窗口函数(ROW_NUMBER、RANK)
• 子查询、CTE(公用表表达式)
• 建表、分区、索引的基本概念
推荐在LeetCode的SQL题库刷50道中难度的题,基本上就够用了。
3. Linux & Git
服务器环境大多是Linux,至少要会:、、、、、这些常用命令。Git的话,把 、、、、、、玩熟就行。
4. 数学基础
不用被"数学很难"吓到。AI数据开发不像算法岗那样需要推导公式,但基础概念得懂:
• 概率统计:均值、方差、分布、假设检验、贝叶斯思想
• 线性代数:向量、矩阵、特征值——至少知道这些是干嘛的
阶段一实战检验 • 写一个Python脚本,从API抓取数据,清洗后存入SQLite数据库 • 用pandas做一份完整的数据探索分析报告(EDA) • 在GitHub上建一个仓库管理你的代码 |
三、阶段二:数据工程核心(2-3个月)
目标:能搭建数据管道,处理大规模数据 |
这个阶段是传统数据开发的核心,也是AI数据开发的基础。没有扎实的数据工程能力,后续的AI相关技能就是空中楼阁。
1. ETL与数据管道
ETL是数据开发的日常。你需要理解:
• 数据抽取:从业务库(MySQL/PostgreSQL)、日志文件、API接口中抽取数据
• 数据清洗:去重、缺失值处理、异常值检测、格式统一
• 数据加载:写入数仓或数据湖,支持增量加载和全量加载
2. 大数据处理框架
2026年,Spark仍然是大数据处理的王者。学Spark重点在:
• RDD、DataFrame、Spark SQL 的API使用
• Spark性能调优(分区、缓存、Shuffle优化)
• PySpark是首选,Java/Scala在数据开发中逐渐边缘化
注意避坑:别一开始就扎进Hadoop全套生态(HDFS、MapReduce、YARN)——对AI数据开发来说,Spark+对象存储(S3/MinIO)的组合远比传统Hadoop生态实用。 |
3. 数据仓库与数据湖
你需要理解两者的区别和适用场景:
• 数据仓库:结构化数据、OLAP分析。主流选型:Doris/StarRocks、ClickHouse
• 数据湖:存储原始数据(结构化+非结构化)。主流选型:Apache Iceberg、Delta Lake、Apache Hudi
• 湖仓一体:2026年的大趋势,Iceberg + Spark + Trino 是热门组合
4. 工作流调度
数据管道不可能手动跑,必须调度起来:
• Apache Airflow:业界标准,必须会。重点学DAG的定义、Task依赖、定时调度、传感器
• DolphinScheduler:国产替代,国内很多公司在用
5. 消息队列(可选但推荐)
实时数据处理越来越重要,Kafka是绕不开的。至少掌握:主题、分区、消费者组、消息生产与消费的基本概念。
阶段二实战检验 • 用Airflow搭建一个每日自动运行的ETL管道,从API拉取数据写入Doris • 用Spark消费Kafka中的实时数据流,做简单的聚合计算 • 在GitHub上展示你的数据管道架构图 |
四、阶段三:机器学习基础(2-3个月)
目标:理解ML全流程,能独立完成特征工程和模型训练 |
注意,AI数据开发不是算法岗,你的重点不是"发明新模型",而是为模型准备数据、搭建训练管道、部署和监控模型。但如果你连模型训练的基本流程都不懂,后面的AI数据工作很难做好。
1. 经典机器学习
先从scikit-learn入手,它封装了最全的ML算法,API设计也非常规范:
• 监督学习:线性回归、决策树、随机森林、XGBoost/LightGBM
• 分类与回归:逻辑回归、SVM、KNN
• 无监督学习:K-Means聚类、DBSCAN、PCA降维
2. 特征工程 —— AI数据开发的核心技能
这也是数据开发和AI结合最紧密的部分。很多人觉得特征工程"没啥技术含量",实际上它直接决定了模型的天花板:
• 数值特征:归一化、标准化、分箱、对数变换
• 类别特征:独热编码、标签编码、目标编码
• 时间特征:周期性编码(年/月/日/星期)、时间窗口聚合
• 文本特征:TF-IDF、词向量、文本长度等统计量
3. 深度学习入门
2026年,完全不懂深度学习已经说不过去了。AI数据开发至少需要:
• PyTorch基础:Tensor操作、自动求导、构建简单的全连接网络
• Transformer基础:理解Attention机制、BERT/GPT的基本架构
• 会用Hugging Face加载预训练模型进行微调
4. ML Pipeline搭建
这是从"手工作坊"到"工业化"的关键一步:
• 用scikit-learn的Pipeline类串联预处理+训练+预测
• 理解训练集/验证集/测试集的划分逻辑
• 掌握交叉验证、超参数搜索(GridSearch/RandomSearch)
阶段三实战检验 • 用Kaggle上的一个表格数据集(如House Prices),从特征工程到模型训练跑完完整Pipeline • 在MLflow上记录实验参数和指标 • 用Hugging Face加载一个BERT模型,在自定义数据集上做文本分类微调 |
五、阶段四:大模型与AI数据开发(2-3个月)
目标:掌握大模型时代的数据处理技术栈 |
这个阶段是2026年AI数据开发与传统数据开发的分水岭。大模型时代,数据开发的工作内容发生了质的变化。
1. RAG(检索增强生成)
RAG是2025-2026年最火的AI应用架构,也是AI数据开发最直接的落地场景:
• 核心流程:文档切分→ Embedding → 向量存储 → 检索 → 大模型生成
• 文档切分:语义切分、固定大小切分、递归切分——不同的切分策略直接影响检索效果
• 检索策略:向量检索(语义相似)、关键词检索(BM25)、混合检索(Hybrid Search)
• 重排序:Reranker模型对检索结果做二次排序,大幅提升质量
2. 向量数据库
2026年向量数据库已经是AI数据开发的标配工具:
• Milvus:最成熟的分布式向量数据库,适合生产环境
• Qdrant:Rust实现,性能极佳,部署简单
• Chroma:轻量级,适合学习和原型开发
• pgvector:PostgreSQL的向量扩展,如果你已经在用PG,这是最省事的方案
3. Embedding模型与数据向量化
数据的向量化质量,决定了RAG系统的上限:
• 了解文本Embedding模型(如BGE、M3E、text-embedding-3-small)
• 了解多模态Embedding(图片、音频的向量化)
• 掌握向量索引算法(IVF、HNSW)的基本原理和参数调优
4. LLM应用框架
• LangChain:最流行的LLM应用开发框架,学习Chain、Agent、Tool、Memory等核心概念
• LlamaIndex:更专注于数据索引和RAG场景,数据工程师会很喜欢它的设计
• Dify:低代码的AI应用开发平台,适合快速验证想法
5. AI Agent与工具调用
2026年Agent已经从概念走向落地。数据开发方向你需要:
• 理解Agent的ReAct模式(思考-行动-观察)
• 掌握Function Calling / Tool Use的实现方式
• 了解Multi-Agent协作(如AutoGen、CrewAI)
• AI数据Agent:让大模型直接查询数据库、执行代码、调度管道
阶段四实战检验 • 搭建一个完整的RAG系统:文档解析 → 切分 → Embedding → 检索 → 问答 • 用LangChain + Milvus做一个知识库问答机器人 • 让AI Agent能够通过自然语言查询你的数据仓库 |
六、阶段五:工程化与部署(1-2个月)
目标:让AI数据系统稳定运行在生产环境 |
模型在笔记本上跑通只是第一步,让它7x24小时稳定服务才是真本事。
1. 容器化与编排
• Docker:必须熟练,写Dockerfile、做镜像、映射端口、挂载卷
• Kubernetes(K8s):Pod、Deployment、Service、ConfigMap,至少会用K8s部署一个AI服务
2. MLOps
MLOps是"AI数据开发的终极形态",核心关注:
• 模型版本管理:DVC(数据版本控制)、MLflow Model Registry
• 特征存储(Feature Store):Feast、Tecton——让特征可以在线/离线复用
• 模型监控:数据漂移(Data Drift)、概念漂移(Concept Drift)检测
• A/B测试:模型上线前的灰度发布能力
3. 数据质量与治理
AI时代,垃圾数据产生的AI也是垃圾。2026年数据治理已经和AI深度绑定:
• 数据质量检查:完整性、一致性、准确性、及时性
• 数据血缘追踪:OpenLineage、Atlas
• 数据安全与隐私:数据脱敏、差分隐私、RBAC权限控制
4. CI/CD for Data
数据管道也要走CI/CD:
• 代码变更触发数据管道测试
• 数据质量测试作为Pipeline的一环
• GitOps管理数据管道的配置
阶段五实战检验 • 把你的RAG系统容器化,用Docker Compose部署 • 搭建一个MLflow服务器,管理实验和模型 • 实现数据质量监控,漂移时自动告警 |
七、阶段六:综合实战(1-2个月)
目标:独立交付一个完整的AI数据项目 |
最后这个阶段不要学新知识了,核心任务就是:把前面学的东西串起来,做一个完整的项目。
推荐实战项目
项目 | 技术栈 | 难度 |
智能客服知识库系统 | LangChain + Milvus + LLM API + FastAPI | ⭐⭐⭐ |
实时用户画像系统 | Kafka + Spark Streaming + ClickHouse + Embedding | ⭐⭐⭐⭐ |
自动数据报表Agent | LLM + NL2SQL + Airflow + 可视化 | ⭐⭐⭐ |
多模态数据搜索平台 | 多模态Embedding + Qdrant + Reranker + LLM | ⭐⭐⭐⭐ |
端到端ML Pipeline平台 | Spark + MLflow + Feast + K8s + 监控 | ⭐⭐⭐⭐⭐ |
做项目时记住三个原则:
• 先跑通,再优化——不要一开始就追求完美架构
• 写文档——架构图、接口文档、部署文档,面试和工作中都用得上
• 开源出去——GitHub上好好维护,这是最好的简历
八、学习资源推荐
免费资源 • Kaggle:学数据处理的实战天堂,从入门赛到顶级赛事都有 • Hugging Face 课程:免费的NLP/Transformer学习资源 • D2L(动手学深度学习):李沐老师的书,中文友好,代码完整 • LangChain 官方教程:最新最全的LLM应用开发指南 • GitHub上的awesome-llm-data仓库:专门收集LLM数据处理的资源 |
付费资源(选学) • DeepLearning.AI 的 Short Courses:Andrew Ng团队出品,每个课程2小时内,干货满满 • DataCamp 的数据工程Track:交互式学习,适合动手型学习者 • 知识星球「华哥聊数据」:持续更新的AI数据开发实战经验,欢迎加入 |
九、几个常见的坑
误区一:什么都想学,结果什么都没学深。AI数据开发涉及的技术栈确实广,但建议每个阶段只专注一个核心技能,学透了再拓展。 |
误区二:只学理论不做项目。看十遍教程不如自己动手写一遍。每学一个工具,马上找个实际场景用起来。 |
误区三:忽略数据质量。很多人眼里只有模型,觉得"模型好就一切都好"。实际上,数据质量才是AI项目的瓶颈。一个脏数据能让最好的模型崩盘。 |
误区四:追最新技术,忽视基本功。2026年新技术层出不穷,但Python、SQL、数据建模这些基本功永远不会过时。地基不牢,楼盖得再高也是危楼。 |
十、写在最后
AI数据开发这个方向,说到底是"数据"和"AI"的交叉地带。你不需要像算法工程师那样精通模型原理,也不需要像后端工程师那样把系统架构做到极致——但你得两头都懂一点,而且能把它们打通。
这种"T型人才"在2026年的市场上非常稀缺,也很有议价能力。
路线图画好了,剩下的就是一步步走。不用急于求成,保持每周都有产出,10个月后回头看,你会发现自己已经走了很远。
