 夜雨聆风
夜雨聆风点击上方 程序员成长指北,关注公众号
回复1,加入高级AI交流群
unsetunset引言:手写 Skill 的困境unsetunset
如果你正在使用 Claude Code、Cursor 等 AI Coding 工具进行日常开发,大概率遇到过这样的场景:
每次写完代码都需要按固定流程做 Code Review——检查安全漏洞、检查性能问题、检查命名规范。你像个复读机一样,一遍遍把同样的话术输入给 AI:"帮我检查这段代码,注意这几点……"
于是你想:能不能把这套流程打包成一个可复用的工作流?
这就是 Skill 的由来——把重复的工作流打包成可复用的指令集。
但当你真正动手写 Skill 时,问题来了:
写完不确定是否有效:SKILL.md 写好了,但跑起来效果总是差点意思,不知道是 prompt 写得不对还是结构有问题 修改后不知道变好还是变差:改了几版,感觉越改越乱,缺少客观的评判标准 模型更新后 Skill 突然失效:上个月还好好的,这个月就不灵了 触发时机不对:该触发的时候不触发,不该触发的时候乱触发
这些问题的根源是同一个:Skill 开发缺乏测试和验证机制。
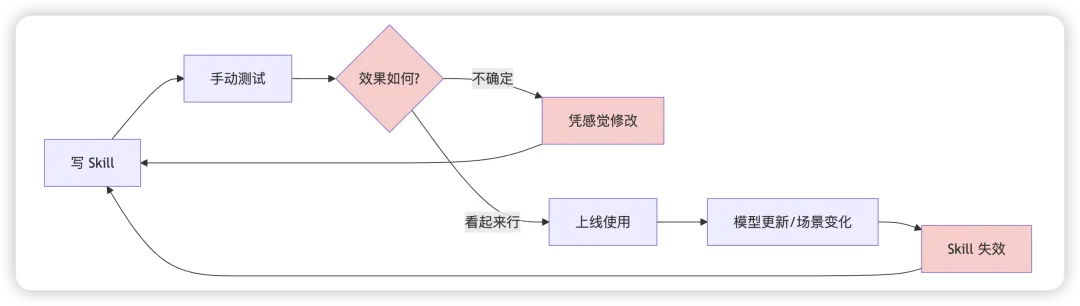
传统软件开发有单元测试、集成测试、CI/CD 流水线来保证质量,而 Skill 开发却停留在"写完跑一下,感觉差不多就行"的草台班子阶段。
有没有一种方法,能把软件工程的严谨性引入 Skill 开发?
有。它叫 skill-creator。
unsetunsetskill-creator 是什么unsetunset
一句话定义:skill-creator 是一个做 Skill 的 Skill。
听起来有点绕口,但它的定位非常清晰:你告诉它你想要什么能力,它就引导你一步步把这个能力输出成一个结构完整、能真正触发、经过测试验证、可持续迭代的 Skill。
可以把它理解为 Claude 生态中的技能工厂。
2026 年 3 月,Anthropic 对 skill-creator 进行了重大更新,引入了评估(Evals)、基准测试(Benchmark)、多智能体并行、A/B 测试、触发器优化等核心功能。这次更新的本质,是把 Skill 开发从"艺术"变成了"工程"——从"看起来有用"变成"验证有效"。
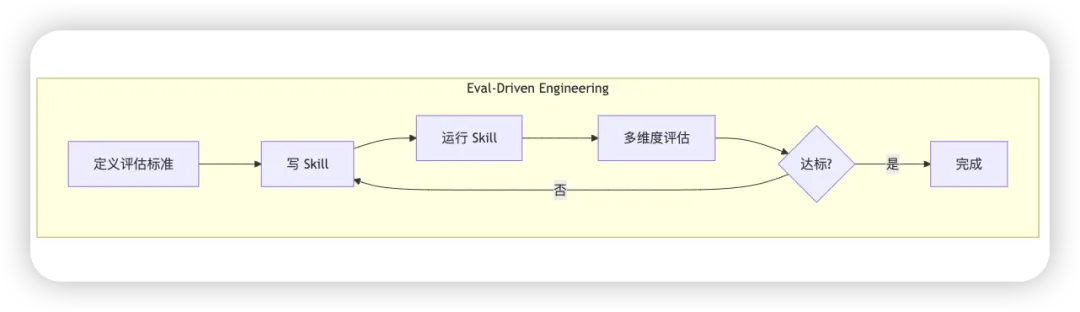
新版 skill-creator 的核心工作流是:

这不再是一个简单的模板生成器,而是一套完整的评估驱动开发(Eval-Driven Engineering)工作流。
unsetunset设计哲学与核心原理unsetunset
这是本文的重点部分。理解 skill-creator 的设计哲学,比会用它更重要——因为这些理念可以迁移到你的其他 AI 工程实践中。
评估驱动开发(Eval-Driven Engineering)
如果你熟悉测试驱动开发(TDD),skill-creator 的理念会让你觉得似曾相识:
TDD:先写测试,再写代码,测试通过即完成 Eval-Driven:先定义评估标准,再写 Skill,评估通过即完成
核心循环是:
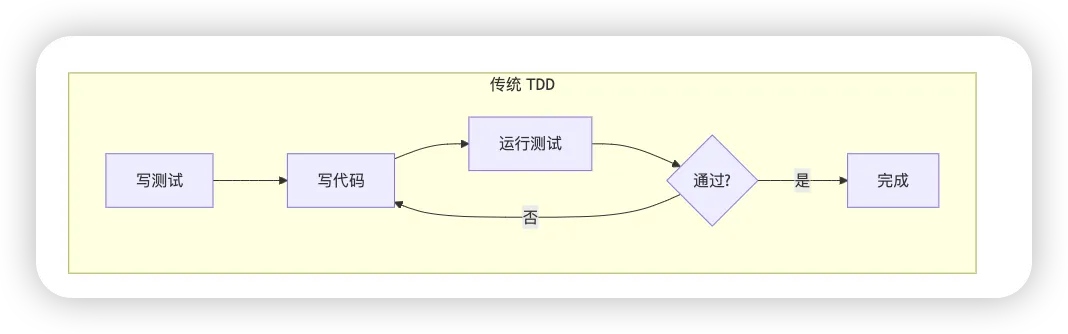
但 AI Skill 的评估比传统代码测试复杂得多。代码测试通常是确定性的:输入 A 必须输出 B。而 Skill 的输出往往是非确定性的,需要从多个维度评估:
正确性:输出是否符合预期? 完整性:是否遗漏了关键信息? 格式:输出结构是否符合要求? 效率:消耗了多少 Token?花了多少时间?
skill-creator 还区分了两类 Skill,它们的测试重点完全不同:
能力提升型(Capability Uplift):帮助 Claude 完成基础模型做不到或表现不稳定的工作。比如特定格式的文档生成、复杂的代码模式等。这类 Skill 需要关注一个特殊问题:随着模型迭代,某些能力可能被模型本身吸收,Skill 就不再必要了。Evals 能告诉你这个转折点什么时候到来。
偏好编码型(Encoded Preference):Claude 本身就能完成各个环节,但 Skill 按照你团队的特定流程来编排。比如按照公司规范审核合同、按照团队模板生成周报。这类 Skill 的生命周期更长,测试重点是验证对实际工作流的忠实度。
多智能体隔离架构
这是 skill-creator 最精妙的设计之一。
传统做法是:用同一个 AI 写 Skill、运行 Skill、评估 Skill。问题是什么?上下文污染。AI 既知道 Skill 的意图,又知道之前运行的结果,很难做出客观评判。就像让出题人自己判卷,难免有偏见。
skill-creator 的解决方案是物理隔离:用不同的 Subagent 分工协作,每个 Subagent 只知道自己需要知道的信息。
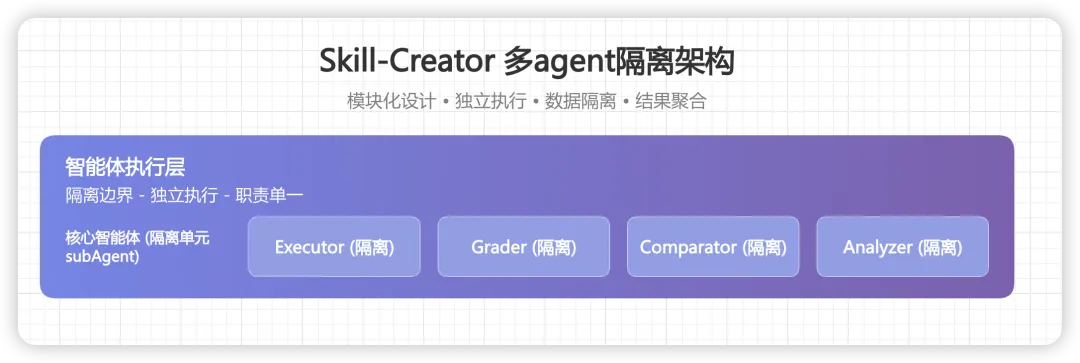
四个核心角色:
Executor(执行者)
职责:在隔离环境中执行任务 输入:Skill + 测试 Prompt 输出:执行记录(transcript)+ 输出文件 特点:完全不知道评估标准是什么,只管执行
Grader(评分者)
职责:依据预设断言评估执行结果 输入:执行记录 + 断言清单 输出:grading.json(每个断言的 PASS/FAIL + 证据) 特点:不知道 Skill 的具体实现,只看结果
Comparator(比较者)
职责:双盲对比两个输出版本 输入:输出 A + 输出 B(不知道哪个是新版本) 输出:谁更好 + 原因 特点:双盲设计,消除偏见
Analyzer(分析者)
职责:分析胜负原因,输出改进建议 输入:比较结果 + 两个 Skill 定义 + 执行记录 输出:归因分析 + 优先级排序的改进建议 特点:复盘专家,负责找出根本原因
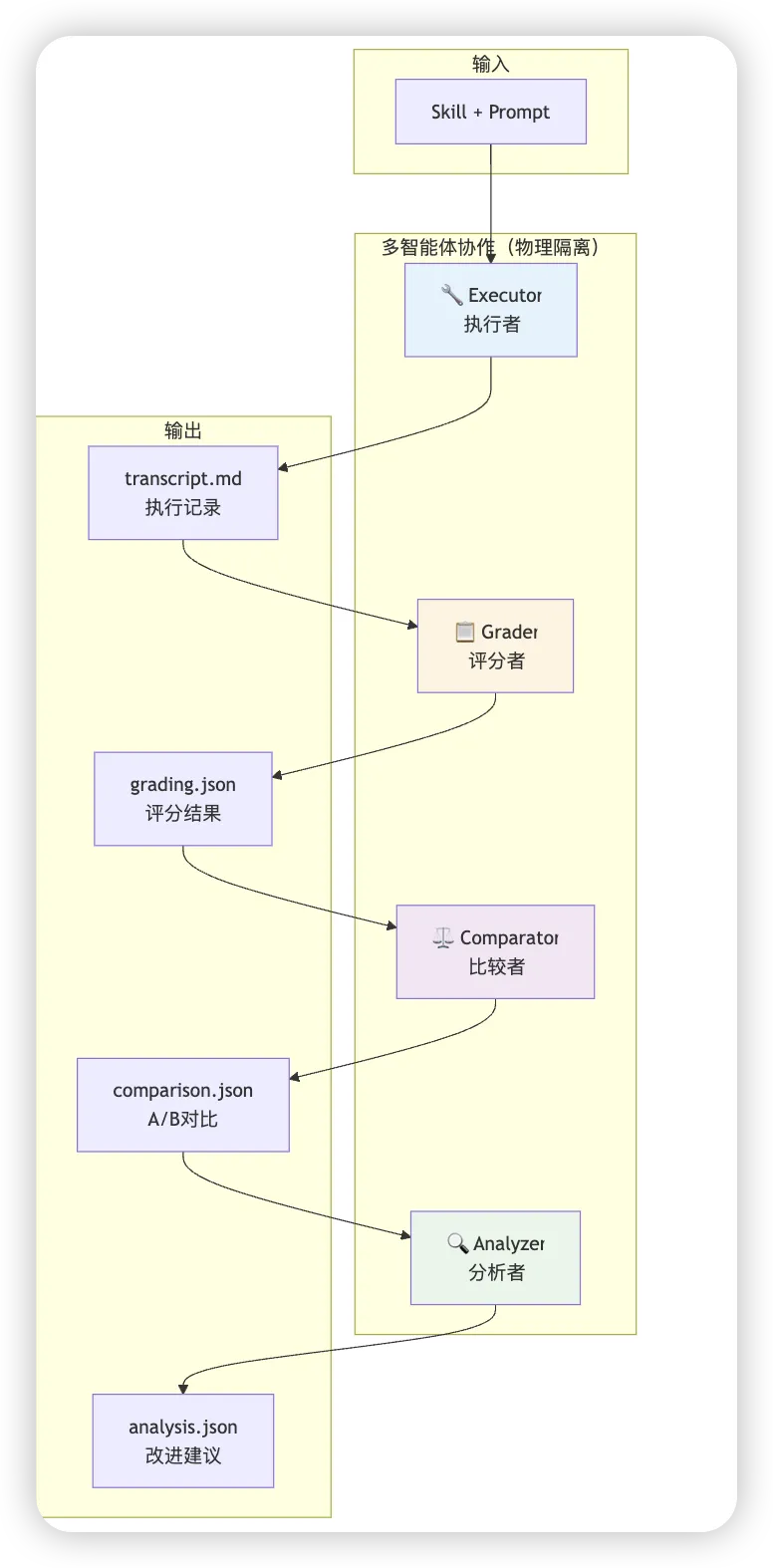
这种架构的好处是:每个角色的上下文都是干净的,不会被其他信息污染,评估结果更客观。
不只是 LLM-as-a-Judge
市面上很多工具用 LLM 来评估 LLM 的输出,但大多只是简单地问:"这个输出好不好?"
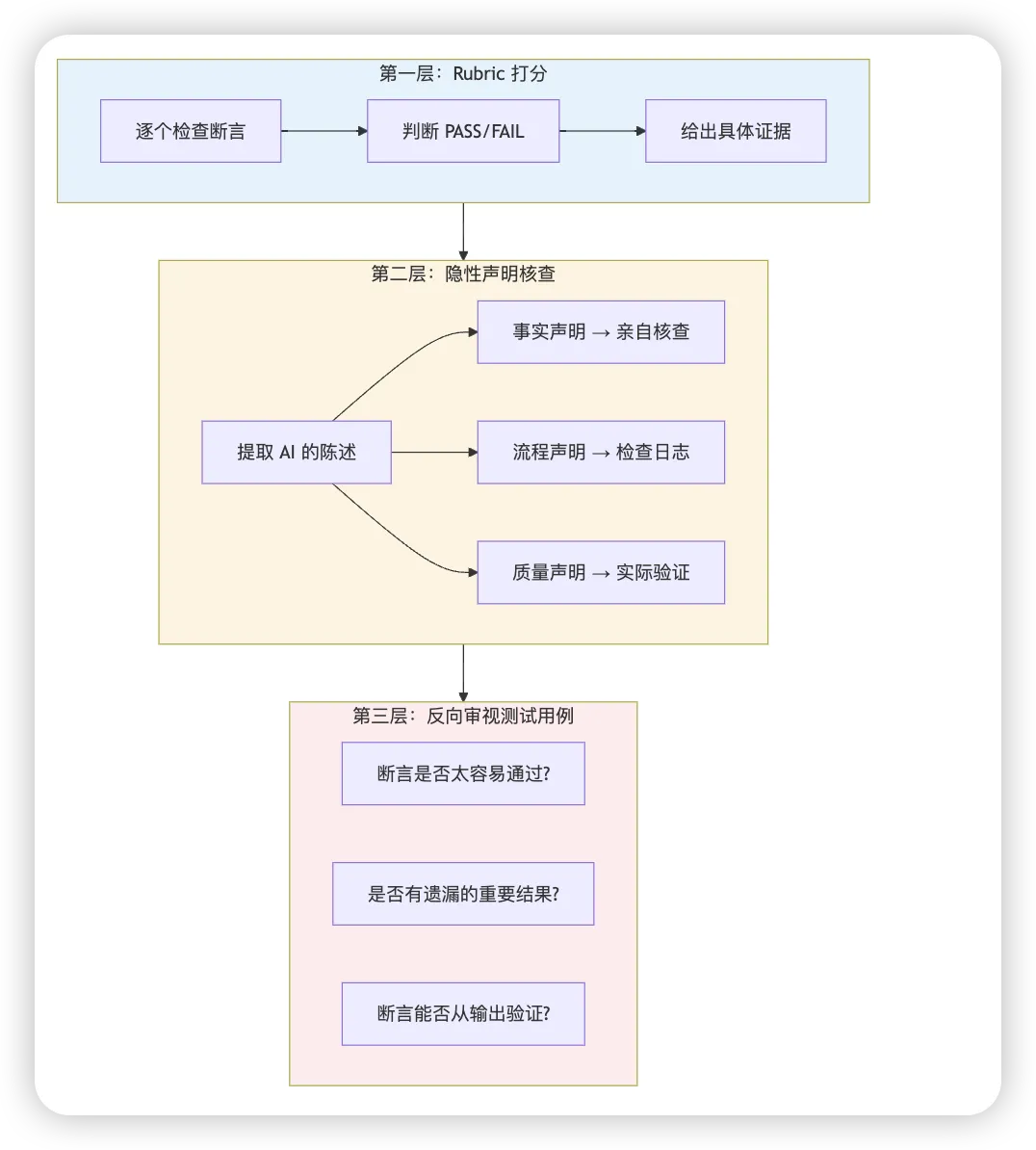
skill-creator 的 Grader 设计要精细得多,它执行三层评估:
第一层:核对 Rubric 打分
这是基础。Grader 会逐个检查预设的断言(assertions),判断 PASS 或 FAIL,并给出具体证据。
判断标准很严格:
PASS:执行记录或输出明确证明断言为真,能引用具体证据 FAIL:找不到证据、证据矛盾、或只是表面合规但实质不对
"表面合规但实质不对"是关键。比如断言是"生成的文件存在且可读",如果只检查文件是否存在就判 PASS,那太草率了。Grader 会进一步检查文件内容是否正确。
第二层:提取隐性声明做事实核查
这是防幻觉的关键。
AI 在执行任务时会产生很多"顺口吐露的陈述",比如:
"这个表单包含 12 个字段"(事实声明) "我使用了 pypdf 库来处理"(流程声明) "所有必填字段都已正确填写"(质量声明)
这些陈述不在预设的断言里,传统测试会直接跳过。但 Grader 会逐个核查:
事实声明:亲自去数字段数量 流程声明:检查日志或代码,确认是否真的调用了 质量声明:实际检查是否属实
这能有效防止 AI "假装完成了任务"。
第三层:反向审视测试用例本身
Grader 不仅评判执行结果,还会反向审视测试用例的质量:
这个断言是不是太容易通过了?(比如只检查文件名不检查内容) 有没有重要的结果没有被任何断言覆盖? 这个断言能不能真的从输出中验证?
这能防止"Anti-Shortcut"——Agent 只追求表面合规而不是真正完成任务。
渐进式披露的上下文管理
Skill 可以包含大量内容:指令、参考文档、示例代码、辅助脚本。如果一次性全部塞进上下文,会浪费大量 Token,还可能干扰 AI 的判断。
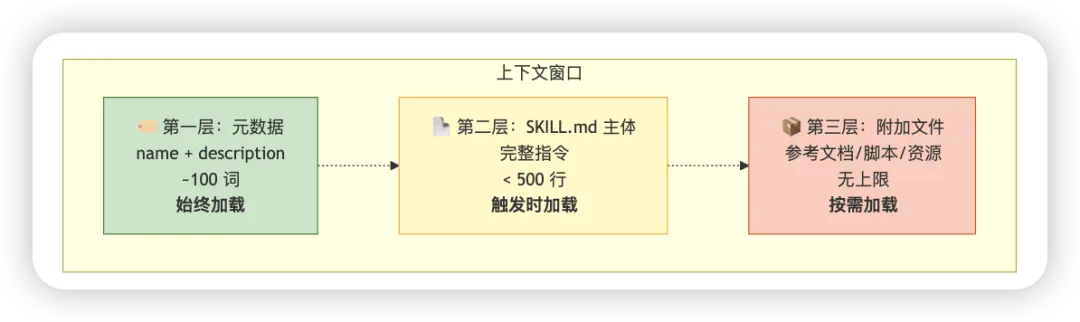
skill-creator 采用三层加载机制:
第一层:元数据
内容:name + description(约 100 词) 加载时机:启动时预加载所有已安装 Skill 的元数据 作用:让 Claude 知道有哪些 Skill 可用,决定是否触发
第二层:SKILL.md 主体
内容:完整的 Skill 指令(建议 < 500 行) 加载时机:当 Skill 与当前任务相关时 作用:提供详细的执行指导
第三层:附加文件
内容:参考文档、脚本、资源等(无上限) 加载时机:按需加载 作用:提供特定场景需要的额外信息
举个例子,PDF Skill 的文件结构可能是:
pdf-skill/├── SKILL.md # 核心定义├── reference.md # 参考资料└── forms.md # 表单填写指南Claude 只有在需要填写表单时才会读取 forms.md,其他时候不加载,节省 Token。
这种设计的哲学是:拥有文件系统和代码执行能力的 Agent,不需要把整个 Skill 读入上下文。Skill 能捆绑的内容量实际上是无限的。
unsetunset五大核心功能解析unsetunset
基于上述设计哲学,skill-creator 提供了 5 个核心功能。
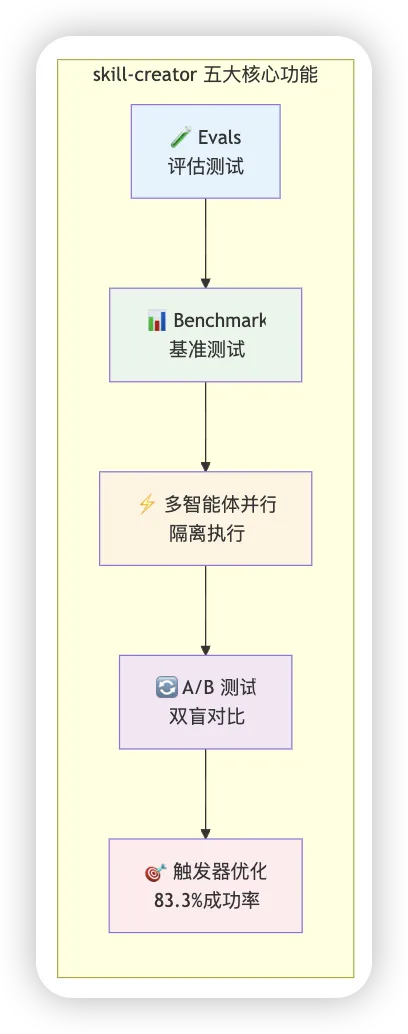
1. Evals(评估)
Evals 是检验 Skill 是否符合预期的测试框架。使用流程:
定义测试 Prompt(+ 所需文件) 描述"好的结果"是什么样(断言列表) 运行测试,skill-creator 告诉你 Skill 是否达标
Evals 有两大用途:
捕捉质量衰退:模型和基础设施演进时,上个月工作的 Skill 今天可能异常。定期运行测试,能在影响实际工作前提供预警。
了解模型进展:如果基础模型在不加载 Skill 的情况下也能通过测试,说明 Skill 的技术方法已被模型吸收——Skill 没坏,只是不再需要了。
2. Benchmark Mode(基准测试)
基准测试模式使用 Evals 运行标准化评估,追踪三个关键指标:
Eval 通过率:Skill 是否达到预期 耗时:执行效率 Token 用量:成本控制
同时还会计算统计聚合数据:平均值、标准差、最小值、最大值。以及两个版本的 Delta(差异):
{"delta": {"pass_rate": "+0.50", // 通过率提升 50%"time_seconds": "+13.0", // 时间增加 13 秒"tokens": "+1700"// Token 增加 1700 }}这让你能客观判断修改是改善还是恶化,而不是凭感觉。
3. 多智能体并行
传统做法是顺序运行测试用例,问题是:
慢 上下文会累积,导致后面的测试受前面的影响
skill-creator 的解决方案:启动独立的 Subagent 并行运行 Evals,每个 Subagent 在干净上下文中工作,有独立的 Token 和时间统计。
结果更快、更干净、无交叉污染。
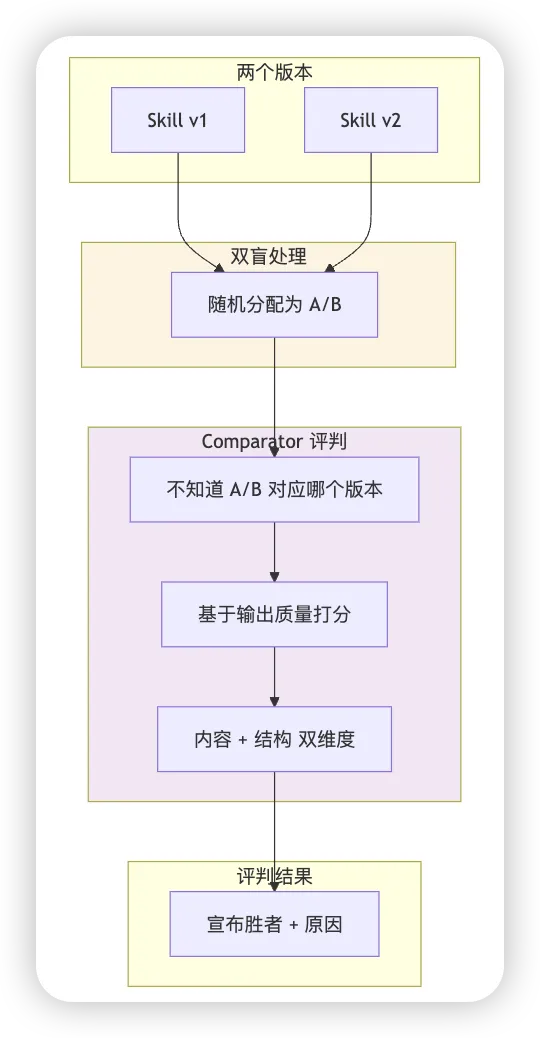
4. A/B 测试(对比智能体)
当你想比较两个 Skill 版本时,skill-creator 提供双盲 A/B 测试:
对比场景:两个 Skill 版本对比、Skill vs 无 Skill 对比 盲测机制:Comparator 不知道 A 和 B 分别是哪个版本 评估维度:内容(正确性、完整性、准确性)+ 结构(组织、格式、易用性)
评分采用 1-5 分制,最终汇总成 1-10 分的总分。只有真正水平相等才宣布平局,否则必须分出胜负。
这确保了评判完全基于输出质量本身,而不是对某个版本的先入为主。
5. 触发器优化
Evals 测量输出质量,但前提是 Skill 要在正确时机触发。
随着 Skill 数量增长,触发描述的精准度变得关键:
太宽泛 → 误触发(不该触发时触发) 太狭窄 → 漏触发(该触发时不触发)
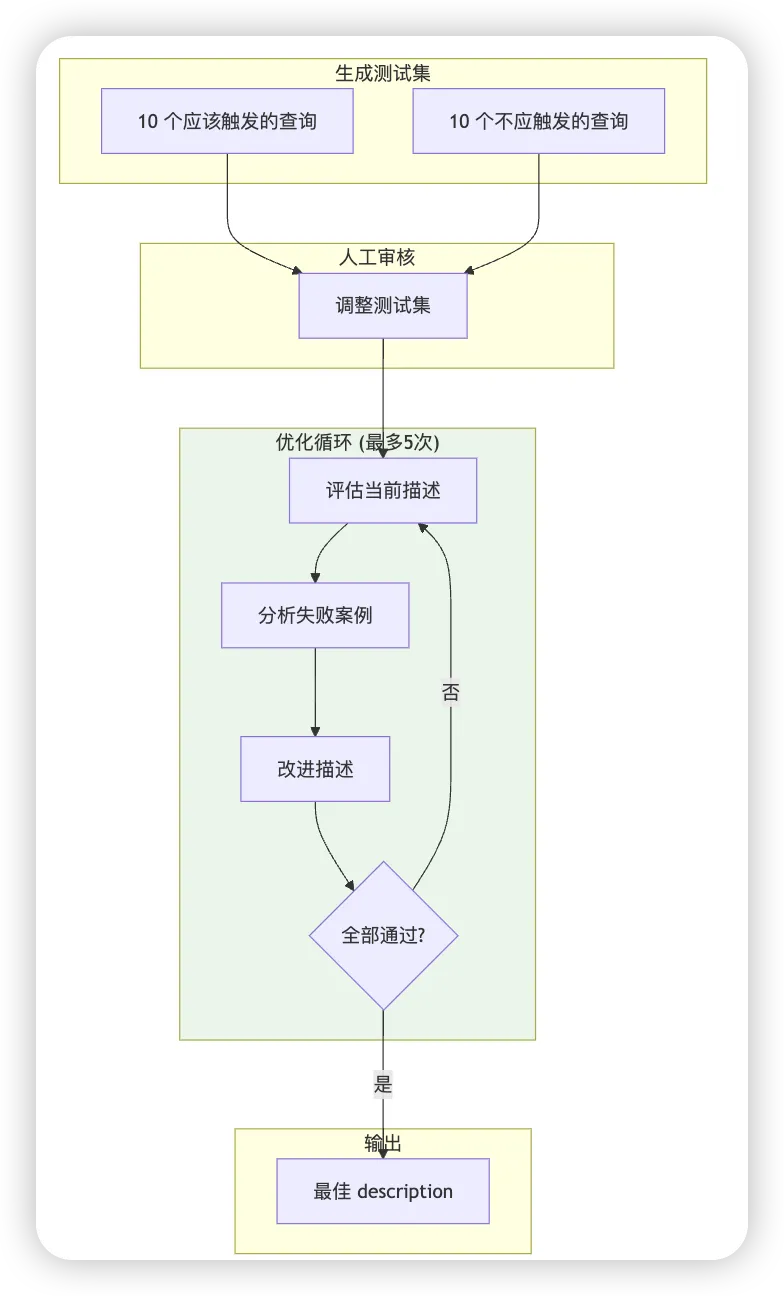
skill-creator 提供自动化的触发器优化:
生成 20 个测试查询(10 个应该触发 + 10 个不应该触发) 人工审核和调整测试集 运行优化循环:评估 → 分析失败案例 → 改进描述 → 重新评估 最多迭代 5 次,输出最佳描述
为防止过拟合,测试集会划分为 60% 训练集和 40% 测试集,最终根据测试集得分选择最佳描述。
实测效果:在 6 个公开 Skill 上测试,5 个 Skill 的触发得到改善,成功率 **83.3%**。
这个数字说明:精准的触发描述是可以系统性优化的,而不是靠"感觉"调参。
unsetunset安装与使用流程unsetunset
理论讲完,来看实操。
安装
在终端输入:
npx skills add anthropics/skills --skill skill-creator选择你使用的 AI Coding 工具(以 Claude Code 为例),空格选中后回车。
然后选择安装级别:
项目级安装:只在当前项目可用 全局安装:所有项目都可用
建议全局安装,因为 skill-creator 是通用工具。
安装完成后,在 Claude Code 中输入 /skill-creator 即可看到。
基本使用
使用方式非常直接,告诉它你想要什么:
使用 skill-creator 帮我实现一个 code-review目标,检测代码中:- 明显的语法问题、边界问题、异常处理、竞态问题等- 业务逻辑耦合,可读性和可维护性差- 不符合项目规范,代码风格差异大- 潜在的逻辑漏洞或其他 bug输出问题点,并指出原因和修复建议。接下来 skill-creator 会引导你完成整个流程:
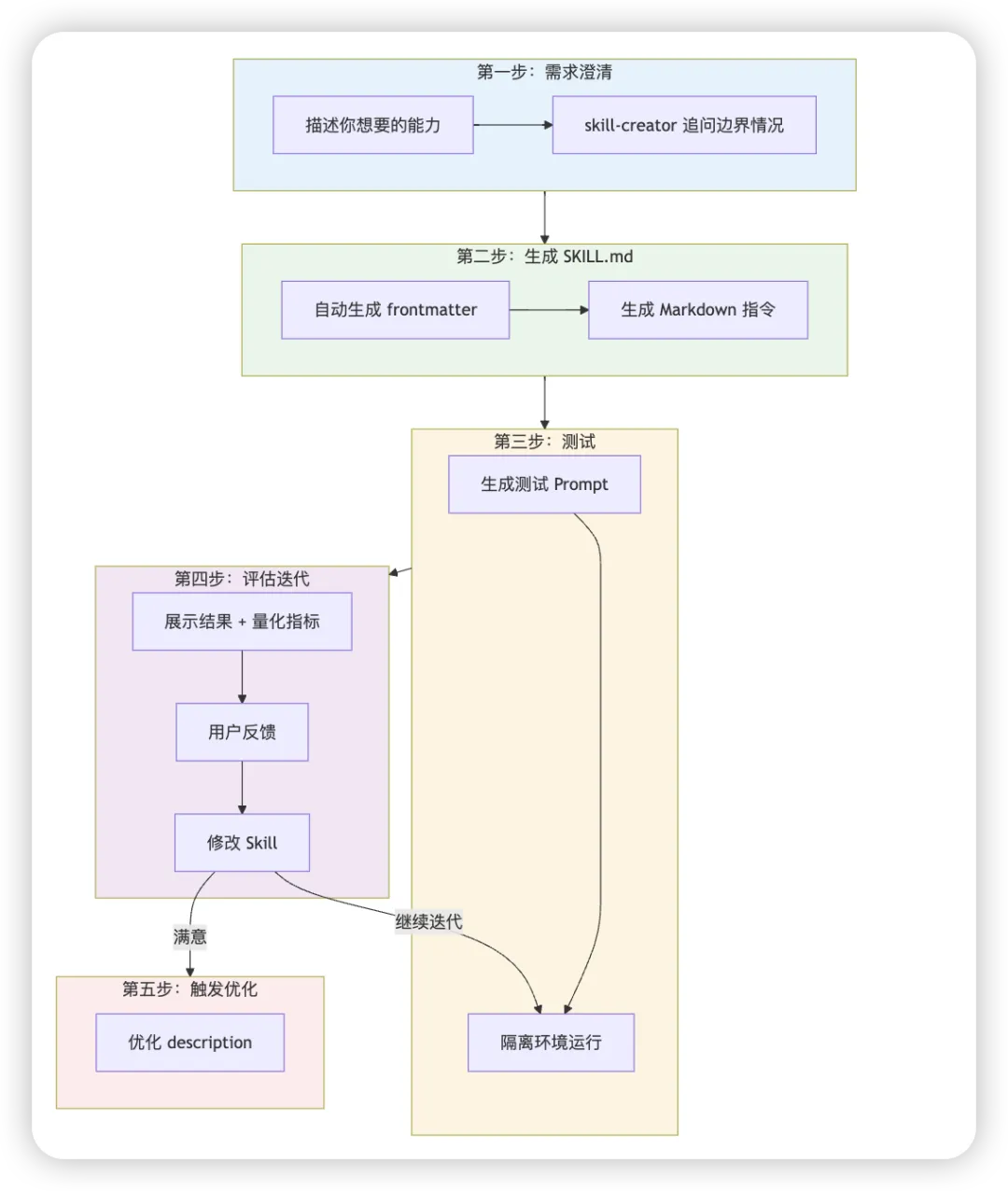
第一步:需求澄清
skill-creator 会追问一些边界情况:
检查范围是单个文件还是整个目录? 是否需要考虑特定的编程语言? 输出格式有什么要求? 严重程度如何分级?
这些问题帮助把模糊的想法梳理成清晰的需求。
第二步:生成 SKILL.md
根据澄清后的需求,skill-creator 自动生成:
frontmatter(name、description 等元数据) Markdown 正文指令 如果需要,还会规划 references 和 scripts 目录
第三步:生成测试用例
skill-creator 会生成 2-3 个真实的测试 Prompt,模拟用户实际会怎么调用这个 Skill:
请帮我 review 一下 src/utils/auth.js 这个文件然后在隔离环境中运行这些测试。
第四步:评估与迭代
测试完成后,skill-creator 会:
打开一个 HTML 界面,展示每个测试用例的输入和输出 显示量化指标:通过率、耗时、Token 用量 让你提供反馈:哪里做得好,哪里需要改进
根据你的反馈,skill-creator 会修改 Skill 并重新测试,直到你满意为止。
第五步:触发器优化(可选)
Skill 功能完善后,可以运行触发器优化,让 Skill 在正确的时机被激活。
进阶用法
运行 Benchmark
当你想量化比较两个版本时:
帮我对 code-review skill 运行 benchmark,对比 v1 和 v2skill-creator 会并行运行两个版本的测试,输出详细的对比报告。
手动触发器优化
帮我优化 code-review skill 的触发描述skill-creator 会生成测试查询集,让你审核后运行优化循环。
unsetunset总结:测试驱动的 AI 开发时代unsetunset
skill-creator 的核心价值,是把软件工程的严谨性引入 AI 能力构建。
对开发者的影响:
降低门槛:不需要是 Prompt 工程专家,也能创建可靠的 Skill 提高效率:Evals、Benchmark、A/B 测试让优化有据可依 增强可靠性:测试捕捉回归,知道何时 Skill 过时
对 AI 行业的趋势:
当前,SKILL.md 本质上是"实现计划"——详细指示 Claude 如何做某事。
未来,可能演变为"规范说明"——用自然语言描述 Skill 应该做什么,模型自行解决实现。Evals 已经在描述"what",最终,描述本身就是 Skill。
这次更新让 Skill 开发告别了"草台班子"时代。
对于已经在用 Claude Code 或其他 AI Coding 工具的开发者来说,与其折腾复杂的第三方工具,不如学好 skill-creator——这是日常工作中非常实用的大杀器。
当你下次想把某个重复工作流打包成 Skill 时,别再手写了。让 AI 帮你造 AI。
近期热门AI 原创文章:
unsetunset参考资料unsetunset
Anthropic 官方 skill-creator 文档
我组建了一个氛围特别好的 AI 社群,里面有很多 AI Coding小伙伴,如果你对AI 学习感兴趣的话(后续有计划也可以),我们可以一起进AI相关的交流、学习、共建。下方加 考拉 好友回复「AI」即可。
“分享、点赞、在看” 支持一波👍

