 夜雨聆风
夜雨聆风vLLM Llama 代码解析
vllm/model_executor/models/llama.py 很适合作为 vLLM 模型代码的入门文件。它一方面保留了标准 LLaMA 的主体结构,另一方面又把 vLLM 真正关心的工程问题都放进来了,比如张量并行、流水线并行、权重映射、量化兼容和编译支持。
如果你第一次读 vLLM 源码,建议就从这个文件开始。
模型结构和类的执行顺序
LLaMA 的简化结构大致如下:
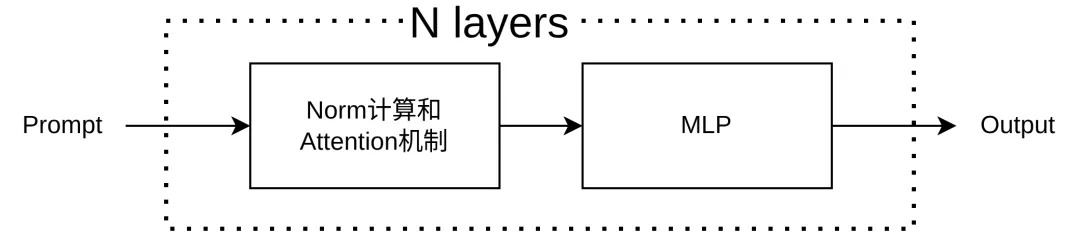
如果只保留最核心的执行主线,伪代码如下:
Model.forward: embedfor each layer: norm attention norm mlp final norm lm_head这段伪代码非常重要,因为 llama.py 的实现,本质上都在围绕这条主线展开。只是为了适配工程需求,它把这条主线拆到了多个类中,你可以先把它们的之间的调用关系理解成:
LlamaForCausalLM -> LlamaModel -> N * LlamaDecoderLayer -> LlamaAttention -> LlamaMLP如果你把断点打到 LlamaAttention.forward(),通常看到的调用栈也基本就是这条主线:
LlamaAttention------forward()LlamaDecoderLayer---forward()LlamaModel----------forward()__call__ (decorators.py)LlamaForCausalLM----forward()_dummy_run (gpu_model_runner.py)所以读这份文件时,最重要的不是先记住每一个工具类,而是先弄清楚一件事:数据到底怎么从 input_ids 一路流到 lm_head。
1.LlamaForCausalLM:最外层入口
LlamaForCausalLM 是整个模型最外层的封装。它本身并不负责 attention 或 MLP 的细节,但它负责把整个模型“拼起来”,因此地位很关键。
从结构上看,它主要组装了两部分:
• self.model:模型实例,里面存储结构和所需的参数• self.lm_head:一个输出投影子模块,用来把最终的hidden_states映射到词表维度
LlamaForCausalLM.forward() 默认返回的是 hidden_states,不是 logits。logits 会通过 compute_logits() 单独计算。
这个类和下一个类的衔接点,就在 forward() 里的这句调用:
model_output = self.model( input_ids, positions, intermediate_tensors, inputs_embeds)这里调用的就是 self.model 这个子模块,也就是 LlamaModel.forward()。所以读完 LlamaForCausalLM 之后,下一步自然就是进入 LlamaModel.forward(),看 hidden states 在主体结构里怎么继续往下流。
这样设计不是随便写的,而是为了更适合 vLLM 的流水线并行。因为在 PP 场景里,lm_head 往往只存在于最后一个 stage。如果每个 stage 都要求 forward() 直接输出 logits,整个执行组织会更麻烦。这个类里还有两个容易被忽略,但很有工程含义的属性:
packed_modules_mapping = {"qkv_proj": ["q_proj", "k_proj", "v_proj"],"gate_up_proj": ["gate_proj", "up_proj"],}embedding_modules = {"embed_tokens": "input_embeddings","lm_head": "output_embeddings",}它们说明一件事:代码内部为了效率,把一些投影层合并了,但外部像 LoRA 这样的适配系统,仍然希望用 q_proj/k_proj/v_proj 这种“语义名字”来操作。因此这里要做一层映射,把“高性能内部结构”和“外部适配接口”对齐。
另外,如果配置里启用了 tie_word_embeddings,lm_head 还会和 embed_tokens 共享权重。这样后面加载权重时就不需要重复加载 lm_head。
这里再强调一次:上面这些内容大多发生在 __init__ 里,所以它的含义主要是“定义并保存子模块”。真正的数据计算,要到 forward() 调用 self.model(...) 时才开始。也就是说,这个类往下一级真正衔接到的是 LlamaModel.forward()。
2.LlamaModel:真正的 Transformer 主体
LlamaModel 可以理解成“去掉 lm_head 之后的纯 Transformer 主体”。这个类里既定义了主体结构,也在 forward() 里执行主体计算。
它内部主要有三块:
• embed_tokens• layers• norm
这三部分正好对应标准 LLaMA 的主体结构。
先看embed_tokens。输入的input_ids会先经过 VocabParallelEmbedding 变成向量。这里用的不是普通 embedding,而是并行 embedding,这说明从一开始它就已经在考虑 TP 场景了。
再看 layers。这里通过 make_layers(...) 构造多层 LlamaDecoderLayer。从名字看起来像“只是搭一个层列表”,但其实它还隐含了流水线并行的切分逻辑。模型虽然总共有 num_hidden_layers 层,但当前进程不一定持有全部层,真正负责的层区间由 start_layer 和 end_layer 决定。
最后是norm。标准LLaMA在所有decoderlayer后面还会有一个最终RMSNorm,这里也保留了这一层。只是如果当前不是最后一个pipeline stage,它不会真的持有这个模块,而是用 PPMissingLayer() 占位。
这就是 vLLM 处理 PP 的一个典型思路:逻辑结构保持完整,但具体模块只在该出现的 stage 上真正存在。
2.1 LlamaModel.forward():主干执行是怎么串起来的
这可能是整份文件里最值得反复读的函数,因为它把“主干执行路径”完整串起来
第一步,是决定 hidden states 从哪里来。
如果当前是第一个 pipeline rank:
• 有 inputs_embeds就直接用• 否则就对 input_ids做 embedding
如果当前不是第一个 pipeline rank:
• 说明前面的 stage 已经算完 embedding 和前面一段层了 • 当前直接从 intermediate_tensors里取hidden_states和residual
这意味着同一个 forward() 同时兼容:
• 普通单段执行 • PP 下接着上一段继续算
第二步,是进入层循环:
for layer in layers: hidden_states, residual = layer(positions, hidden_states, residual)这里最值得注意的是:在层与层之间传递的不只是hidden_states,还有 residual。这说明在 vLLM 的这份实现里,残差分支不是每一层内部临时加一下就结束了,而是被显式保留下来,作为后续层继续使用的信息。
这里的layer(...)实际上调用的就是LlamaDecoderLayer.forward()。也就是说,LlamaModel自己并不展开attention和mlp的细节,而是把“单层该怎么算”交给 LlamaDecoderLayer,然后拿回这一层的输出,继续喂给下一层。
第三步,是 final norm:
hidden_states, _ = self.norm(hidden_states, residual)这一步进一步说明,最后的RMSNorm 仍然吃的是“当前 hidden states + residual”这一对信息,而不是只看一条主分支。
3.LlamaDecoderLayer:单层结构
如果只看这个类和下一级子模块的衔接,最关键就是:
hidden_states = self.self_attn(positions=positions, hidden_states=hidden_states)hidden_states = self.mlp(hidden_states)首先调用的是 LlamaAttention.forward(),其次是 LlamaMLP.forward()。
• 先做第一段 norm • 再把数据交给 LlamaAttention• attention 返回后,再做第二段 norm • 然后把数据交给 LlamaMLP
所以读完LlamaDecoderLayer,下一步自然就应该去看 LlamaAttention 和 LlamaMLP 这两个子模块内部到底怎么算。
4.LlamaAttention:注意力部分重点
在 LlamaDecoderLayer.forward() 里,真正调用它:
hidden_states = self.self_attn( positions=positions, hidden_states=hidden_states,)也就是说,LlamaAttention.forward() 的输入只有两个:
• positions• hidden_states
它不直接处理 residual。residual 是由 LlamaDecoderLayer 自己在外面维护的。
再看 LlamaAttention.forward() 本身,主线就是下面这几步:
qkv, _ = self.qkv_proj(hidden_states)q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1)q, k = self.rotary_emb(positions, q, k)attn_output = self.attn(q, k, v)output, _ = self.o_proj(attn_output)return output• 第一步,先一次性算出一个大的 qkv张量。• 第二步,大张量拆成:q, k, v • 第三步,这里只对 q和k加 RoPE,v不参与• 第四步,使用 self.attn这个子模块计算注意力。• 第五步,这一步把 attention 的输出再映射回 hidden_size• 最后,把结果返回给 LlamaDecoderLayer.forward()。LlamaDecoderLayer拿到这个返回值之后,才会继续执行后面的:
hidden_states, residual = self.post_attention_layernorm(hidden_states, residual)hidden_states = self.mlp(hidden_states)所以这几层的衔接顺序是:
LlamaDecoderLayer.forward() -> input_layernorm -> LlamaAttention.forward() -> qkv_proj -> split q/k/v -> rotary_emb -> self.attn -> o_proj -> return output -> post_attention_layernorm -> LlamaMLP.forward()另外,LlamaAttention.__init__() 里还有几块是为兼容不同配置准备的,但它们属于“构造这个模块时的配置逻辑”,不是 forward() 当场发生的计算。比较重要的有三类:
• GQA 相关:根据 num_heads和num_kv_heads计算q_size、kv_size• RoPE 相关:通过 _init_rotary_emb()初始化self.rotary_emb• 注意力类型相关:根据 attn_type选择Attention还是EncoderOnlyAttention
如果再往前多看一点,还能看到它对滑动窗口注意力和 GGUF 格式做了兼容处理,但这些都属于“初始化时怎么把模块配置好”,不是 forward() 里的主计算路径。
5.LlamaMLP:看懂 SwiGLU 就够了
相比 attention,LlamaMLP 的结构更直接,但也有一个必须看懂的点:它不是普通的两层前馈网络,而是 SwiGLU。
它的主流程可以写成:
x -> gate_up_proj -> split(gate, up) -> SiLU(gate) * up -> down_proj -> output这里最关键的是gate_up_proj。它不是一个普通投影名,而是在告诉你:代码把 gate_proj 和 up_proj 合并到了一次 MergedColumnParallelLinear 里,先一起算出来,再在最后一维拆成两半。
然后 SiluAndMul 完成核心门控操作:
SiLU(gate) * up最后再通过 down_proj 把维度收回到 hidden_size。
并行:vLLM 的工程味主要就体现在这里
这份 llama.py 表面上是模型文件,实际上它处处都在为分布式推理服务。最明显的就是两种并行:
• TP:Tensor Parallel • PP:Pipeline Parallel
TP 体现在一系列并行层上:
• VocabParallelEmbedding• QKVParallelLinear• MergedColumnParallelLinear• RowParallelLinear• ParallelLMHead
这些名字已经说明它们不是普通单卡层,而是为切分执行准备的。
PP 则主要体现在下面这些对象和判断上:
• get_pp_group().is_first_rank• get_pp_group().is_last_rank• PPMissingLayer• IntermediateTensors
其核心思想非常直接:
1. 每个 stage 只持有自己需要的模块。 2. 不属于当前阶段的模块,用占位层代替。 3. stage 和 stage 之间传递中间结果,而不是重复前面的计算。
这也是为什么在 PP 场景下:
• 首阶段负责 embedding • 中间部分负责自己那一段 decoder layers • 末尾负责 final norm 和 lm head
这里还有一个很容易忽略但非常重要的点:在这套实现里,PP 传递的不只是 hidden_states,还有 residual。因为 residual 也是这条主干计算链的一部分,下一段阶段必须接着它继续算。
值得学习什么
读这份代码时一定要同时看两层东西:
• 模型结构层:attention、MLP、decoder stack • 工程实现层:TP、PP、权重映射、量化兼容、编译支持
