 夜雨聆风
夜雨聆风在人工智能飞速发展的今天,我们见证了从代码补全到自动修复 Bug 的演进。然而,最近一个名为Program Bench的全新基准测试的出现,彻底打破了人们对 AI 编程能力的固有认知。如果说以往的测试是在考查 AI 的修补能力,那么 Program Bench 则是在要求 AI 独立完成造物的壮举:从零开始重构一整个复杂的软件系统。
 Program Bench 的核心概念——“黑盒”重构,象征着从简单修补到全系统创建的转变。
Program Bench 的核心概念——“黑盒”重构,象征着从简单修补到全系统创建的转变。
从打补丁到全量重构:测评维度的史诗级跳跃
AI 编程测评的演进路径非常清晰。最初的HumanEval关注的是简单的代码片段编写;随后的SWE-Bench提升了难度,要求 AI 在现有仓库中定位并修复 Bug。而Program Bench的出现,标志着测评进入了“黑盒重构”时代。
在该测试中,AI 无法访问互联网,拿不到任何现成的源代码,其唯一的输入是一个已编译的可执行文件和一份用户手册。AI 必须像最顶尖的反向工程专家一样,通过理解逻辑、推导边界情况并独立设计架构,去还原出整个软件。
 AI 基准测试的阶梯式进化:从 HumanEval 到 SWE-Bench,最终跨向 Program Bench 的高峰。
AI 基准测试的阶梯式进化:从 HumanEval 到 SWE-Bench,最终跨向 Program Bench 的高峰。
0% 的成功率与不可忽视的磨损效应
在对包括 GPT-4、Claude Opus 和 Gemini 在内的九大顶级模型进行测试后,结果令人震惊:在全量重构大型项目的指标上,所有模型的成功率均为0%。这意味着目前的 AI 尚无法独立复现像 FFmpeg(拥有 270 万行代码)或复杂的 PHP、Lua 编译器这样的系统。
然而,这并非宣告 AI 的失败。相反,这是一个恐怖的转折点。根据历史经验,一旦某个任务被基准化(Benchmarked),全球的 AI 实验室就会开启疯狂的刷榜和迭代模式。Claude Opus 已经在部分任务中达到了 95% 的功能实现,这预示着 0% 到 100% 的突破只是时间问题。
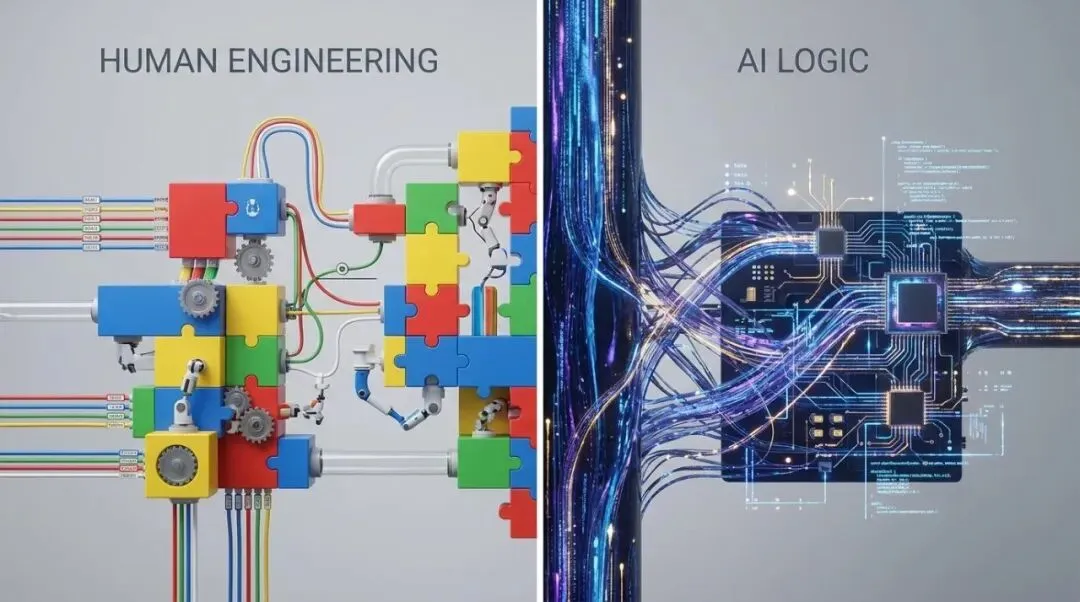 人类追求的模块化整洁代码与 AI 追求的机器执行效率之间的强烈对比。
人类追求的模块化整洁代码与 AI 追求的机器执行效率之间的强烈对比。
效率至上:AI 正在终结整洁代码时代
Program Bench 的分析揭示了一个有趣的现象:AI 生成的代码风格与人类推崇的软件工程实践完全背道而驰。人类编写代码强调模块化、解耦、可读性和目录结构,这是为了补偿人类有限的记忆力和协作成本。
而 AI 倾向于编写庞大的单文件脚本,拥有极长的函数和扁平的目录。这种被人类诟病为“代码山”的结构,在拥有百万级上下文窗口(Context Window)的 AI 看来却是最高效的。这意味着,随着 AI 成为软件生产的主力,传统意义上的“优雅代码”可能将成为历史,取而代之的是极致的机器执行效率。
职业预警:程序员角色的范式转移
Program Bench 的出现向所有开发者发出了明确信号:仅仅掌握写代码这项技能已经变得极度危险。当 AI 能够通过刷榜和磨损效应逐渐攻克软件重构的难题时,底层代码的编写将实现全自动化。
 未来程序员的角色转变:从底层代码的编写者,进化为高层系统的架构师与质控官。
未来程序员的角色转变:从底层代码的编写者,进化为高层系统的架构师与质控官。
未来的程序员必须从代码编写者转型为需求设计师、系统验收员和质量控制官。核心竞争力将不再是你实现功能的速度,而是你定义系统架构的能力,以及判断 AI 生成结果是否符合业务逻辑的深度。
结语
Program Bench 不仅仅是一个测试榜单,它更像是一份关于未来软件生产方式的预言。它定义了自主 AI 软件工程师的终极目标。当代码的生产成本趋近于零,当人类不再需要为了阅读而优化代码时,整个软件产业的逻辑都将被重写。我们正处于一个旧时代的终点,而迎接我们的,是一个由 AI 驱动的、逻辑完全异化的新数字化世界。
