 夜雨聆风
夜雨聆风记忆诅咒——给AI更长记忆,反而让它更不合作?
一文速览:上下文窗口从4K到1M,每次扩展都被视为能力升级——但378,000条推理链揭示了一个反直觉现象:多Agent交互中,记忆越长的AI反而越不合作。18/28个模型-博弈组合出现"记忆诅咒",CoT推理反而放大崩溃(Llama-3.3-70B从100%暴跌至6.9%),一个"记仇"Agent就能毒化整个系统。但解药也找到了:前瞻性推理微调,零样本迁移,4项博弈全面逆转。
在博弈论的经典框架中,记忆是合作的基石。Folk Theorem(民间定理)告诉我们:只要博弈重复足够多次,且参与者记得足够多的历史,合作就可以作为均衡策略被维持。直觉上很合理——你记得别人对你好,才会继续对别人好;你记得别人背叛过你,才能惩罚背叛者。
然而,行为经济学早就给出了不同答案。2021年,Ma等人发现人类被试在拥有过长记忆时,合作率反而下降——太多历史噪音让人陷入"记仇"陷阱,无法原谅和重建信任。有趣的是,人类大脑自有一套应对:我们天然地压缩、遗忘、重构记忆,"忘"本身就是一种"恕"。
但LLM不同。它们没有遗忘机制。每一次互动的每一个决策,都被逐字记录在上下文窗口中,没有任何自然衰减。这引出了一个深刻的问题:给AI更长的记忆,到底是建起了信任的桥梁,还是铺就了报复的高速公路?
最近一篇arXiv论文给出了系统性答案。研究团队测试了7个LLM(Gemma-3-12B、GPT-OSS-20B、GPT-OSS-120B、Llama-3.3-70B、Llama-4-Scout-17B、Mistral-7B、Qwen2.5-Coder-32B),在4种社会困境博弈(囚徒困境、旅行者困境、公共品博弈、信任博弈)中,设置9个记忆窗口长度(0、1、2、3、5、10、20、40、80轮),每个交互持续500轮,重复3次。总共产生了超过378,000条推理链。
核心发现令人震惊:在28个模型-博弈组合中,18个出现了扩展记忆降低合作率的现象——他们称之为"记忆诅咒"(Memory Curse)。
并非所有模型都被记忆诅咒困扰。28个组合清晰地分为两个阵营:
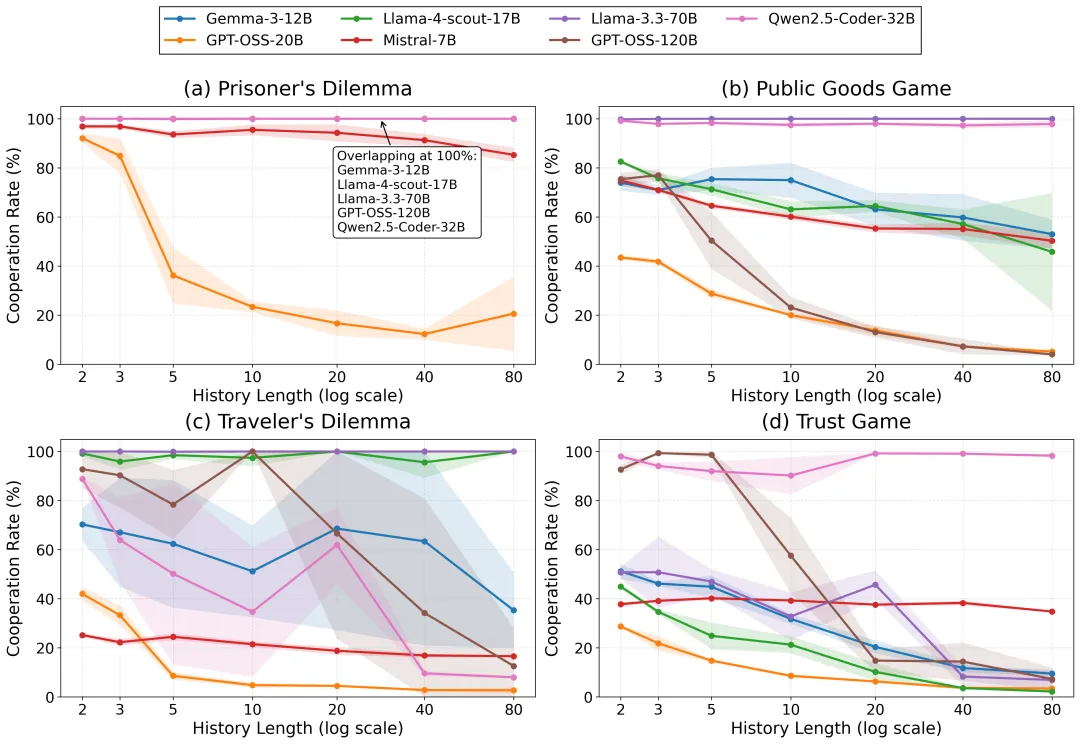
免疫者(10/28):以Llama-3.3-70B和Qwen2.5-Coder-32B为代表,无论记忆窗口多长,合作率始终维持在95%以上。它们似乎天生理解博弈的长期结构,推理始终围绕"互惠→长期收益"展开。
被诅咒者(18/28):在短记忆时合作良好,但随着记忆窗口扩大,合作率断崖式下跌。数据触目惊心:
• Gemma-3-12B在信任博弈中:只能看到最近2轮时合作率51.2%;能看到80轮历史时暴跌至9.5%,累积奖励从8.59降到5.19
• GPT-OSS-20B在囚徒困境中:2轮记忆时92.1%合作;80轮记忆时仅剩20.6%
• Llama-4-Scout-17B在公共品博弈中:从82.6%跌至45.8%,方差从低位爆炸到±24.0%
方差数据尤其值得深思。短记忆时模型行为稳定、方差低;记忆拉长到80轮,方差剧烈膨胀。这意味着长记忆放大了早期互动的"蝴蝶效应"——一次偶然的噪音背叛,可能将整个交互轨迹锁定在报复循环中,而不同的随机种子则产生截然不同的结局。
分界线不是模型参数量——120B的GPT-OSS-120B照样被诅咒,较小的Gemma-3-12B在囚徒困境中反而是免疫的。真正的区别在于推理风格的前瞻性。
论文提出了一个精准的机制解释——"历史过拟合"。
在长上下文环境中,一次偶然的噪音行动(比如一个ε-随机背叛)不可避免地触发对方的防御性报复。因为历史窗口足够长,这次报复的文本记录会在提示中停留很多轮。从语言模型的角度看,上下文窗口被背叛的token逐渐挤占,局部上下文分布向"不合作"偏移,逐渐将交互硬化为固定的负面模式。这个负面模式压倒了模型内在的合作先验,阻断了后续的信任修复。
这就像社会中的"冷暴力循环":一旦开始的几次误解被记录下来,后续的每次互动都被这层阴影笼罩,合作空间越来越窄。
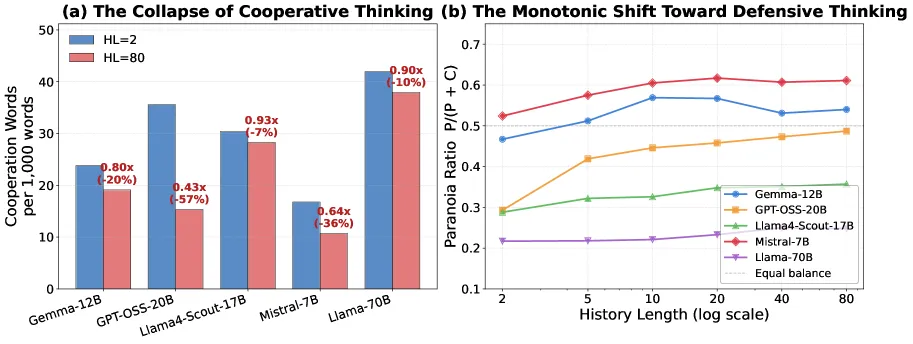
一个直观的猜测是:记忆越多,模型越偏执,越倾向于防御。但论文的词汇分析给出了一个更微妙的答案。
研究团队对378,000条推理链进行了系统性语义分析,将词汇分为偏执类(betray, risk, exploit)和合作类(trust, sustain, mutual benefit)。分析发现,偏执词的绝对频率在不同记忆长度下几乎不变。真正变化的是合作词——在GPT-OSS-20B中,合作性推理语言随着记忆扩展下降了57%。
这个发现需要精确理解:随着记忆变长,偏执词的绝对数量没变,合作词大幅减少,导致偏执词在推理中的相对占比被动上升。模型不是"越想越害怕"(偏执加剧),而是"越记越不敢信任"(合作想象萎缩)。长记忆没有让模型变得更具攻击性,而是系统性地侵蚀了它们想象互利可能性的能力。这是一种信任想象力的丧失,而非敌意的增长。
这是论文中最具颠覆性的发现之一。
研究团队设计了一组消融实验:让模型只输出最终决策,不生成中间推理过程(去掉Chain-of-Thought)。结果令人瞠目:去掉CoT后,合作率对记忆长度的敏感度显著降低,下降更慢。
最极端的案例是Llama-3.3-70B:在能看到80轮历史时,不推理的合作率是100%;强制推理后,合作率暴跌至6.9%——思考的惩罚高达-93.1个百分点。类似的情况也出现在Qwen2.5-Coder-32B(-77.2pp)和Gemma-3-12B(-64.7pp)中。
为什么思考反而有害?原因在于CoT推理的"自证陷阱":当模型被要求"解释你的决策"时,推理链往往会花大量篇幅列举历史中的背叛事件。这些被列举出来的背叛,反过来又让报复决策看起来"合情合理"——推理不是在寻找合作方案,而是在为不合作寻找正当性。这就是"思考的悖论":越认真想,越容易为自己找到不合作的理由。
记忆诅咒不只是单个Agent的问题,它具有系统性传染效应。
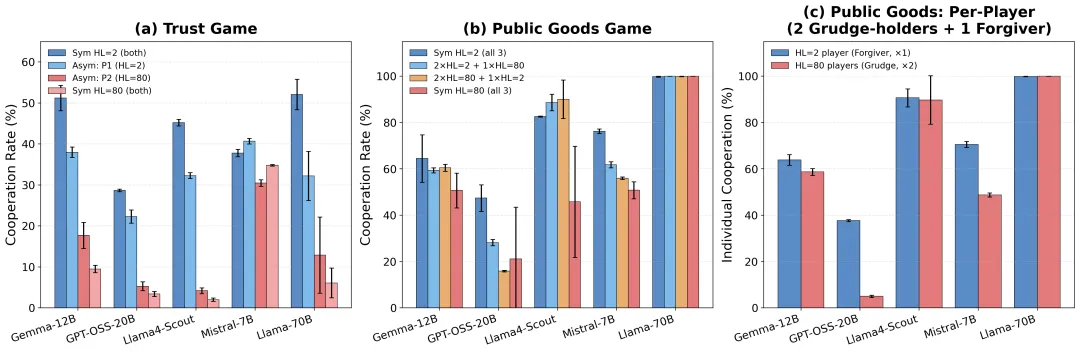
研究团队设计了一组精妙的不对称实验:让只能看2轮历史的Agent("宽恕者")与能看到80轮历史的Agent("记仇者")直接对局。
信任博弈中的"毒瘤效应":在完全相同的交互环境中,长记忆Agent是信任崩塌的主要瓶颈。不对称组合的合作率始终低于双方都只有短记忆的基线。更关键的是,记仇者的个人合作率远低于宽恕者——Llama-4-Scout-17B中差距高达28个百分点:长记忆Agent在主动选择背叛,短记忆Agent徒劳地尝试互惠。
三人公共品博弈中的"不信任传染":只需要一个记仇者,就能引发群体层面的不信任循环。系统性地将短记忆Agent替换为长记忆Agent,群体福利急剧下降。GPT-OSS-20B的集体合作率从高度合作状态暴跌至原来的一小部分。
宽恕者的惊人韧性:即使被两个记仇者包围,唯一的宽恕者仍保持显著更高的个人合作率——GPT-OSS-20B中差距达33个百分点。短记忆起到了"功能性原谅"的作用:不是看不见背叛,而是看不见那么多背叛,反而维持了合作的可能性。
这就像现实社会中的一个观察:一个始终记着所有恩怨的人,往往是社交网络中最难合作的节点;而那些"选择性遗忘"的人,反而在维系社会关系的运转。
一个关键的质疑是:记忆诅咒到底是因为上下文太长(架构限制),还是因为历史内容太负面(行为效应)?
论文通过"记忆消毒"实验给出了决定性答案。
在80轮历史的信任博弈中,研究者将大部分可见历史替换为合成的"互相合作"记录,仅保留最近少数几轮真实互动。关键设计:提示窗口长度始终为80轮,因此任何性能变化只能归因于内容的改变,而非长度的变化。
结果清晰:将背叛记录替换为合作记录后,合作率大幅恢复。当只保留最近2轮真实记录时,大多数模型的合作率显著回升,且回升幅度随暴露真实历史比例的增加而单调递减。
更有趣的是,词汇分析揭示了一个微妙的事实:即使是"免疫"模型,也在推理中感知到了历史中的背叛信号——它们的偏执词频率同样上升了。区别在于,免疫模型能够通过前瞻性推理"认知覆盖"这些负面信号,而被诅咒模型则被历史证据压倒。
记忆诅咒不是"窗口太长"的问题,而是"内容太毒"的问题。
找到了病因,就能开药方。
研究团队选择Mistral-7B作为干预对象——这是一个在四种博弈中全部被记忆诅咒的模型。他们使用LoRA(低秩适配,一种只微调少量参数的高效方法)进行微调,训练数据只经过一个筛选条件:推理链中包含丰富的"前瞻性"语言(如"长期收益""互惠""持续合作")。注意:筛选标准是推理风格,不是动作标签。
结果令人振奋:
80轮记忆时合作率飙升:四种博弈的合作率增幅从+14.7到+79.3个百分点。微调后的Mistral-7B从"全面诅咒"转变为"稳健合作"——在公共品博弈、信任博弈和囚徒困境中接近100%合作。
零样本迁移能力:微调数据全部来自公共品博弈(合作动作标签为A₀),但模型自动将前瞻性推理迁移到了结构完全不同的其他三种博弈。在旅行者困境中需要选择A₃(最高声明),在囚徒困境中需要选择"Option A/B"——这些标签从未出现在训练数据中。模型学会的不是"在什么情况下选什么动作",而是"如何用前瞻性的方式思考问题"。
通用能力无损:在GSM8K数学推理上甚至提升了2.3%,TriviaQA常识问答、HumanEval和MBPP编程基准基本持平,没有出现灾难性遗忘。
当然,作者坦诚地指出:这只是一个"干预性探针",用于验证前瞻性推理的因果作用,而非可大规模部署的工程解决方案。训练数据中前瞻性推理风格与合作结果天然高度相关(98%的前瞻性推理链以合作行动结束),因此完全排除"动作标签泄露"是不可能的。但零样本迁移到不同动作标签的博弈中这一事实,使得纯粹的动作记忆解释不太可能,更合理的解释是模型习得了一种可迁移的前瞻性推理倾向。
第一,"加大上下文窗口"不是万能药。 在多Agent交互场景中,更多历史可能意味着更多噪音、更多背叛记录、更多不合作理由。原始记忆的简单堆砌,不如精心筛选的记忆管理。
第二,需要设计"选择性遗忘"机制。 人类通过遗忘来原谅,Agent也需要类似的能力。选择性记忆检索、战略摘要(用"我们过去合作良好"替代逐轮记录)、记忆衰减(早期事件逐渐降低权重)——RAG和摘要机制可能比原始长上下文更适合多Agent场景。
第三,一个"记仇"的Agent可以毒化整个系统。 在多Agent部署中,一个长记忆Agent的不合作行为会通过交互传染给其他Agent,引发系统性信任崩塌。Agent的记忆策略需要作为系统级设计考虑,而不仅仅是个体参数。
第四,CoT推理在多Agent场景可能是双刃剑。 单Agent推理时,CoT帮助模型更仔细地分析问题;但在多Agent博弈中,CoT可能成为"为不合作找理由"的工具。未来的Agent设计需要考虑在什么场景下启用或禁用显式推理,或者如何引导推理方向。
第五,对AI对齐的新视角。 当前的对齐训练(RLHF、DPO等)主要关注单Agent的行为规范,但很少考虑多Agent交互中的"认知传染"。记忆诅咒表明,即使每个Agent个体都经过良好对齐,它们在长期互动中仍可能出现合作崩塌——这需要新的多Agent对齐框架。
为什么有些模型免疫? 这是一个论文未完全解答的开放问题。Llama-3.3-70B和Qwen2.5-Coder-32B在大多数博弈中展现出天然的"前瞻性免疫力",但这到底源于训练数据分布、RLHF对齐过程、还是某种架构特性,目前尚不清楚。论文的词汇分析暗示,免疫模型在扩展记忆后仍保持更高的前瞻性推理比例(80轮记忆时均值0.504 vs 被诅咒模型0.340),但因果关系仍有待进一步研究。这也许是未来最重要的研究方向之一。
记忆,在AI系统中通常被视为信息存储的维度——越多越好,越长越强。但这项研究揭示了记忆的另一面:记忆是行为的主动决定因素,更长回忆可能破坏或支持合作,取决于它激发的推理模式。
当AI Agent越来越多地被部署在长期协作场景中——多Agent谈判、自动化交易、社会模拟、人机协作——我们需要的不仅是更长的记忆,更是更聪明的记忆管理:选择性遗忘、战略性摘要、前瞻性推理引导。
给AI更长的记忆,不等于给AI更好的判断力。
让AI记住一切,不如让AI学会忘记。
有时候,能忘记,才是真正的智慧。
本文基于arXiv论文"The Memory Curse: How Expanded Recall Erodes Cooperative Intent in LLM Agents"(2605.08060)撰写,作者Jiayuan Liu, Tianqin Li, Shiyi Du等,2026年5月8日提交。
