 夜雨聆风
夜雨聆风满屏的AI词汇,看得越多越懵——这篇文章就是你的「AI黑话翻译器」。16个最高频的AI术语,每个都用大白话+生活类比说清楚。
💡 建议先收藏,遇到不懂的词,回来翻这篇就行。
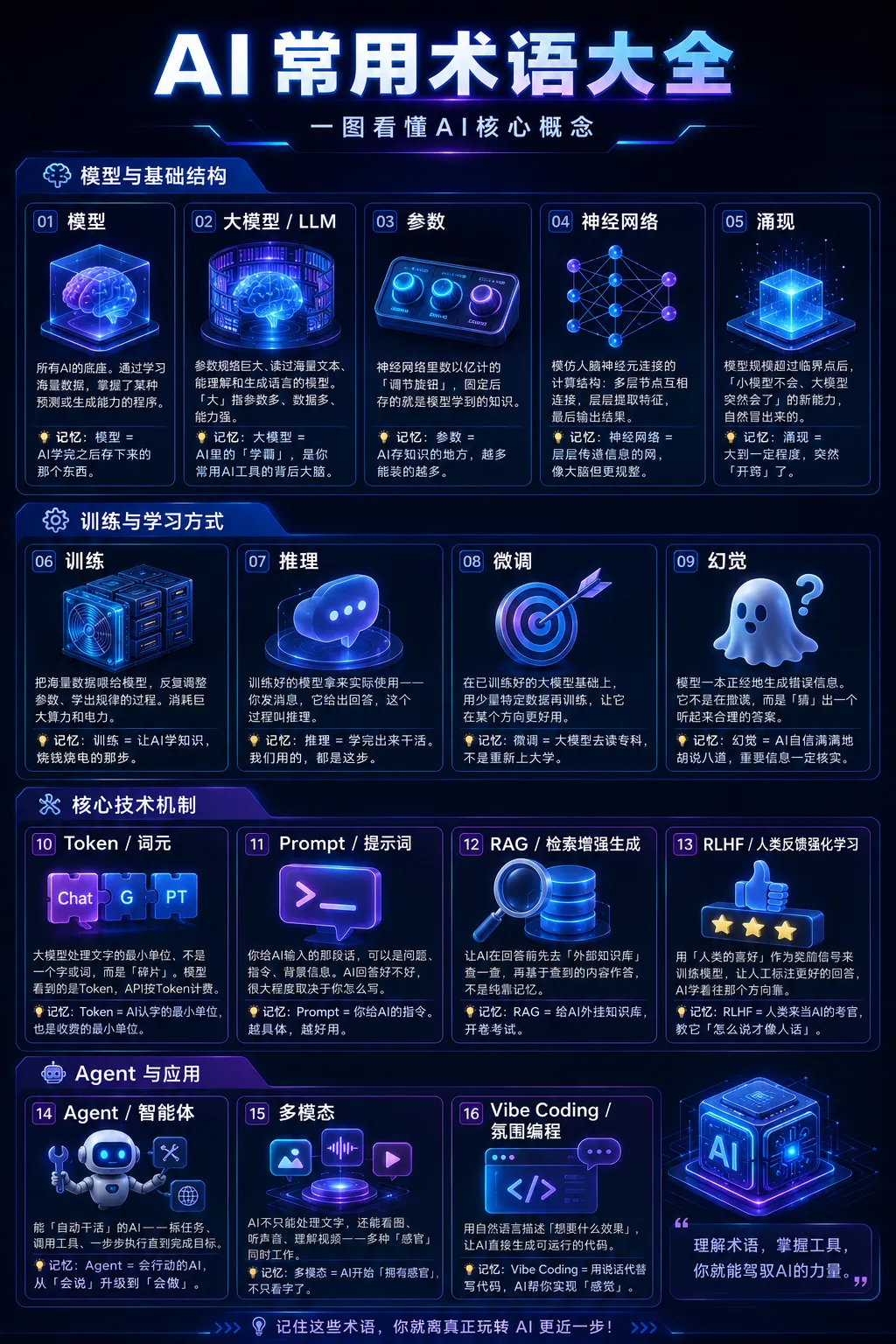
🧠 模型与基础结构
大模型 / LLM(Large Language Model)参数规模巨大、读过海量文本、能理解和生成语言的模型。ChatGPT、Claude、DeepSeek都是大模型。「大」指的是参数多、数据多、能力强。 🍎类比:就像一个把图书馆全读完的人——你问什么,它都能接几句。不一定全对,但永远不沉默。 🧠记忆法:大模型 = AI里的「学霸」,是你常用AI工具的背后大脑。 |
Parameter参数神经网络里数以亿计的「调节旋钮」,训练时不断调整,最终固定下来——存的就是模型学到的知识。你常听到的「千亿参数」就是在说这个。 |
Neural Network神经网络模仿人脑神经元连接方式设计的计算结构:多层节点互相连接,信息从一层传到下一层,每层提取更高级的特征,最后输出结果。 |
Emergence涌现模型规模超过某个临界点后,「小模型不会、大模型突然会了」的新能力——不是人为设计的,是自然冒出来的。 |
Training训练 把海量数据喂给模型,让它反复调整参数、学出规律的过程。只有AI公司在做,消耗巨大算力和电力。 🍎类比:让学生做了一千万道题,做错立刻纠正——训练就是这个反复刷题的过程,只不过AI刷的是数据。 🧠记忆法:训练 = 让AI学知识。 |
Inference推理 训练好的模型拿来实际使用——你发一条消息,它给出回答,这个过程叫推理。我们平时用ChatGPT聊天,全程都在推理阶段。 🍎类比:学生读完书毕业后开始工作——你雇的是毕业后的他,不用管他怎么读书的。 🧠记忆法:推理 = 学完出来干活。 |
Fine-tuning微调 在已训练好的大模型基础上,用少量特定领域数据再训练一遍,让它在某个方向更好用。不是从头学,是在原有基础上精进。 🍎类比:全科医生再读三年皮肤科专科——没有扔掉通识能力,只是加强了某个专项。 🧠记忆法:微调 = 大模型去读专科,不是重新上大学。 |
Hallucination幻觉 模型一本正经地生成了错误信息——它不是在撒谎,而是根据语言模式「猜」出一个听起来合理的答案,但那个答案可能根本不存在。 🍎类比:就像有人记忆不好但死不承认,会「脑补」出一个听起来合理的故事来填补空白——而且说得非常自信。 🧠记忆法:幻觉 = AI自信满满地胡说八道。重要信息一定核实。 |
大模型处理文字的最小单位——不是一个字或一个词,而是介于两者之间的「碎片」。模型看到的是Token,API按Token计费。 🍎类比:「ChatGPT」可能被拆成「Chat」「G」「PT」三个Token。模型是按这些碎片来理解和生成文字的。 🧠记忆法:Token = AI认字的最小单位,也是收费的最小单位。 |
Prompt提示词 你给AI输入的那段话——可以是问题、指令、背景信息。AI回答好不好,很大程度取决于你Prompt写得清不清楚。 🍎类比:跟一个聪明但容易跑偏的实习生沟通——说「写文案」他懵;说「写面向25岁女生的防晒霜小红书文案,语气活泼」,他立刻明白了。 🧠记忆法:Prompt = 你给AI的指令。越具体,越好用。 |
🍎类比:普通AI闭卷靠记忆,容易瞎编;RAG允许AI带「小抄」进考场,现查现答,准确多了。 🧠记忆法:RAG = 给AI外挂知识库,开卷考试。 |
RLHF人类反馈强化学习 用「人类的喜好」作为奖励信号来训练模型——让人工标注哪个回答更好,AI学着往那个方向靠。ChatGPT能说「人话」,很大程度靠这个。 🍎类比:就像训狗做对了给零食,做错了不给——AI也是靠这种「人类点赞」的反馈一点点变得准确。 🧠记忆法:RLHF = 人类来当AI的考官,教它「怎么说才像人话」。 |
Agent智能体 能「自动干活」的AI——不只回答问题,还能拆任务、调用工具、一步步执行直到完成目标。是目前最热的AI方向之一。 🍎类比:普通AI像「坐那里答题的人」,Agent像「能帮你跑腿的助理」——给它一个目标,它自己拆步骤、找工具、完成任务。 🧠记忆法:Agent = 会行动的AI,从「会说」升级到「会做」。 |
Multimodal多模态 AI不只能处理文字,还能看图、听声音、理解视频——多种「感官」同时工作。你上传截图让AI分析,用的就是这个能力。 |
Vibe Coding氛围编程 |
💡 先收藏这篇,遇到不懂的AI词随时来翻 🙌
