 夜雨聆风
夜雨聆风你一定遇到过这种情况。
好不容易去了一趟景点,拍了一段超满意的视频。回来一看——背景里全是路人丙、丁、戊……
行,Pro级选手,打开AI消除工具,一顿操作猛如虎。
然后你发现:人是真的没了,但影子还在地上晃。
或者更离谱的:你本来想消除那个乱入的路人,结果AI给你把旁边的柱子"顺走"了,留下一块诡异的空白。
这还不是最绝的。
有时候视频里有人快速骑过自行车,你一帧一帧处理,结果第12帧到第15帧之间——车没了,但留下了一道幽灵般的残影,忽闪忽闪的,比鬼片还刺激。
一句话总结:现有方法,理论上很强,实践起来全是bug。

为什么AI视频消除总是"差点意思"?
很多人会问:AI都这么强了,怎么连个物体都消除不干净?
原因很简单——大多数论文里的"完美测试环境",现实中根本不存在。
真实世界的视频有三个"不完美":
第一,遮罩不完美。
你用SAM或者其他分割模型标出来的边界,边缘经常歪歪扭扭的。AI一看这遮罩,心里就犯嘀咕:"这到底要我消除哪些?"
第二,运动不完美。
物体在视频里不可能匀速直线运动,总会有突然加速、减速、转弯的时候。传统方法逐帧处理,到了这些突变帧,分分钟"跟丢"目标。
第三,阴影不完美。
物体没了,影子还在。咖啡杯移走了,桌上还留着一圈阴影轮廓。你说这是消除成功了还是没成功?
小米大模型应用团队就是看到了这三个问题,花了大半年时间,搞出了今天要聊的SVOR(Stable Video Object Removal)。
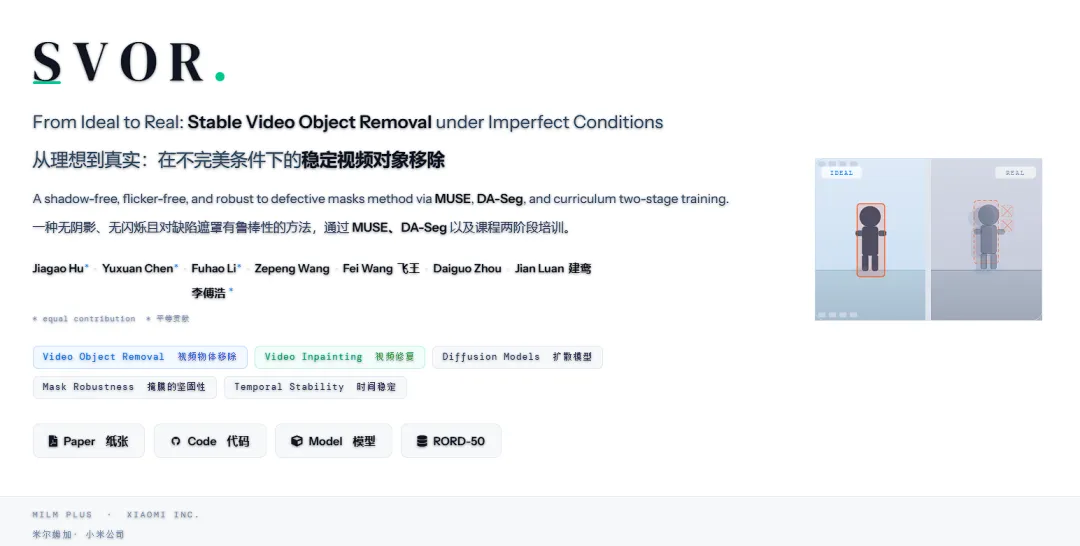
SVOR是什么?一句话版本
小米提出的视频物体消除框架,专门在"不完美"的真实条件下稳定工作。
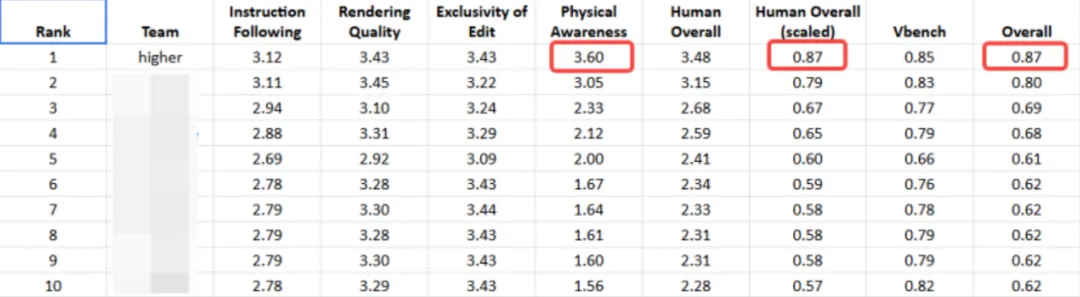
不是实验室里那种"控制变量完美条件下刷SOTA"的货色,而是直接拿到CVPR 2026物理感知视频实例消除挑战赛上,和17支队伍同台竞技,然后——拿了第一名。
它是怎么做到的?三个核心设计
1. MUSE:让快速运动不再"跟丢"
MUSE,全称Mask Union for Stable Erasure(遮罩联合稳定消除)。
这名字听着复杂,但原理很好理解。
传统方法处理视频的时候,每一帧单独看,物体在哪个位置就消除哪个位置。
问题来了:如果一个物体运动速度很快,第1帧在左边,第3帧在右边,第2帧刚好被跳过了怎么办?
MUSE的思路是:别单独看每一帧,看一个时间窗口内的整体。 在这个窗口里,把所有出现过物体的位置都标记上遮罩。
就像你用肉眼看快速移动的乒乓球,脑子会自动"脑补"它的运动轨迹,而不是只看某一帧的定格。
实测下来,MUSE可以让快速运动物体的消除成功率大幅提升,那些"一闪一闪"的问题基本消失。
2. DA-Seg:遮罩不准确?AI自己纠错
DA-Seg,全称Denoising-Aware Segmentation(去噪感知分割)。
这玩意儿相当于给系统装了一个"智能纠错机制"。
就算你标出来的遮罩边缘歪了、漏了一块,DA-Seg也能根据扩散模型的去噪过程,"猜"出物体真正的边界在哪里。
它不会去干扰主要的生成过程,只是默默提供更准确的定位信息。
简单说:遮罩不准不是你的错,SVOR帮你兜底。
3. 两阶段训练:先学走路,再学跑步
第一阶段:用真实背景视频做自监督学习,让模型学会"理解"正常场景应该长什么样。
第二阶段:用合成数据精调,专门训练"消除阴影和反射"这个技能。
这个策略叫什么?课程式学习(Curriculum Learning) ——先学简单的,再学难的。
结果就是:阴影没了,背景自然了,连"连人带影一键抹除"这种操作都能做到。
实测效果怎么样?
光说不练假把式。SVOR在多个标准数据集上刷到了SOTA水平。
更重要的是,在遮罩退化、运动突变这些"不完美条件"下,SVOR的稳定性远超现有方法。
简单翻译一下:别人在实验室里很牛,SVOR在真实场景里很能打。
总结一下:
视频物体消除这个赛道,从来不缺"论文SOTA",缺的是"真实场景能打"的方案。小米SVOR这次做的事,说白了就是:正视现实中的不完美,然后解决它。不是搞一个"实验室里的完美方案",而是让技术真正落地。视频编辑工具的下一波突破,说不定就从这里开始。
GitHub:https://github.com/xiaomi-research/svor
往期精选
比Claude Code便宜百倍!这个21K Star的终端Agent让DeepSeek生态闭环了!
4.6K Star的AI排版项目Kami,制定8条铁律,让AI排版直接起飞!
28.7K Star!开源版Claude Design来了,这次不用花一分钱!
GPT Image 2的免费平替!SenseNova U1:看图推理生图一条龙!
游戏开发要变天!说句话就能玩上自己设计的游戏!OpenGame让游戏开发门槛降到地板!
追踪AI前沿,深挖GitHub宝藏。
用优质内容陪你成长,
点击关注,携手启航。
