 夜雨聆风
夜雨聆风从宏观来看,金融市场的核心功能是资金的配置与融通;在微观层面,这一功能通过金融交易实现。所有交易的前提都是可靠的信息与数据。所谓“可靠”,至少包括三个要求:覆盖完整性(Coverage)、准确性(Accuracy)和合规性(Compliant)。
获取可靠的金融数据,是各类 AI 工具与智能体落地金融应用的底层基础。所谓"Garbage in, garbage out"(垃圾进,垃圾处),输入错误或劣质的数据,必然输出偏差结论甚至毫无意义的结果。
AI 技术的迭代发展,尤其是大语言模型(LLM)和生成式人工智能(GenAI),指数级地提升了金融信息和数据分析的效率。它既能够快速处理新闻等非结构性数据处理,也能更高效地检索、调取并分析结构化数据,还可以在短时间内自动生成分析报告,契合交易流程精简和极速执行的行业要求。
这类技术创新,尤其是 Deepseek 4.0 等 LLM 开源工具,进一步降低了金融服务的参与门槛,对金融这一数据驱动型产业形成明显冲击:咨询、金融软件、市场分析等相关业务受影响尤为突出,不少金融服务公司估值承压,面临较强的替代与颠覆风险。
即便如此,从实际落地情况来看:人工智能并不能从根本上自动解决数据可得性与可靠性两大核心问题,甚至还可能衍生出新的数据风险与挑战。
一、数据可得性难题
金融数据的核心价值在于降低市场信息不对称,是资产准确定价的重要前提。彭博、LSEG、ICE、万得、同花顺等金融信息服务商,通过数据采集、整合、加工与分发,持续缓解市场信息不对称问题。
从经济学视角来看,大规模金融数据的生产、运维本身存在高昂成本。若所有数据都可借助 AI 免费、无限制公开获取,信息服务商将丧失提供付费数据的商业动力,进而破坏数据生产与维护的可持续性,催生 “搭便车”现象。这会削弱数据质量保障、造成数据供给不足,进一步恶化市场数据可得性。
二、知识产权与授权合规
指数、评级、估值等高价值金融数据,以及可直接用于交易分析、业务流程的专业研判成果(如标普、穆迪、惠誉、MSCI 等数据产品),知识产权均归属数据提供商;而交易所逐笔行情、实时报价等基础行情数据,产权则归各交易平台所有。
具备产权属性的数据接入 AI 分析工具前,必须完成合法授权,否则将面临合规风险(Compliance Risk)。当算力不再成为行业主要瓶颈,金融数据这类数字资产已经成为AI时代更稀缺的生产资料。金融数据企业虽会主动拥抱AI技术,但绝不会轻易出让自身核心数据资产。
三、数据供应商的信用背书与责任承担
金融数据服务商不只是数据供给方,更依托数据准确性提供专业信用背书。一旦数据出现错漏,服务商需承担相应责任并及时修正,有效降低道德风险,筑牢数据可信根基。
反观纯 AI 生成或 AI 自主校验的数据,普遍存在可解释性弱(黑箱问题)、数据源追溯困难、责任主体难以界定等短板,很难在金融核心场景替代经过权威认证的专业数据源。直白来说,数据一旦出现重大偏差,AI 无法承担责任,而金融数据服务商为维护自身商誉,有充足动力主动兜底、整改纠错。
境外金融数据提供商分类图
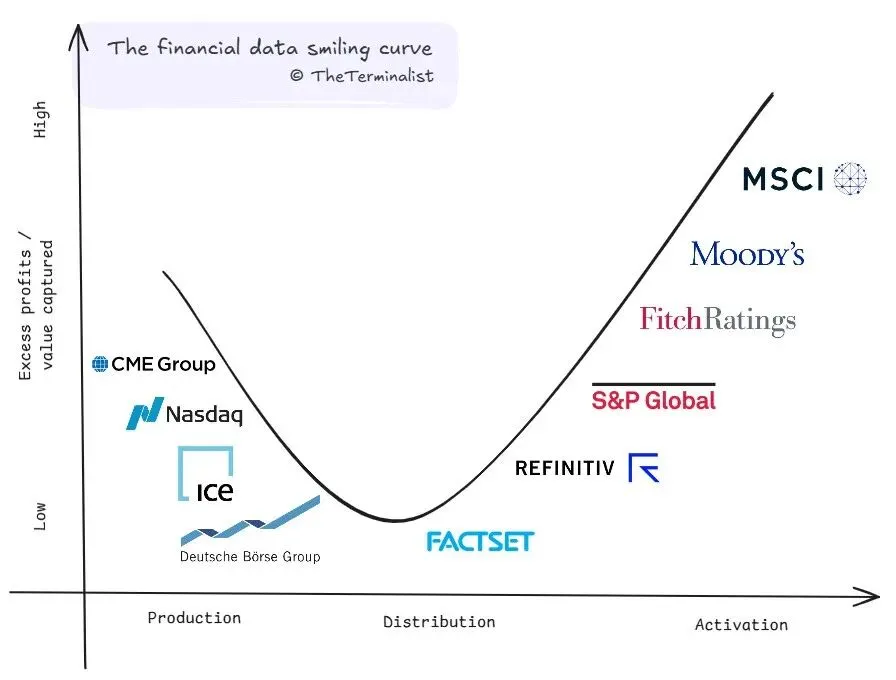
来源:https://theterminalist.substack.com/p/beyond-bloomberg-the-invisible-curve
以上三大因素决定:AI 时代的数据供给仍是行业突出痛点。金融机构虽拥有了更强的数据分析工具,但金融数据的供给逻辑与源头约束依旧存在诸多挑战。
不仅如此,AI 的发展还催生了新的金融数据可靠性隐患:包括算法生成虚假数据、恶意主体对 AI 模型进行 “数据投毒”、黑箱分析结果不可溯源等问题,让 AI 时代的数据可靠性面临更大考验。
此外,跨市场数据壁垒、监管规则约束、企业内部数据权限隔离等现实摩擦,进一步抬高了数据获取门槛。
依靠 AI 工作流(Workflow)一键完成全流程金融分析、自动执行交易的理想形态,目前仍距离落地较远。
正所谓理想很丰满,现实很骨感,梦想中“Palantir 本体论”式的全域金融 AI 生态,短期内仍难以实现。
当然,AI 仍是金融发展的核心引擎与未来趋势,行业变革速度远超预期。我们期待 AI 时代的金融数据生产资料能够更易获取、质量更有保障,但这离不开监管规则、数据要素市场、金融基础设施的中长期持续完善。
归根结底,金融属于强监管、重风险管理的行业,合规、可靠、可信的数据,在可预见的未来,依然比技术创新的新颖性来得更为重要。
高质量的数据生产要素和AI所依赖的算力一样,将继续是AI 时代稀缺的生产资料。
