 夜雨聆风
夜雨聆风这一天,三件事同时发生。
它们互不相干,却指向同一个结论。
第一件事:一个 7B 的小模型,当上了 GPT-5 的老板
先讲这篇论文。它够硬核,也够颠覆。
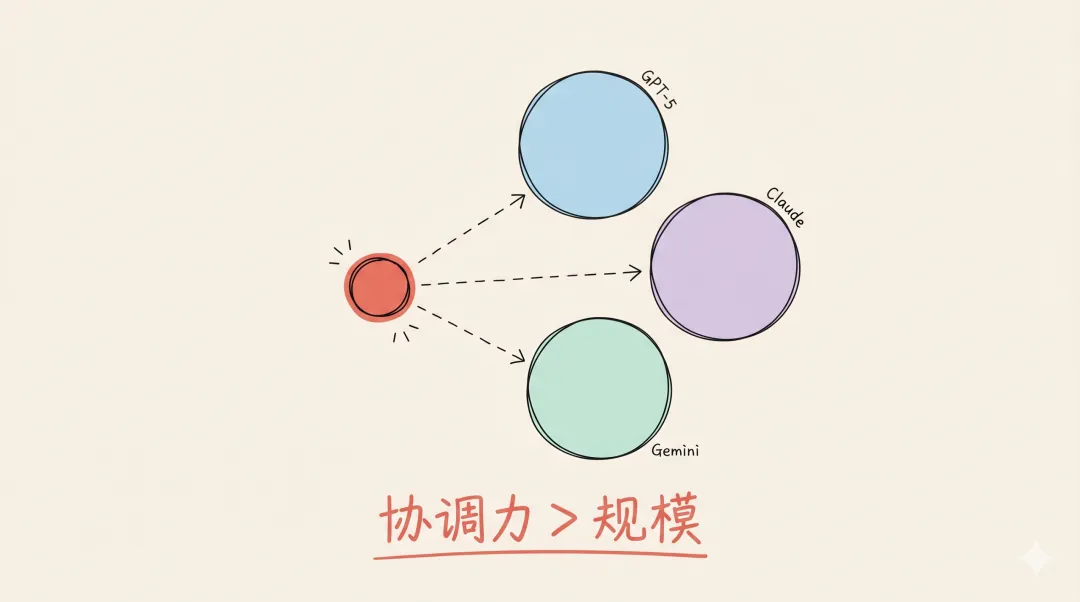
一个通过强化学习训练的 7B 参数模型——注意这个数字,7B,在今天的 AI 圈连"中等规模"都算不上——被安排了一个任务:指挥 GPT-5、Claude Sonnet 4 和 Gemini 2.5 Pro 协同工作。
它不是简单地调用这些大模型。它是做管理。写自然语言子任务,分配给不同的大模型执行,精确指定每个模型需要的上下文信息,然后综合结果。
结果让人沉默。
在 GPQA Diamond、LiveCodeBench 和 AIME 25 三个硬核基准测试中,这个"小指挥大"系统全面超越了任何一个单个前沿模型。
几个数字值得刻在脑子里:
- 平均每个问题只需要调用约 3 次大模型,比人类手动设计的多代理流程更高效
整个提示工程和流程设计——那些当前商业 AI 产品中依赖人类专家手工打磨的东西——完全通过奖励信号端到端学习 没有任何人工干预,系统自己学会了什么时候调用谁、给什么信息、怎么综合结果
这件事的核心不是"小模型打败了大模型"。核心是:智能的差距可能不在于模型规模,而在于协调与指挥的能力。
我们这行一直有一个默认假设:更大的模型 = 更强的智能。参数越多越好,算力越多越好。Scaling Law 是信仰。
这篇论文在这个信仰上凿了一道裂缝。
第二件事:一年前的旧模型,在急诊室超过了人类医生
同一天,《科学》杂志发表了一项研究。
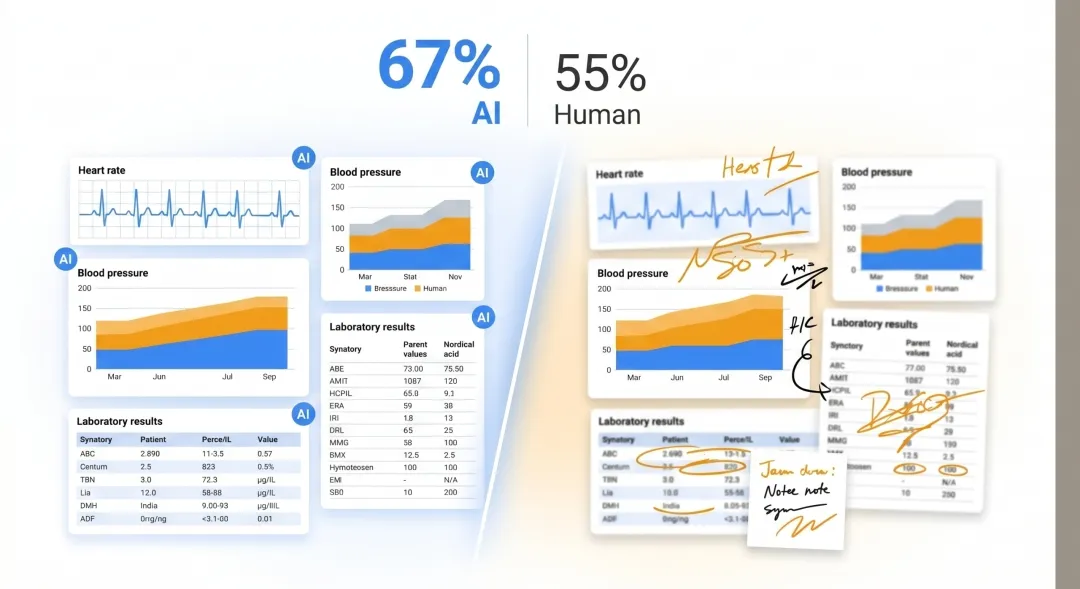
OpenAI 的 o1 模型——请注意,这是一年前发布的"旧模型"——在急诊诊断中表现优于人类医生。正确或接近正确诊断率 67%,而医生的这一数字是 50%–55%。
提醒一下,急诊诊断不是体检报告解读。它面对的是真实、混乱、信息不完整的临床数据。病人说不清哪里疼,检验结果还没出来,时间窗口以分钟计。
恰恰是在这种信息有限的早期分诊阶段,o1 的优势最明显。在结构化病例中,它的临床推理被研究者描述为"近乎完美"。
研究者还很克制地加了一句:当前模型可能更强。
重点不是"AI 又在一个领域超过了人类"。重点是:这是一个"旧模型"。按照 AI 行业的更新速度,它已经属于上一代产品。 但它依然超过了在这个领域训练了十几年的专业人士。
我们一直在讨论"AI 落地"的时间表。这篇论文给出的答案比大多数人预期的要早。不是在"未来几年"——是在现在。用着去年的模型。
第三件事:一个 7B 的中国模型,正在改造制造业工厂
第三个故事不在论文里,在车间里。
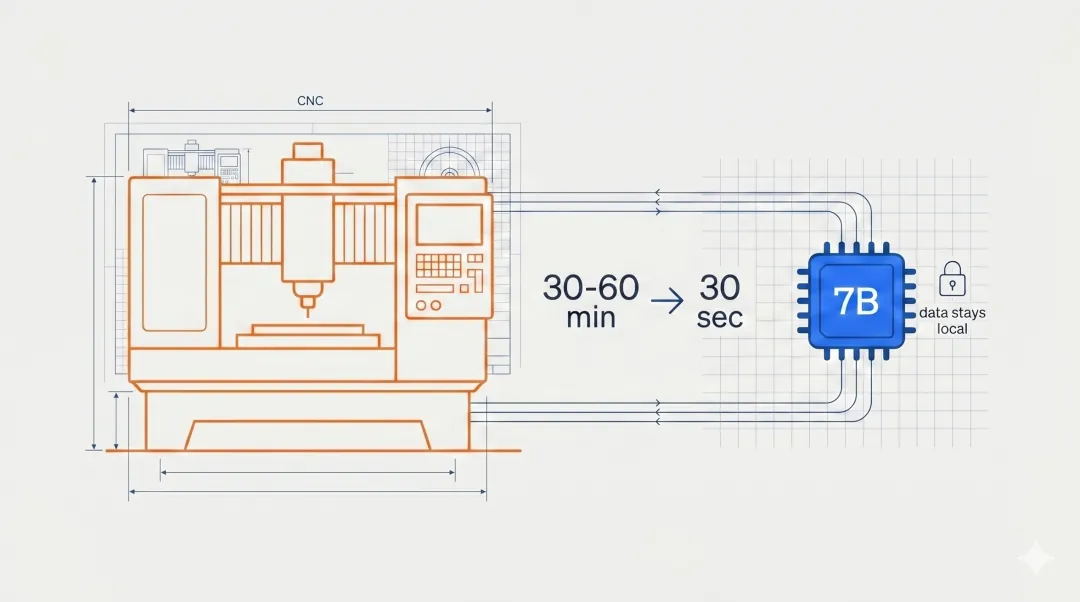
MachinaCheck,一个基于 AMD MI300X 加速卡和 Qwen 2.5 7B 模型构建的多智能体系统,正在革新小型 CNC 机加工车间的报价分析流程。
传统上,车间经理需要花 30–60 分钟手动分析一张图纸:这个零件能不能做?需要什么刀具?生产前要做什么准备?
MachinaCheck 把这个过程压缩到了 30 秒。上传 STEP 文件,输入材料和公差要求,系统自动生成完整的可制造性报告。
这件事的关键不在速度。在于两点:
- 用的是"小模型"
。Qwen 2.5 7B,不是 GPT-5,不是 Claude Sonnet 4。一个开源的、可以在本地跑的 7B 模型。 - 数据不离开工厂
。AMD MI300X 的 192GB HBM3 显存确保客户设计数据全在本地处理。对制造业来说,数据隐私不是锦上添花,是准入门槛。
这个故事和前两个故事共享同一个逻辑:解决真问题,不需要最大的模型。 7B 够用了。关键是把它放进正确的系统架构里。
三条线,一个结论
现在把这三件事放在一起看。
它们发生在同一天。来自不同的团队,解决不同的问题,用的是不同的模型和芯片。但它们共同瓦解了 AI 行业一个根深蒂固的信仰:
更大的模型 = 更强的能力。
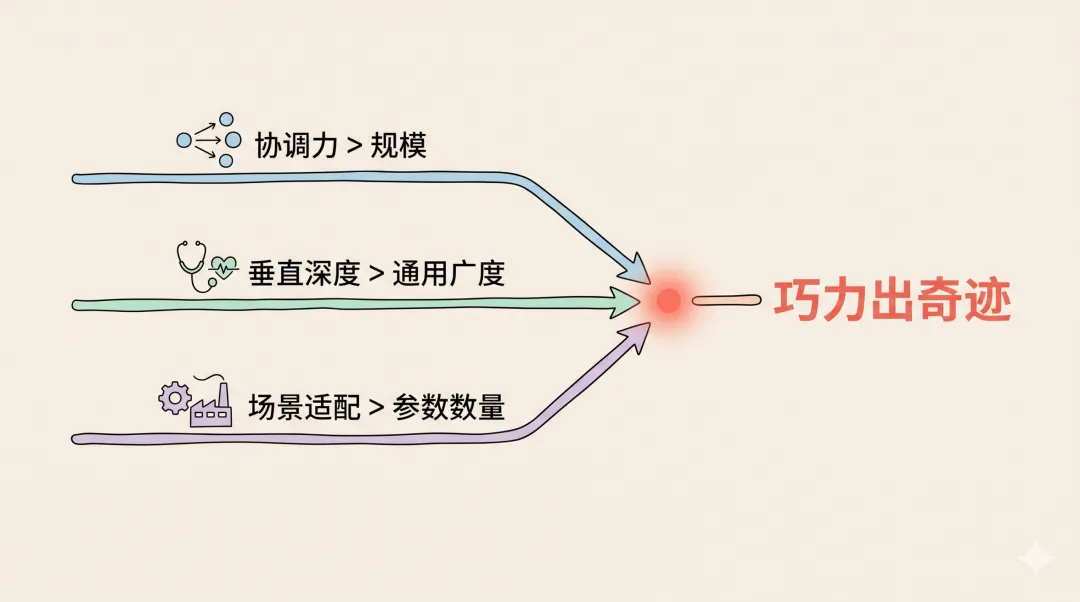
7B 小模型指挥大模型集群,在硬核基准上超越任何一个单独的大模型——说明协调力 > 规模。
旧版 o1 在急诊诊断中超越人类医生——说明垂直深度 > 通用广度。
Qwen 2.5 7B + AMD 芯片在制造业车间里 30 秒出报告——说明场景适配 > 参数数量。
这三条线汇在一起,指向同一个方向:AI 行业正在从"大力出奇迹"的阶段,进入"巧力出奇迹"的阶段。
Scaling Law 没有失效,但它不再是唯一的答案。甚至不是最好的答案。
范式转折的四个信号
如果你仔细看,这个转折不是今天才开始。2026 年 5 月 11 日的这三件事,是已经积累了一段时间的信号集中爆发。往前翻:
- DeepSeek V4 Pro
在 Pareto Code 的市场需求数据中占据首位——不是靠最大的参数规模,是靠成本效益和场景匹配 - Anthropic
不靠补贴、不靠价格战,靠产品力拿下令牌份额第一——Claude 的竞争优势不在"最大",在"最好用" - 中国移动 MoMA
接入 300+ 模型,国家队把"模型中转"当成基础设施做——暗含的判断是:未来不会有"一个模型统治一切"
把这些碎片拼在一起,画面很清楚:
"大模型"这三个字,正在从一个技术标准变成一个营销概念。真正在解决问题的人,已经不关心你的模型有多少参数了。
对中国 AI 的隐含意义
如果你是中国 AI 行业的从业者或观察者,今天这三件事有一个额外的信息:
对"小模型"友好 = 对中国 AI 友好。
这不是口号。是技术约束下的理性推论。
中国 AI 公司长期面临两个约束:芯片禁令限制了大算力训练,价格战压缩了利润空间。在一个"越大越好"的世界里,这两个约束是致命的。但如果你相信"协调力 > 规模"、"垂直深度 > 通用广度"、"场景适配 > 参数数量"——那这两个约束反而成了聚焦的理由。
MachinaCheck 用的是中国模型(Qwen 2.5)和非英伟达芯片(AMD MI300X)。7B 小模型指挥大模型的论文来自中国团队(AntLingAGI 也在做类似架构)。DeepSeek 用成本效率在全球市场撕开了一道口子。
当全球 AI 竞赛的规则从"谁模型大谁赢"变成"谁用得好谁赢",中国公司的游戏空间突然变大了。
这不是说芯片不重要了。芯片依然重要。但芯片不再是唯一重要的事了。
一个行业的集体转向
一天之内,三个独立的证据点,从学术论文到顶级期刊到制造业车间,同时宣告了同一件事。
这不是巧合。这是量变到了质变。
AI 行业的第一个十年是关于能不能造出更大的模型。第二个十年——或许从今天开始——将转向能不能用好已有的模型。
7B 干了 GPT-5 干不了的事。
旧模型救了新病人。
小芯片跑了整个车间。
2026 年 5 月 11 日。这个日期或许值得记住。在这一天,三件事同时指向一个可能性:大力出奇迹——但大力不是唯一的答案。
