 夜雨聆风
夜雨聆风前几天我和一位做 AI 的朋友讨论Agent的记忆。
我:“你们在用Agent的时候,怎么考虑它的记忆问题?”
他:“我们把聊天记录存起来,下次再塞回上下文。”
我:“你们是不是还需要一些背景知识呢?”
他:“那就用RAG啊。”
这个回答也不能说错,RAG+prompt,可能是大部分人的选择。
但它只解决了最浅的一层问题。把历史记录存下来,不等于 Agent 有记忆;把历史记录全塞回 prompt,也不等于 Agent 会正确使用记忆。
真正的问题是:Agent 要记住什么,什么时候写入,什么时候取出,怎么避免记错、记重复、记过期,以及怎么控制 token、延迟、隐私和权限。
我们以目前最火的开源 Agent 记忆方案 Mem0 为例,来拆解一下,看看如何让你的AI具备好的记性?
Mem0 的 GitHub 仓库现在大约 55k stars,Apache-2.0 开源,官方定位是 “Universal memory layer for AI Agents”。它不是唯一方案,但很适合作为理解 Agent 记忆系统的切入口。
首先明确:Agent 为什么需要记忆?

图 1:Agent 记忆不是保存聊天记录,而是抽取可复用上下文。
Agent 记忆的价值,不是让模型“多知道一点历史”,而是让它在多次交互、多次任务、多天甚至多月之后,仍然能保持连续性。
如果一个用户已经说过“我不喜欢太营销化的表达”,下一次让 Agent 写公众号文章时,它最好自动避开浮夸话术。如果一个客户上周已经确认过预算范围,销售 Agent 不应该今天又从零开始问一遍。如果一个代码 Agent 已经知道项目里不能引入某个依赖,它后面改代码时就不应该反复犯同样的错。
没有记忆的 Agent,更像一次性问答工具。它可以很聪明,但每次都从零开始。全量上下文方案看似简单,把历史聊天全部塞进去就行,但上下文越长,成本和延迟越高,模型也未必能从几十页历史中稳定抓住关键事实。
所以生产级记忆系统的目标,是把历史压缩成可用的任务上下文:只保留值得复用的事实、偏好、关系、状态和约束,并在需要时精准召回。
什么才算 Agent 记忆?
很多系统会把“聊天记录”“知识库”“缓存”“用户画像”都叫记忆,但它们不是一回事。
聊天记录是原始历史,适合审计和回放,但不适合每次都原样喂给模型。知识库是稳定知识,适合回答公司制度、产品文档、API 说明,但它通常不记录某个用户在长期互动中的偏好变化。缓存解决的是重复计算和性能问题,不等于长期记忆。用户画像更接近业务系统里的结构化档案,适合保存确定字段,但灵活性不如从对话中动态抽取的记忆。
Agent 记忆更像一层中间系统:它从交互中抽取可复用事实,把它们结构化、向量化、打标签,并在未来任务中按相关性取回来。好的记忆系统不是“什么都记”,而是知道哪些东西值得记、怎么记、何时忘、谁能看、什么时候不能用。
Mem0 的好处是什么?
选择 Mem0,不是因为它一定是所有场景的最优解,而是因为它抓住了 Agent 记忆系统里最关键的工程矛盾:准确性、成本和延迟很难同时做好。
Mem0 官方 README 显示,它提供 Python 和 TypeScript SDK,也支持自托管 server 和云平台。官方文档把它描述为一套持久、上下文化的记忆层,核心方式是用 LLM 从对话中抽取重要信息,再通过向量存储做语义检索。它还支持 Graph Memory,把人物、地点、事件和关系存成图结构,用来弥补纯向量检索对复杂关系的表达不足。
更重要的是,Mem0 不是只停留在“把对话写入向量库”的层面。它的文档里把记忆系统拆成写入和读取两个阶段:写入时做事实抽取、去重、embedding 和实体链接;读取时用语义搜索、关键词搜索和实体搜索多信号融合,最后把最相关的记忆注入上下文。
Mem0 的核心流程
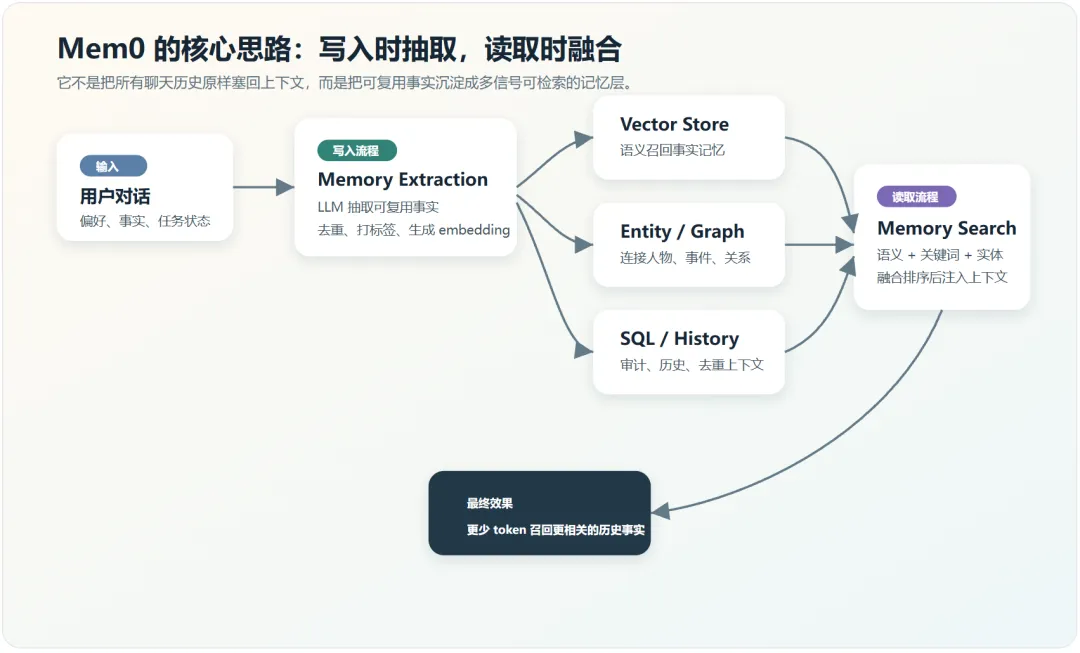
图 2:Mem0 的写入、存储、检索和注入流程。
Mem0 的写入流程可以理解成“把对话变成记忆”。用户和 Agent 交互后,系统不会简单保存整段聊天,而是通过 LLM 抽取其中值得长期保留的事实,例如用户偏好、已确认的决策、长期约束、项目背景、人与事件的关系。随后系统会对这些事实去重、生成 embedding、打上用户或 agent 相关的 metadata,并保存到后端存储中。
它的读取流程可以理解成“把记忆变回上下文”。当用户发起新任务时,Mem0 会根据当前 query 搜索相关记忆。官方文档提到,新算法会并行使用语义搜索、BM25 关键词搜索和实体搜索,再融合排序得到最终 top-K。这样做的好处是不同类型的问题可以走不同信号:概念类问题更依赖语义,相对精确的事实查询更依赖关键词,围绕人名、项目名、组织名的问题则更依赖实体链接。
这个设计比普通 RAG 更贴近 Agent 记忆。RAG 通常检索的是静态文档,而 Agent 记忆检索的是用户与系统长期互动中沉淀出来的事实。两者都用检索,但检索对象和更新方式完全不同。
Mem0 的架构亮点
Mem0 最值得学习的不是某个 API,而是它把记忆分成了几个层次。第一层是事实记忆,它把对话中稳定、可复用的信息抽出来,而不是把聊天全文当作记忆。第二层是实体和关系,Graph Memory 可以把人物、项目、地点、事件之间的关系显式记录下来。第三层是历史和审计,记录什么时候写入了什么记忆、为什么写入、后面有没有变更。第四层是检索融合,把语义、关键词和实体信号合并,减少单一检索方式的盲点。
什么时候适合用 Mem0?
如果你的 Agent 需要跨会话持续理解用户,Mem0 很适合。典型场景包括个人助理、客服助手、销售助手、学习助手、AI coding assistant、长期项目管理 Agent。它们共同的特点是:同一个用户或同一个项目会反复出现,历史偏好和已确认事实会影响未来决策。
如果你的系统现在靠“最近 N 条聊天记录”维持上下文,也很适合引入 Mem0。最近消息只能覆盖短期上下文,无法稳定保留长期偏好和跨会话事实。Mem0 可以把短期对话蒸馏成长期记忆,再按需召回。
如果你的成本压力很明显,也值得考虑这类方案。全量上下文方案会随着历史增长不断变贵,而选择性记忆的目标是用更少 token 召回更有用的信息。Mem0 官方文档和论文都强调 token efficiency,把准确性、成本和延迟放在一起评估,这个方向是对的。
什么时候不要急着上 Mem0?
不是所有 Agent 都需要长期记忆。如果你的任务是一次性的,比如“把这份 PDF 总结一下”“根据这份会议纪要生成待办”“查询一次库存并返回结果”,那普通上下文加临时状态就够了。为了这类任务引入长期记忆,会增加不必要的复杂度。
如果你的知识主要来自稳定文档,比如公司制度、产品手册、接口文档,优先做 RAG,而不是 Agent memory。RAG 解决“系统知道什么知识”,记忆解决“系统记得这个用户或这个任务过去发生过什么”。两者可以结合,但不要混用概念。
如果你的业务对隐私、合规和删除权要求很高,也不能只看 Mem0 的 API 好不好用。你要先设计数据边界:哪些内容可以被写成记忆,哪些必须脱敏,用户能否查看、修改、删除自己的记忆,不同 agent、不同租户、不同团队之间是否隔离。
Mem0 和 RAG 有什么区别?
很多人会把 Mem0 理解成“一个带抽取的向量库”,这不够准确。RAG 的核心对象通常是文档,文档相对稳定,更新频率低,权限边界比较清楚。Agent 记忆的核心对象是互动中产生的事实,它会持续变化,带有强用户属性、强时间属性和强上下文属性。
所以更准确的关系是:RAG 是知识检索,Memory 是经历检索。前者让 Agent 读资料,后者让 Agent 记住共同经历。
记忆系统真正难在哪里?
Agent 记忆最难的地方不是存储,而是治理。记忆会错,LLM 可能把临时偏好当成长期偏好,把猜测当成事实,把 Agent 自己生成的内容当成用户确认过的信息。记忆也会过期,用户偏好、项目状态、客户预算、团队成员都会变化。记忆还可能越权,一个 agent 记住的信息不一定应该给另一个 agent 用,一个客户的敏感信息更不能跨租户召回。
更重要的是,记忆会影响行为。如果 Agent 记错了“用户喜欢激进投资”,后续投研或理财建议就可能偏离风险偏好。越是高风险场景,越要给用户查看、纠正和删除记忆的入口。
怎么把 Mem0 用到自己的 Agent 里?
比较稳的接入方式,是先不要让记忆系统直接控制关键业务动作,而是先作为上下文增强层。第一步,在低风险场景里记录用户偏好和项目背景,例如文章风格偏好、常用技术栈、项目约束、客户沟通习惯。第二步,把 memory write 放到任务结束后,而不是每句话都实时写。第三步,在 memory read 时明确区分“记忆”和“当前输入”,让模型结合当前用户输入判断历史记忆是否适用。
第四步,给记忆加 metadata,至少要有 user_id、agent_id、project_id、source、created_at、confidence、scope。第五步,做可见和可改,用户应该能看到系统记住了什么,也能删除或修正。
现有记忆方案怎么选?
如果只做一次性任务,用短期上下文就够了。如果主要问题是“读公司知识库”,优先做 RAG。如果需要跨会话记住用户偏好、项目背景和长期约束,Mem0 这类选择性长期记忆方案就很合适。如果任务里有很多人、组织、事件、时间线和关系推理,就要考虑图记忆。如果已经进入金融、医疗、企业合规或强权限场景,就要在 Mem0 或其他框架之上补自研治理层。
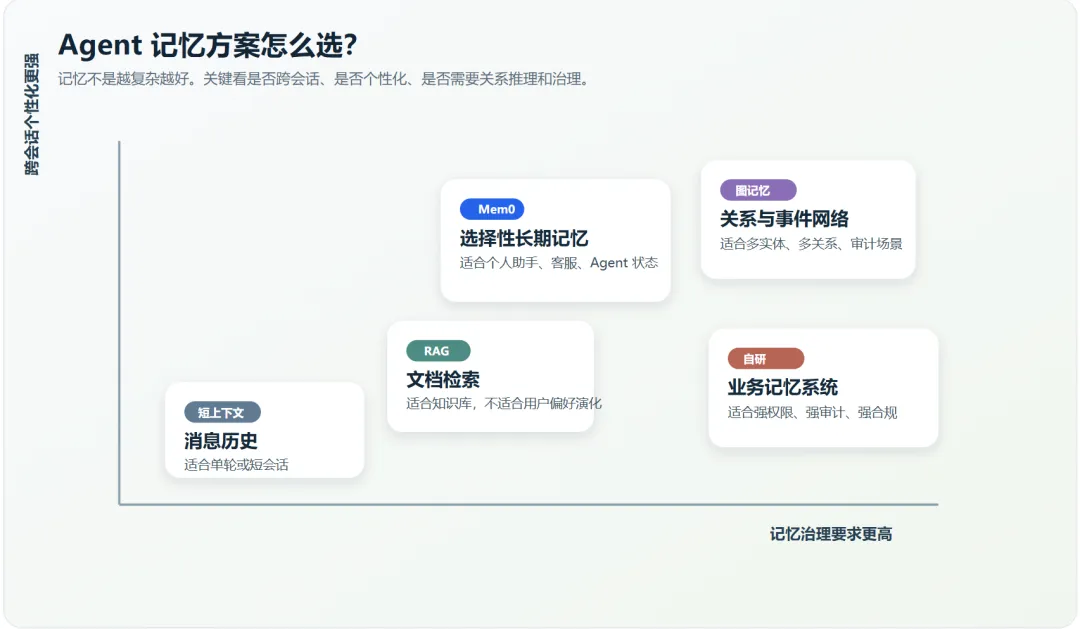
图 3:Agent 记忆方案选型。
写在最后:真正有用的记忆是怎样的
Agent 记忆不是“把聊天记录存起来”,也不是“把历史全塞进 prompt”。真正有用的记忆,是从历史中抽取可复用事实,在未来任务中按需召回,同时接受权限、时间、冲突、删除和审计的约束。
我们今天介绍的Mem0 的价值,在于它把 Agent 记忆从一个简单向量库问题,推进到了“写入抽取 + 多层存储 + 多信号检索 + 图关系增强”的工程系统。它很适合需要长期个性化和跨会话连续性的 Agent,但它不是合规、权限和业务治理的替代品。
总结:如果 Agent 只是完成一次任务,不需要更长久的记忆;如果 Agent 要长期服务同一个人、同一个客户或同一个项目,记忆就会变成核心基础设施。Mem0 是目前最值得研究和试用的开源方案之一,但上线前一定要补上自己的权限、审计、冲突处理和用户可控机制。
