 夜雨聆风
夜雨聆风选 GPT-4 还是 Claude?这个问题本身可能就是错的。
1
第一幕:效率幻觉——你以为选对了模型
2026 年初,某 AI 初创公司的技术负责人拉出了一份 API 账单:每月 GPT-4 花费 5 万美元。他逐条分析了请求日志,发现 80% 的查询其实是"今天天气怎么样"、"帮我翻译这句话"这类日常任务——GPT-4o-mini 就能搞定。
这不是个案。Switchcraft(一个专门为 Agent 工具调用设计的模型路由器)的论文里有一个关键洞察:
"Larger models do not consistently outperform smaller ones on tool-use tasks." "更大的模型并不总是比小模型在工具使用任务上表现更好。"
这句话指向一个普遍现象:在工具调用(tool calling)这类任务中,GPT-4 的表现可能和 GPT-4o-mini 差不多,但成本高出几十倍。
为什么开发者还是默认选大模型?信息不对称。你不知道哪个模型在你的具体任务上表现如何,所以"选最贵的"成了最安全的策略。
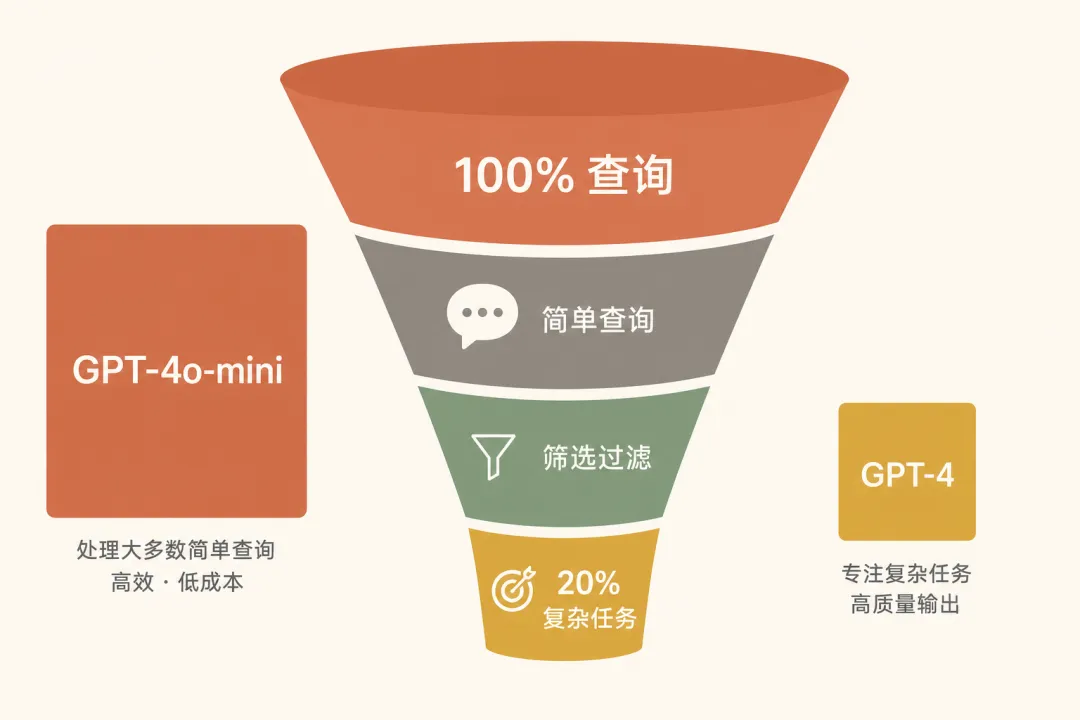
FrugalGPT(斯坦福大学 2023 年的论文)给出了一个量化视角:商业 LLM API 的定价差异可达两个数量级。GPT-4 和 GPT-3.5-turbo 之间的价格差是 20-30 倍。如果你的应用有 80% 的简单查询和 20% 的复杂查询,全部用 GPT-4 就是在为那 80% 的简单任务多付 20 倍的钱。
问题的核心不是"选哪个模型",而是"为每个查询选最合适的模型"。
这个思路转变,催生了一个新的技术领域:AI 模型路由(Model Routing)。
2
3
第二幕:从"选一个"到"用对的"——模型路由的诞生
3.1
FrugalGPT:第一个系统性框架(2023)
2023 年 5 月,斯坦福大学的 Lingjiao Chen、Matei Zaharia 和 James Zou 发表了 FrugalGPT,这是第一个系统性地研究"如何在大规模使用 LLM 时降低成本"的论文。
他们提出了三种策略:
Prompt 适应(Prompt Adaptation)——修改提示词,让它在更便宜的模型上也能工作 LLM 近似(LLM Approximation)——用更便宜的模型近似昂贵模型的输出 LLM 级联(LLM Cascade)——按从便宜到贵的顺序查询模型,在置信度足够时停止
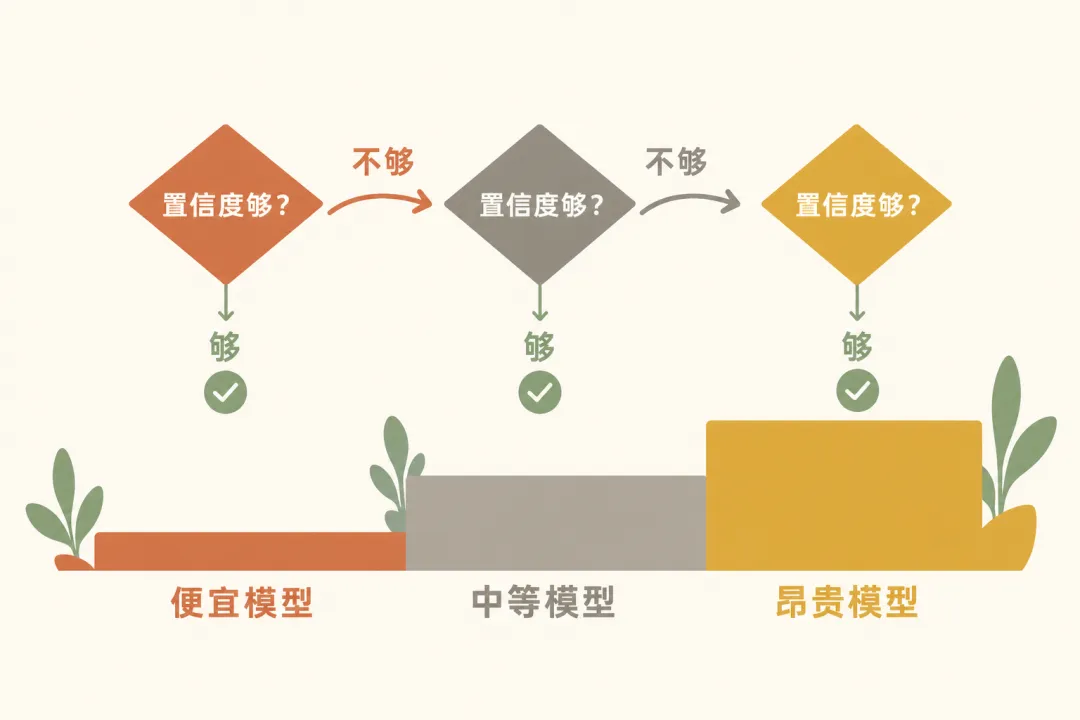
其中最有影响力的是级联策略。想象一个漏斗:所有查询先经过最便宜的模型,如果这个模型"不确定"自己的答案,就把查询升级到更贵的模型。只有真正复杂的查询才会到达最昂贵的模型。
FrugalGPT 的实验结果:匹配 GPT-4 的性能,成本降低 98%。或者在相同成本下,准确率比 GPT-4 提高 4%。
但 FrugalGPT 有一个局限:它需要预先知道每个模型在每种查询上的表现。在实践中,这意味着你需要大量的标注数据来训练路由策略。
3.2
RouteLLM:用偏好数据训练路由器(2024)
2024 年 6 月,LMSYS(Large Model Systems Organization,Chatbot Arena 的创建者)和加州大学伯克利分校的团队发表了 RouteLLM,将模型路由推向了实用化。
RouteLLM 的核心创新是:利用人类偏好数据训练路由器。
Chatbot Arena 积累了大量人类对模型输出的偏好数据("哪个回答更好?")。RouteLLM 利用这些数据训练路由器,让它学会判断:"对于这个查询,强模型比弱模型好多少?"
RouteLLM 提供了五种路由器实现:
mf | 推荐 | |
sw_ranking | ||
bert | ||
causal_llm | ||
random |
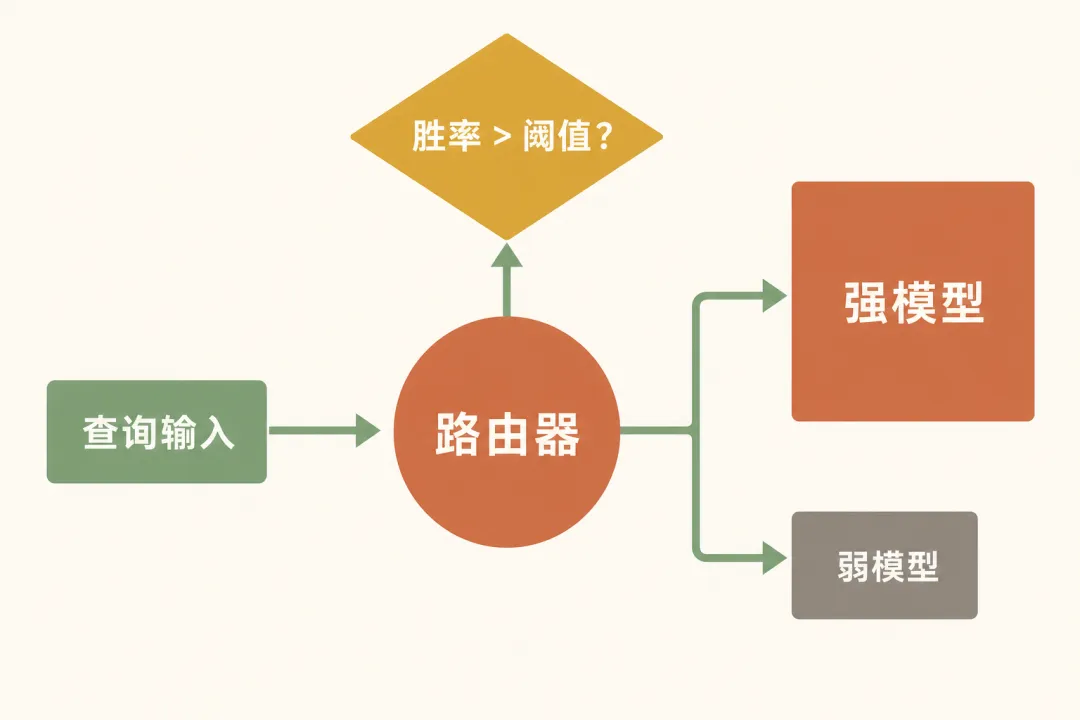
路由器的工作原理很简单:对于每个查询,计算"强模型的胜率"。如果这个胜率高于你设定的成本阈值,就把查询路由到强模型;否则路由到弱模型。
一个关键发现是:路由器具有强迁移学习能力。即使你在 GPT-4 vs Claude 之间训练路由器,然后在测试时换成 GPT-4 vs Gemini,路由器仍然有效。这意味着你不需要为每对模型重新训练路由器。
RouteLLM 的评估结果显示:在某些场景下,成本降低超过 2 倍,同时不牺牲输出质量。
开源的 RouteLLM 框架(GitHub: lm-sys/routellm)让任何人都可以搭建自己的模型路由器。你只需要定义"强模型"和"弱模型",提供偏好数据,就能训练出一个路由器。
4
5
第三幕:Agent 时代的新挑战——Switchcraft 的启示
2026 年 5 月,Switchcraft 论文的发表标志着模型路由进入了新阶段:专门为 Agent 场景设计。
5.1
为什么 Agent 让模型选择更难?
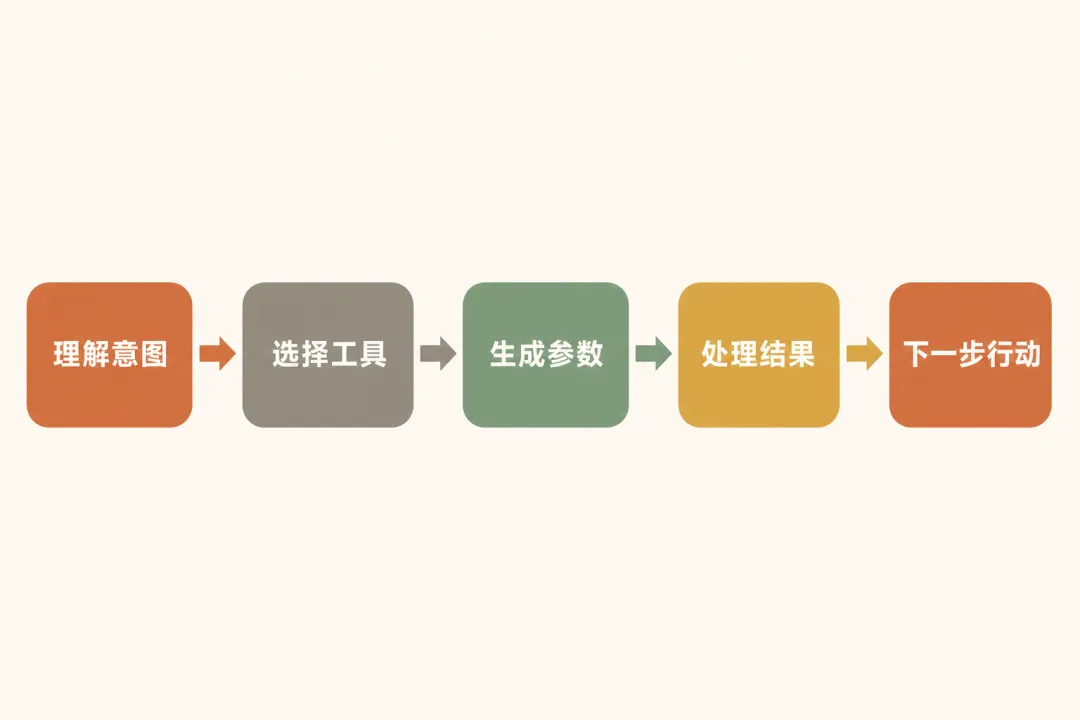
传统 LLM 应用是"一问一答"——用户问,模型答。Agent 场景不同:模型需要理解意图、选择工具、生成调用参数、处理返回结果、决定下一步行动。这是多步骤、多工具的流程。
 在这种场景下,模型选择变得更加微妙:
在这种场景下,模型选择变得更加微妙:
不同步骤需要不同能力:理解意图可能需要强推理能力,但生成 API 参数可能只需要模式匹配能力 token 消耗差异巨大:强模型的推理 token(reasoning tokens)可能是弱模型的 5-10 倍 错误成本不对称:工具调用错误的后果比普通对话错误严重得多
5.2
Switchcraft 的三个关键发现
发现一:"更大的模型并不总是比小模型在工具使用任务上表现更好。"
这和直觉完全相反。但在工具调用任务中,模型需要的是"精确执行"而非"深度思考"。小模型在模式匹配和参数生成上的表现可能和大模型相当,但成本低得多。
发现二:"名义上更便宜的模型可能因 token 密集型推理而产生更高的总成本。"
价格标签写的是"每 1M token $0.5 vs $15",但实际成本还包括推理 token 的消耗。如果一个"便宜"模型需要生成大量推理 token 才能完成任务,总成本可能反而更高。
发现三:82.9% 准确率 + 84% 成本降低。
Switchcraft 基于 DistilBERT(一个轻量级 BERT 变体)构建路由器,在 5 个函数调用基准测试上达到了 82.9% 的准确率——匹配或超过最佳单个模型。同时,推理成本降低了 84%,每百万查询节省超过 $3,600。
5.3
路由器本身必须足够轻
Switchcraft 有一个工程约束:路由器必须在延迟预算内运行。用大模型来决定用哪个模型,本身就违背了成本优化的目的。
DistilBERT 是一个仅 6600 万参数的模型,推理速度极快。它可以在毫秒级完成路由决策,几乎不增加端到端延迟。
6
第四幕:五种路由范式——从简单到复杂
综合 FrugalGPT、RouteLLM、Switchcraft 和 Anthropic 的实践经验,模型路由已经发展出五种主要范式:
6.1
1. 级联(Cascading)——最简单的起点
查询先经过最便宜的模型,置信度不够就升级到更贵的模型。实现简单,无需训练数据,适合刚起步的团队。缺点是延迟高——可能需要多次 API 调用。
Anthropic 的建议是直接用这个思路:"将简单/常见问题路由到更小、更经济的模型(如 Claude Haiku 4.5),将困难/罕见问题路由到更强大的模型(如 Claude Sonnet 4.5)。"
6.2
2. 学习型路由器(Learned Router)——最成熟的方案
训练一个分类器(如 BERT、矩阵分解),预测每个查询应该用哪个模型。快速、准确率高、可迁移。缺点是需要偏好数据(Chatbot Arena 风格的标注)。
代表是 RouteLLM,提供 5 种路由器实现。适合有大量查询历史数据的团队。
6.3
3. 任务感知路由(Task-Aware)——Agent 场景最优
根据任务类型(工具调用、代码生成、文本摘要)路由到专门优化的模型。针对特定场景效果最好,但需要任务分类逻辑。
代表是 Switchcraft,专门为 Agent 工具调用设计。
6.4
4. 置信度路由(Confidence-Based)
根据模型对自己答案的置信度决定是否升级。自适应,不需要预定义任务类型。但置信度校准是开放问题——模型经常"过度自信"。
6.5
5. 工作流路由(Workflow)
将输入分类,引导到专门的下游任务,每个任务有独立的提示和模型配置。关注点分离,但架构复杂度高。Anthropic 在"Building Effective Agents"中推荐了这种模式。
7

8
第五幕:生产环境的现实——谁在用模型路由?
8.1
OpenRouter:统一 API + 自动路由
OpenRouter 提供了一个统一的 API 层,可以访问来自 OpenAI、Anthropic、Google、Meta、Mistral 等多家提供商的数百个模型。它的核心功能包括:
自动路由: auto模型关键词让 OpenRouter 根据提示动态选择最佳模型故障转移:如果一个提供商宕机,自动切换到备用提供商 成本透明:显示每个上游提供商的每 token 价格
8.2
Martian:$950 万融资的模型路由创业公司
Martian(由 Manvitha Ponnapati 和 Emily Gorsinsky 创立)在 2024 年获得了 $950 万种子轮融资(Lightspeed Venture Partners 领投)。他们的核心产品是一个智能模型路由层,帮助企业根据成本、延迟和质量动态选择最优模型。
Martian 的价值主张很直接:帮助企业在不牺牲质量的情况下将 LLM 成本降低 50% 以上。
8.3
RouteLLM:开源路由器框架
RouteLLM 是目前最成熟的开源模型路由框架。它提供了:
5 种路由器实现(矩阵分解、BERT、因果 LLM 等) 完整的评估框架,支持多个基准测试 阈值校准工具,帮助你找到成本和质量的最佳平衡点 28 个代码示例,开箱即用
8.4
企业实践:什么时候值得自建路由器?
9
第六幕:决策框架——你的团队该怎么选?
9.1
简单决策树
1你的场景是什么?
2├── 日常对话/简单任务
3│ └── 直接用小模型(Haiku/GPT-4o-mini),不需要路由
4├── 混合任务(简单+复杂)
5│ ├── 有偏好数据?→ 学习型路由器(RouteLLM)
6│ └── 没有偏好数据?→ 级联策略(先便宜后贵)
7├── Agent 工具调用
8│ └── 任务感知路由(Switchcraft 方案)
9└── 复杂多任务系统
10 └── 工作流路由(Anthropic 方案)+ 学习型路由器
11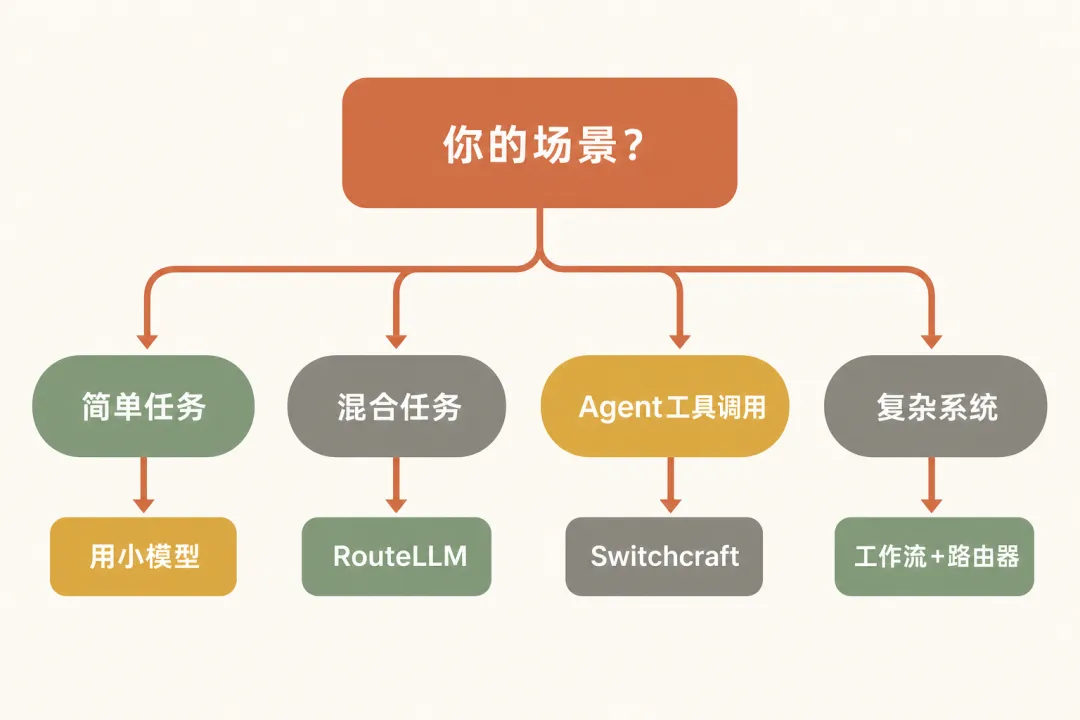
9.2
成本估算:路由能省多少钱?
假设你的应用有 100 万次查询/月,混合使用 GPT-4 和 GPT-4o-mini:
| 67%-80% | |||
| 83%-90% | |||
| 33%-50% |
(实际节省取决于查询分布和具体模型定价,上述为估算值)
9.3
避坑指南
不要过度路由——如果 90% 的查询都是简单任务,直接全用小模型就好。级联策略会增加延迟,学习型路由器延迟更低。模型在不断更新,今天的最优路由策略明天可能就过时了。还有一个容易忽略的点:不要只看"每 1M token 价格",要算实际的 token 消耗量。
10
结尾:从"能用"到"用好"
模型路由不是什么高深的技术。它的核心思想可以用一句话概括:简单问题用小模型,复杂问题用大模型。
Anthropic 在《Building Effective Agents》中写道:
"找到尽可能简单的解决方案,只在需要时增加复杂性。"
对于大多数团队来说,最简单的路由策略可能就足够了。你不需要一开始就搭建复杂的路由器,但你需要有这个意识:一个模型不够用,你需要的不是"选一个最好的",而是"为每个查询选最合适的"。
未来,模型路由会成为 AI 基础设施的标准组件,就像 CDN 之于 Web 一样——用户不需要知道内容从哪个服务器加载,但系统会自动选择最快、最便宜、最可靠的节点。
