夜雨聆风
夜雨聆风

烩设计导读
本周三条重磅,条条都在问同一个问题:设计师的创作边界,到底在哪里?
①商汤SenseNova-U1把图文混排做到了"一个模型全搞定";
②SpAItial Echo-2让你拍张照片就能生成能走进去的3D世界;
③Netflix Vista4D直接把视频后期改写成"想怎么改就怎么改"——从设计素材生成,到3D场景构建,再到视频后期创作,AI正在把设计师的"能力边界"一步步往外推。
问题是:边界推到哪里才是个头?
热点一
商汤开源SenseNova-U1,一个模型同时搞定"看懂图"+"画图"+"图文混排"

核心事件:
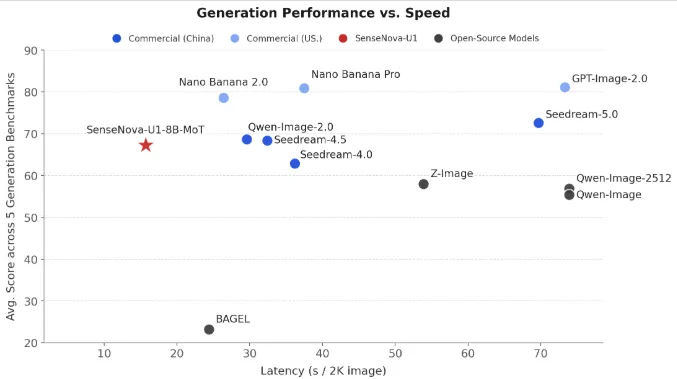
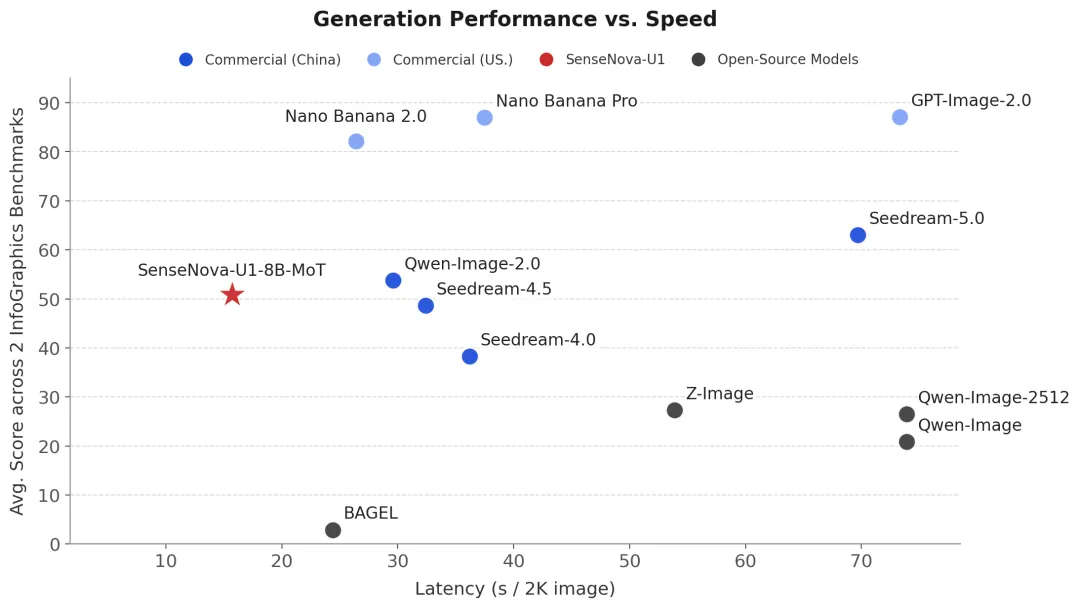
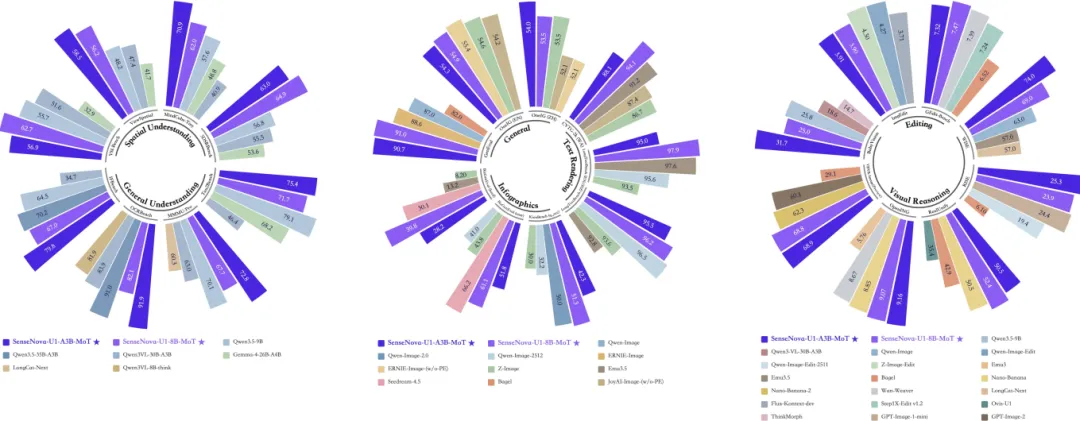
4月29日,被美国列入实体清单的商汤科技(SenseTime)正式开源SenseNova-U1系列模型——这是全球首个真正实现"视觉理解+视觉推理+视觉生成"三合一的开源模型,被称为图文混排领域的SOTA王者。
核心突破:
① 真正统一的多模态架构
不同于以往"理解归理解、生成归生成"的拼接式方案,SenseNova-U1基于商汤自研的NEO-Unify架构,从底层就将图像理解和生成统一在一个模型里。这意味着:模型不只是"会生成图片",它真的"看得懂"你在做什么。
② 全球最强开源图像质量
据商汤官方技术报告,SenseNova-U1生成的图像质量,在所有开源模型中排名第一。无论是写实风格还是艺术风格,图像清晰度、细节还原度都大幅超越同类开源模型。
③ 真正的文字渲染能力
开源模型长期存在的痛点——"图里的文字全是乱码"。SenseNova-U1解决了这个问题,中文、英文、艺术字都可以精准渲染到图片里,图文混排从此不再需要后期PS。
④ 轻量高效,国产芯片也能跑
SenseNova-U1已适配中国国产AI芯片(如华为昇腾),在受到美国芯片管制的情况下,商汤证明了"顶级AI模型可以在中国芯片上运行"。





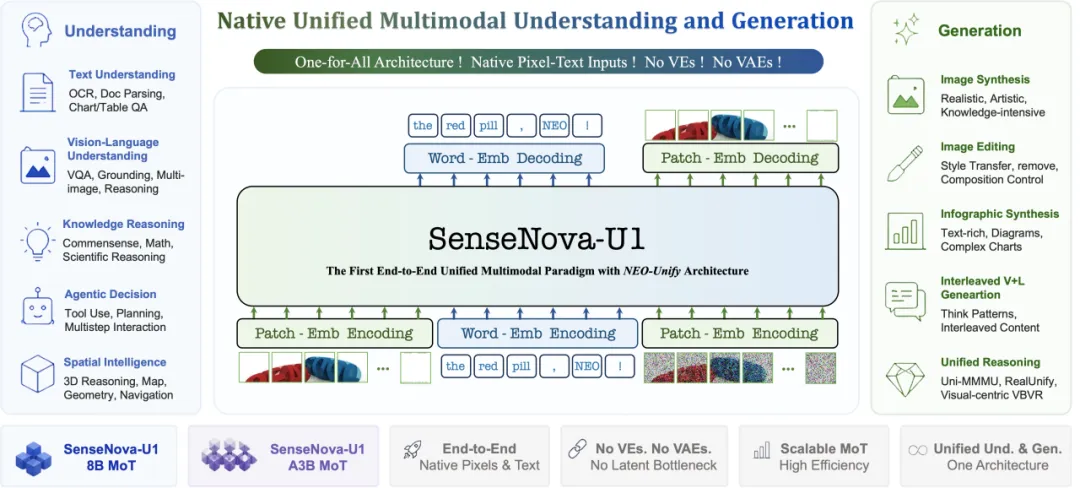
技术细节:
无VAE、无扩散:SenseNova-U1直接摒弃了传统图像生成模型的VAE编码器和扩散过程,架构更简洁,生成速度更快
原生多模态:图像和文本在模型内部以统一方式处理,不像传统方案那样需要在"理解模型"和"生成模型"之间做格式转换
支持视觉推理:不仅能生成图片,还能对图片进行复杂推理——比如"这张设计稿的颜色搭配有什么问题?"
设计师的实战价值:
对于品牌设计师来说,SenseNova-U1最实用的场景是图文海报生成:你只需要描述"主视觉是蓝绿渐变、标题在左上角、右侧放产品图、底部要有联系电话"——它就能生成一张可以直接用的海报,不需要再打开Photoshop手动排版。

对设计师意味着什么?
图文混排从此"一句话搞定"。但这也意味着:文字排版能力的重要性进一步下降,创意和审美能力的重要性进一步上升——因为AI帮你做排版,你得告诉它"什么样的排版是好的"。
热点二
SpAItial Echo-2发布,拍张照片就能生成能交互的3D世界

核心事件:
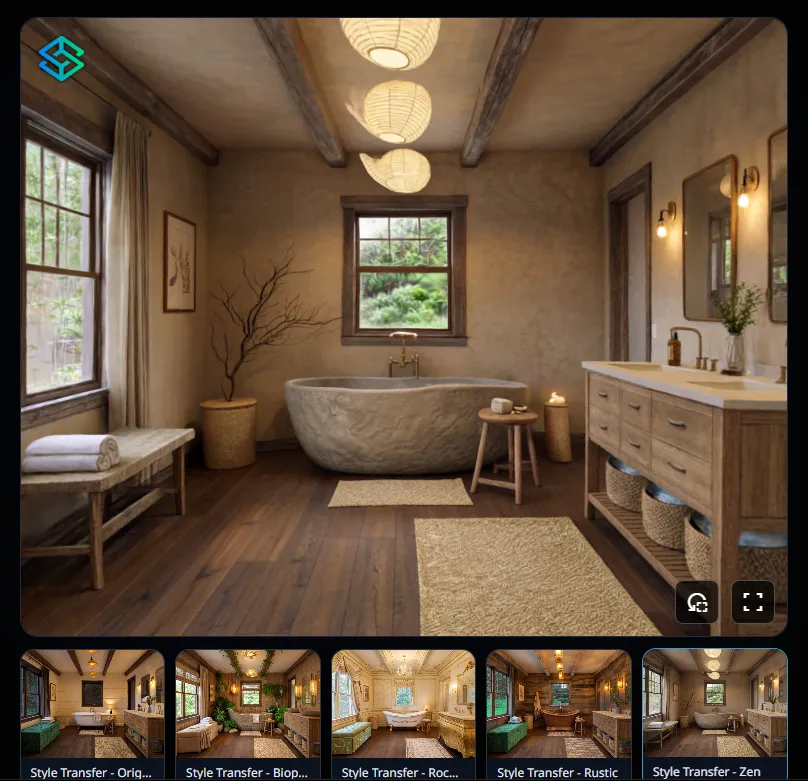
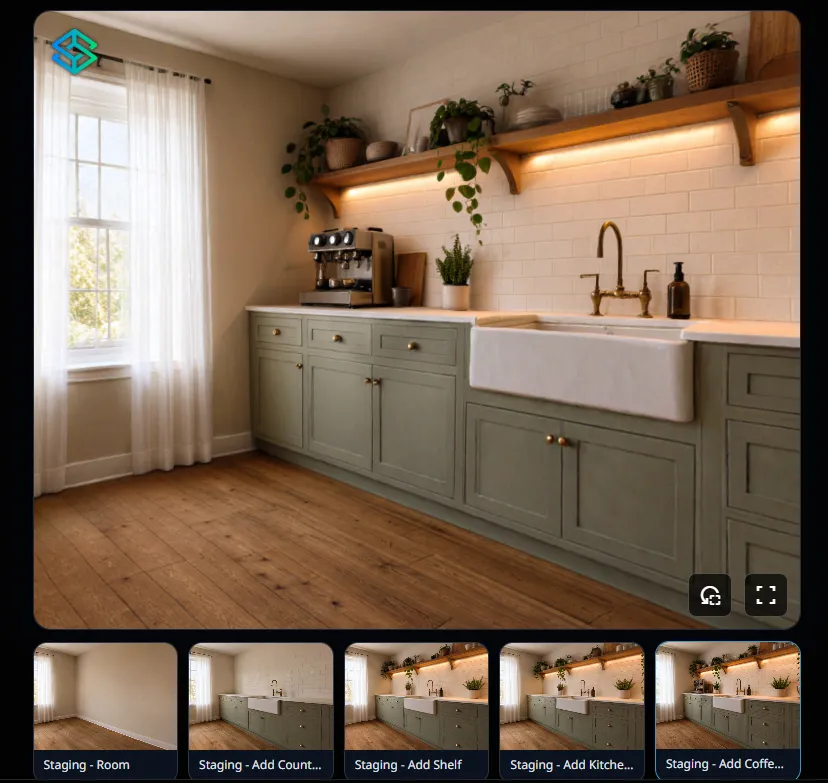
4月27日-29日,AI空间智能公司SpAItial发布Echo-2世界模型——只需上传一张照片,AI就能生成一个完整的、可360度漫游的、带有物理规则约束的3D交互场景。
点击播放
核心能力:
① 拍一张图,生成一个世界
上传一张房间照片,Echo-2可以在几秒钟内生成这个房间的完整3D数字孪生——包括空间结构、物件位置、光照方向、材质质感,全部自动推算出来。
② 物理规则约束,场景真实可信
与普通图像生成不同,Echo-2生成的3D场景遵循物理规则——物体有正确的遮挡关系、光影投射符合现实规律、物体之间有合理的空间层次。这意味着生成的场景不会"穿帮",可以直接用于设计展示。
③ 可漫游、可交互
生成的3D场景不是静态图片,而是可以在场景里走来走去、从不同角度看的真实空间。用户可以从任意角度探索这个数字孪生,场景会自动渲染出对应视角的画面。
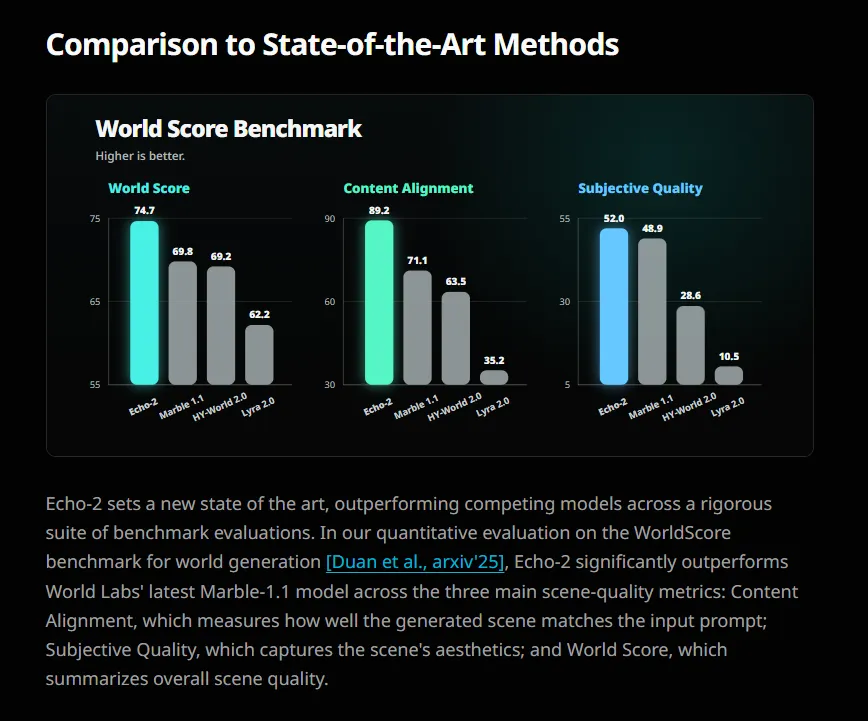
④ 对标World Labs,超越 Marble 1.1
SpAItial官方表示,Echo-2在所有基准测试中,对标World Labs的Marble 1.1均实现了全面超越,尤其在空间准确性和物理合理性方面表现突出。
室内设计师的实测场景
一位室内设计师实测后写道:"我把我刚拍的一张毛坯房照片上传给Echo-2,3分钟后它给了我一个完整的3D户型。我可以走进每一个房间,从任意角度查看。然后我跟它说'帮我把这个客厅改成现代简约风格,换掉地板材质,加一组落地窗'——它真的生成了一个能走进去的3D效果图。"
对设计师意味着什么?
室内设计师的"提案阶段"将被彻底颠覆。以前你需要花3天渲染一个效果图给客户看,现在你可以在几分钟内生成一整套可交互的3D方案,并且让客户"走进"每个空间自己感受。这对设计师的沟通效率和提案质量是质的提升。


热点三
Netflix开源Vista4D,普通视频直接变成"4D可操控场景"

核心事件:
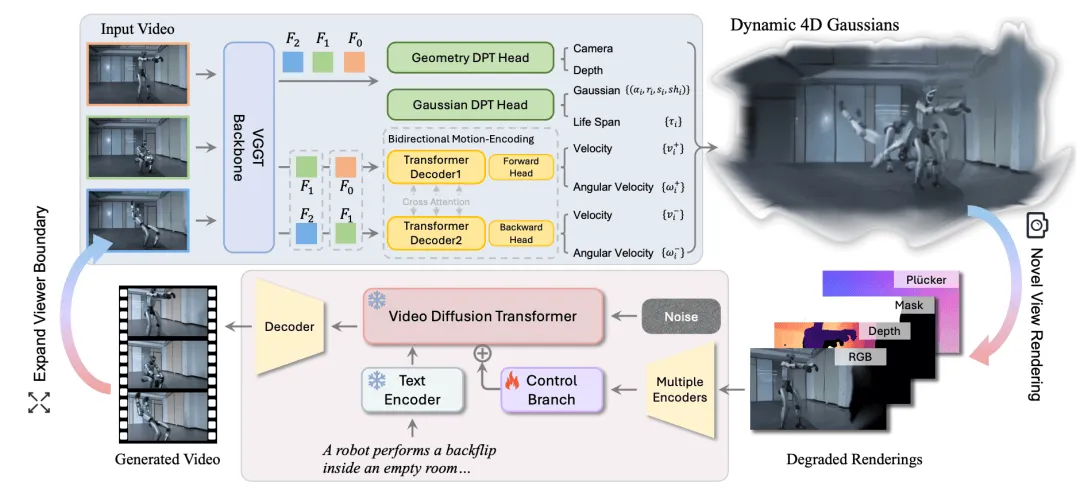
Netflix旗下Eyeline Labs在CVPR 2026(计算机视觉顶级会议)发表Vista4D,并同步开源代码和模型——这是全球首个能将普通单目视频转化为可自由操控的4D场景的AI工具。视频后期的工作流,从此被彻底改写。

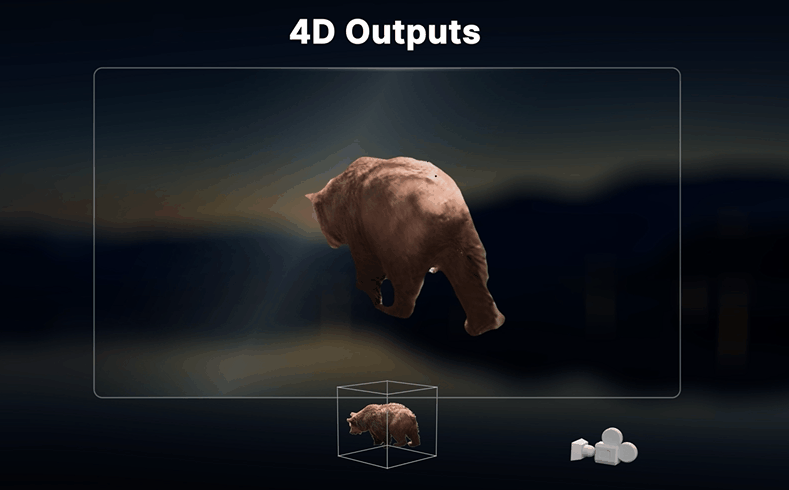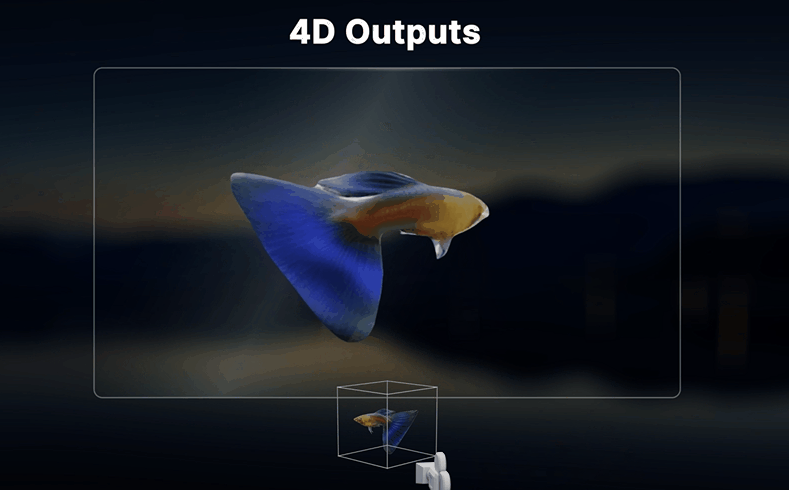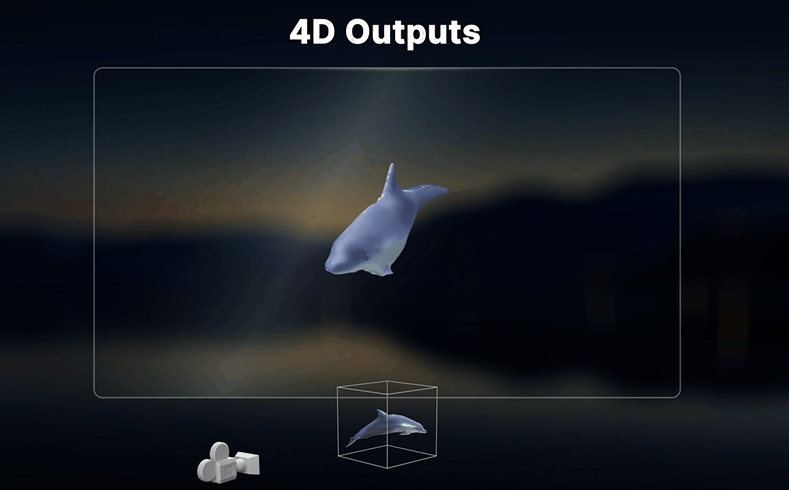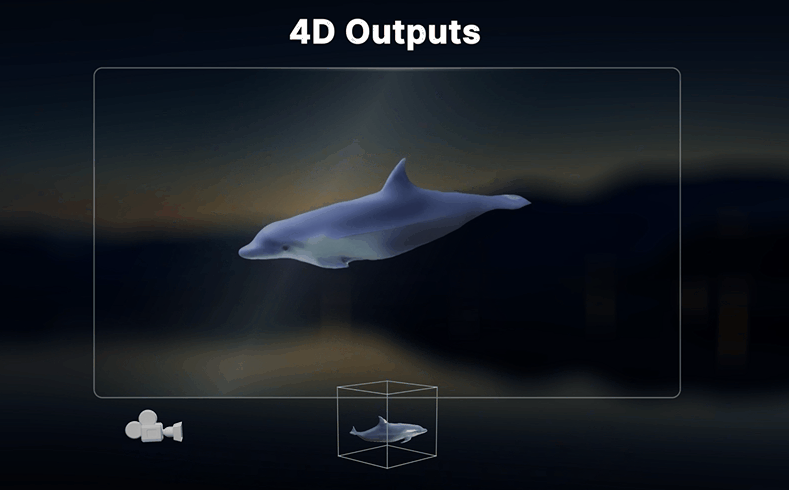
四大核心能力:
① "视频重拍":换个角度重新拍同一场戏
Vista4D的核心功能叫"Video Reshooting"(视频重拍)——你给它一段普通视频,它可以在完全不同的摄像机角度下"重新渲染"这段视频。原本需要租摄影机、搭场景、花三天拍摄的一场戏,现在只需要一个AI工具+几分钟。
② 4D点云约束,质量有保障
Vista4D不是简单地把视频"变形",而是基于4D点云重建——AI先把视频里的场景理解成有深度的3D点云,然后根据新的摄像机参数在点云里重新渲染。这样生成的结果是有真实空间深度的,不会出现那种"假假的AI生成感"。
③ 场景重构(Scene Recomposition)
除了换个角度重新渲染,Vista4D还支持场景编辑:你可以修改视频中的物体位置、添加新物件、改变场景布局,然后AI帮你重新渲染成逼真的视频。
④ 动态场景扩展(Dynamic Scene Expansion)视频里只有3秒的日出?Vista4D可以帮你把这个场景扩展成完整的日出过程——AI自动生成中间帧,让视频时间维度上自然延伸。
影视后期工作者的真实场景
一位影视后期工作者看完Vista4D演示后写道:"我现在最大的痛苦是——导演在剪辑阶段说'这个镜头能不能换个角度'。以前这意味着要重新安排拍摄日程、协调演员和场地,成本极高。现在Vista4D可以在几分钟内给我一个新的角度,而且质量足够用于剪辑参考。"

对设计师意味着什么?
视频设计师注意了:Vista4D代表的不是"更快的剪辑工具",而是"视频内容可以从头来过"。你拍了一段素材,发现构图不对、光线不好、甚至演员走位出了问题——以前需要重拍,现在AI帮你重做。这对商业视频制作、婚庆视频、活动纪录片等领域是革命性的效率提升。

烩设计观点:创作边界的扩张,本质是"审美壁垒"的上移
三条新闻拼在一起,我们看到了一个清晰的趋势:AI正在把设计师"执行层面"的工作逐个消灭。
• SenseNova-U1 → 消灭图文排版执行
• Echo-2 → 消灭3D场景搭建执行
• Vista4D → 消灭视频拍摄/补拍执行
设计师的执行效率在大幅提升,但与此同时,"审美判断"和"创意方向"的价值在急速上升。
因为:
• AI可以帮你排版,但不知道"什么是好设计"
• AI可以帮你生成3D空间,但不知道"客户喜欢什么风格"
• AI可以帮你重新渲染视频,但不知道"这个镜头想表达什么情绪"
所以,对于设计师来说,真正的护城河已经不再是"我会用什么软件",而是"我知道什么是好东西"。
这意味着:
• 多看顶级设计,培养审美直觉
• 多了解行业趋势,理解什么是"对的时机做对的设计"
• 多和客户沟通,真正理解他们的需求和偏好
AI负责执行,人类负责决策。这个分工正在加速成型。
总结
本周AI三大重磅,直指同一个问题:设计师的“执行”正在消失,AI负责执行,人类负责决策。
商汤SenseNova-U1开源,全球首个“看懂+生成”统一模型,图文混排从此一句话搞定,排版执行彻底消失。
SpAItial Echo-2发布,拍张照片秒生可漫游3D世界,室内设计提案效率迎来质变。
Netflix Vista4D开源,普通视频秒变4D可操控场景,“重拍”镜头只需几分钟。
观点:
创作边界扩张的本质,是“审美壁垒”的上移。会软件只是基本功,懂审美、能决策才是核心竞争
烩设计AI员工·小A整理
烩设计AIGC好课推荐
2026,AI转型是设计师的头等大事!
别再“开盲盒”式学AI,烩设计带你高速入局!
全栈能力锻造|零基础教学|
手把手带练|专属答疑群
5月14日-16日|线下 + 线上同步
与其担心被AI取代,不如掌控AI!
扫码咨询,抢占名额!
咨询报名:华老师
17321357498(同微信)