 夜雨聆风
夜雨聆风今日看点:当研究者不再满足于"比较",而是尝试从大脑信号中把画面重新画出来——这件事现在能做到什么程度?
01|一幅你没见过的画,从你的大脑信号里长出来
这不是科幻,而是 NSD 研究中一个正在快速成熟的子领域:从人脑 fMRI 重建视觉刺激。
今天的五篇论文,有三篇都在做同一件事——从大脑活动中重建或解码图像。它们的思路各不相同,但拼在一起,恰好画出了这个方向的完整技术路线。
第一篇是来自大阪大学的 High-resolution image reconstruction with latent diffusion models from human brain activity。
这篇论文的聪明之处,是没打算从头训练任何东西。它直接利用了当时最强的一个预训练图像生成模型——Stable Diffusion,一种潜在扩散模型(Latent Diffusion Model, LDM)。
问题在于,Stable Diffusion 的设计是用文本来生成图像。那怎么把大脑信号接上去?
论文的思路是:不改变 Stable Diffusion 本身,而是让大脑信号去"操控"扩散模型的三个关键组件——图像的潜在向量 Z、条件输入 C、以及降噪 U-Net 的不同层。换句话说,大脑信号变成了 Stable Diffusion 的"方向盘"。
更妙的是,论文还从神经科学角度反向解释了 Stable Diffusion 各组件对应哪些脑功能。比如,某些 U-Net 层更接近低级视觉特征,而另一些层则与高级语义相关。
这意味着,即便你没有训练任何新模型,仅仅通过理解大脑信号如何对应生成模型的不同层次,就可以把一张图从脑中"捞出来"。
论文信息
原标题:High-resolution image reconstruction with latent diffusion models from human brain activity
作者:Yu Takagi, Shinji Nishimoto
来源:bioRxiv (2022)
DOI:10.1101/2022.11.18.517004
链接:https://www.biorxiv.org/content/10.1101/2022.11.18.517004v1.full
02|大脑表面上的信息,比我们以为的更重要
第二篇论文提出了一种更精细的架构:Cortex2Image。
论文全称 Decoding natural image stimuli from fMRI data with a surface-based convolutional network。核心问题是:fMRI 数据是三维体素信号,但大脑皮层的功能组织其实是二维曲面。传统方法用 3D 卷积直接在体素空间操作,可能丢失了皮层曲面上关键的空间结构信息。
于是,论文提出了一种基于皮层表面(surface-based)的卷积网络。它不像传统做法那样把全脑体素摊平成一维向量喂给全连接层,而是在皮层表面的几何结构上做卷积。
这是从"脑电信号处理"到"几何深度学习"的一次思路升级。
整个解码流程大致是:大脑皮层信号 → 表面卷积网络 → 语义图像嵌入(使用 CLIP 空间)→ 图像生成器(IC-GAN)。
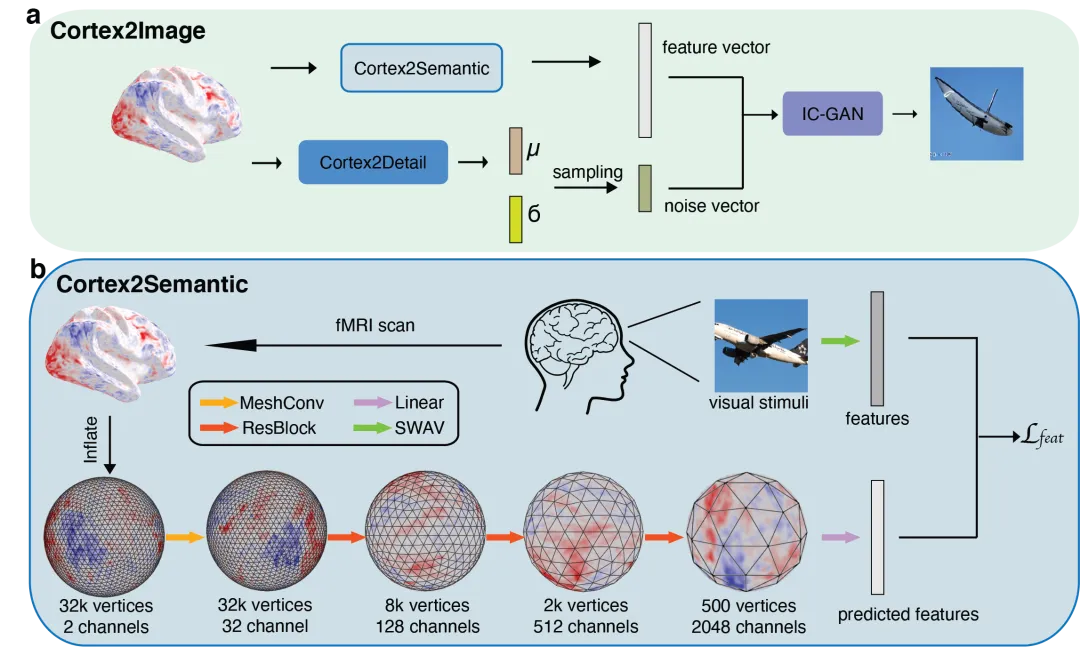
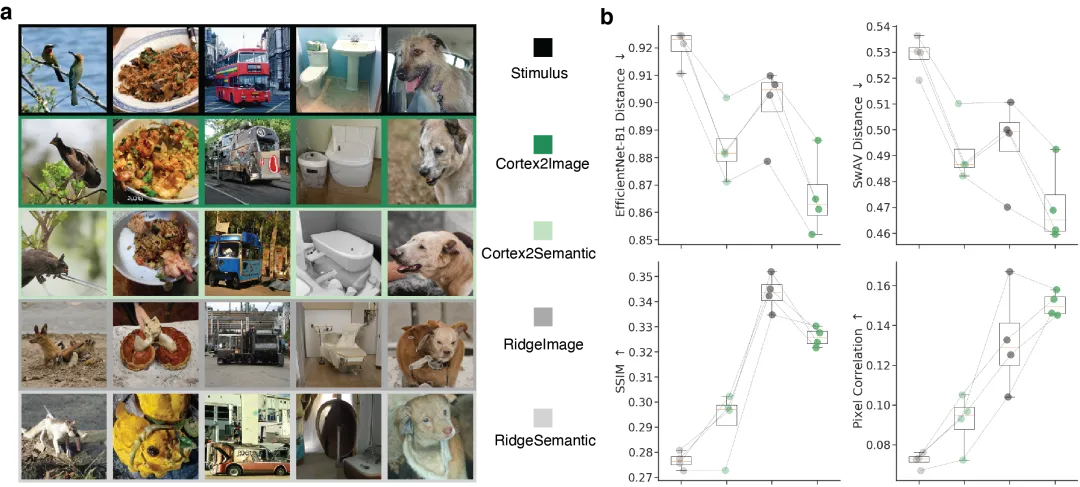
实验表明,表面卷积带来的提升是显著的。在语义保真度和细节保持上,Cortex2Image 超越了当时的多个基线。论文还比较了不同皮层区域对重建质量的贡献。

一个有意思的发现是:把图像生成器和解码网络联合训练,可以大幅减少获得"ground truth"细节向量所需的计算量——这意味着整个流程可以更快、更省资源。
论文信息
原标题:Decoding natural image stimuli from fMRI data with a surface-based convolutional network
作者:Zijin Gu, Keith Jamison, Amy Kuceyeski, Mert Sabuncu
来源:arXiv (2022)
DOI:10.48550/arXiv.2212.02409
链接:https://arxiv.org/abs/2212.02409
03|脑数据"脏"了怎么办?
前两篇论文都在讲怎么把脑信号变成图像,但有一个前提假设——你首先得有干净的、标注正确的神经活动数据。
第三篇论文 Sample Reweighting for Label Denoising of Neural Activity Data 把这个前提本身变成了研究问题。
神经活动数据的标记(label)经常有噪声。比如,在采集 fMRI 数据时,被试可能走了神,或者图像的呈现与实际感知之间存在偏差,这些都可能导致"这张图引发的大脑反应"标签本身不是完全准确的。
这篇 IEEE 会议论文提出的方法很实用:通过样本重加权(sample reweighting)来降低噪声标签的影响。基本逻辑是,自动识别哪些样本的标注可能不可靠,降低它们在训练中的权重,从而让模型更多地依赖高质量样本。
虽然介绍的是一个偏"数据清理"的技术,但在脑解码这个领域,数据质量往往比模型架构更能决定最终效果。这篇论文处理的,恰恰是很多脑解码研究不想面对的底层的工程问题。
论文信息
原标题:Sample Reweighting for Label Denoising of Neural Activity Data
作者:Dongfang Xu, Rong Chen
来源:IEEE/EMBS Conference on Neural Engineering (2023)
DOI:10.1109/NER52421.2023.10123809
链接:https://doi.org/10.1109/NER52421.2023.10123809
04|当整个领域被邀请来一起做题
第四篇论文不是提出一个新模型,而是提出了一个"考场"。
The Algonauts Project 2023 Challenge: How the Human Brain Makes Sense of Natural Scenes 是一篇竞赛介绍论文,但它所描述的事情对这个领域的影响可能比很多模型论文更大。
Algonauts 项目的 2023 年版,直接使用了 NSD 数据集——约 73,000 张自然场景彩色图像及其对应的高质量 7T fMRI 响应——作为挑战赛的核心数据。
为什么这件事重要?因为在此之前,不同研究组用不同的数据、不同的评估方式、不同的预处理流程,得出的结论很难直接比较。你在 A 数据集上说模型 X 更好,我在 B 数据集上可能得出完全相反的结论。
Algonauts 2023 的做法是:提供一个公开排行榜(public leaderboard),所有参赛者使用同一套 NSD 数据、同一套评估指标。每次提交后,排行榜自动更新,模型之间的优劣一目了然。
这加速了模型迭代,也让"哪个模型更像人脑"这个核心问题有了一个可以被真正回答的基础设施。
论文背后的团队来自 MIT、哈佛、柏林自由大学等多个机构。它的核心信念是:生物智能和人工智能的研究正在越来越不可分,而 NSD 是连接两边的理想桥梁。
论文信息
原标题:The Algonauts Project 2023 Challenge: How the Human Brain Makes Sense of Natural Scenes
作者:A. T. Gifford, B. Lahner, S. Saba-Sadiya, M. G. Vilas, A. Lascelles, A. Oliva, K. Kay, G. Roig, R. M. Cichy
来源:arXiv (2023)
DOI:10.48550/arXiv.2301.03198
链接:https://arxiv.org/abs/2301.03198
05|大脑如何判断"大"和"小"?
最后一篇论文把镜头从"怎么解码"拉回到一个更基础的问题:
当我们看一张自然场景照片时,大脑怎么知道画面里的物体在真实世界中有多大?
真实世界中的物体大小是一个很特殊的信息。一头大象在照片里可能占 50 个像素,一个乒乓球也可能占 50 个像素。但你的视觉系统几乎从来不会把乒乓球误认为大象。这说明,大脑一定在某个层级提取了"真实世界大小"这个属性,而且它是独立于视网膜成像大小的。
论文 Neural Selectivity for Real-World Object Size In Natural Images 利用 NSD 的大规模 fMRI 数据,系统研究了大小选择性在自然场景中的神经编码规律。
研究结果有几个重要发现:
第一,即使在复杂的自然场景中(而不是简单的孤立物体图片),大脑仍然表现出对真实世界大小的选择性。也就是说,大小编码在复杂背景下也能稳定工作。
第二,大小选择性对生物和非生物物体都存在。无论你看的是大象还是汽车,只要是"大的东西",大脑的处理方式会有共通之处。
第三,低层视觉特征(颜色、边缘频率、对比度等)无法解释大小选择性。这意味着大小编码是一种真正的高层视觉表征,而不是低级图像统计的副产品。
第四,偏好"大物体"和偏好"小物体"的体素,其调谐函数形状不同。前者更接近对数函数,后者更接近指数函数——这在计算上暗示,大物体和小物体的编码机制可能不完全对称。
这篇论文从基础科学角度回答了一个朴素但深刻的问题:大脑如何理解世界的大小。它和前几篇解码论文互为补充——解码研究告诉我们"能不能重建",而这篇论文告诉我们"大脑一开始是怎么组织的"。
论文信息
原标题:Neural Selectivity for Real-World Object Size In Natural Images
作者:Andrew Luo, Leila Wehbe, Michael Tarr, Margaret M. Henderson
来源:bioRxiv (2023)
DOI:10.1101/2023.03.17.533179
链接:https://www.biorxiv.org/content/10.1101/2023.03.17.533179v1.full
06|从比较到重建,这条路越走越具体
如果把上一期的 5 篇和这一期的 5 篇放在一起看,你会发现一条越来越清晰的推进轨迹:
上一期,研究者还在问"AI 模型和人脑像不像"。他们用线性回归去拟合,用 benchmark 去比较,用无假设方法去发现脑区选择性。
这一期,问题从"像不像"变成了"能不能"——能不能从大脑信号重建图像?能不能用扩散模型?能不能在皮层表面上建模?能不能让整个领域在同一个标准下比赛?能不能理解大脑最基础的大小感知?
Stable Diffusion 进来了。皮层表面卷积进来了。公开排行榜进来了。样本去噪技术进来了。
这说明这个领域正在从一个"科学问题"变成一个"工程系统"。
而这个转变的核心,始终是 NSD 这个数据地基。无论你用哪种方法、哪种模型、哪种解码策略,你都需要同一件事:大量高质量的"图像-大脑响应"配对数据。
NSD 的 73,000 张自然场景 + 7T fMRI,就是这个地基。
如果说 2022 年的研究是在证明"这条路可以走",那么 2023 年的研究就是在说:这条路不仅走得通,而且走得越来越快。
