 夜雨聆风
夜雨聆风纯本地运行、支持中文、完全免费、全手搓 | 一个建筑闲人的AI实战记录
先看结果
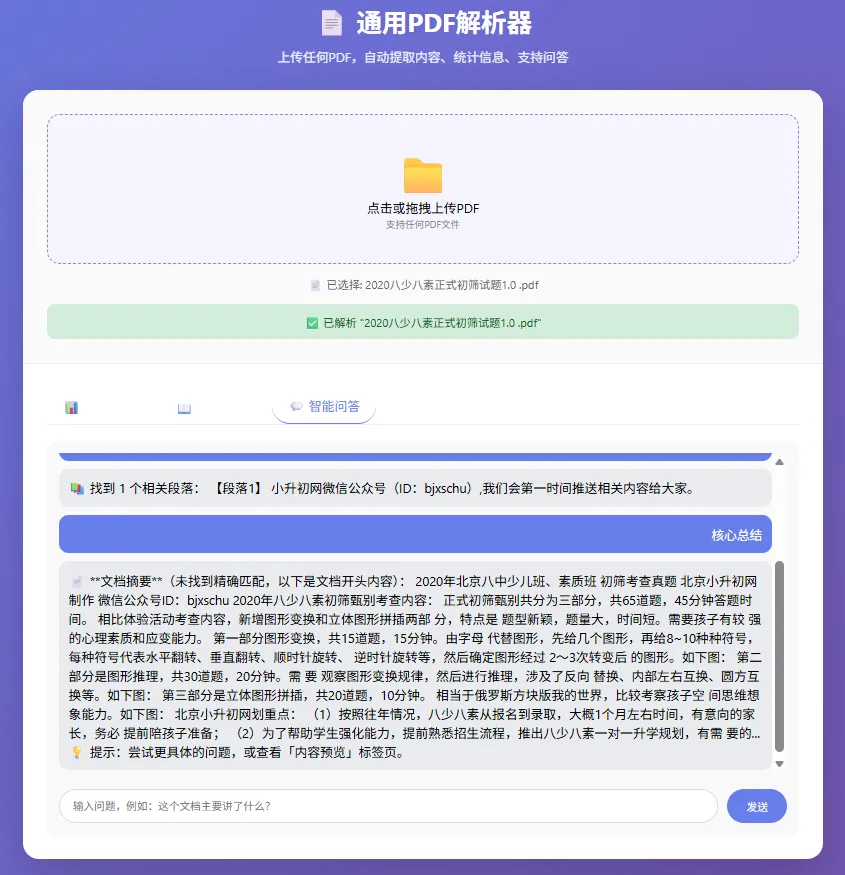
一个网页,打开后上传任何PDF,系统会自动:
提取全文内容
统计字数、行数、文本块
提取核心关键词
支持自然语言问答
这不是ChatPDF等在线服务的翻版——它是纯本地运行的,模型存在你电脑里,PDF不上传任何服务器,数据完全私有,自己从零写的AI MVP。
项目名称:WoyeAI 1.0 MVP
一句话核心
现在的AI就是一个函数。你不需要懂数学,不需要会训练,只需要学会“调用”。
text
输入 → [模型] → 输出"hello" → [模型] → "正面情绪,置信度99%"这就是“模型即函数”范式的核心。模型被封装得如同print()一样简单。
第1小时:环境准备 + 第一个模型
5分钟装环境
bash
pip install transformers torch gradio pymupdf sentence-transformers peft
让模型输出第一句话
python
from transformers import pipelineclassifier = pipeline("sentiment-analysis")result = classifier("I love building AI!")print(result)
输出:[{'label': 'POSITIVE', 'score': 0.9998}]
恭喜!你已经调用了一个大模型成为你的函数语句。这一刻,你完成了90%的人没做过的事——不是“学AI”,而是“自己写的mini AI”。
第2小时:LoRA微调——只训练1%的参数
传统全量微调:训练上亿参数,需要昂贵GPU,保存的模型几GB
LoRA微调:只训练0.5%-1%的参数,普通笔记本可跑,保存的插件只有几MB
python
from peft import LoraConfig, get_peft_modellora_config = LoraConfig(r=8, lora_alpha=32)model = get_peft_model(model, lora_config)model.print_trainable_parameters()
输出:trainable params: 589,826 || trainable%: 0.58%
这就是LoRA的核心价值——用极低成本让模型适应你的任务。
第3小时:RAG——让AI读懂你的PDF
RAG(检索增强生成):不重新训练,而是把文档变成向量库,提问时检索相关内容。
python
from sentence_transformers import SentenceTransformermodel = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')defembed_text(text):return model.encode([text])[0]
流程只有三步:
建库:本地的PDF,拆成小段 → 每段转成向量 → 存起来
检索:用户问题转成向量 → 在库里找最相似的段落
回答:返回相关段落
关键洞察:模型的核心能力不是“记忆知识”,而是“理解上下文”。你给它什么材料,它就基于什么回答。
第4小时:网页界面——从命令行到产品
用Gradio,3行代码把命令行工具变成网页:
python
import gradio as grgr.ChatInterface(fn=ask).launch()
打开浏览器 http://127.0.0.1:7860,一个完整的对话界面就出现了。
第5小时:通用PDF解析器 + 智能问答
最终成品代码结构:
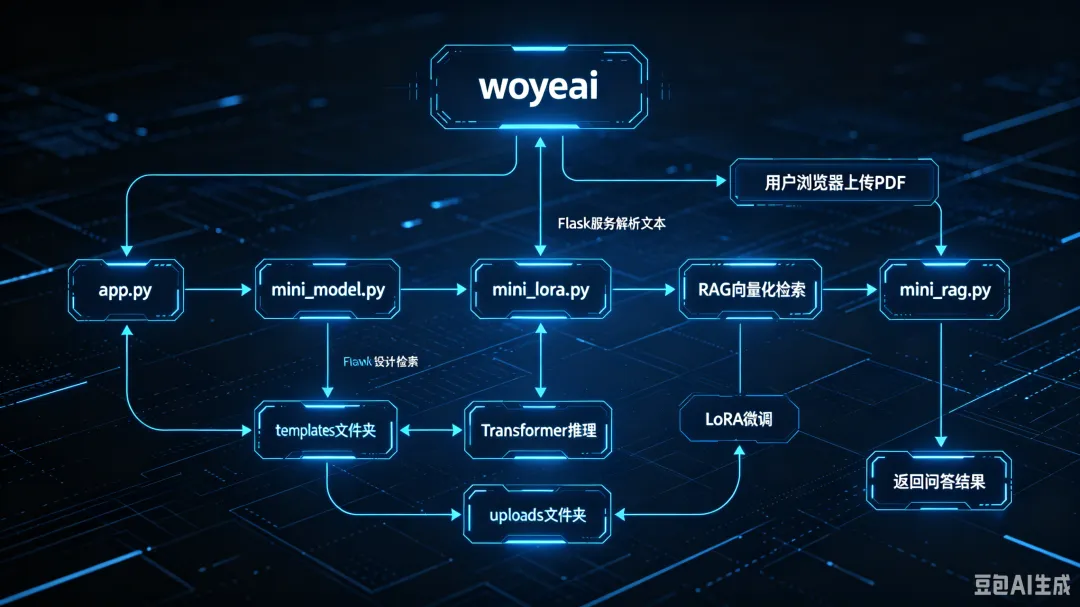
核心能力:
| 功能 | 说明 |
|---|---|
| 上传任何PDF | 自动解析全文 |
| 统计信息 | 字数、行数、文本块数 |
| 关键词提取 | 自动提取文档核心词汇 |
| 内容预览 | 显示文档开头内容 |
| 智能问答 | 基于关键词检索相关段落 |
我学到的“范式迁移”
| 旧认知 | 新认知 |
|---|---|
| 模型是巨大的黑箱 | 模型是可调用的函数 |
| 训练需要海量数据和GPU | 微调只需要少量数据和普通笔记本 |
| 模型必须掌握所有知识 | 知识可以存储在外部,按需注入 |
| 部署需要复杂配置 | 3行代码生成网页界面 |
一句话总结:不需要成为造发动机的人,只需要学会如何拿个轮子出发。
这个系统能做什么?
个人知识库:上传工作文档,用自然语言搜索
论文阅读助手:上传PDF,不懂就问
内部资料问答:公司手册、制度文件做成内部知识库
试题解析:上传考题,自动提取题型、题量、时间
最重要的是:你开发的mini AI,数据本地,不上传任何服务器。
给想尝试的人:路线图
理解:跑通
Hello world,感受“模型即函数”微调:用LoRA让你的模型适应特定领域
RAG:建立向量索引,让模型能读文档
界面:用Gradio/Flask封装成网页应用
产品化:支持中文、动态加载、通用PDF解析
不需要AI博士学位,不需要昂贵的硬件。你只需要一台普通的电脑,愿意花5个小时时间,大模型AI敲代码,理解生成自己的mini AI。
写在最后
这次实践让我最感慨的,不是技术本身,而是AI开发的门槛正在以惊人的速度降低,print函数可以“print”大模型。
从“训练模型”到“使用模型”再到“组合模型”,这场范式迁移正在发生。
拿起键盘,从第一行代码开始。
核心依赖:Flask + PyMuPDF + sentence-transformers
👇 你想写一个自己的AI小模型吗?欢迎交流!
