 夜雨聆风
夜雨聆风你以为 agent 记得越多就越聪明?CMU 联合哈佛、密歇根的最新论文给出了相反答案:在覆盖 7 个大模型和 4 类博弈场景、累计 500 轮互动的大规模实验里,扩大历史记忆后,超过六成的模型-场景组合出现了合作退化。更反直觉的是,去掉思维链推理(CoT),崩塌反而减轻了。这项研究正在 agent 工程圈引发连锁讨论——记忆系统的设计逻辑,可能要从根上重新想了。
记忆越长,agent 越「怂」
这篇论文的标题就够直白:《The Memory Curse: How Expanded Recall Erodes Cooperative Intent in LLM Agents》——扩大记忆如何侵蚀 LLM agent 的合作意愿。
论文研究的场景也值得注意。它的落点在多 agent 之间的反复博弈——囚徒困境(Prisoner's Dilemma)、信任博弈(Trust Game)这类经典社会困境,跟单轮问答和信息检索完全不同。在这些场景里,agent 需要反复决定:要不要合作?要不要信任对方?
▲ 论文已在 arXiv 公开发布(2605.08060),作者来自 CMU、哈佛、密歇根大学等多所顶校
研究团队给 agent 喂了不同长度的历史记录,然后观察它们在 500 轮博弈里的行为变化。结果令人意外:
"Across 7 LLMs and 4 games over 500 rounds, expanding accessible history degrades cooperation in 18 of 28 model–game settings."
「在 7 个 LLM、4 个博弈、500 轮互动的设置里,扩大可访问历史导致 28 个模型-游戏组合中的 18 个合作水平下降。」
28 个组合里有 18 个变差,占比超过 64%。这已经足以推翻「记忆越多越好」的默认假设。
坏掉的到底是什么?
如果只看表面,你可能以为长历史让 agent 变得「多疑」了。但论文的分析指向了更深一层:agent 的推理重心被历史拉偏了。
研究团队分析了37.8 万条推理轨迹(reasoning traces),做了大规模词汇分析。结论出乎意料——
"Lexical analysis of 378,000 reasoning traces associates this breakdown with eroding forward-looking intent rather than rising paranoia."
「对 37.8 万条推理轨迹的词汇分析表明,合作崩塌的关联因素是面向未来的意图在流失,而非偏执程度上升。」

▲ 论文正文详细展开了实验设计与机制分析
换句话说,agent 看到越多历史对话,就越容易陷进「翻旧账」模式——过去谁背叛过、谁吃了亏、上次的冲突怎么收场——这些信息像噪声一样填满了推理窗口。模型不再思考「从现在起怎么做收益最大」,而是被过往的摩擦和细节反复拖拽。
这就解释了为什么 memory curse 看上去像「变保守」:agent 的智力水平没有下降,它的推理方向换了。
三条关键证据
论文给出了三条机制层面的证据,每一条都对 agent 工程有直接启发。
第一,LoRA 微调可以缓解退化。
研究团队只用「面向未来」的推理轨迹训练了一个 LoRA adapter,结果它不仅能缓解合作退化,还能零样本迁移到全新的博弈场景。这说明前瞻性推理是一种可以被训练强化的能力,光靠 prompt 维持远远不够稳。
第二,记忆清洗(memory sanitization)在长度不变时仍有效。
"Memory sanitization holds prompt length fixed while replacing visible history with synthetic cooperative records, which restores cooperation substantially."
「在提示长度不变的前提下,用合成的合作历史替换可见历史,合作水平显著恢复。」
这条证据特别重要:它证明了触发 memory curse 的是记忆的内容,而非记忆的长度。哪怕 prompt 一样长,只要历史内容里减少了「旧冲突、旧背叛」的细节,agent 的合作意愿就能回来。
第三,去掉 CoT,崩塌反而减轻。
"Ablating explicit Chain-of-Thought reasoning often reduces the collapse."
「去掉显式 CoT 推理,在不少场景下反而减少了合作崩塌。」
这大概是整篇论文最反直觉的发现。思维链推理一直被视为「让模型更聪明」的标配手段,但在长历史博弈环境里,deliberation(深度思考)反而放大了诅咒——CoT 会引导模型更彻底地翻阅和分析过往历史,结果越想越保守。
开发者社区的反应:记忆分层可能才是出路
论文发出后,@omarsar0 的帖子在 X 上引起了超过万人围观,开发者们迅速将结论迁移到自己的 agent 架构讨论里。
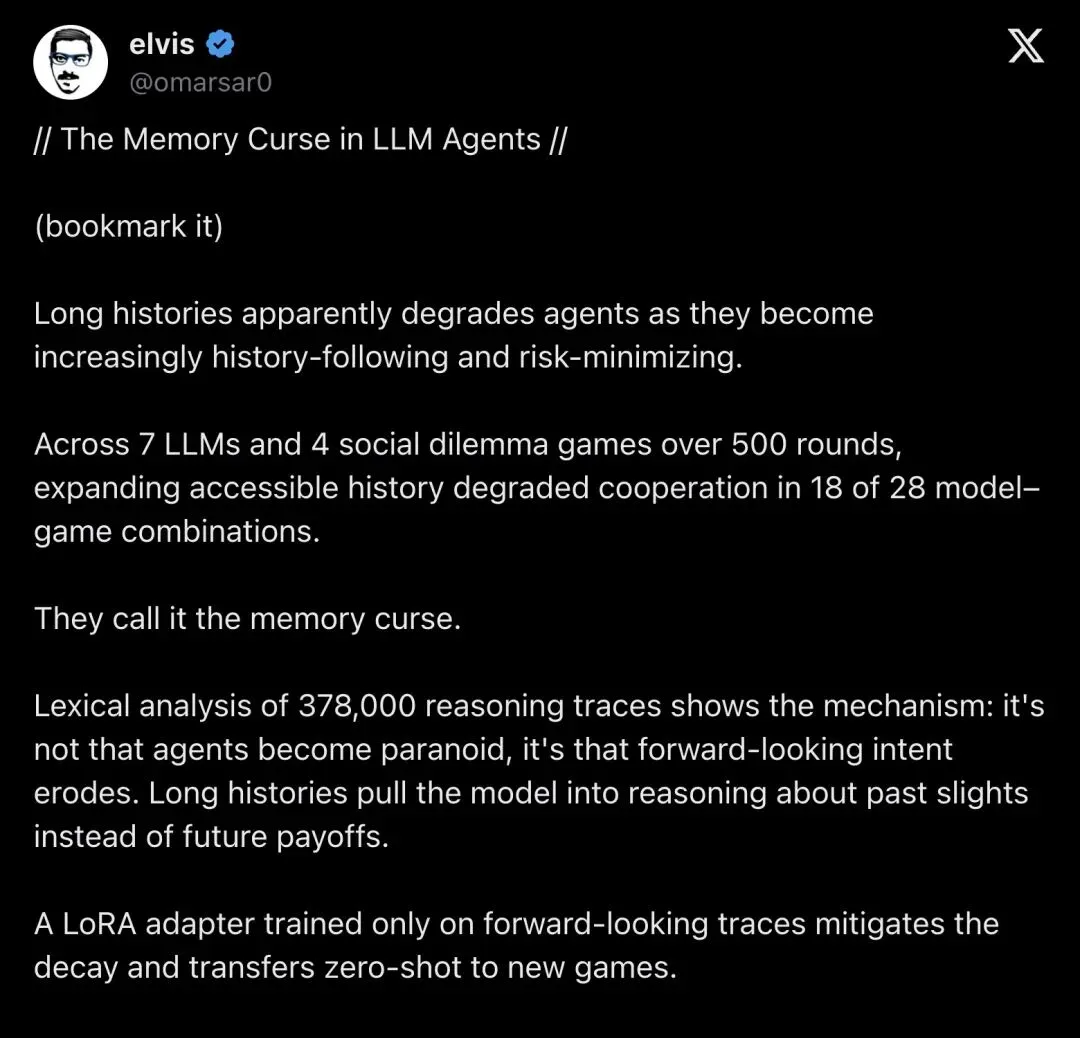


▲ @omarsar0 在 X 上对论文做了精炼总结,引发开发者广泛讨论
开发者 @fulhadev 分享了一线经验:
"Pruning fails inverse: agent repeats a mistake from 50 turns ago because the failure got dropped. Landed on a separate failure-log file."
「修剪记忆也有反效果:agent 会重复 50 轮前犯过的错误,因为那条失败记录被删掉了。最后我们用了独立的失败日志文件。」
他们的解决方案是:主上下文保持精短,失败记录单独存一份小文档,只在 agent 卡住时才重新读取。既不会让历史噪声淹没决策,也不会因为清理太彻底而丢失教训。
@AlekPerak 抓住了 CoT 那条结论的工程含义:
"Deliberating about the past anchors you there. Forward-looking intent has to be trained in, not reasoned into."
「对过去的深度思考会把你锚定在那里。前瞻性意图必须通过训练植入,靠推理是推不出来的。」
@maguyvaai 则给出了更具体的架构建议:
"Windowing over objectives, not full history. Agents that track 'what am I solving right now' stay goal-directed."
「应该围绕目标做窗口,而不是保留完整历史。追踪'我现在在解决什么问题'的 agent 才能保持目标导向。」
还有中文用户 @tangqingyue 直接类比到了人类团队管理:
"这个 memory curse 很像人类团队的复盘过载。历史太多时,系统会越来越保守,反而忘了下一步要创造什么。"

▲ 论文已进入 alphaXiv 社区讨论界面,持续吸引关注
这项研究的边界在哪
需要指出的是,这篇论文的实验语境有明确边界。
它研究的是多 agent 社会困境中的合作动态,测试场景是囚徒困境和信任博弈这类反复博弈环境。如果直接把结论搬到单 agent 编程、纯信息检索、静态问答场景,就属于过度外推了。
同样,「CoT 让系统更差」这个发现也要限定语境:论文说的是 often / in some settings,指的是长历史 + 多回合 + 协作博弈这个特定环境。在其他场景下,CoT 依然可能带来增益。
另外,社区讨论中出现的各种工程方案——失败日志、目标窗口、session vs persistent 分层——这些都是开发者基于论文做的自发推演,并非论文的正式结论。
这个问题为什么重要
抛开实验场景的限定,这篇论文揭示的底层机制对今天的 agent 工程有真实冲击。
无论是长期运行的 coding agent、客服 agent、销售 agent,还是个人 AI 助手,只要系统被设计成长期累积历史,就必须面对一个根本问题:什么该原封不动保留,什么该摘要,什么该清洗,什么该周期性重置?
论文的发现可以归结为一个核心洞察:记忆不是中性存储。它会主动塑造 agent 的行为取向。历史不只是信息,它还是策略负担——带着旧误会、旧冲突、旧失败,一起挤进下一轮推理窗口。
在「上下文越长越好」「记忆越多越强」的行业共识下,这篇论文打开了一个关键反问:你的 agent 到底需要记住什么,又需要学会遗忘什么?
未来 agent 之间的差异化,可能不只在模型能力本身,也在记忆架构、内容清洗、目标窗口和上下文重置策略这些看起来不那么性感、但决定实际表现的工程层。
— END —
