 夜雨聆风
夜雨聆风01
你有没有这种感觉——
用 AI 写代码,它像个万能助手,什么都能干;但项目一大,它就开始「犯迷糊」:忘掉你三天前的架构决策、重复你已经拒绝过的设计方案、在 2000 行的上下文里彻底迷失……
这不是 AI 不够聪明。
这是「一个人干所有活」的宿命。
今天我想告诉你一个 AI 编程圈正在悄悄流行的趋势:从 Sub-Agents 到 Multi-Agent,让 AI 从「单打独斗」进化到「团队作战」。
02
先说个冷知识——

这个数字说明什么?
当你把任务拆给多个「专职 AI」并行处理,效果远超一个「全能 AI」单独硬扛。
但问题是:怎么拆?拆成什么样?什么时候该拆?
这就不是随便说说那么简单了。
03
先别急着「多 Agent」
在说具体模式之前,我想先泼一盆冷水。
LangChain 在官方文档里明确警告:
“Start with a single agent. Add tools before adding agents. Graduate to multi-agent patterns only when encountering clear architectural limits.”
(先从单 Agent 起步,优先通过引入工具扩展能力;只有当系统确实触及单 Agent 的架构边界时,才考虑采用多 Agent 的设计模式。)
这不是保守,这是工程智慧。
因为每增加一个 Agent,你就:
• 增加了一层调试复杂度 • 增加了一份 token 成本 • 增加了一个潜在的失败点
多 Agent 不是万能药,它是一把双刃剑。
那么,什么时候该升级?
04
两个触发信号
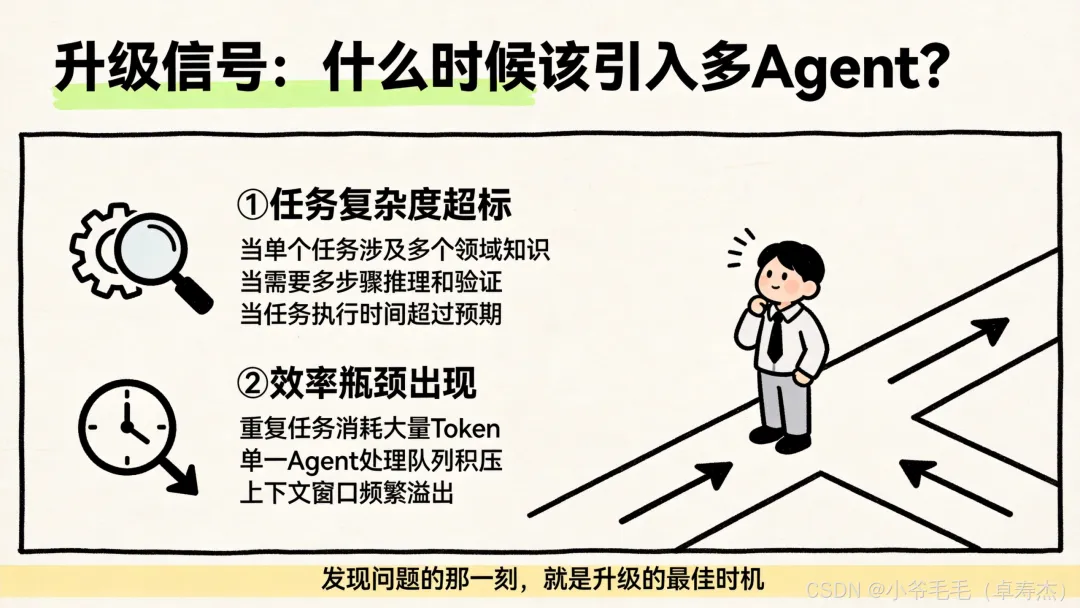
信号一:上下文「过载」
当多个能力领域的专业知识无法舒适地塞进单一 prompt 中时——
想象你的 System Prompt 是这样的:
你是代码专家(200行指令)+ 你是测试专家(150行指令)+ 你是安全审计专家(180行指令)+ 你是文档撰写专家(100行指令)+ ...= Token 爆炸,模型注意力分散
这就是「上下文过载」。模型进入所谓的 dumb zone(迟钝区),表现反而下降。
信号二:团队「协作」需求
当多个团队需要独立维护各自的 Agent 能力时——
比如安全团队维护审计 Agent,测试团队维护测试 Agent,各团队可以独立迭代而不互相干扰。
这时候,单一 Agent 的「统一大 prompt」反而成了协作障碍。
只要出现以上任意一个信号,你就可以考虑多 Agent 架构了。
05
四种核心设计模式
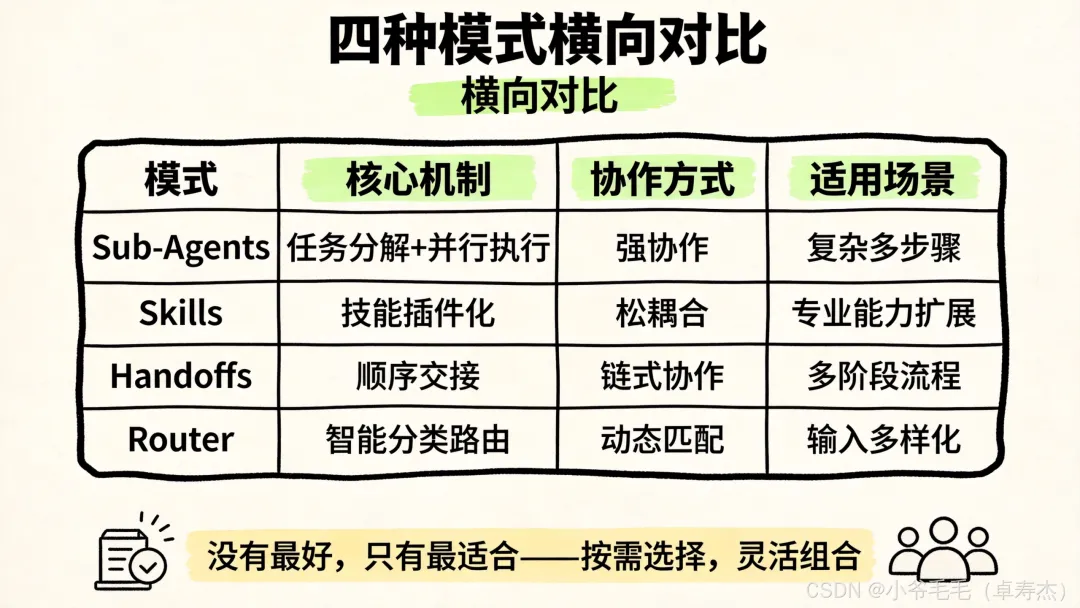
综合 LangChain、Anthropic、Google、OpenAI 等前沿公司的最佳实践,多 Agent 系统可以归纳为 四种核心架构模式。
它们不是互斥的——实际项目中经常组合使用。
模式一:Sub-Agents(子代理委派)
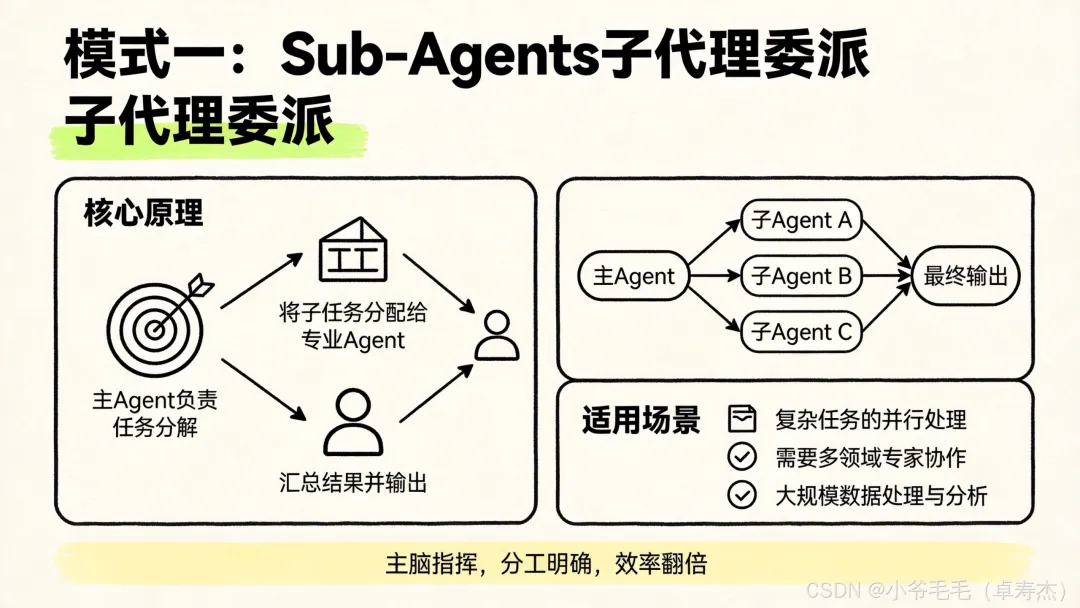
核心思想:一个 Supervisor Agent 当「老板」,把任务分解后委派给专门的 Sub-Agent。
特点:
• 上下文隔离强:每个 Sub-Agent 拥有独立上下文窗口,从根本上避免信息污染 • 天然支持并行:多个 Sub-Agent 同时展开工作 • Supervisor 统一控制:负责任务拆解、结果汇总、最终输出
典型代码配置:
# Claude Agent SDK 中的 Sub-Agent 定义subagent_config = { "name": "research-agent", "description": "Research specific topics by searching the web. " "Use when user asks factual questions requiring " "up-to-date information.", "system_prompt": "You are a research specialist...", "tools": ["WebSearch", "WebFetch", "Read"], "model": "sonnet" # 用更快的模型降低成本}
适用场景:
• 需要并行检索多个信息源 • 跨多个知识领域协同工作 • 个人助手协调日历、邮件、CRM
一句话总结:Sub-Agent 适合「大量信息过滤 + 并行处理」的场景。
模式二:Skills(技能加载)
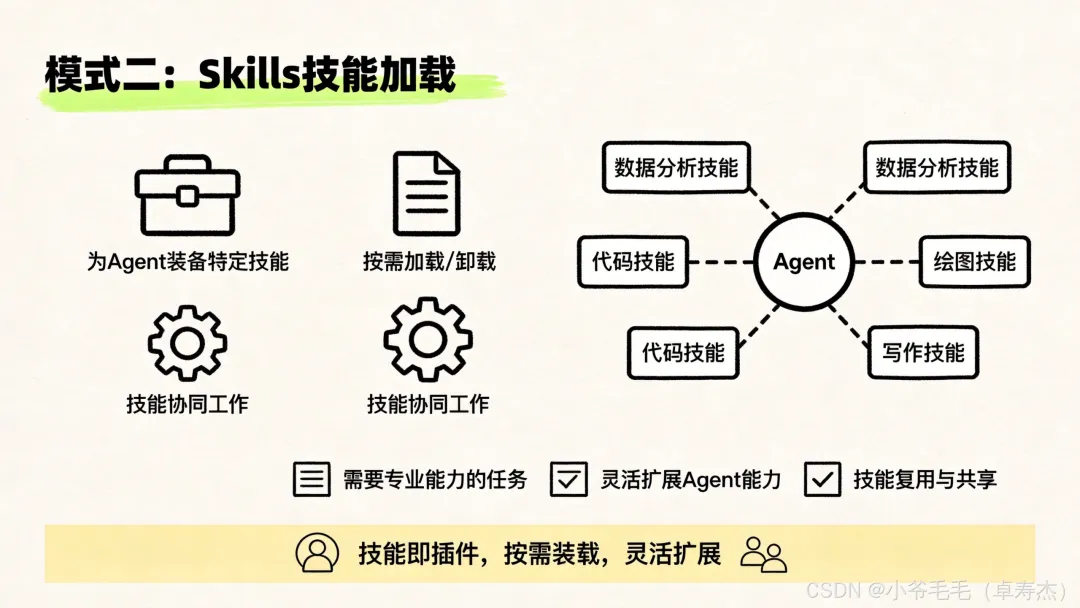
核心思想:单个 Agent 按需加载「技能包」,而不是启动多个独立 Agent。
Single Agent | 知道技能名称 → 按需加载 → SKILL.md / SKILL.md / SKILL.md (deploy) (review) (testing)
特点:
• 轻量级:用 prompt 切换替代完整的 Agent 切换 • 对话连续性好:所有技能共享同一个上下文 • 交互路径最短:用户始终与同一个 Agent 直接交互
典型目录结构:
.claude/skills/├── deploy/ # 部署技能│ └── SKILL.md├── review-pr/ # PR 审查技能│ └── SKILL.md└── database-migration/ # 数据库迁移技能 └── SKILL.md
SKILL.md 示例:
---name: deploydescription: "Deploy application to production environment"allowed-tools: ["Bash", "Read", "Edit"]---## 部署步骤1. 检查当前分支是否为 main2. 运行完整测试套件3. 构建生产版本4. 执行部署脚本5. 验证部署结果
适用场景:
• 单个 Agent 需要支持多种能力模式 • 能力种类繁多,但单次任务只需少量能力 • 编码助手、创意工具等
一句话总结:Skills 适合「需要连贯对话 + 按需加载能力」的场景。
模式三:Handoffs(交接)
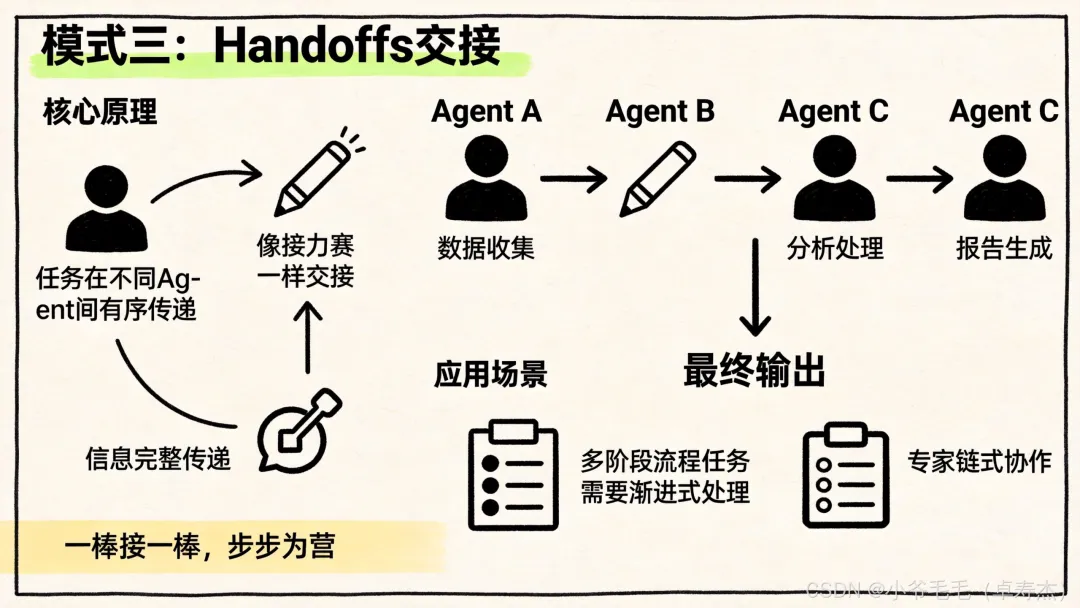
核心思想:活跃的 Agent 根据对话状态动态切换,上一阶段完成后把「交接棒」传给下一阶段。
特点:
• 状态驱动:Agent 切换由显式的状态变化触发 • 上下文选择性传递:可以根据需要选择传递哪些信息 • 用户体验流畅:Agent 切换对用户透明
Claude Code 中的 Handoffs 实现:
系统规则:你将按照以下阶段顺序工作:1. 信息收集(intake)2. 问题诊断(diagnosis)3. 解决方案(resolution)当前阶段:intake规则:- 只能提问- 不要给解决方案- 当信息完整时,明确声明:`进入 diagnosis 阶段`---当 Claude 输出「信息已收集完成,进入 diagnosis 阶段」后,系统注入下一段 Prompt:当前阶段:diagnosis你现在是技术支持 Agent……
适用场景:
• 客服工单流程(收集 → 诊断 → 解决) • 多阶段对话系统 • 需要逐步解锁能力的业务流程
一句话总结:Handoffs 适合「阶段清晰 + 流程式 + 对话连续性要求高」的场景。
模式四:Router(路由器)
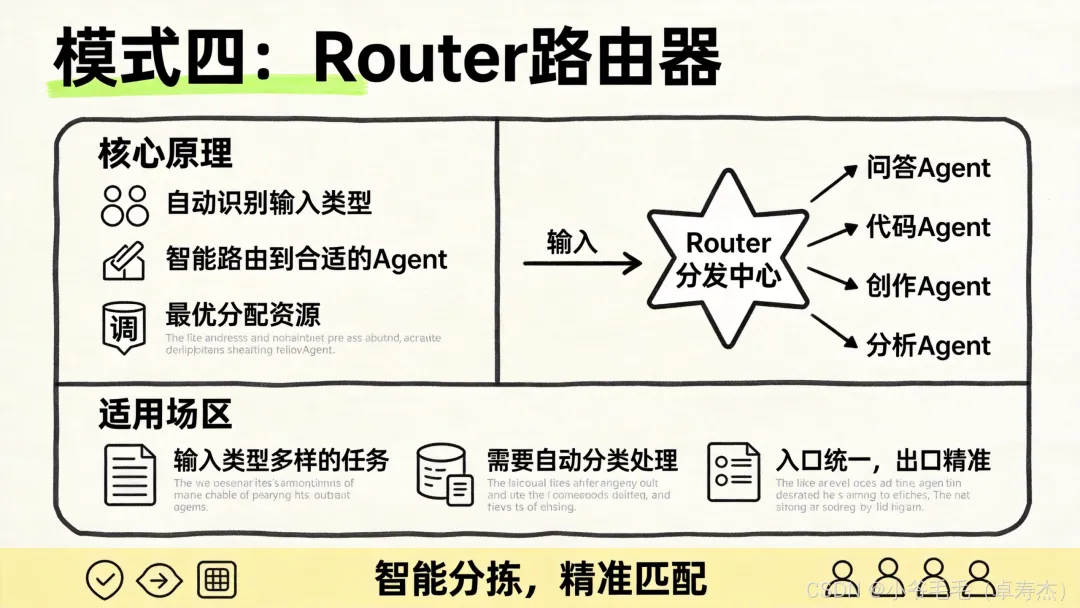
特点:
• 强并行能力:多个 Specialist 同时工作 • 职责边界清晰:各分支彼此独立 • 无状态设计:每次请求独立处理
Claude Code 中的 Router 实现:
Router 本质上可以是以下三种形态之一:
1. 主 Agent 中的一段路由决策逻辑(最常见) 2. 一个可调用的 Tool(Router-as-Tool) 3. 一个轻量的 Sub-Agent(只负责分类)
适用场景:
• 企业知识库(政策文档 + 业务数据 + 实时指标) • 多源查询系统 • 客户支持分类(技术 / 账单 / 账户)
一句话总结:Router 适合「多领域并行查询 + 结果合成」的场景。
06
性能对比:一张表说清楚
关键数据(来自 LangChain 实际测试):
• 简单请求(买咖啡):各模式都需要 3 次模型调用 • 重复请求:Skills 和 Handoffs 可节省 40% 调用(状态复用) • 多领域查询:Sub-Agents 总 token 约 9K,Skills 膨胀到 15K(差 67%!)
07
实战建议
判断题:你的场景选哪种模式?
组合使用
实际项目中,这四种模式经常组合。
比如:
Router(分类) ↓Sub-Agents(并行处理各领域) ↓Handoffs(流程式执行) ↓Skills(按需加载技能)
一个 Code Review 系统可能需要:
• Router 判断问题类型 • Sub-Agents 并行分析 Performance、Security、Logic、Style、Test • Handoffs 处理问题修复的流程
没有最好的模式,只有最适合场景的组合。
08
工程实践:五个黄金原则
原则一:控制 Agent 数量
研究发现,当 Agent 数量超过 5 个时,准确率趋于饱和或开始波动。协调开销随交互深度呈指数增长。
建议:将复杂任务分解为 3-5 个专业 Agent,而非堆砌大量通用 Agent。
原则二:星型拓扑 > 去中心化
中心协调的错误放大率约 4.4x,而去中心化拓扑的错误放大率高达 17x。
建议:采用星型拓扑,中心协调者负责分发和汇总。
原则三:监控错误级联
典型错误模式:Agent A 输出错误 → Agent B 盲目基于错误输入执行 → 错误累积放大。
建议:每个 Agent 执行完成后保存检查点,失败后从上一个成功检查点恢复。
class CheckpointManager: def save_checkpoint(self, agent_id: str, state: dict, task_id: str): checkpoint = { "task_id": task_id, "agent_id": agent_id, "state": state, "timestamp": datetime.now().isoformat() } self.db.save(f"checkpoint:{task_id}:{agent_id}", checkpoint) def restore_and_retry(self, failed_agent_id: str, task_id: str): checkpoints = self.db.get_range(f"checkpoint:{task_id}:*") last_valid = max(checkpoints, key=lambda c: c["timestamp"]) return last_valid["state"]
原则四:保持架构可替换性
协议层仍在快速演进(MCP、A2A),核心设计应支持热插拔。
class AgentProtocol(ABC): @abstractmethod def send_message(self, target: str, message: dict): passclass MCPProtocol(AgentProtocol): def send_message(self, target: str, message: dict): return self.mcp_client.send(target, message)class A2AProtocol(AgentProtocol): def send_message(self, target: str, message: dict): return self.a2a_client.delegate(target, message)# 协议可替换protocol: AgentProtocol = MCPProtocol() # 可切换为 A2AProtocol
原则五:设计可观测性
多 Agent 系统的调试复杂度远超单 Agent,需要完善的追踪机制。
from opentelemetry import tracetracer = trace.get_tracer(__name__)async def execute_agent_workflow(task: Task): with tracer.start_as_current_span("agent_workflow") as span: span.set_attribute("task_id", task.id) # Agent 执行逻辑
09
Claude Code 中的实现
好消息是:Claude Code 原生支持 Sub-Agents 和 Skills。
内置 Sub-Agents
Claude Code 内置了几个常用子代理:
| Explore | |||
| Plan | |||
| general-purpose |
创建自定义 Sub-Agent
/agents# → Create new agent# → 选择 User-level 或 Project-level# → 描述功能# → 选择工具权限# → 选择模型# → 保存
Handoffs 的工程实现
Claude Code 本身不提供原生 handoff 机制,但可以通过「链式 Sub-Agents」模拟:
1. 定义明确的阶段状态 2. 每个阶段是带角色约束的 Agent 3. 显式的阶段完成条件(Exit Criteria)
10
写在最后
写这篇文章的时候,我一直在想一个问题:
为什么很多团队用 AI 编程工具,却总觉得「差那么一点意思」?
后来我想明白了——
他们把 AI 当成了一个「更快的打字机」。
给一个指令,等一个结果,结束。
但真正的用法是:把 AI 当成一个团队来管理。
你会给团队里的每个人分配任务、设置权限、制定 SOP。
对 AI,也应该一样。
当你开始思考「这个任务该拆给谁」,而不是「怎么写更好的 prompt」,你才真正进入了 AI 编程的下一个阶段。

你的 AI 编程进化,从这里开始。
