 夜雨聆风
夜雨聆风📌 快速资源汇总
一、🔥 从一个真实的烦恼说起
你用 AI 助手用了多久了?
每次打开对话框,第一件事是什么?
重新介绍自己。
"我是一个做前端的独立开发者,在做一个 SaaS 产品,现在遇到一个问题……"
你说过一百遍了。上次说的它忘了,这次你重新说。
或者你去查邮件,AI 不知道你的邮件在哪里。你去处理日历,AI 不知道你今天有什么会议。你写代码,AI 不知道你的项目结构,不知道你喜欢什么技术栈,不知道你上周解决过同一个 bug。
大多数 AI 助手没有记忆,没有上下文,每次都从零开始。
你在用一个非常聪明但患有严重失忆症的助手。
OpenHuman 想解决的就是这件事——连接你所有的账号,每 20 分钟自动拉取一次数据,把你的邮件、日历、代码仓库、Notion、Slack 消息,全部压缩进一个本地知识库,让 Agent 在对话开始之前,就已经知道你是谁、你在做什么、你的上下文是什么。
不只是记得。而是真正了解你。
二、📦 这个项目是什么
项目名称:OpenHuman
作者:tinyhumansai(创始人:@senamakel)
⭐ Star 数:776
🍴 Fork 数:105
版本:v0.53.22(2026 年 5 月 9 日)
开源协议:GPL-3.0
状态:Early Beta,活跃开发中
技术栈:Rust 69.4% + TypeScript 26.6%
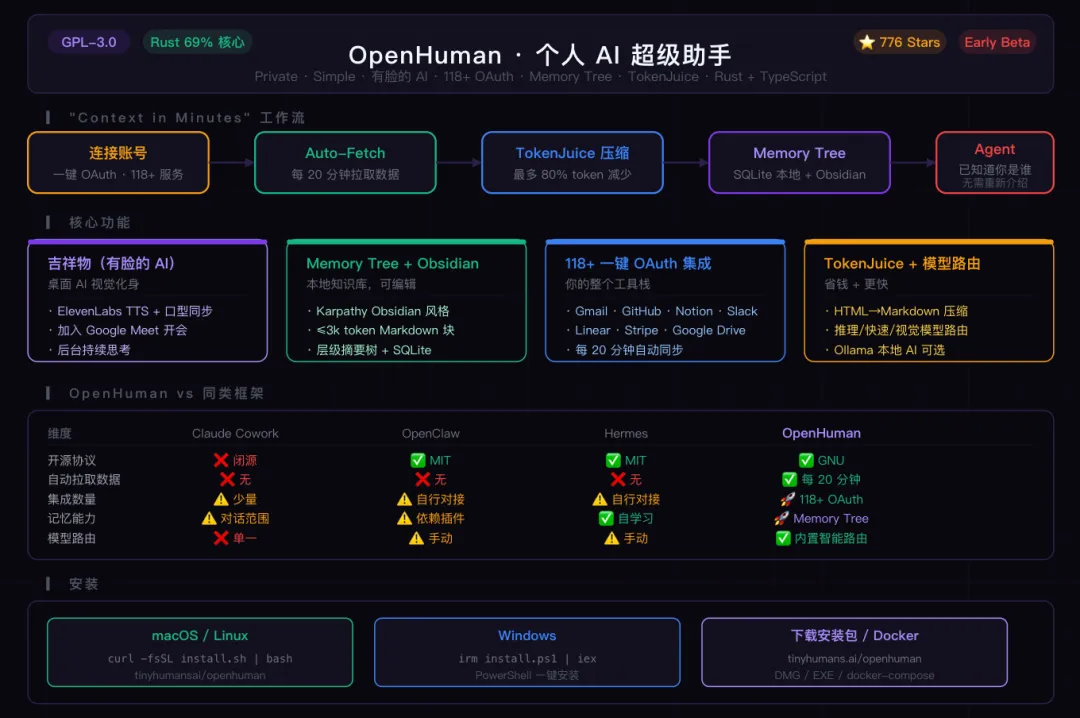
一句话定位:你的个人 AI 超级助手——UI 优先,拥有一张会说话的脸,118+ 一键集成自动拉取你的数据,本地记忆树让 Agent 几分钟内就真正了解你。
一个细节让这个项目和其他所有 Agent 项目不一样:这个 Agent 有脸。
一个桌面吉祥物,会说话,会对周围的事情作出反应,能以真实参与者身份加入你的 Google Meet 会议,嘴型和声音同步,在你停止打字后继续在后台思考。
这不是噱头,这是对"AI 助手应该以什么方式存在于你的生活里"的一个非常不同的答案。
和其他 Agent 框架的对比
这张表里最不同的一行是"自动拉取数据"——只有 OpenHuman 有。其他所有框架都需要你主动给 Agent 上下文,OpenHuman 是 Agent 自己去拿。
三、⚙️ 核心功能,一个个说清楚
1. Memory Tree + Obsidian Wiki:真正的长期记忆
这是整个项目最核心的设计,也是"context in minutes"这个承诺的底层实现。
你连接账号之后,OpenHuman 的 auto-fetch 机制每 20 分钟运行一次,从所有已连接的服务拉取新数据,把它压缩成 ≤3k token 的 Markdown 块,打分排序,存进本地 SQLite 数据库,同时生成 .md 文件放到一个 Obsidian 兼容的 Vault 里。
邮件 → 压缩 → Memory Tree
日历 → 压缩 → Memory Tree
GitHub PR → 压缩 → Memory Tree
Slack 消息 → 压缩 → Memory Tree
Notion 页面 → 压缩 → Memory Tree下次对话,Agent 开始之前就已经知道:你今天有什么会议,昨天有什么邮件没回,你的代码仓库里最近在做什么,你的项目文档里写了什么。
这个设计来自 Karpathy 的 Obsidian Wiki 工作流——把 LLM 的知识库外化成可以查看和编辑的 Markdown 文件,不是黑盒存储在云端,是放在你自己的机器上、可以打开 Obsidian 直接看的文本文件。
2. 118+ 一键 OAuth 集成
不用配 API Key,不用写连接器代码,一键 OAuth 授权:
通讯协作:Gmail、Outlook、Slack、Discord、Telegram、WhatsApp
生产力:Google Calendar、Notion、Linear、Jira、Confluence、Asana
代码与开发:GitHub、GitLab、Bitbucket、Vercel、Railway
云存储:Google Drive、Dropbox、OneDrive、Box
财务:Stripe、QuickBooks、Xero
……以及更多,共 118+ 种连接方式
每个连接都以类型化工具的形式暴露给 Agent,也就是说 Agent 不只是能"读取"这些服务的数据,还能对这些服务执行操作。
3. 桌面吉祥物(Mascot):有脸的 AI
这是最容易被低估、但其实最有意思的功能。
OpenHuman 的桌面吉祥物不是一个动图贴纸,它是 Agent 的视觉化身:
• 会说话:ElevenLabs TTS 驱动,声音和嘴型完全同步(lip-sync) • 有反应:对周围的事情(通知、日历提醒、你的输入)有视觉反应 • 加入 Google Meet:以真实参与者的身份出现在你的视频会议里,一个 AI 同事坐在那里开会 • 后台思考:你停止输入后它继续在后台工作,主动推送信息
这个设计回答了一个很有意思的问题:当 AI 变成真正的个人助手之后,它应该以什么形式存在? 是对话框里的一段文字,还是一个真实出现在你工作环境里的存在?
4. TokenJuice:最多 80% token 压缩
每一个工具调用结果、网页抓取内容、邮件正文、搜索结果,在进入 LLM 之前都会经过 TokenJuice 处理:
• HTML 转 Markdown • 长 URL 缩短 • 非 ASCII 字符清理 • 冗余内容移除
压缩后信息量不变,token 数量最多减少 80%,带来的效果是:响应更快、成本更低。
5. 智能模型路由
不同的任务交给不同的模型:
• 复杂推理任务 → 推理模型 • 快速响应任务 → 轻量模型 • 视觉理解任务 → 视觉模型 • 本地敏感任务 → Ollama 本地推理
用户不需要手动选模型,系统根据任务类型自动路由,在一个账号下完成。
6. 原生工具集
全部内置,不需要安装插件:
• Web 搜索:不依赖外部 API,内置 • 网页抓取:带 TokenJuice 压缩的 HTML 解析器 • 代码工具集:文件系统、git、lint、test、grep——完整的 coder 工具链 • 原生语音:STT 语音输入,ElevenLabs TTS 输出,吉祥物口型同步
四、🚀 怎么装、怎么用
方式一:安装脚本(macOS / Linux)
curl -fsSL https://raw.githubusercontent.com/tinyhumansai/openhuman/main/scripts/install.sh | bash方式二:Windows
irm https://raw.githubusercontent.com/tinyhumansai/openhuman/main/scripts/install.ps1 | iex方式三:下载安装包
访问 tinyhumans.ai/openhuman,下载 macOS DMG 或 Windows EXE,双击安装。
[配图:OpenHuman 桌面界面截图,展示吉祥物和主对话区]
首次设置
Step 1:启动 OpenHuman
首次打开,UI 引导你完成快速设置——不需要打开终端,不需要配置文件。
Step 2:连接你的账号
在集成页面,选择要连接的服务,一键 OAuth 授权。建议先连最常用的几个:
Gmail + Google Calendar → 邮件和日历上下文
GitHub → 代码仓库和 PR 上下文
Notion / Linear → 项目和任务上下文[配图:集成连接页面,OAuth 授权界面截图]
Step 3:等一个同步周期(约 20 分钟)
auto-fetch 第一次运行完成后,Memory Tree 里就有了你的基本上下文。
Step 4:打开 Obsidian 看看你的记忆树
把 OpenHuman 生成的 Vault 目录添加到 Obsidian,可以直接浏览和搜索 Agent 收集整理的所有内容。
[配图:Obsidian 里打开 Memory Tree 的截图]
Docker 部署(自托管)
git clone https://github.com/tinyhumansai/openhuman.git
cd openhuman
docker-compose up -d适合想自托管、完全控制数据的用户。
五、💡 三个真实使用场景
场景一:独立开发者,让 AI 真正进入你的工作流
背景:独立开发者同时在跑几个项目,用 GitHub + Linear + Notion + Gmail 管理工作。每次找 AI 帮忙,都要手动粘贴上下文。
操作:连接 GitHub、Linear、Notion、Gmail,等 Memory Tree 完成第一次同步。
效果:
• "帮我写一下昨天那个 #423 PR 的发布说明" → Agent 直接查到 PR 内容,不需要你粘贴 • "今天下午 3 点之前我需要做什么" → 结合 Linear 任务和 Gmail 邮件给出完整清单 • "帮我给 Alex 回邮件,关于上周那个 API 方案" → Agent 找到对应邮件线程,理解背景,起草回复
这三件事你以前每件都要手动复制粘贴。现在 Agent 自己知道。
场景二:Manager,在 Google Meet 里有一个 AI 同事
背景:产品经理每周要开很多会,会后需要整理会议纪要和跟进事项,很耗时间。
操作:让 OpenHuman 吉祥物加入 Google Meet 会议:
设置 → 吉祥物 → 加入会议 → 粘贴 Meet 链接吉祥物以参与者身份加入,全程记录讨论内容,结合 Memory Tree 里已有的项目背景理解会议上下文。
会议结束后主动生成:会议摘要、决策项、待跟进事项、责任人。
效果:再也不用自己做会议记录,也不用会后整理笔记。Agent 知道这个项目的背景,它整理的跟进事项比你自己手写的更完整。
场景三:个人知识管理,用 Memory Tree 建立自己的第二大脑
背景:有 Obsidian 使用习惯的知识工作者,之前一直手动维护笔记,但同步 Notion、邮件、日历里的信息太费时间。
操作:连接所有常用服务,让 OpenHuman 的 auto-fetch 自动把内容整理成 Obsidian 兼容的 Markdown 文件。
效果:一个定期自动更新的知识库,把你所有账号里的信息都沉淀下来,可以在 Obsidian 里全文搜索、手动添加链接、做双向链接图谱。相当于一个会自动整理资料的研究助理。
六、🐦 X 上的人怎么说
「吉祥物加入 Google Meet 这个功能我第一次看到的时候以为是开玩笑,真试了之后觉得这才是 AI 应该有的存在方式。」
——早期用户,X 平台
「Memory Tree 连上 GitHub + Linear + Notion 之后,第一次感觉 AI 真的知道我在干什么,不用每次解释。」
——独立开发者,Discord 社区
「TokenJuice 那个 80% 压缩比有点夸张,但实测 50-60% 还是有的,长文档上下文处理确实快了很多。」
——技术用户,GitHub Issues
「Rust 写的核心,数据本地加密存储,这个隐私方案对我来说比云端同步方案放心很多。」
——注重隐私的用户,Reddit r/tinyhumansai
「还是 Early Beta,某些集成偶尔有 bug,但整体方向是对的——这个思路比'你在对话框里喂 AI 上下文'高一个维度。」
——开发者,GitHub Issues 反馈
博主点评
这几条评价里,我觉得最准的是"高一个维度"这个判断。
现在大多数 AI 工具的使用范式是:用户主动提供上下文 → AI 处理 → 用户得到输出。
OpenHuman 想建立的范式是:AI 持续了解用户 → 用户提出任务 → AI 基于已有上下文处理。
这两种范式的差距,就是"工具"和"助手"的差距。
Memory Tree 的设计方向、auto-fetch 的机制、吉祥物在 Google Meet 里开会——这些功能指向同一个问题的同一个答案:AI 助手应该主动存在于你的工作流里,而不是等你去打开它。
它现在还是 Early Beta,有粗糙的地方,有 bug。但这个方向,值得关注。
七、🎯 值不值得现在就装?我的判断
适合谁
• ✅ 有大量工具集成需求的知识工作者:Gmail + Calendar + GitHub + Notion 全部一键连,自动同步,不用手动配 • ✅ Obsidian 用户:Memory Tree 生成的就是 Obsidian 兼容格式,直接接上你现有的工作流 • ✅ 想体验"有脸的 AI"的人:吉祥物功能是目前市场上罕见的,想试早期形态的可以装 • ✅ 注重隐私的用户:Rust 核心、数据本地加密、SQLite 本地存储,不走云端中转
要说清楚的局限
• ⚠️ Early Beta,有粗糙边缘:项目自己也在 README 里说了"expect rough edges",某些集成偶尔有 bug,不要带着生产级稳定性预期装 • ⚠️ Star 数还少(776):社区积累的踩坑经验和解决方案还有限,遇到问题主要靠 Issues 和 Discord • ⚠️ 吉祥物功能需要麦克风和摄像头权限:以及 ElevenLabs TTS 需要额外订阅才能用高质量语音 • ⚠️ 118+ 集成质量参差不齐:核心的 Gmail / GitHub / Notion 打磨较好,边缘集成可能稳定性差一些
最后说一句
大多数 AI 工具让你学会怎么和 AI 对话——OpenHuman 想做的是让 AI 学会怎么了解你。这两件事的难度和价值都不在同一个量级。它现在还粗糙,但方向是对的。
先装上,连两三个你最常用的账号,给它一个同步周期,看看 Memory Tree 里出现的第一份关于你自己的摘要是什么感觉。
主动了解你而不是等你解释——这个开源项目连接 118 个工具,每 20 分钟给自己更新一次你的上下文」**
推荐场景:AI 话题流量池(头条/知乎热榜),"主动了解你"vs"等你解释"是强对比,"118 个工具"制造规模感,泛 AI 读者好理解。
