 夜雨聆风
夜雨聆风论文:LLMs Corrupt Your Documents When You Delegate作者:Philippe Laban, Tobias Schnabel, Jennifer Neville(微软研究院)来源:arXiv 2026 | https://arxiv.org/abs/2604.15597
问题的起点:幻觉之外,还有「无声损坏」
AI 圈对幻觉(Hallucination)的讨论已经很多了。但幻觉描述的是模型「凭空编造」——它生成了不存在的内容。
这篇论文关注的是另一个更隐蔽的问题:
当你把一份真实文档交给 LLM 编辑,它在完成任务的同时,会不会悄悄损坏已有内容?
这个场景被称为 Delegated Work(委托工作):用户不再只是提问,而是把正在进行的工作资产——账本、代码库、乐谱、族谱——交给模型修改和维护。
Vibe Coding 就是典型例子:你描述意图,模型直接修改文件。
问题的关键在于:用户通常没有能力或时间逐行复核模型做出的所有改动。
一次幻觉,你能发现。几十轮委托交互积累下来的细微损坏,你很可能发现不了。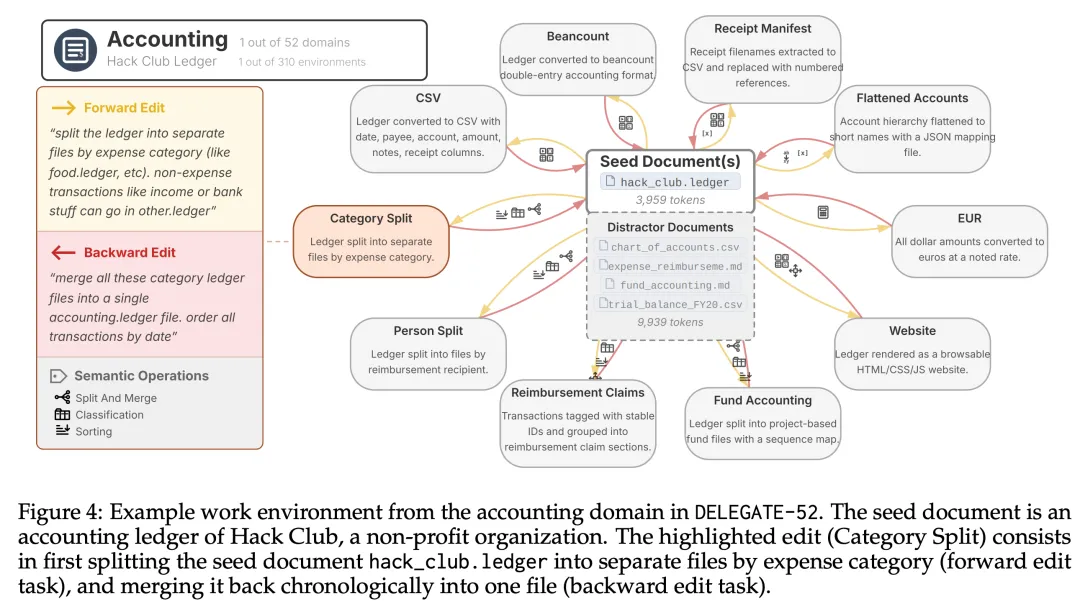 比如:
比如:
把一份账本扔给它,说「帮我按支出类别拆成几个文件,再合回一份按时间排序的总账」。
它很顺从,改完了,你随手扫了一眼,感觉没问题,就关掉了。
但你不知道的是——
金额悄悄变了。一条记录被合并错了。一个类别丢了。
不是整份文件崩掉。只是坏了几处。肉眼扫过去,反而更容易相信它。
这,就是「委托工作」最隐蔽的风险。
微软研究院最新发布了一篇论文,用数据证明了这件事有多严重。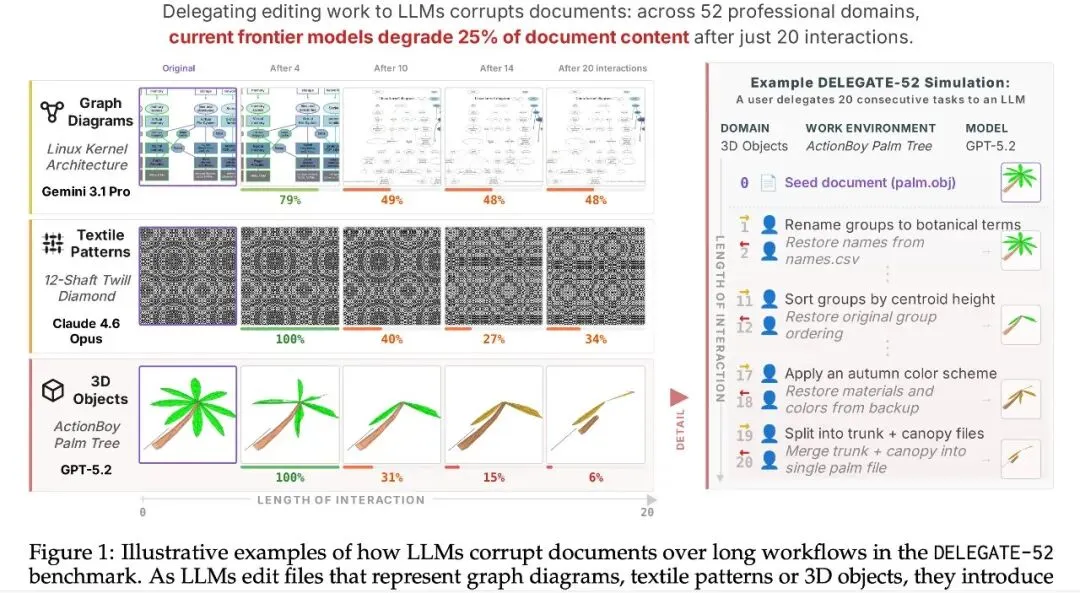
DELEGATE-52:一个跨 52 个职业领域的长流程委托基准
论文的第一个贡献是构建了 DELEGATE-52 基准测试。
为什么需要新基准
现有的 LLM 编辑基准(如代码编辑、文本简化、SVG 编辑)存在两个根本局限:
1. 领域单一:大多集中在代码或普通文本,不能反映知识工作的多样性 2. 流程太短:单步或少步测试,无法暴露长流程中的误差累积
DELEGATE-52 正是针对这两点设计的。
基准构成

DELEGATE-52 包含:
• 52 个职业领域,横跨 5 大类 • 310 个工作环境,每个领域 6 个环境 • 每个环境包含:一份真实种子文档(Seed Document)、5-10 个可逆编辑任务、一组干扰上下文(Distractor Context)
五大类别:
• Code & Configuration:Python、Docker、JSON、Makefile、DBSchema 等 11 个领域 • Science & Engineering:Circuit、Molecule、Crystal、Quantum、Robotics 等 11 个领域 • Creative & Media:MusicSheet、Screenplay、AudioSyn、Weaving、OBJ3D 等 11 个领域 • Structured Records:Accounting、Genealogy、Spreadsheet、GeoData 等 11 个领域 • Everyday:Recipe、Transit、Chess、Earnings、Playlist 等 8 个领域
所有种子文档均来自真实在线文档,无合成数据,长度约 2–5k tokens。干扰上下文约 8–12k tokens。
核心方法:往返中继(Round-trip Relay)
这是论文最有技术价值的设计。
往返编辑原语(Round-trip Primitive)
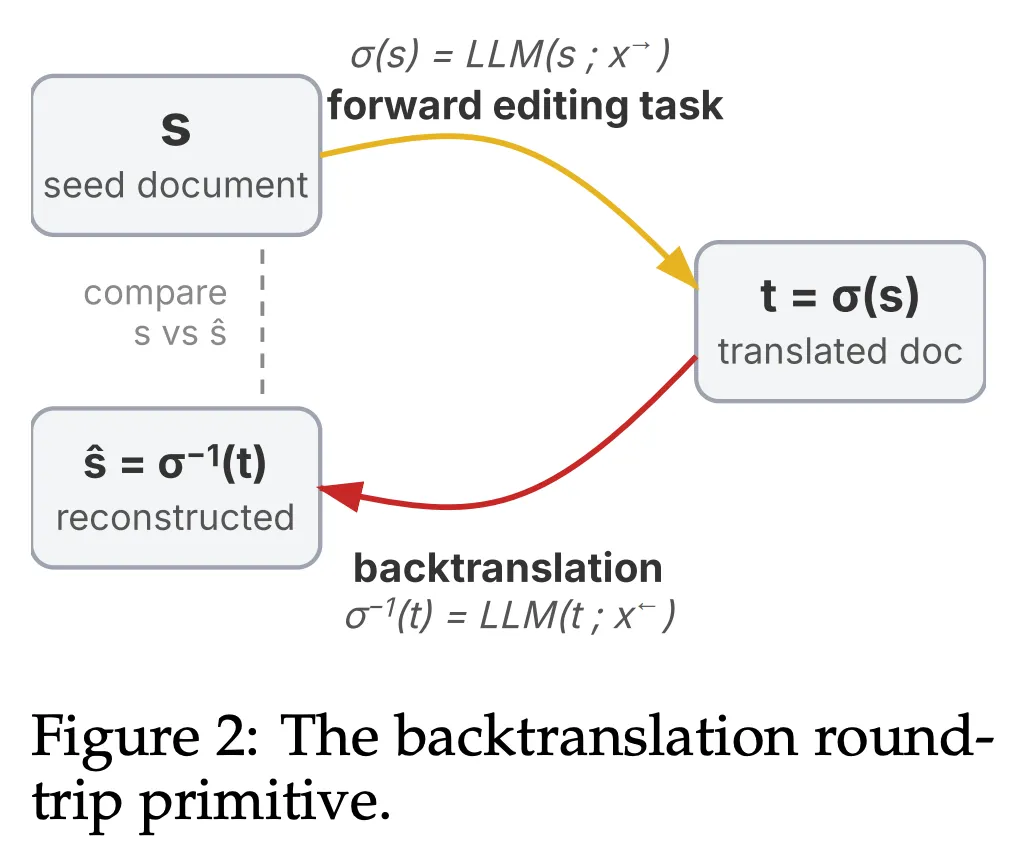
形式化定义如下:
给定种子文档 s,定义一对可逆编辑任务 (x→, x←),分别对应正向变换 σ 和其逆变换 σ⁻¹:
1. 正向:模型执行 x→,将 s 变换为 t = σ(s) = LLM(s; x→) 2. 反向:模型执行 x←,将 t 还原为 ŝ = σ⁻¹(t) = LLM(t; x←)
若模型完美执行,则 ŝ ≡ s(语义等价)。
往返编辑的价值在于:无需人工标注标准答案。原始文档 s 本身就是评估基准。差距 sim(s, ŝ) 即为一轮往返的重构质量。
往返中继(Relay)模拟长流程
单次往返不足以暴露长流程风险。论文将 N 组往返串联:
RS@k(s) = sim(s, ŝ_{k/2})
即第 k 次交互(k/2 组往返)后,重建文档与原始文档的语义相似度。主实验使用 k=20(10 组往返)。
领域专属解析评分(Domain-Specific Parsing)
通用文本相似度指标(Levenshtein、ROUGE、Embedding Similarity)在专业文档评估上有系统性缺陷:
• 表面层面方法(Levenshtein、ROUGE-L)过度惩罚:等价表示(如 200g vs 0.2kg)会被判为不同 • 语义层面方法(Embedding、LLM-as-Judge)过度宽容:语义损坏(如 200g 变 800g)会被视为相似
论文为每个领域实现了专属解析器:
• Recipe:解析食材(名称、数量、单位)、步骤、提示,按权重(40%/40%/20%)加权评分 • Accounting:解析日期、金额、类别,数值精度敏感 • Graph:解析节点集合与边集合,结构完整性优先
这套设计使得「200g 变 0.2kg」可以等价,而「200g 变 800g」必须被判为严重错误。
实验验证:包括 GPT 5.4 LLM-as-Judge 在内的所有通用方法,与领域专属分数的相关性最高只有约 25%。
实验结果:19 个模型全部退化
主要结论
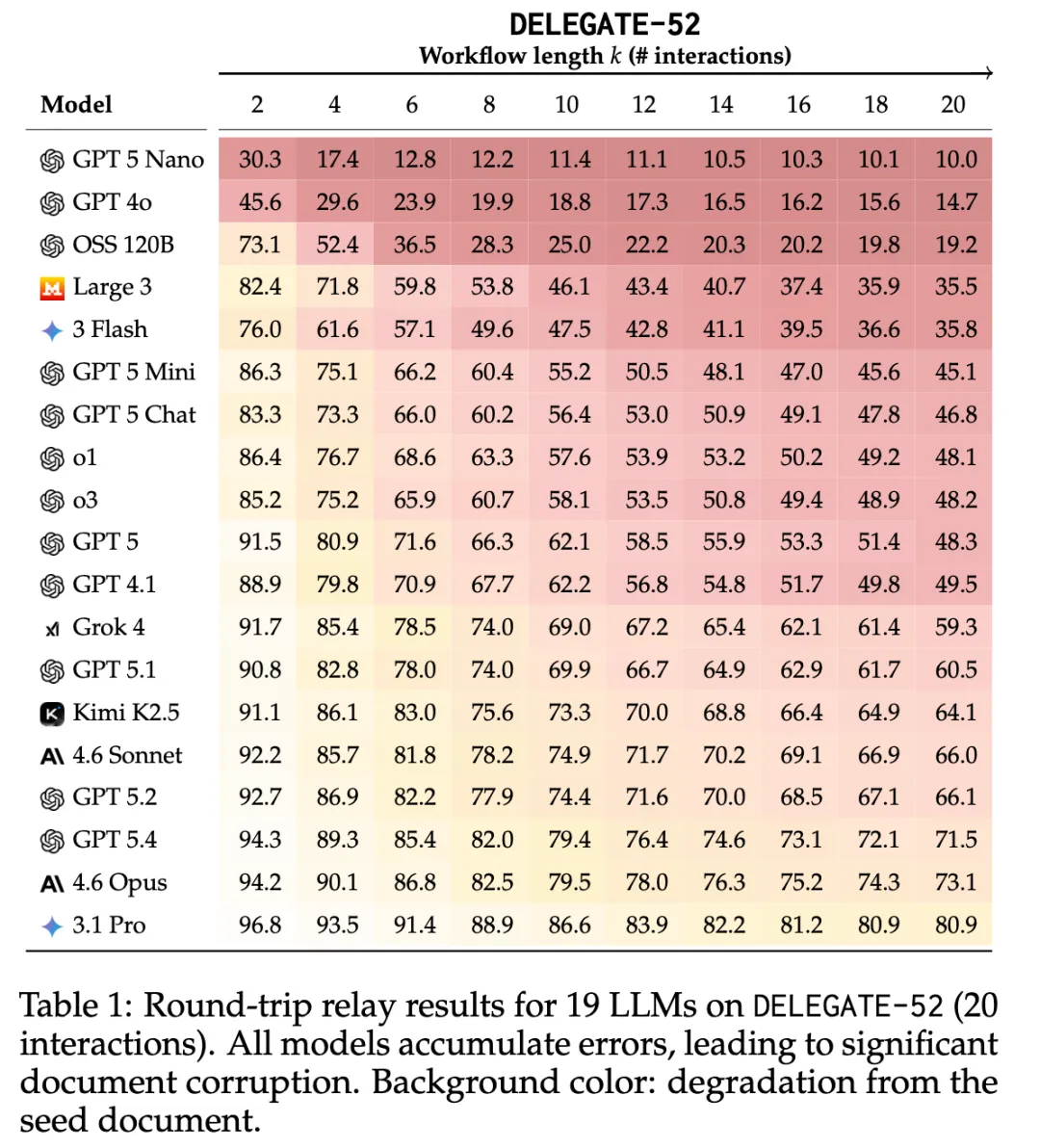
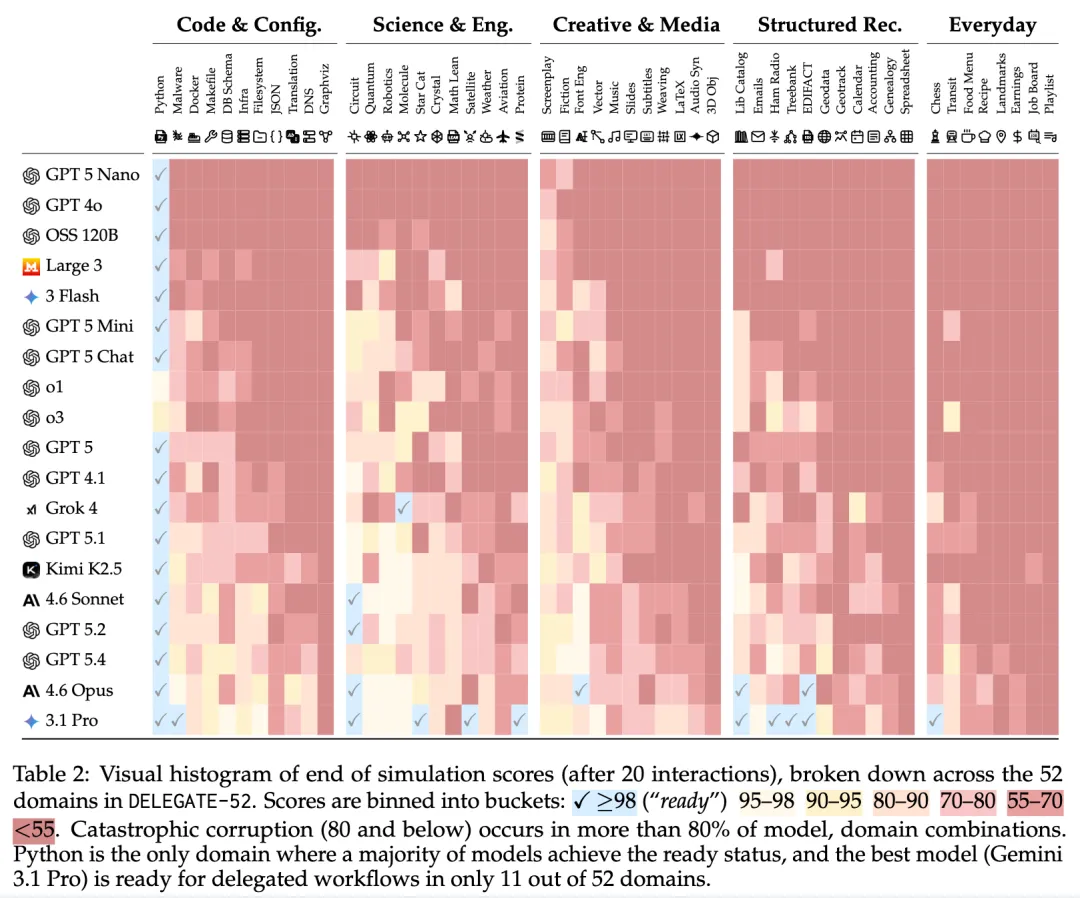
在 20 次交互(10 组往返)后:
所有 19 个模型平均退化约 50%。前沿模型(Gemini 3.1 Pro、Claude 4.6 Opus、GPT 5.4)平均退化约 25%。
短流程表现不预测长流程
GPT 5 与 Kimi K2.5 在 RS@2 几乎相同(91.5 vs 91.1),RS@20 差距扩大至 15.8 分(48.3 vs 64.1)。
这意味着:以 2 次交互评估的 benchmark 结果,对长流程委托工作的可靠性判断几乎无效。
Python 是唯一例外
论文定义 RS@20 ≥ 98% 为「可放心委托」(ready)。
• Python 是唯一一个多数模型(17/19)达到 ready 的领域 • 最强的 Gemini 3.1 Pro 在 52 个领域中也只有 11 个达到 ready • 在 80% 的模型-领域组合中,至少出现了 20% 的内容损坏
关键分析发现
发现一:工具使用(Agentic Harness)不改善,反而恶化
论文为部分模型配备了基础智能体外壳,工具包括:文件读写、代码执行、搜索替换。
理论上,精准工具调用应当减少整体重写带来的内容损失。
实验结果却相反:4 个测试模型在有工具时,平均额外损坏 6%。
根因分析:
• 每个任务平均调用 8–12 次工具,输入 token 量扩大 2–5 倍 • 长上下文保持性能本身是 LLM 弱点,工具调用放大了这一压力 • 多数模型仍偏向直接生成文件(file writing),而非写程序精确修改(code execution) • 即使更强的 GPT 5.4 的 code execution 占比提升至 45%,也未能消除退化
结论:朴素工具外壳不等于可靠智能体工程。
发现二:稀疏大事故(Critical Failures)解释 80% 退化
论文将单轮掉分 ≥ 10 分定义为 critical failure。
对所有模型的分析显示:文档损坏不是「千刀万剐」式的线性积累,而是高度集中于少数大事故。
稀疏大事故解释了约 80% 的总退化量。
这一发现有重要含义:模型的长期可靠性,不应用平均曲线判断,而应用大事故频率和时机衡量。强模型不是消除了大事故,而是更晚发生、发生次数更少。
发现三:删除 vs 污染,强弱模型的败坏方式不同
论文将退化分解为两个组件:
• Deletion(删除):元素数量减少,内容丢失 • Corruption(污染):元素数量不变,但语义被改错
结果:
• 弱模型(GPT 4o、GPT 5 Nano):70–73% 的退化来自 deletion • 前沿模型(Claude 4.6 Opus、4.6 Sonnet):deletion 只解释 22–27%,剩余是 corruption
这对实际使用影响很大:删除是可见的缺失,pollution 是隐性的错误。肉眼扫过一份看起来完整的文档,几乎不可能察觉内容被悄悄改错。
影响因素实验
文档大小与交互长度的复合效应
GPT 5.4 在不同文档规模下的 RS@20:
• 1k token 文档:91.4 • 3k token 文档(默认):约 71.5 • 10k token 文档:59.9
每增加 1,000 tokens,2 次交互后损失约 0.7%,20 次交互后损失约 3.6%。 负面效应随交互长度复合放大,不是线性叠加。
中继长度没有平台期
将中继延伸至 50 组往返(100 次交互),所有模型持续单调下降,无明显平台期。GPT 5.4 在 100 次交互后降至 58.7。
干扰上下文的累积伤害
加入干扰文档(Distractor Context)的影响:
• 短期(2 次交互):仅差 0.4–4% • 长期(20 次交互):扩大至 2–8%
与文档大小效应类似,干扰的负面影响在长流程中会逐步放大。
图像领域:退化远比文本严重
论文还构建了 6 个视觉工作环境,测试 9 个图像编辑模型。
结果:
• 最强图像模型 RS@20 仅 28–30%,相比文本模型的 70–80% 差距悬殊 • 即使只经过 2 次交互,没有任何图像编辑模型超过 65% • 文本模型 20 次交互后的表现,仍好于图像模型 2 次交互后的表现
结论:当前图像编辑模型完全不适合委托工作场景。
对实践者的意义
对 AI 系统开发者
• DELEGATE-52 的 52 个领域可改造为 52 个 mini-gym,用于强化学习训练 • Reward 设计必须同时捕捉 instruction-following 和 content preservation,单独优化任一目标都会导致 reward hacking • 当前 agentic 系统的工具设计,需要专门针对内容完整性做优化,朴素工具堆叠不够
对工程实践者
• 不要用短流程 benchmark 评估长流程场景的可靠性 • 对重要文档引入版本控制机制:每次 AI 编辑前保存快照,支持 diff 比对和回滚 • 智能体设计上,优先小步提交、局部补丁、可回滚,而非一次性交给模型整个仓库 • 基于领域特性选择 AI 工具:programmatic/structured 领域(Python、DBSchema)可信度更高;自然语言密集、词汇丰富的领域(Recipe、Earnings、Fiction)风险更大
对普通用户
• AI 能力是锯齿形的(Jagged Frontier):在某个领域表现强,不代表在其他领域同样可靠 • 长流程委托后,对关键字段进行抽查,而不是整体扫一眼 • 对高价值文档(合同、财务记录、研究数据),委托 AI 修改后需要人工核验
论文局限性
作者坦诚地列出了几点限制:
1. 单轮交互假设:实验中每条指令都是充分指定的单轮会话。真实用户常常表达不完整,需要多轮澄清。多轮场景可能进一步放大退化 2. 任务空间受限:方法依赖可逆任务,对开放式生成、沟通、规划等不可逆工作任务尚不适用 3. 工具外壳是基础版本:不代表优秀智能体工程的上限,结论应为「朴素外壳不够」,而非「工具无用」 4. 实验规模限制:出于成本和上下文窗口限制,文档规模和中继长度都有上界,而论文额外实验表明这些参数增大时退化会更严重
总结
这篇论文用一个核心问题重新定位了 LLM 可靠性评估:
不是「模型能不能完成任务」,而是「模型完成任务时,能不能同时保护好你的工作资产」。
两个最值得记住的数字:
• 50%:所有测试模型在 20 次委托交互后的平均文档完整性损失 • 25%:前沿模型(Gemini 3.1 Pro、Claude 4.6 Opus、GPT 5.4)在同等条件下的平均损失
当我们把 AI 定位成「能干的同事」时,需要同时问清楚:它是否也是可靠的?
目前的答案,是不确定的。
论文来源:Philippe Laban, Tobias Schnabel, Jennifer Neville. "LLMs Corrupt Your Documents When You Delegate." arXiv 2026.论文链接:https://arxiv.org/abs/2604.15597代码与数据集:github.com/microsoft/DELEGATE52
