 夜雨聆风
夜雨聆风
PART 01
PART 02
第一,CXL.io。该部分与PCIe类似,主要负责设备发现、枚举、配置、中断和基础I/O通信,是CXL设备接入系统的基础。
第二,CXL.cache。该协议允许设备访问主机内存并保持缓存一致性,适用于GPU、DPU、FPGA、AI加速器等需要共享主机内存或缓存数据的设备。
第三,CXL.mem。该协议允许主机访问设备侧内存,使外部内存扩展设备成为系统内存层级的一部分,是CXL内存扩展和内存池化的核心协议基础。
第一,CXL内存扩展控制器芯片。该类芯片位于主机CXL链路与后端DDR DRAM之间,负责协议转换、内存访问调度、错误校验、带宽管理和安全隔离,是CXL内存扩展模组的核心芯片。
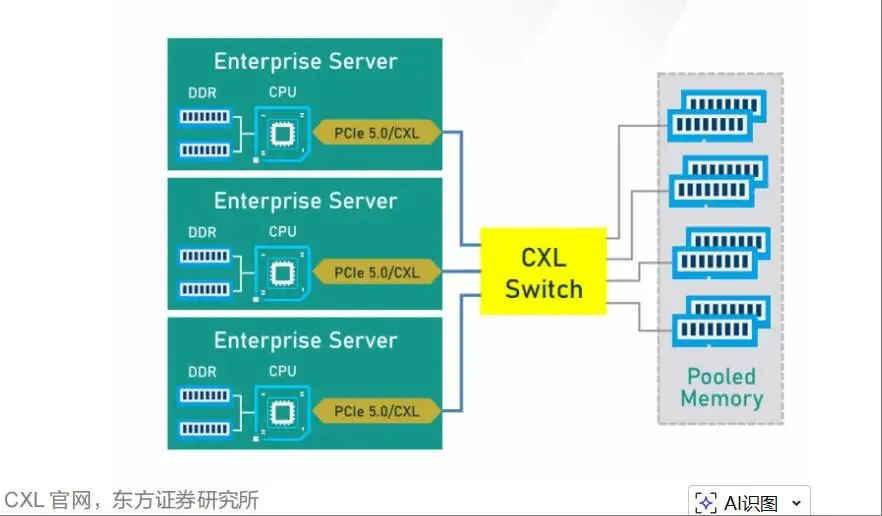
第二,CXL Switch芯片。该类芯片承担多主机、多设备和多内存池之间的交换连接功能,是从点对点内存扩展走向多节点内存池化、Fabric架构和资源动态调度的关键。
第三,CXL内存模组与扩展卡。包括基于DDR5 DRAM的CXL Memory Module、E3.S形态的CXL内存扩展模块、PCIe插卡形态的CXL扩展卡,以及未来结合DRAM、NAND、SCM等介质的混合内存模组。
第四,配套管理芯片。包括SPD、EEPROM、VPD等芯片,用于设备识别、参数管理、系统级校验、固件信息存储和可靠性管理。随着CXL内存扩展模组进入服务器平台,配套管理芯片的价值也将同步提升。
第五,服务器与系统级方案。CXL最终需要在服务器整机、云基础设施、数据库系统、AI推理框架、操作系统内存管理和调度软件中落地,因此服务器厂商和云厂商是CXL产业化的重要推动者。
PART 03
第一,长上下文推理提升KV Cache容量需求。模型上下文窗口越长,KV Cache占用越大。随着长文本处理、代码库理解、法律金融文档分析、多轮智能体任务成为重要应用,单次请求需要保存和访问的上下文状态显著增加。若完全依赖GPU HBM保存KV Cache,将限制并发数量并提高成本;若频繁卸载到SSD,又会导致延迟放大。CXL内存池可以作为KV Cache的高性能共享存储层,提高容量弹性。
第二,高并发推理要求资源动态调度。推理请求具有明显波动性,不同任务对算力、内存和带宽的需求差异较大。传统静态绑定资源的方式容易导致资源利用率下降。CXL内存池化可以将内存资源从单机绑定中释放出来,按业务负载动态分配,提高资源利用效率。
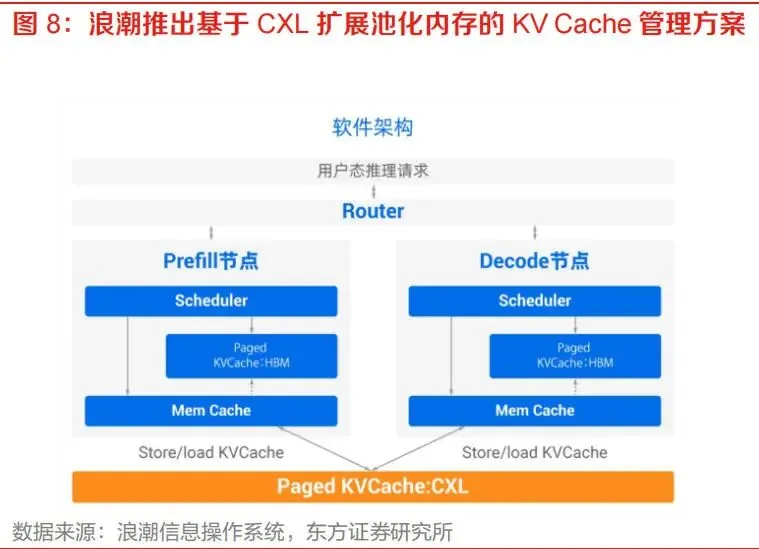
第三,Prefill和Decode阶段分离催生共享缓存需求。大模型推理通常可分为Prefill和Decode阶段。Prefill阶段更偏计算密集,Decode阶段更偏访存和串行生成。若两类节点分离部署,KV Cache需要在节点之间传输。浪潮MantaKV方案的思路是将Prefill节点产生的海量KV Cache集中存储在CXL池化共享内存中,Decode节点可直接访问,从而减少重复搬运。
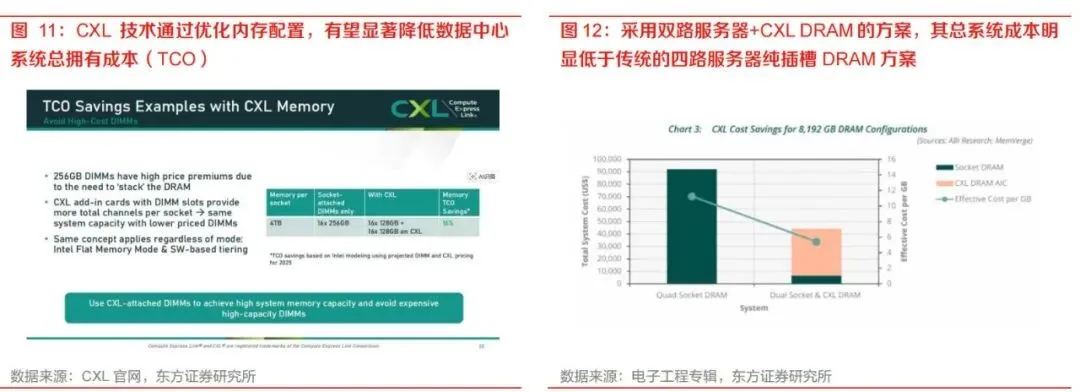
第四,AI基础设施TCO压力推动更经济的内存扩展方案。高容量DIMM价格存在显著溢价。资料中提到,在单路4TB内存配置示例中,传统方案需要16条256GB DIMM,而CXL方案可采用"16条128GB本地DIMM加16条128GB CXL附加DIMM"的组合。由于128GB DIMM单价更低,CXL方案在满足同等容量情况下有望带来约16%的TCO节省。对于大规模数据中心而言,内存成本优化具有显著商业价值。
PART 04

CXL 1.x阶段主要实现设备直连和基础内存扩展能力,适用于单主机与单设备之间的低延迟连接。该阶段的意义在于验证CXL协议在CPU与加速器、内存扩展设备之间的可行性。
CXL 2.0阶段引入Switch和内存池化能力,是CXL从点对点扩展走向共享资源架构的关键一步。通过CXL Switch,多台主机可以连接到多个CXL设备,内存资源可以被池化,并根据需求动态分配给不同服务器。这一能力对云计算、数据库和AI推理具有重要意义。
CXL 3.0阶段进一步支持Fabric架构,提高组网灵活性,并将数据速率提升至64GT/s。Fabric能力意味着CXL可以从单机或单机柜内部扩展,向更复杂的数据中心资源互联架构演进。对于超大规模AI集群而言,Fabric化是实现资源解耦和弹性调度的基础。
CXL 4.0阶段将数据速率进一步提升至128GT/s,相较CXL 3.0翻倍,并增强多级交换和动态设备管理能力。随着速率提升,CXL在带宽层面的短板将进一步缩小,其在高性能内存扩展和跨设备互联中的适用范围将扩大。
Type 1设备通常是不带本地内存或不暴露本地内存给主机的加速器,主要使用CXL.cache与主机进行缓存一致性访问。
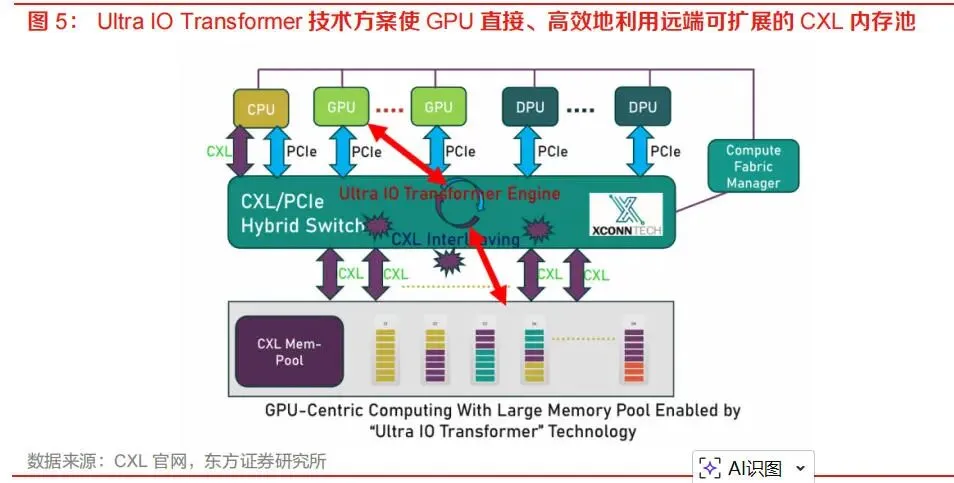
Type 2设备通常是带有本地内存的加速器,如GPU、FPGA、DPU等,既可能访问主机内存,也可能让主机访问设备侧内存,因此会同时涉及CXL.cache和CXL.mem。
Type 3设备主要是内存扩展设备,不具备复杂计算能力,核心作用是向主机提供额外内存容量。CXL内存扩展控制器芯片和CXL Memory Module多属于Type 3相关范畴。澜起科技发布的基于CXL 3.1 Type 3标准设计的内存扩展控制器芯片,正是该方向的代表性产品。
第一,内存从"服务器私有资源"变成"可调度资源"。在云数据中心中,内存使用率往往存在不均衡现象。一些节点内存不足,另一些节点内存闲置。CXL内存池可以提高整体资源利用率。
第二,服务器配置从"峰值静态配置"转向"按需动态配置"。传统服务器需要按照最极端负载配置内存,导致平时资源浪费。CXL池化后,部分峰值需求可以由共享内存池承接。
第三,系统设计从"节点级优化"走向"集群级优化"。AI推理、数据库和云原生应用越来越强调跨节点资源协同。CXL为内存资源的集群级调度提供硬件基础。
PCIe:核心定位是通用高速I/O互连,主要连接CPU与SSD、网卡、GPU等外设。其典型优势在于生态成熟、兼容性强、成本较低;主要局限是主要承载I/O语义,缺乏内存一致性能力。PCIe与CXL的关系是:CXL基于PCIe物理层演进而来。
CXL:核心定位是一致性内存互连,主要连接CPU、加速器、内存扩展设备、Switch。其典型优势是支持内存扩展、缓存一致性、内存池化;主要局限是生态仍处早期,软件适配复杂。CXL是数据中心内存架构升级的核心技术。
NVLink:核心定位是GPU高速互连,主要连接GPU与GPU、GPU与CPU。其典型优势是带宽高、适合GPU计算集群;主要局限是生态偏封闭,主要依附英伟达平台。NVLink与CXL形成互补关系,服务GPU内部及近端互联。
RDMA:核心定位是远程直接内存访问,主要连接跨服务器节点。其典型优势是网络范围广,适合分布式系统;主要局限是延迟高于近端内存互连,软件栈复杂。RDMA与CXL共同构成跨节点与近端内存体系。
以太网与InfiniBand:核心定位是数据中心网络,主要连接服务器集群。其典型优势是覆盖距离长、生态成熟;主要局限是延迟较高,不适合内存级访问。以太网与InfiniBand和CXL处于不同互连层级。
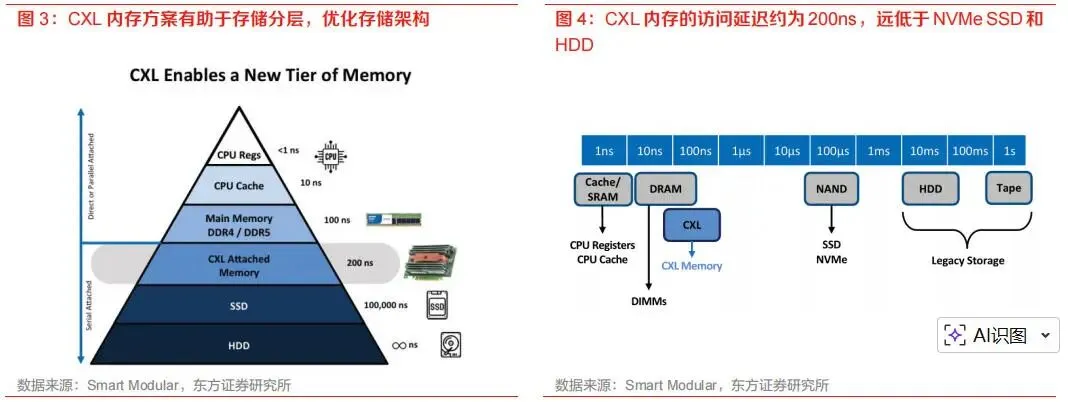
第一,延迟控制。CXL访问延迟虽然远低于SSD,但仍高于本地DRAM。对于延迟极敏感应用,如果软件没有做好数据冷热分层和访问调度,CXL可能带来性能波动。因此,CXL的价值需要结合负载特征判断,不能简单将其视为本地DRAM的完全替代。
第二,带宽与拥塞管理。多主机、多设备共享CXL内存池时,可能出现链路争用和热点访问。CXL Switch需要具备优秀的QoS、拥塞控制和隔离能力,系统软件也需要避免多个高负载应用同时争抢同一内存资源。
第三,缓存一致性和安全隔离。CXL引入一致性机制后,系统复杂度上升。云计算场景中,不同租户之间的内存隔离、安全访问和故障隔离非常关键,任何一致性错误、越权访问或数据泄露都可能造成严重后果。
第四,软件栈适配。硬件支持CXL只是第一步,操作系统、虚拟化平台、数据库、AI推理框架和调度系统都需要理解CXL内存的性能特征,并将其纳入内存分配和数据放置策略。没有软件栈配合,CXL可能只是一块昂贵的外部内存。
第五,生态互操作。CXL涉及CPU、BIOS、操作系统、控制器、Switch、内存颗粒、模组、服务器主板和管理软件。任一环节兼容性不足,都可能影响客户部署。早期市场中,合规测试、客户验证和跨厂商互通将是决定产品能否量产的关键。
高带宽方面,CXL 4.0将速率提升至128GT/s,未来随着PCIe物理层继续演进,CXL链路带宽仍有提升空间。带宽提升有助于扩大CXL在高性能AI推理、HPC和数据库场景中的适用性。
低延迟方面,控制器芯片、Switch芯片和软件栈将持续优化访问路径,减少协议处理、地址转换和调度开销。对于CXL而言,延迟优化与带宽提升同样重要,因为其定位接近内存层级而非传统存储层级。
池化方面,CXL将从单机内存扩展逐步走向多主机共享内存池、机柜级内存池和数据中心级资源组合。内存池化是CXL最大商业价值之一,有助于提升云数据中心资源利用率。
智能化方面,CXL控制器和系统软件可能引入更多数据冷热识别、访问预测、压缩、纠删、QoS调度和故障预测功能。未来CXL设备可能不只是被动提供内存,而是具备一定智能内存管理能力。
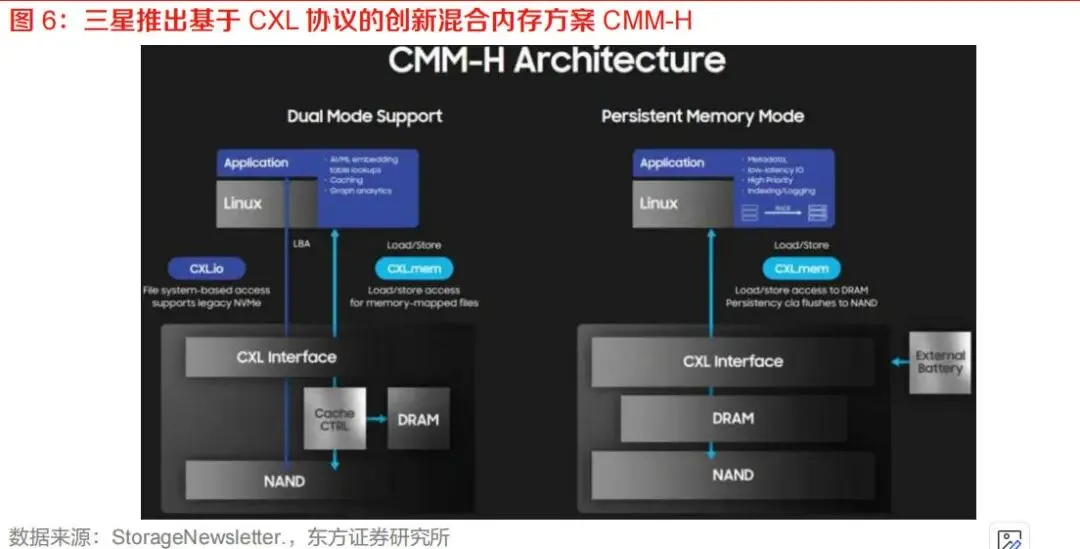
多介质融合方面,DRAM、NAND、持久化内存和未来新型存储介质可能通过CXL被统一纳入系统内存层级。三星CMM-H所代表的混合存储模组正体现出这一方向。长期看,CXL可能成为连接多种存储介质、构建分层内存系统的重要协议基础。
PART 05
2025年市场规模约0.12亿美元,为基准年,按2030年17亿美元、2025年至2030年复合增速170%反推得出; 2026年约0.32亿美元,同比增长170%,对应产品从样品验证进入小批量导入阶段; 2027年约0.86亿美元,同比增长170%,对应内存扩展控制器和部分Switch需求开始放大; 2028年约2.33亿美元,同比增长170%,对应AI服务器、云数据库等场景批量部署提升; 2029年约6.30亿美元,同比增长170%,对应CXL模组渗透率进一步提升; 2030年约17.00亿美元,同比增长170%,对应公开预测目标值。
2024年份额接近0%,处于样品、验证和早期试点阶段;
2025年至2026年份额进入低个位数,仍以试点为主,头部云厂商、数据库和AI推理场景先行验证;
2027年至2028年渗透率进入加速期,随CXL 2.0/3.0生态完善,内存扩展模组放量;
2030年份额达到约15%,CXL有望成为中高端服务器DRAM配置的重要组成部分。
第一,从CXL全组件口径看,公开机构给出的2030年前后市场空间存在较大差异,保守口径约为20亿至30亿美元量级,积极口径可达百亿美元级别。考虑到CXL生态仍处于早期,短期更适合采用Global Market Insights相对保守口径作为底部参考,同时将Strategic Market Research口径作为乐观情景参考。
第二,从CXL互连芯片口径看,2030年17亿美元的市场规模更贴近控制器、Switch、Retimer等芯片公司的可服务市场。该数据对于澜起科技等控制器厂商、以及潜在CXL Switch和高速互连芯片厂商更具参考意义。
第三,从服务器DRAM渗透率看,2030年约15%的份额意味着CXL内存扩展并非小众功能,而可能成为AI服务器和高端云服务器的重要内存配置方式。该渗透率将直接决定CXL模组、控制器芯片和配套管理芯片的出货弹性。
第四,市场规模测算应采用"总市场—芯片市场—渗透率"三层框架:CXL组件总市场反映行业天花板,CXL互连芯片市场反映芯片企业收入空间,CXL在服务器DRAM中的份额反映产业落地深度。三者结合,才能更准确判断行业投资价值。
第一,AI推理规模扩张。随着大模型应用从训练竞赛进入推理变现,推理基础设施的成本效率成为核心问题。CXL可在内存容量、缓存复用和TCO优化方面提供支撑。训练阶段往往强调单次大规模计算任务,而推理阶段强调持续服务能力、低延迟响应、高并发请求和单位Token成本。CXL对推理场景的价值,正是在于用更合理的内存层级承载推理过程中的热数据、温数据和共享缓存。
第二,长上下文和Agent应用普及。长上下文对KV Cache容量需求极高,Agent任务又会引入更多历史状态、工具调用数据、检索结果和中间计划,对共享内存和缓存管理提出新要求。如果未来模型上下文窗口继续扩大,CXL内存池的边际价值会同步提升。
第三,CXL标准持续升级。CXL 3.0、4.0在速率、Fabric、多级交换和动态管理方面持续增强,为更大规模部署提供基础。标准升级的意义不仅是带宽提升,更重要的是让CXL从单设备扩展能力,逐渐演进为可管理、可组合、可池化的数据中心基础设施。
第四,头部厂商示范效应。英伟达、阿里云、浪潮、三星、SK海力士等企业的产品和方案会影响行业采用节奏。头部厂商一旦在实际部署中验证经济性,将带动上下游加速投入。CXL行业具有明显生态属性,单一芯片厂商很难独立推动行业爆发,必须依赖CPU平台、存储原厂、服务器厂商和云客户共同完成闭环。
第五,国产化和供应链安全。国内AI服务器和数据中心建设需要自主可控的内存扩展、控制器和模组方案。CXL作为新兴架构,为国内厂商提供了在新标准下建立先发优势的机会。与一些成熟赛道相比,CXL格局尚未完全固化,国内企业若能在客户验证和产品迭代中跑在前列,有望获得更高参与度。
一是增加CXL控制器和相关接口芯片。每个CXL内存模组都需要控制器芯片,高速链路中还可能需要Retimer、时钟、电源管理和管理存储芯片。
二是增加CXL内存扩展模组。传统服务器以内存条直连CPU为主,CXL则增加外部内存扩展设备,使服务器内存配置更加灵活。
三是增加CXL Switch和系统级资源池化设备。当服务器从单机扩展走向机柜级共享内存池时,CXL Switch、线缆、背板、管理软件和系统集成价值量将上升。
PART 06
上游主要包括EDA工具、IP授权、先进制程晶圆制造、封装测试、DDR5 DRAM颗粒、NAND颗粒、PCB、连接器、电源管理芯片、时钟芯片和散热材料。其中,高速SerDes IP、PCIe/CXL协议IP、DDR控制器IP和先进封装能力是CXL控制器和Switch芯片设计的重要基础。
中游主要包括CXL控制器芯片厂商、CXL Switch芯片厂商、内存模组厂商、eSSD厂商、VPD/SPD/EEPROM芯片厂商和服务器板卡厂商。该环节承担协议实现、模组设计、硬件验证、固件开发和系统适配,是产业链价值集中的核心环节。
下游主要包括云计算厂商、AI服务器厂商、数据库厂商、HPC客户、互联网公司、金融机构、科研机构和企业级数据中心用户。下游客户的真实工作负载验证决定CXL产业能否从样品走向量产。
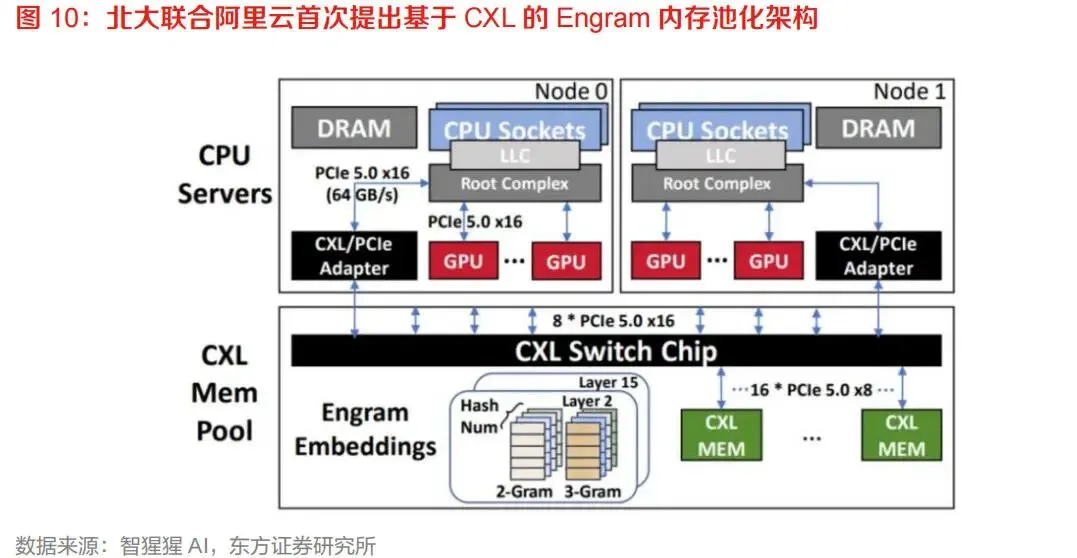
AI推理是最具成长弹性的场景。CXL可用于扩展KV Cache存储、支持Prefill/Decode解耦、提升缓存复用率和降低推理成本。浪潮MantaKV和北大联合阿里云的Engram方案均体现了CXL在AI推理软件栈中的应用潜力。
云数据库是较早具备商业化逻辑的场景。阿里云基于CXL 2.0 Switch技术的PolarDB数据库专用服务器,通过CXL高速互连构建分布式内存池,实现百纳秒级延迟和数TB/s带宽的远程内存访问,使内存资源池化共享、按需调度。数据库对内存容量、延迟和一致性要求较高,是CXL验证价值的重要场景。
HPC和科研计算也适合CXL。高性能计算任务常常存在大内存需求,传统扩展方式成本较高。CXL可以为HPC提供更加灵活的内存容量层。
虚拟化和云原生场景同样具备潜力。云服务商可通过CXL内存池改善不同租户、不同实例之间的内存配置效率,降低资源碎片化。
PART 07
第一类是CPU、GPU和加速器厂商,包括英特尔、AMD、英伟达等。这些企业决定服务器平台是否支持CXL协议,也决定CXL在主流AI和数据中心平台中的可用性。CPU平台支持是CXL普及的基础,GPU和加速器支持则决定其在AI场景中的深度。
第二类是存储原厂,包括三星、SK海力士、美光等。这些企业具备DRAM颗粒和内存模组能力,是CXL Memory Module的重要推动者。三星推出CMM-H混合存储CXL模组,将DRAM和NAND结合,为AI推理等场景提供兼具大容量、高性能和持久性的方案。SK海力士完成CXL 2.0 DDR5客户验证,表明主流存储厂商正在推动产品化。
第三类是互连芯片和控制器厂商,包括澜起科技、Astera Labs、Microchip、Marvell等。该类厂商提供CXL控制器、Retimer、Switch或相关连接芯片,是CXL硬件生态的核心。
第四类是云厂商和服务器厂商,包括阿里云、谷歌、微软、Meta、浪潮等。这些企业既是CXL方案的客户,也是应用创新的推动者。CXL最终是否具备商业价值,需要在这些企业的真实数据中心负载中得到验证。
英特尔是CXL生态的重要推动者。英特尔在服务器CPU领域长期具备平台影响力,其服务器平台对CXL的支持直接影响行业普及节奏。CXL作为开放互连协议,与英特尔推动数据中心可组合基础设施、内存扩展和异构计算的战略方向一致。由于服务器CPU是CXL链路中的主机侧核心,英特尔平台生态、BIOS支持、验证工具和合作伙伴资源对CXL发展具有基础性意义。
AMD同样是CXL生态的重要参与者。随着AMD EPYC服务器CPU在云计算和高性能计算市场份额提升,其平台对CXL的支持将推动更多云厂商和服务器厂商采用CXL方案。AMD在高核心数CPU和AI服务器平台中具备较强增长势头,因此其对CXL的支持也是行业扩散的重要变量。
英伟达在AI服务器生态中具有极强话语权。虽然英伟达体系中NVLink、NVSwitch和HBM是核心互连与内存方案,但随着AI推理对容量和成本优化提出更高要求,CXL仍可能在CPU侧内存扩展、外部共享内存池和系统级存储架构中发挥作用。英伟达是否在未来平台中更深度支持CXL,将显著影响AI服务器CXL应用速度。
三星、SK海力士和美光代表全球DRAM原厂力量。CXL内存模组本质上仍需要高质量DDR5 DRAM颗粒和企业级内存模组能力,因此存储原厂是CXL生态中不可替代的参与者。三星CMM-H和SK海力士CMM-DDR5等产品说明,存储原厂不希望CXL仅成为控制器厂商和服务器厂商的机会,而是希望通过CXL将DRAM产品从单纯颗粒供应升级为系统级内存解决方案。
Astera Labs是高速互连芯片领域的代表性公司,产品覆盖PCIe/CXL连接、Retimer和相关数据中心互连芯片。该类企业的优势在于高速SerDes、信号完整性、云客户验证和完整连接解决方案。随着AI服务器中高速链路数量增加,Retimer、CXL连接芯片和Switch芯片价值提升,Astera Labs等企业具备较强生态卡位。
Marvell、Microchip等企业也在数据中心互连、控制器和交换芯片领域具备长期积累。它们的优势在于企业级客户、网络和存储控制器能力,未来可能围绕CXL Switch、控制器、桥接芯片和系统方案进行布局。
技术壁垒方面,CXL控制器和Switch芯片需要高速SerDes能力、PCIe/CXL协议能力、DDR控制器能力、缓存一致性处理能力和系统级调试能力。随着CXL 4.0速率提升至128GT/s,信号完整性、功耗控制、链路训练和误码控制难度进一步上升。普通芯片设计企业很难快速进入高端CXL芯片市场。
客户壁垒方面,CXL产品主要面向服务器、云厂商和存储原厂,客户验证周期长,认证要求高。进入头部客户供应链后,产品稳定性和长期供货能力成为关键。由于CXL涉及基础设施核心架构,客户通常不会频繁更换供应商。
生态壁垒方面,CXL设备需要与CPU平台、BIOS、操作系统、服务器主板、内存颗粒、模组固件和应用软件配合。单一环节领先并不等于产品可用,厂商必须具备跨生态协同能力。能够参与CXL联盟测试、进入合规供应商清单、与内存原厂共同开发产品的企业具备明显优势。
可靠性壁垒方面,CXL面向企业级和数据中心场景,对RAS能力要求极高。内存扩展设备一旦出现错误,可能影响数据库、AI服务和云实例稳定性。因此,ECC、错误隔离、热插拔、故障恢复、固件升级和安全管理能力都是客户评估重点。
PART 08
PART 09
第一,DRAM颗粒成本。CXL内存模组通常仍需使用DDR5 DRAM,DRAM颗粒是主要成本项。不同容量、速率和封装的颗粒价格差异较大。
第二,CXL控制器芯片成本。控制器负责协议转换、内存控制和可靠性管理,是模组的核心增量成本。随着量产规模提升和制程成熟,控制器成本有望下降。
第三,PCB、连接器和电源管理成本。CXL模组可能采用E3.S、PCIe插卡或其他形态,对PCB高速布线、信号完整性和供电设计要求较高。
第四,散热和系统集成成本。高带宽CXL设备会带来功耗和散热挑战,需要服务器系统配合设计。
第五,软件和运维成本。内存池化需要操作系统、虚拟化层、调度系统和应用软件适配,初期会增加开发和运维成本,但成熟后可通过提高资源利用率摊薄成本。
第一,使用更经济的DIMM组合替代高价大容量DIMM。资料中的示例显示,为达到4TB内存容量,传统方案需要使用16条256GB DIMM,而CXL方案可采用本地128GB DIMM加CXL附加128GB DIMM的组合。由于超大容量DIMM价格溢价明显,CXL方案可降低系统成本。
第二,提高内存利用率。数据中心中内存资源存在闲置和碎片化,CXL池化可以减少过度配置,使内存按需分配。
第三,减少数据搬运和重复存储。AI推理场景中,CXL共享内存池可减少KV Cache在节点之间重复传输和多份复制,提高系统吞吐。
第四,延长服务器平台生命周期。通过CXL扩展内存容量,部分服务器无需更换CPU平台或主板即可获得更大内存能力,从而延长资产使用周期。
PART 10
PART 11
CXL:Compute Express Link,计算快速连接协议,基于PCIe物理层,用于CPU、加速器和内存扩展设备之间的高速一致性互连。
CXL.mem:CXL协议子集之一,允许主机访问设备侧内存,是CXL内存扩展的基础。
CXL.cache:CXL协议子集之一,允许设备访问主机内存并保持缓存一致性。
CXL.io:CXL协议子集之一,提供类似PCIe的设备发现、配置和I/O能力。
CXL Memory Module:基于CXL协议的内存扩展模组,通常通过CXL控制器连接DDR内存。
CXL Switch:CXL交换芯片,用于连接多个主机和多个CXL设备,支持内存池化和资源调度。
KV Cache:大模型推理过程中保存Key和Value张量的缓存,用于加速后续Token生成,是长上下文推理的重要内存消耗来源。
Prefill:大模型推理中对输入上下文进行初始计算的阶段,通常计算量较大。
Decode:大模型推理中逐步生成输出Token的阶段,通常对缓存访问和低延迟要求较高。
DRAM:动态随机存取存储器,服务器主内存主要形式。
HBM:高带宽内存,常用于GPU和AI加速器,带宽高但成本高、容量有限。
VPD:Vital Product Data,用于存储设备关键参数、身份信息和系统校验数据的芯片或数据区域。
TCO:Total Cost of Ownership,总拥有成本,包括采购、运维、能耗、部署和生命周期成本。
