 夜雨聆风
夜雨聆风
最近我越来越确认一件事:
AI 写代码最大的坑,不是它不会写。
真正可怕的是:它太能写了。
需求没澄清完,它开始写。方案没定完,它开始写。接口归属还没搞清楚,它开始写。Review 发现问题后,它又带着前面一堆废弃上下文继续写。
最后代码确实“能跑”,但工程开始变味:到处是兼容补丁,到处是临时判断,到处是“先这样吧”。
这不是模型能力问题,这是工作流问题。
一个代理吞掉需求、设计、实现、Review 全部上下文,迟早会把项目吃成一锅粥。
所以我这次干了一件很简单但很爽的事:
用 OpenSpec 管流程,用 Agent 管角色,用文件做交接。
一句话:不让一个 AI 当全能选手,而是让每个代理只干自己那一段。
一、以前的问题:上下文污染,比 Bug 更难受
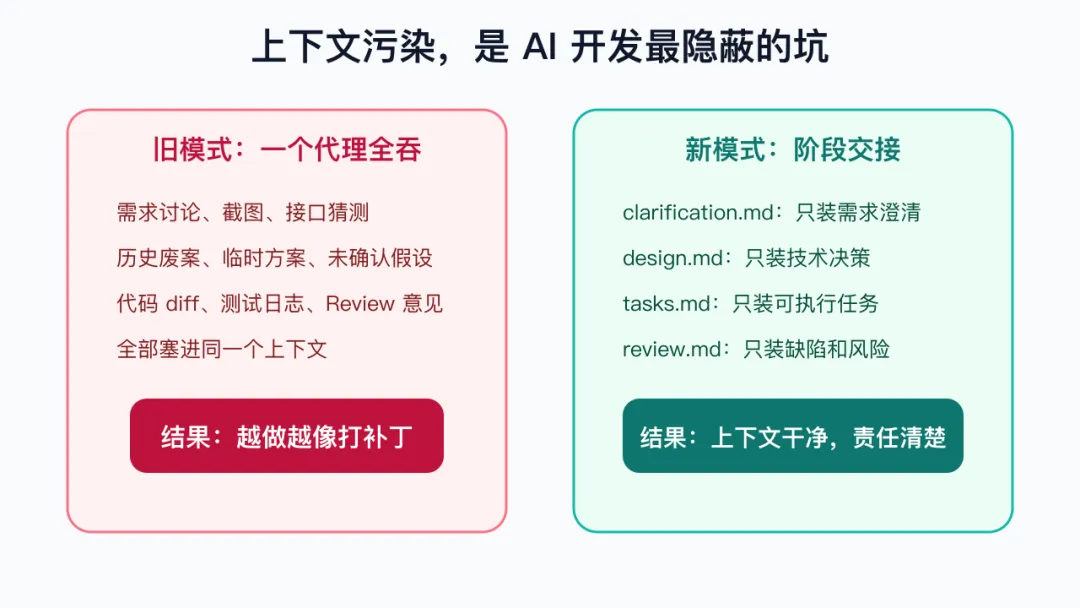
传统 AI 开发流程,经常是这样的:
用户说一个需求 AI 开始分析 分析到一半发现接口不对 又补充数据库、菜单、权限、前端页面 继续写代码 写完 Review Review 后再修
看起来很顺。但上下文已经开始脏了。
一开始的猜测、后面推翻的方案、用户临时纠正的话、错误模块里的探索记录、失败命令、废弃接口,全都还在同一个上下文里。
AI 后面继续工作时,很容易把这些“历史废案”当成有效信息。
于是你会看到几种熟悉的坏味道:
明明应该精准对接契约,它开始写兼容兜底 明明只改一个接口,它顺手重构一片 明明需求已经改了,它还引用旧判断 明明 Review 只指出一个 bug,它把任务扩成“全面优化”
这就是上下文污染。它不像编译错误那么直接,但它会慢慢把代码库拖烂。
二、我的解法:OpenSpec + Agent,不靠聊天记忆交接
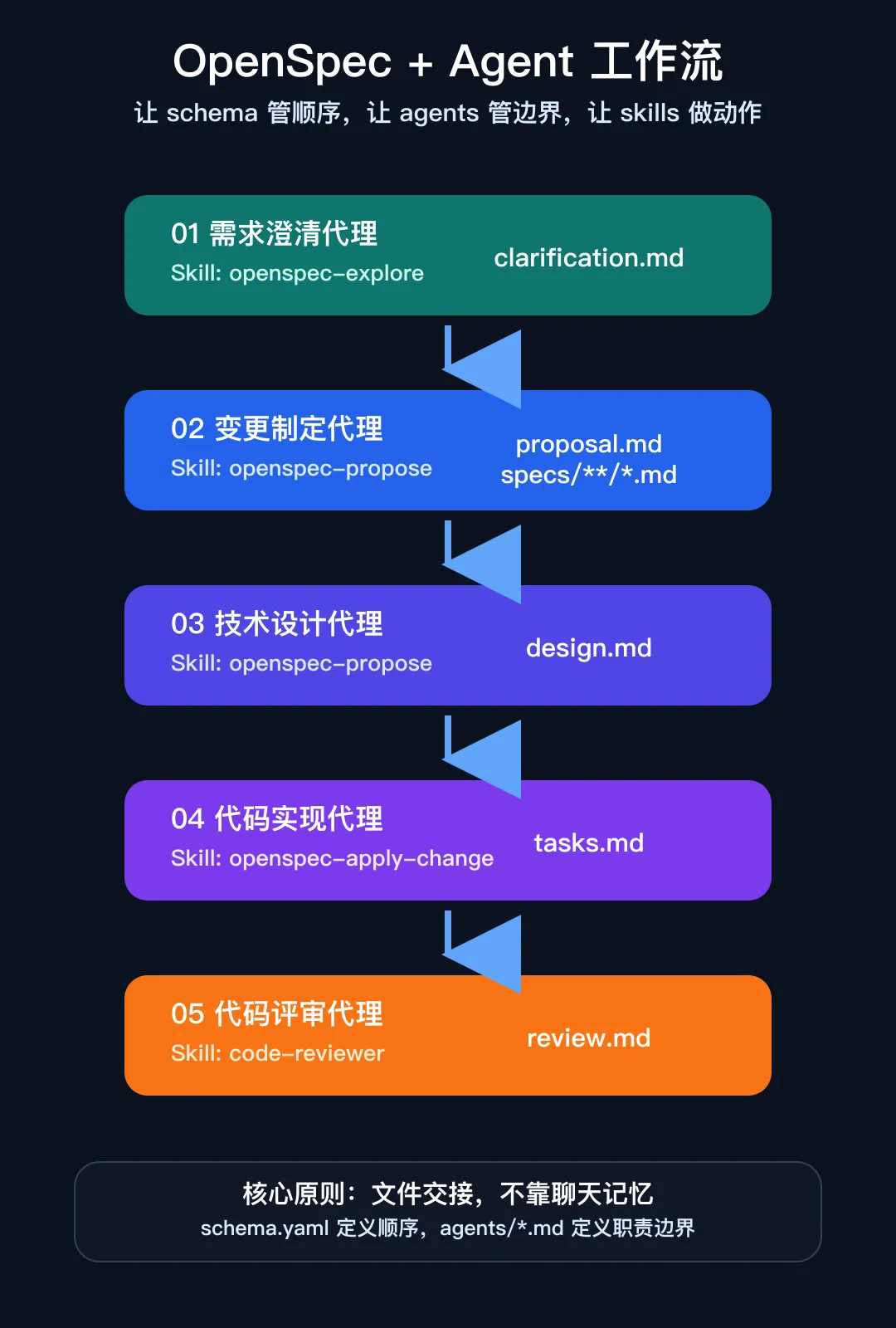
我把整个 OpenSpec 工作流拆成 5 个阶段:
需求澄清 变更制定 技术设计 代码实现 代码 Review
每个阶段一个明确产物。
不是靠“上个代理说过什么”,而是靠文件交接:
clarification.md -> 需求澄清
proposal.md -> 变更提案
specs/**/*.md -> 行为规格
design.md -> 技术设计
tasks.md -> 实现任务
review.md -> 代码 Review这样一来,每个代理只需要读自己该读的文件。
需求澄清代理不用知道最终代码 diff。实现代理不用吃完整个需求讨论历史。Review 代理不用参与前面的方案争论,只看 OpenSpec、diff 和验证证据。
Agent 不是越全能越好,而是上下文越干净越好。
三、角色怎么拆?我用了 4 个代理
我没有一上来搞复杂平台,也没有做花哨调度。先用最朴素、最稳的方式:写 4 份代理说明。
agents/
├── requirement-clarifier.md
├── openspec-designer.md
├── implementation-worker.md
└── code-reviewer.md1. Requirement Clarifier:需求澄清代理
它只负责弄清楚需求。它不能写 OpenSpec,不能写代码。
输出一个 clarification.md:
# Requirement Clarification
## Background
## Current Problem
## Confirmed Facts
## Assumptions
## In Scope
## Out of Scope
## Open Questions
## Acceptance Criteria
## Suggested Change Id这个代理最适合处理那种“页面为什么没数据”“这个弹窗为什么空”“这个状态为什么不同步”的问题。
它的重点不是马上修,而是先追链路:前端从哪里请求,后端查哪张表,数据归属是谁,是平台数据还是门店数据,是渲染问题还是数据源错了。
需求没澄清完,不进入下一步。
2. OpenSpec Designer:变更制定代理
它负责把澄清后的需求变成 OpenSpec artifacts。
它要检查已有 openspec/changes,能更新就更新,不重复创建;然后生成 proposal.md、specs/**/*.md、design.md、tasks.md。
它也不能写业务代码。这一步的重点是把“我要什么”变成“系统 SHALL 做什么”。
3. Implementation Worker:代码实现代理
它只实现 approved tasks。它不重新解释需求,不扩大 scope,不顺手重构。
它的输入不是聊天记录,而是 clarification.md、proposal.md、specs/**/*.md、design.md、tasks.md。
它按 tasks.md 一项一项做。每项都要能验证。
4. Code Reviewer:代码 Review 代理
Review 代理最重要的一点:它不改代码。
它只输出 findings:
# Review Findings
## Findings
## Open Questions
## Verification Reviewed
## Summary它看的是 OpenSpec 是否被满足、diff 是否偏离设计、权限和路由是否正确、测试是不是假跑、有没有兼容性风险。
Review 不参与实现,能避免一个很常见的问题:写代码的人给自己找理由。
四、关键不是代理,而是 schema
只写 agents 文档还不够。因为代理说明只是“岗位职责”,真正控制 OpenSpec 阶段顺序的是 schema。
我新建了一个 schema:
openspec/schemas/agent-openspec/schema.yaml然后把 openspec/config.yaml 的第一行改成:
schema: agent-openspec这样 OpenSpec 就知道:现在不是默认的 proposal -> specs -> design -> tasks,而是新的代理友好流程。
clarification -> proposal -> specs -> design -> tasks -> code-review这一步很爽。因为它让“先澄清,再设计,再实现,再 Review”变成了工具层面的约束,而不是一句口头约定。
五、核心 schema 直接贴出来
下面是关键版本,真实项目里可以直接按这个改。
name: agent-openspec
version: 1
description: Agent-aware OpenSpec workflow - clarification -> proposal -> specs -> design -> tasks -> code-review
artifacts:
- id: clarification
generates: clarification.md
description: 需求澄清交接文档
template: clarification.md
instruction: >
使用 openspec-explore skill 的探索方式,并遵守
agents/requirement-clarifier.md 的职责边界。
只澄清需求,不创建 OpenSpec 变更,不修改代码。输出必须让后续
openspec-propose 阶段可以脱离完整聊天上下文工作。
requires: []
- id: proposal
generates: proposal.md
description: 概述变更的初始提案文档
template: proposal.md
instruction: >
使用 openspec-propose skill,并遵守 agents/openspec-designer.md 的职责边界。
基于 clarification.md 创建 proposal.md。创建前必须检查 openspec/changes
是否已有相关变更;如果已有,应更新现有 change,而不是重复创建。
requires:
- clarification
- id: specs
generates: specs/**/*.md
description: 变更的详细规格说明
template: spec.md
instruction: >
使用 openspec-propose skill,并遵守 agents/openspec-designer.md 的职责边界。
为 proposal 的 Capabilities 部分列出的每个能力创建 spec 文件。
每条需求必须使用 SHALL/MUST,并至少包含一个 #### Scenario。
requires:
- proposal
- id: design
generates: design.md
description: 包含实现细节的技术设计文档
template: design.md
instruction: >
使用 openspec-propose skill,并遵守 agents/openspec-designer.md 的职责边界。
中文友好要求:章节标题可以使用英文以保持 OpenSpec 结构稳定,但正文必须
主要使用中文描述。
requires:
- clarification
- proposal
- specs
- id: tasks
generates: tasks.md
description: 可跟踪任务的实现清单
template: tasks.md
instruction: >
基于 specs 和 design 创建任务列表。每个任务必须使用:
- [ ] X.Y 任务描述
中文友好要求:任务描述、验证说明、风险提示应主要使用中文。
requires:
- specs
- design
- id: code-review
generates: review.md
description: 代码 review 报告
template: review.md
instruction: >
使用 code-reviewer 代理,并遵守 agents/code-reviewer.md 的职责边界。
只 review,不改代码。findings 必须优先输出,按 P1/P2/P3 排序。
requires:
- proposal
- specs
- design
- tasks
apply:
requires:
- clarification
- proposal
- specs
- design
- tasks
tracks: tasks.md
instruction: |
使用 openspec-apply-change skill,并遵守 agents/implementation-worker.md 的职责边界。
只实现 approved OpenSpec tasks。每次只处理明确的任务切片。
不得重新解释需求,不得扩大 scope,不得顺手重构无关代码。注意这里的设计很克制。schema 不负责“真的启动子代理”。schema 只负责定义有哪些 artifact、先后依赖是什么、每一步的输出文件是什么、每一步应该遵守哪个 agent 边界。
schema 管顺序,agents 管边界,skills 做动作。
六、为什么要加 clarification.md?
因为很多需求不是一开始就清楚的。
比如用户说:“这个弹窗为什么没数据?”
糟糕的 AI 会马上改接口。靠谱的流程应该先问:弹窗数据来自哪个接口?接口查的是平台服务项,还是门店上架服务项?当前页面有没有 institutionId?业务期望是机构维度,还是平台维度?没数据是前端没调,还是后端查错表?
这些如果不写进 clarification.md,后面实现代理就很容易“凭感觉修”。
所以 clarification 不是形式主义。它是整个流程的地基。
七、design.md:标题可以英文,正文必须中文
OpenSpec 默认模板偏英文。但在中文团队里,如果 design.md 全是英文,Review 成本会变高。
尤其是业务系统,很多概念是中文语境里的:门店、平台、护理对象、长护险、服务项、服务套餐、参保名单、审核记录。
这些硬翻成英文,反而丢信息。
所以我加了一个规则:标题可以英文,正文必须主要使用中文。
## Context
用中文说明背景、当前状态、业务约束和相关系统。
## Goals / Non-Goals
用中文列出本次设计要达成的目标,以及明确不包含的范围。
## Decisions
用中文说明关键技术决策、原因和考虑过的替代方案。
## Data / API Flow
用中文描述数据来源、请求参数、状态流、跨端契约和权限边界。
## Verification Strategy
用中文说明后端、前端、SQL、端侧分别如何验证,并写出必要命令。这个小改动非常值。它让文档既保持工程结构,又能让团队真正读得下去。
八、tasks.md:不要再写“实现后端”这种废话
我最怕的任务拆分是这种:
- [ ] 实现后端
- [ ] 实现前端
- [ ] 联调测试看起来有计划,实际上没法执行。实现哪个接口?改哪个表?验证什么?失败怎么判断?都没有。
所以我把 tasks.md 模板改成中文可执行风格:
## 1. Preparation
- [ ] 1.1 用中文描述准备工作,例如确认现有代码、数据表、接口或页面入口
- Verify: 用中文说明验证方式,可包含命令、SQL 或手工检查点
## 2. Implementation
- [ ] 2.1 用中文描述具体实现任务,保留必要的文件路径、类名、接口路径或字段名
- Verify: 用中文说明完成后如何验证,必要时写出精确命令任务越清楚,代理越不容易自作聪明。
九、Review 必须独立出来
很多人让同一个 AI 写完代码后顺手 Review。这当然也能做,但效果不够硬。
因为写代码的上下文里,已经装满了它自己的理由。
独立 Review 代理应该只看:
OpenSpec artifacts
git diff
verification evidence
project rules它必须 findings first:
# Review Findings
## Findings
- [P1] path:line - 问题和影响
- [P2] path:line - 问题和影响
## Open Questions
## Verification Reviewed
## SummaryReview 代理只报问题,不修代码。修复再交回 Implementation Worker。职责一分开,质量会立刻上来。
十、落地以后怎么用?
先看 schema:
openspec schemas你会看到:
agent-openspec
Artifacts: clarification → proposal → specs → design → tasks → code-review校验 schema:
openspec schema validate agent-openspec查看某个阶段的指令:
openspec instructions clarification --change <change-id>
openspec instructions design --change <change-id>
openspec instructions tasks --change <change-id>
openspec instructions code-review --change <change-id>执行实现阶段:
openspec instructions apply --change <change-id>如果某个历史 change 没有 clarification.md,现在会被 block。这不是 bug,这是新流程在保护你。
Missing artifacts: clarification你有两个选择:
# 新流程:补一个 clarification.md
openspec instructions clarification --change <change-id>
# 旧 change 临时走旧 schema
openspec instructions apply --change <change-id> --schema limit-context十一、这个方案真正解决了什么?
它不是让 AI 更炫。它是让 AI 更守规矩。
以前的问题是:
一个代理 + 巨大上下文 + 模糊任务 = 代码开始漂现在变成:
多个角色 + 文件交接 + OpenSpec 约束 = 每一步都能审这套流程的价值不在“自动化程度更高”。而在“每一步都能停下来检查”。
需求错了,停在 clarification。方案错了,停在 design。任务太粗,停在 tasks。代码偏了,停在 review。不会一路错到生产。
十二、最后说句实话
AI 时代,真正拉开差距的不是“谁会 prompt”。
而是谁能把 AI 放进一个靠谱的工程流程里。
让它该澄清时澄清。该设计时设计。该实现时实现。该闭嘴 Review 时,就只 Review。
OpenSpec 给了我们规格驱动的骨架。Agent 给了我们职责隔离的肌肉。文件交接则是血管。
这三件事合在一起,AI 才不会像一个兴奋过头的实习生,到处乱改。
它会变成一个真正可控的工程协作者。
这才是 OpenSpec + Agent 最爽的地方。
