 夜雨聆风
夜雨聆风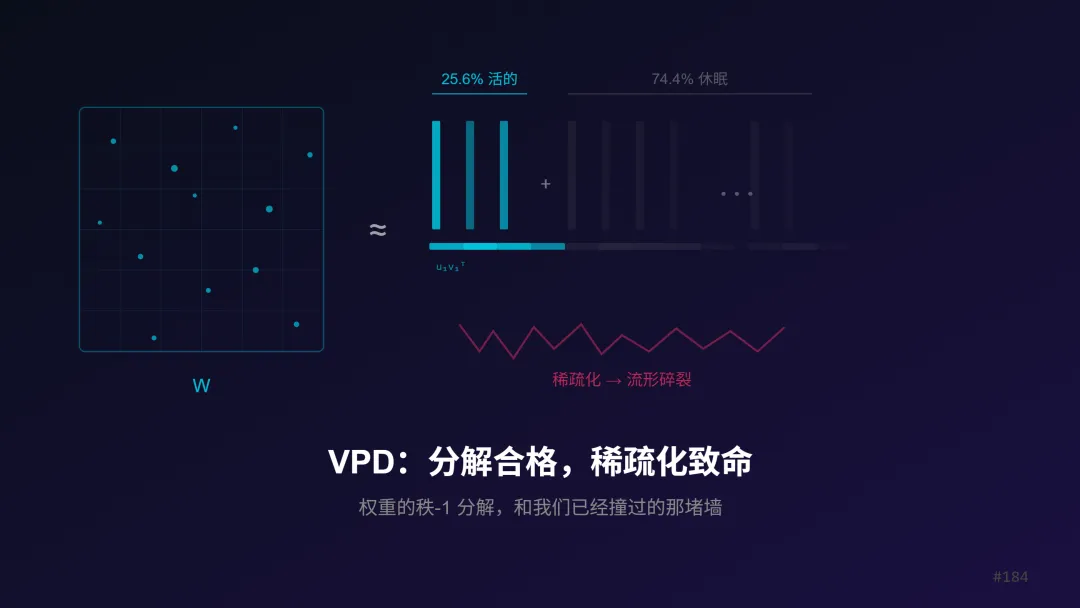
━━━━━━━━━━━━━━━━━━━━
偶然看到一篇著名大厂的公众号文章,把 Goodfire 的 VPD 论文(Interpreting Language Model Parameters,2026 年 5 月)吹成"大模型黑盒迎来真正的法医"。文章写得不错,但结论太乐观了。
VPD 代表了可解释性领域一个重要的方向转变——从分解激活转向分解权重。但这条路的难度和局限性,我们其实已经从不同角度亲手验证过了。
━━━━━━━━━━━━━━━━━━━━
◆ SAE 派做了什么
━━━━━━━━━━━━━━━━━━━━
过去两年,SAE(Sparse Autoencoder)是可解释性领域的绝对主角。
Anthropic 用 SAE 做出了金门大桥 Claude——找到一个"金门大桥"特征,把它的激活值拉满,模型就开始在所有回答里疯狂提金门大桥。Scaling Monosemanticity 把 SAE 从玩具模型推到了 Claude 3 Sonnet 级别,分离出了几百万个可解释特征。Anthropic 的情绪向量实验证明了残差流里存在有因果效力的情感方向。NLA(Natural Language Autoencoder)更进一步,直接把激活翻译成人话,发现了模型"知道自己在被考试"的元认知信号。
我们自己也一路跟下来了:「第 151 期【AI可解释性】训练三层Mistral-7B模型的SAE——解开结构与语义的纠缠」自己动手训了三层 Mistral-7B 的 SAE,把结构特征和语义特征物理分离;「第 155 期【AI前沿】Anthropic 论文实锤:Claude 内部存在"情绪向量",而且它们在驱动坏行为」跟进 Anthropic 的情绪向量论文,用线性探针在残差流里找到了 171 个情绪方向,证明它们有因果效力;「第 175 期【开源】提取 DeepSeek V4 Flash 的中间层激活值」在两台 DGX Spark 上提取了 DeepSeek V4 Flash 280B 的中间层激活值;「第 180 期【AI可解释性】Anthropic 给 AI 做了脑部 CT——然后发现它知道自己在被考试」解读了 NLA 的架构和四个重磅发现。
但 SAE 有一个核心问题:特征分裂。
SAE 的字典大小是超参数——你设 16384 个槽位,它就分解出 16384 个特征;你设 65536 个,它就分解出 65536 个。特征数量是测量工具决定的,不是模型自身决定的。给得多就填得多,给得少就合并。用程序员的话说:这就像你写了个 hash map,桶的数量是你自己设的,不是数据告诉你的。桶设少了,不同的 key 挤在同一个桶里(特征合并);桶设多了,同一个 key 被分到了多个桶里(特征分裂)。你永远无法确定:模型内部到底有多少个"真正的"独立特征?
━━━━━━━━━━━━━━━━━━━━
◆ VPD 想做什么
━━━━━━━━━━━━━━━━━━━━
Goodfire 的背景
这篇论文来自 Goodfire——一家专做大模型可解释性商业化的公司,给 Llama 等模型做过 SAE 特征提取,完整功能包在商业产品 Silico 里。2025 年 4 月 A 轮融了 5000 万美元,2026 年 2 月 B 轮 1.5 亿美元,估值 12.5 亿。有意思的是,Anthropic 参与了 Goodfire 的 A 轮融资(约 100 万美元,是 Anthropic 历史上第一笔对外投资)——那篇公众号文章把两家框成"挑战者 vs 霸主",其实人家至少是投资关系。
────────────────────
分解权重 vs 分解激活
VPD(adVersarial Parameter Decomposition)走了一条和 SAE 完全不同的路:不拆激活,拆权重。
SAE 是在模型运行时截取激活向量做稀疏分解——看的是运行时的"影子"。VPD 直接对权重矩阵动刀——分解的是机器本身。类比:SAE 是功能核磁共振(fMRI),看你哪个脑区亮了;VPD 是神经解剖,直接打开大脑看神经纤维的走向。
不过有一点容易混淆:VPD 分解完权重之后,要判断每个齿轮"是干什么的",还是得喂句子进去看哪个齿轮亮——这一步和 SAE 看 max-activating examples 没有本质区别。SAE 分解的是激活(没有输入就没有激活),VPD 分解的是权重(不管喂什么输入都不变)。 SAE 描述的是"模型此刻在想什么",VPD 描述的是"模型的线路怎么接的"——但验证线路功能时,两者殊途同归,都要看输入。
────────────────────
分解公式与基本数据
VPD 把一个 67M 参数的 4 层 Transformer 的所有权重矩阵做如下分解:
W ≈ u₁v₁ᵀ + u₂v₂ᵀ + u₃v₃ᵀ + ... + u_C v_Cᵀ + ΔW 是原始权重矩阵。每个 u_i v_iᵀ 是一个 秩为 1 的矩阵 ——一个列向量乘一个行向量,秩只有 1,是矩阵能拥有的最简单的非零形态。Δ 是残差项,训练时被 L2 惩罚压向零。
这些 u_i、v_i 不是 SVD 算出来的(SVD 分量必须正交),而是用梯度下降 训练出来的 ,优化五个损失项的加权和,训练几万步收敛。VPD 的分量没有正交约束。收益是:频率最小化和条件稀疏激活会逼每个分量只在窄语境(少数几种特定场景)下激活——"遇到系动词时亮""遇到 it 时亮"——窄的功能更容易被人类命名和理解。当然这只是倾向,不是保证——论文里大量齿轮仍然没法命名。
每个秩-1 矩阵只需要存两个向量,参数量从原矩阵的"行数×列数"降到"行数+列数"。你可以把每个秩-1 矩阵想象成一个"齿轮":模型能装备的最小功能单元。
整个模型被分解为 38912 个齿轮,但只有约 9972 个是"活的"(25.6%),每个 token 位置平均只用其中 205 个(占活组件的 2.1%)。38912 个零件里四分之三休眠,剩下的活零件里每个位置只唤醒百分之二。
四分之三休眠也有信息量:它说明 VPD 学到的不是"把所有槽位都填满"的字典,而是一套带强烈选择性的参数子组件。但这里要小心,活组件比例和本我流形的维度不是一回事。9972 个活分量分布在 24 个权重矩阵和 4 层里,它更像是在告诉我们"参数使用是稀疏的",而不是直接告诉我们流形有多少维。
VPD 的训练目标有五项,其中两个是真正的创新——对抗消融和频率最小化,这两个设计也是 VPD 最漂亮的地方,放在下一节讲。
━━━━━━━━━━━━━━━━━━━━
◆ VPD 的亮点
━━━━━━━━━━━━━━━━━━━━
对抗消融(Adversarial Ablation)
传统消融实验随机拔齿轮看输出变化,但模型可能有冗余齿轮做后备——你拔了齿轮 A,齿轮 B 顶上了,你误判 A 不重要。
VPD 用 PGD(Projected Gradient Descent)梯度上升解决这个问题:不是随机拔齿轮,而是在同一个输入上搜索最刁钻的消融掩码——把"哪些齿轮要关"当作可优化变量,目标函数是让消融前后的 KL 散度最大化(即让输出概率分布偏离原始模型越远越好)。这样搜出来的组合能把所有"掩护齿轮"一锅端掉,孤立目标齿轮再拔它。如果 KL 散度爆了,说明这个齿轮是刚需,没有任何替补能救场。这个设计把消融实验的可靠性往前推了一步。
────────────────────
频率最小化(Frequency Minimization)
SAE 的特征分裂问题怎么解决?VPD 在训练损失函数里加了一项"注册税"。具体做法:先统计每个齿轮在整个 batch 上被激活的总频次 freq,然后惩罚项是 freq × log₂(1 + freq)。log₂(1 + x) 的关键性质是:x 从 0 到 1 时涨得最陡(从 0 到 1),x 从 100 到 101 时几乎不动。效果是:一个齿轮从"完全不用"到"用一次"的代价最高(注册费),之后每多用一次的边际成本递减。
对比 SAE 的 L1 正则化:L1 惩罚激活值的绝对值之和(Σ|z_i|),线性的,只关心"每个开了多大",不直接关心"开了几个"。如果理想的惩罚是 L0(只数非零元素个数,不管大小),L0 又是阶跃函数没法求导。VPD 的 log₂ 介于两者之间——低频段对"开不开"敏感(接近 L0 行为),高频段对"多用一次"不敏感(接近 L1 行为),而且连续可导,可以做梯度下降。效果上逼模型复用已有齿轮而不是开新的,从根源上抑制特征分裂。
────────────────────
容量扫描:模型自己决定特征数量
这是 VPD 论文最漂亮的结果之一。
他们做了一组扫描:预留的秩-1 分量总数(槽位)从基准的 0.5 倍到 4 倍(翻了 8 倍),看最终"活"的分量数怎么变。结果——钉死在 6500-7000 不动。
槽位从半满到四倍过剩,模型稳定只用 6500-7000 个齿轮。这个数量由模型结构决定,不是你给多少槽位决定的。对比 SAE——你给 16384 个槽位它填 16384 个,给 65536 就填 65536——VPD 在"特征数量到底是谁说了算"这个问题上,给出了一个干净得多的回答。
────────────────────
三个注意力发现
VPD 还分解出了一些有语言学意义的结构:前一词注意力(attend-to-previous-token)跨 6 个头分布,消融一对齿轮后 6 个头同时瘫痪;句法边界检测(标点、换行处激活飙升);最有意思的是一个 虚词判别器 ——三个齿轮(q308/k218/k485)协同工作,区分 "it is raining" 里的虚词 it(纯粹的语法占位符)和 "the book is heavy, it weighs five pounds" 里的实指 it(指代 book)。这是语言学家研究了几十年的经典区分,模型在没有任何显式语法训练的情况下自己长出来了——对"LLM 到底有没有学到语法"这个争论提供了新证据。
━━━━━━━━━━━━━━━━━━━━
◆ VPD 的问题
━━━━━━━━━━━━━━━━━━━━
分解本身合格,但存储代价不低
先看重建质量:
全开状态下 CE 从 2.71 到 2.72,分解本身几乎无损——足够多的秩-1 矩阵并联起来可以精确重建任意满秩矩阵。
但代价是冗余。对比 SVD:SVD 也把矩阵分解为秩-1 矩阵的加和(W = σ₁u₁v₁ᵀ + σ₂u₂v₂ᵀ + ...),在"所有元素的误差平方和最小"这个标准下数学最优——顺着流形主轴切,每一刀正交、高效。VPD 的分量方向被频率最小化扭曲了:不是顺着方差最大的方向切,而是顺着"能在窄语境下独立激活"的方向切。两个方向没有理由重合,所以需要更多分量才能达到同等重建质量。
算一笔账:38912 个秩-1 分量,每个都要存两个向量。论文分解的是 24 个权重矩阵,没分解 embedding / unembedding;所以不能简单拿"分解后参数量"直接除以整个 67M 模型来算膨胀率。但方向很清楚:VPD 不是压缩算法,它是用额外参数、路由网络和训练成本换一套更容易解释的参数基底。用冗余换可解释性,这个汇率不便宜。
────────────────────
稀疏化才是真正的问题
VPD 全部的可解释性结论都建立在稀疏激活上——只有稀疏了才能说"这个位置只用了这几个齿轮,所以它们就是解释"。全开时 9972 个齿轮一起亮,你解释什么?
但恰恰是稀疏化这一步出了问题。每个 token 位置平均只开 205 个齿轮(占活组件 2.1%),瓶颈是路由网络能不能精确选对——选错一个,重建就歪了。困惑度从 15 跳到 17-19(掉 15-27%):并联的表达能力够,动态选择的精度不够。
这里有一个容易被忽略的关键区别:SAE 的稀疏激活不影响原始模型。 SAE 是旁边挂着的观测器,模型照常运行。你把 SAE 里某个特征的激活值归零,影响的只是那个特征对应的方向——金门大桥 Claude 就是拉满一个特征,模型疯狂提金门大桥,但其他能力基本没崩。VPD 的稀疏激活是在 模型本体上动刀 ——关掉一个秩-1 分量,等于从权重矩阵里物理减掉一块。而且分量之间不严格正交,关掉 A 可能改变 B 和 C 的有效贡献——牵一发动全身。困惑度涨 15-27% 不是"观测误差",是模型真的变弱了。SAE 是在副本上画标记,VPD 是在原件上拆零件。
────────────────────
为什么稀疏化的杀伤力这么大
因为频率最小化逼每个分量专注于窄功能——两个分量如果总在相似语境下同时激活,就会一起缴"频率税"。训练最省钱的办法,是让它们错开:你负责系动词,我负责代词;你负责标点边界,我负责前一词注意力。
这不是数学意义上的严格正交,但会产生一种事实上的 功能正交化 :每个齿轮都被训练成更容易单独命名、更少和别的齿轮纠缠的方向。
问题就在这里。可解释性喜欢正交,因为正交以后人类好贴标签;但语言模型真正的功能不是正交零件堆出来的,而是大量方向的重叠、共振和跨层协同。 一个词、一个句法结构、一个推理步骤,往往不是某个齿轮单独完成的,而是一组方向同时参与的复合模式。VPD 为了让齿轮更干净,等于把连续流形切成坐标轴。坐标轴很清楚,但原来的曲率没了。
正是因为 VPD 把分量推向了功能正交化(为了可解释性),稀疏化才变得危险:路由一旦选错,错删的不是装饰件,而是复合结构里的一根承重轴。 正交分解能列出零件清单,但模型的行为是零件的复合,稀疏化破坏的是复合关系——这才是重建质量掉 15-27% 的根因。
────────────────────
冗余容错杯水车薪
由于分量不严格正交,分量之间存在一定重叠,会提供一些冗余容错。但这远不足以承受极端稀疏路由的误选。杯水车薪。
所以要把两件事分开评价:分解本身是合格的工程活——全开时几乎无损,多花存储和训练成本换一组非正交基底,代价可以讨论。但稀疏化是不合格的科学声明——可解释性结论全建立在稀疏激活上,而路由精度不够,重建质量掉 15-27%,对抗强度一大就崩。学术野心全押在整条链路最弱的一环上。
────────────────────
67M——房间里的大象
以上所有分析还有一个大前提:VPD 目前只在 67M 参数的 4 层模型 上做了。67M 是什么概念?现在主流开源模型 7B 起步,7B 已经算小模型了——67M 连小模型都不是,根本不是一个能用的 LLM,只是一个实验室里的教学玩具,差了两个数量级。67M 上"能分解"是因为矩阵小、层数少、对抗消融还能跑得动。换到真正的语言模型,VPD 需要的分量数、路由难度和对抗消融计算量都会爆炸。
那篇公众号文章标题说"大模型黑盒迎来真正的法医"——这个法医目前只解剖过一只老鼠,还没碰过人体。
对比:SAE 已经推到 Claude 3 Sonnet(几十 B),NLA 开源了 7B-70B 四个规模的解释器权重。VPD?67M。
━━━━━━━━━━━━━━━━━━━━
◆ 我们已经撞过的那堵墙
━━━━━━━━━━━━━━━━━━━━
这一节是这篇文章的重点。
先亮一个统一框架:后训练操作——不管是往里塞、往外删、还是拆开看——都在低维子空间里干活,碰不到全维流形的曲率。
我们从两个完全不同的方向验证过这堵墙。VPD 是第三个撞上去的。
────────────────────
4.1 从外面往里塞——129 期红楼梦实验
「第 110 期【Doc-to-LoRA】AI 终于学会"睡一觉就记住了"」分析了 Sakana AI 的 Doc-to-LoRA 方案:超网络把文档切块,每块生成一个 rank-8 的 LoRA,拼接后 rank 线性增长。
「第 129 期【Doc-to-LoRA 实验】AI 需要学会遗忘——我们用红楼梦亲手验证了」我们用红楼梦英译本 85K tokens 亲手测了这条路。
结果:块越多准确率越低。不是边际递减,是单调递减到零。
rank-408(18% hidden_dim)时模型输出退化为 "ing ing ing"——语言能力本身崩溃了。不是答错了红楼梦的问题,是不会说话了。
结论:LoRA 的秩稍微大一点就撕碎本我流形。 秩-1 操作之所以安全,恰恰因为它小到碰不到什么。
────────────────────
4.2 从里面往外删——131 期遗忘技术综述
「第 131 期【AI记忆擦除】四类假装遗忘的方案和一群证伪者,一颗无法遗忘的大脑」我们系统梳理了四类遗忘方法(线性投影 / 权重编辑 / 梯度上升 / 激活干预),结论是:全部被攻破。
其中和 VPD 直接相关的是 ROME——MIT 的 Meng et al. 用因果追踪定位知识存储的 MLP 层,然后对权重做 秩-1 更新 (rank-one update)来编辑事实。数学上和 VPD 的秩-1 分解同构,只是方向相反:ROME 是往里改,VPD 是往外分解。
ROME 的结果:编辑超过 10 条事实就开始连锁崩溃。改了"巴黎是法国首都",模型连"法国在哪个洲"都答不上来——齿轮之间有看不见的皮带,牵一发动全身。VPD 说"我能分解为 9972 个独立齿轮",ROME 的经验说"你动其中一个,旁边九个就跟着抖"。同一个数学操作,同一个物理限制。
更致命的证据:Zhang et al. 的量化攻击,4-bit 量化就恢复了 83% 的"已遗忘"知识——量化沿所有维度做微扰,低维子空间里精心画的涂鸦被高维噪声一抖就没了,底下的原画露出来。
结论:知识编码在全维流形的曲率里,低维操作删不掉。
Cooper et al. 的 30 人联名论文说到了根子上:
泛化的本质就是信息已经融入了模型的全局结构,你无法定点删除一条数据的影响,就像你无法从一杯咖啡里把糖分子捞出来。
────────────────────
4.3 从里面拆开看——VPD 自己的数据
把 VPD 论文的数据拿来和我们的历史实验对照,会发现惊人的一致性。
第一,活组件只占 25.6%。 129 期的红楼梦实验发现:rank 超过约 18-20% hidden_dim,模型就崩溃。VPD 发现只有 25.6% 的齿轮是活的——这两个数字不能严格等同,一个是 LoRA 注入秩,一个是参数分解后的活子组件比例;但量级上的呼应很有意思。它们都在指向同一件事:模型真正稳定使用的自由度,远小于表面参数空间;你一旦越过那个低维工作区,就不是"加知识",而是在撕结构。
第二,PGD 160 步 KL 爆到 25.256。 对抗消融训练时,PGD 用梯度上升搜索"最坏的消融组合"——在路由网络认为可以关掉的分量里,找一个让模型输出损坏最大的组合。PGD 步数越多搜索越深:20 步找到的最坏情况还算温和(KL=0.828),160 步就找到了真正致命的组合(KL=25.256,输出分布完全崩溃)。这说明总存在某些齿轮组合,单独看每个都"不重要",同时关掉就完蛋——齿轮之间有隐藏的协同依赖,路由网络看不到。用傅里叶级数来类比:每个基底是单一频率,完美正交,但语言里每个词都是多频率的复合信号。抽掉几个频率分量,不是丢了"几个独立功能"——是所有词汇同时变形,因为每个词都用到了那几个频率。PGD 搜到的"致命组合",就是那几个被很多词共用的频率分量。
第三,前一词注意力跨 6 个头分布。 VPD 自己发现了这个现象——一个看似简单的功能(关注前一个词),需要 6 个注意力头协同完成。这正是即使最基本的语法结构,也是一个"复合函数"的实证——恰好验证了 131 期引用 Geva et al. 的核心结论:知识是多层注意力头和 MLP 协同完成的分布式计算,不是某个神经元里存了一张小卡片。
如果知识是分布式的,那"分解成秩-1 齿轮"这个粒度就不对。一个秩-1 矩阵 u×vᵀ 在物理上只是一个 单向信息泵 ——把沿着 v 方向的输入映射到 u 方向,仅此而已。它不是功能单元。真正的功能单元是多个这种信息泵的协同模式——跨层、跨头、跨 MLP 的分布式计算回路。
这就像你把一台发动机拆成了 9972 颗螺丝、弹簧和垫片,每颗都检查过了,然后宣布自己理解了发动机的工作原理。你理解了零件,但你没理解燃烧循环。燃烧循环是零件之间的协同时序关系,不住在任何一颗螺丝里。如果连"关注前一个词"这么简单的功能都需要 6 个头协同,那"语言理解""逻辑推理"要多少个齿轮协同?秩-1 粒度还够用吗?
数学里有个叫 Calabi-Yau 流形的东西——六维空间里高度对称、结构极其精密的几何体。但你把它投影到三维空间里看,就是一团浆糊,什么对称性都看不出来。大模型的知识结构也是这样:它活在几百维的流形上,秩-1 分解就是往一维子空间上投影——投影出来的东西,和原始结构的关系就像 Calabi-Yau 的三维投影和六维原体的关系一样:信息在投影中丢光了。
━━━━━━━━━━━━━━━━━━━━
◆ 可解释性的正确打开方式
━━━━━━━━━━━━━━━━━━━━
VPD 的学术价值不是零——对抗消融把消融实验的可靠性往前推了一步,频率最小化比 SAE 的 L1 正则化更聪明,虚词判别器对"LLM 有没有学到语法"提供了新证据。但把它吹成"真正的法医"为时过早。
SAE/NLA 路线虽然"只看激活的影子",但它能 scale。「第 180 期【AI可解释性】Anthropic 给 AI 做了脑部 CT——然后发现它知道自己在被考试」解读过:NLA 已经在 Claude 级别的模型上发现了元认知信号,16 个评测中 10 个检出率超过 5%,部分高达 20-40%。VPD 目前在 67M 上分解出了虚词判别器——有意思,但离实用还很远。
可解释性的正确姿势不是"拆到原子级"——那是 VPD 的野心。正确的姿势是 "在有用的粒度上读懂" ——这是 SAE/NLA 的路线。
原因很简单:131 期已经证明了,知识是分布式的。不存在可以单独拧下来检查的螺丝。你把螺丝拧下来的时候,承载知识的协同模式就已经不在了。
类比:你不会通过拆解 CPU 的每个晶体管来理解 Linux 内核在做什么。你需要的是 strace、perf、ftrace 这些运行时观测工具。SAE 是大模型的 perf——高频采样,定位热点。NLA 是大模型的 strace——翻译系统调用,直接告诉你模型在干什么。VPD 是拿扫描电子显微镜看晶体管的掺杂分布——学术上有意义,但你不会用它来排查一个返回 500 的 API。
工具要匹配问题的粒度。可解释性的问题是"模型为什么做了这个决策",不是"模型的第 3721 个秩-1 分量在干什么"。VPD 选了后者,漂亮地解剖了一只老鼠。
但我们需要给活人看病。坐在你面前的病人说"胸口闷",你不能把他打开看——你做心电图、做血检、做 CT。可解释性的未来大概率也是这样:静态分解提供基础知识(VPD 的贡献在这里),运行时观测解决实际问题(SAE/NLA 的战场在这里)。两者互补,但别搞反了主次。
━━━━━━━━━━━━━━━━━━━━
参考文献
━━━━━━━━━━━━━━━━━━━━
Goodfire, "Interpreting Language Model Parameters", 2026.5 (https://www.goodfire.ai/research/interpreting-lm-parameters) GitHub: https://github.com/goodfire-ai/param-decomp APD: arxiv.org/abs/2501.14926 SPD: arxiv.org/abs/2506.20790 Anthropic, "Scaling Monosemanticity", 2024 Anthropic, "Natural Language Autoencoders", 2026.5 Cooper et al., "Machine Unlearning Doesn't Do What You Think", 2024 Meng et al., "Locating and Editing Factual Associations in GPT" (ROME), NeurIPS 2022 Geva et al., "Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space", 2022 Zhang et al., "Catastrophic Failure of LLM Unlearning via Quantization", ICLR 2025
━━━━━━━━━━━━━━━━━━━━
// 靳岩岩的 AI 学习笔记 × Claude 的严谨 × Gemini 的浪漫
// 2026-05-11
