 夜雨聆风
夜雨聆风
人工智能系统现在能够以低成本生成看似合理的科学成果,例如论文、评论和调查。这给我们的科学系统(scientific systems)带来了“认知污染(epistemic pollution)”的风险,即不可靠但看似合理的成果会以远超系统过滤速度的速度积累。问题在于结构性因素:科学的认知基础设施是为这样一个世界而设计的:生成一份看似合理的成果需要大量的专业知识、人力和时间,因此生成成本本身就起到了一种粗略的过滤作用;而人工智能削弱了这种过滤作用,却没有相应地降低验证成本。我们认为,“人工智能时代的科学应该将此视为一个工程问题:重新设计认知基础设施,以平衡生成成本和验证成本”。当前以论文为中心的系统使得验证成本高昂:论文将冗长的科学逻辑压缩成散文,迫使审稿人(无论是人还是人工智能)在评估论文之前,必须先重构其潜在的论证结构。作为朝着这个方向迈出的一步,我们提出将“蓝图”(blueprints)作为初步的认知基础设施:它是结构化的、分解的研究成果,以类型化的图组件(graph components)形式表示主张、证据、假设和定义。蓝图旨在以较低的前期生成成本换取下游更经济、更本地化、更分布式的验证。我们已在概念验证原型中实现了这一方案。

请索引第92篇论文
 |  |
你的论文可能正在“中毒”:AI时代,科学该如何自救?
当生成一篇“像模像样”的SCI比点外卖还快,谁来保证科学的底线?
如果你是一名研究生,最近可能有这种感觉:arXiv上充斥着大量行文流畅、图表精美,但读完后总觉得“哪里不对劲”的综述;审稿意见里,开始出现逻辑自洽却完全没抓住重点的“AI腔”。
这不是错觉。伊利诺伊大学香槟分校(UIUC)的Jiaqi W. Ma助理教授在最新的工作论文《Toward an Engineering of Science》中,提出了一个振聋发聩的观点:科学界正在面临一场“认知污染”(Epistemic Pollution)。
今天,我们就来深度拆解这篇极具前瞻性的论文,看看AI是如何打破科学大厦的平衡,以及我们这些科研民工该如何应对。
01 危机:当“生成”变得廉价,“验证”成了瓶颈
论文指出,传统的科学基础设施(论文、同行评审、引用体系)是在一个“生成成本极高”的世界里建立的。
以前,写一篇论文需要读文献、做实验、推导公式,耗时数月甚至数年。这种高昂的成本本身就是一个过滤器,挡住了大部分垃圾。
但AI改变了游戏规则。
现在的AI可以瞬间生成代码、撰写综述、伪造数据,甚至写出能通过顶会门槛的“完美”论文(论文中提到的AI Scientist-v2已经做到了这一点)。
这就导致了“生成-验证”成本的严重失衡:
生成端: 成本趋近于零,速度极快。
验证端: 成本依然极高,需要专家花数小时甚至数天去复现、去推敲逻辑。
这就像是一个城市每天产生十万吨垃圾,但垃圾处理厂的处理能力只有一吨。结果是什么?“认知污染”。
“DDoS攻击”与“僵尸评审”
论文列举了两个令人细思极恐的现象:
Survey Paper DDoS Attack: 2025年10月,arXiv的CS板块被迫修改政策,要求综述必须经过正式同行评审才能发布。原因就是AI生成的综述像洪水一样淹没了预印本平台,这是一种针对科研人员注意力的“拒绝服务攻击”。
AI评审AI: 有研究显示,顶级AI会议上高达21%的审稿意见是由AI生成的。这意味着:AI写的论文,正在由AI来审稿。
如果这一闭环形成,科学将不再是真理的探索,而是“胡说八道”的自我繁殖。
02 病灶:为什么现在的论文这么难审?
为什么验证成本降不下来?论文一针见血地指出:因为我们的载体是“散文式论文”(Prose Paper)。
我们现在的论文是线性的、叙事性的文本。为了可读性,作者把复杂的逻辑网络压缩成了流水账。
作者的脑海里是一张图(Graph),写出来却变成了一条线(Text)。
审稿人拿到论文后,必须做一件极其痛苦的事——“逆向工程”。你要从几千字的文本中,把作者脑海里的那张逻辑图重新拼凑出来,找到Claim(主张)、Evidence(证据)、Assumption(假设)之间的关系。
这不仅耗时,而且极易出错。这也是为什么现在的AI很难自动审稿——因为长文本的线性化丢失了结构信息。
03 解药:Blueprint(蓝图)——科学的“工程化”尝试
为了解决这个结构性问题,作者提出了一个激进的方案:重构科学产出物本身。
他提出了 Blueprint(蓝图) 的概念。这不仅仅是一个新格式,更是一种新的科研范式。
Blueprint借鉴了数学界著名的 leanblueprint(用于Lean定理证明)的思想,将长篇大论分解为结构化的论证图谱。
1. 什么是Blueprint?
Blueprint是一个有向图(Directed Graph)。在这个图中:
节点(Nodes): 包含 Claim(主张)、Evidence(证据)、Assumption(假设)、Definition(定义)、Risk(风险)等。
边(Edges): 定义了它们之间的逻辑关系,如 Supports(支持)、Expands(展开)、Contradicts(反驳)。
为了让你直观理解这种数据结构,请看论文中的示意图:
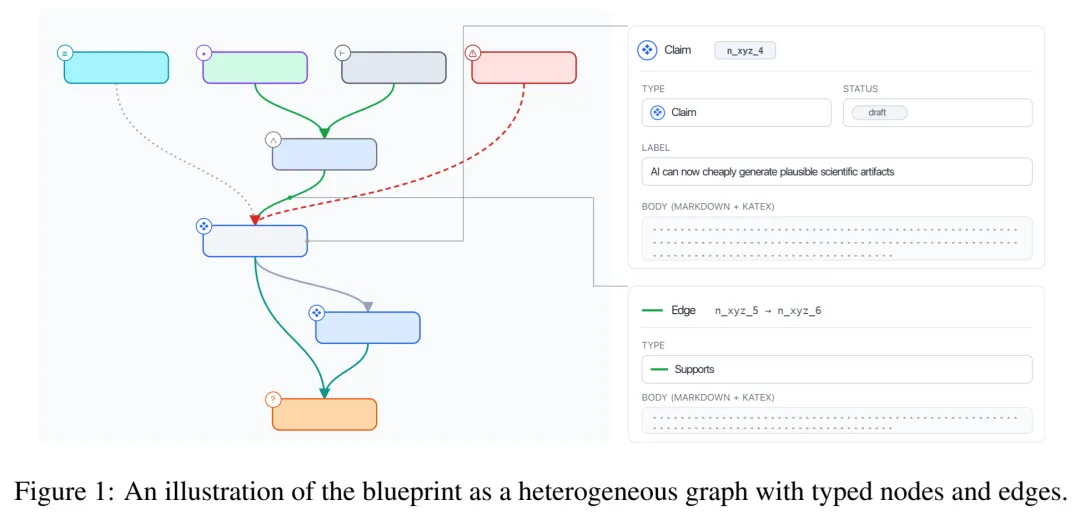
这是一个典型的Blueprint结构。不再是线性的文字,而是模块化的组件。每一个Claim都需要有明确的Supports关系指向它。
2.双界面协作
为了让人类和AI都能编辑,Blueprint设计了两个接口:
浏览器画布(Canvas): 给人类看的思维导图式界面。
命令行接口(CLI): 专门给AI Agent用的API。

作者在左侧用自然语言写草稿,右侧通过CLI指挥AI Agent去填充证据、检查逻辑漏洞。两者实时同步。
3. 状态追踪(Status)
Blueprint引入了软件工程中的“状态管理”。
一个Evidence可以是
Missing(缺失) ->Cited(已引用) ->Verified(已验证)。一个Claim可以是
Draft(草稿) ->Stated(陈述) ->Supported(被支持)。
这种机制让“半成品”科学变得透明。 审稿人一眼就能看出,这篇论文有多少主张是“裸奔”的,没有任何证据支持。
04 启示:对我们本硕博学生意味着什么?
读完这篇论文,图科学实验室认为,这对我们年轻研究者既是挑战,也是巨大的机遇。
1. 警惕“AI代写陷阱”
如果你的研究只是把数据喂给AI,让它生成漂亮的叙事,你的工作很可能成为“认知污染”的一部分。未来的评价体系一定会惩罚那些没有透明逻辑结构的“黑箱研究”。
2. 学会“分解”你的研究
不要只盯着最终的PDF论文。试着像搭积木一样构建你的研究:
我的核心主张是什么?(Claim)
支撑它的证据链在哪里?(Evidence Graph)
哪些是强假设?(Assumptions)
Blueprint思维能帮你提前发现逻辑漏洞,而不是等到审稿人指出来才后悔。
3. 拥抱“人机协作”的新范式
论文中提到,Blueprint允许AI Agent作为协作者。你可以让AI去查漏补缺,去质疑你的假设(Risk),去整理证据。
未来的科学家,不再是谁更能写,而是谁更能设计好这张“逻辑蓝图”。
05 结语
这篇论文不仅仅是关于工具的革新,它是对科学本质的一次回归。
正如作者所言:“科学不应该只是看起来像科学(Plausible),它必须是可验证的科学(Verifiable)。”
当AI能轻易制造出“看起来像科学”的垃圾时,我们需要像工程师一样,重新设计科学的管道,把“验证”的成本降下来。Blueprint或许只是一个开始,但它指明了一个方向:在AI时代,只有结构化的真理,才能对抗生成式的噪音。
各位同学,你们觉得这种“蓝图式科研”可行吗?欢迎在评论区留言讨论。
关注 @图科学实验室Graph Science Lab,带你用图视角看透前沿科技。



