 夜雨聆风
夜雨聆风## 一、起点:推理是内存带宽受限的任务
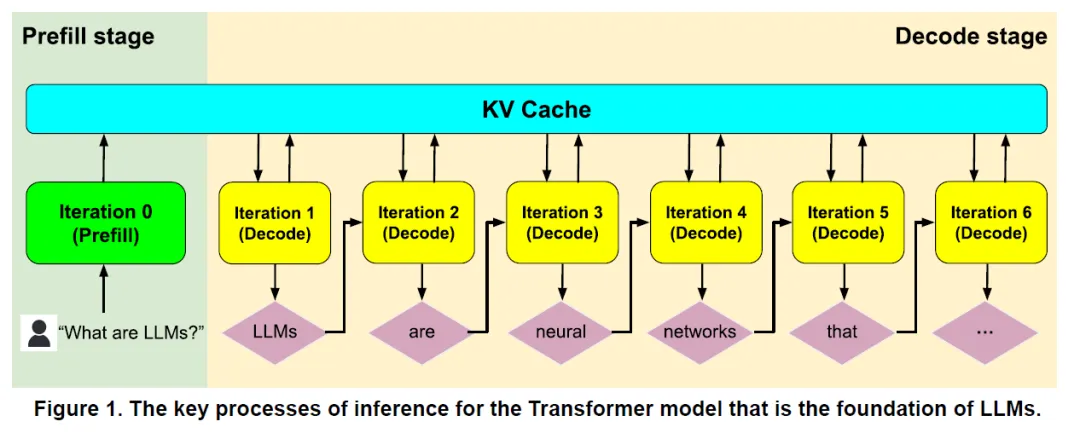
## 二、证据:Memory 正在成为 AI 芯片的最大成本项
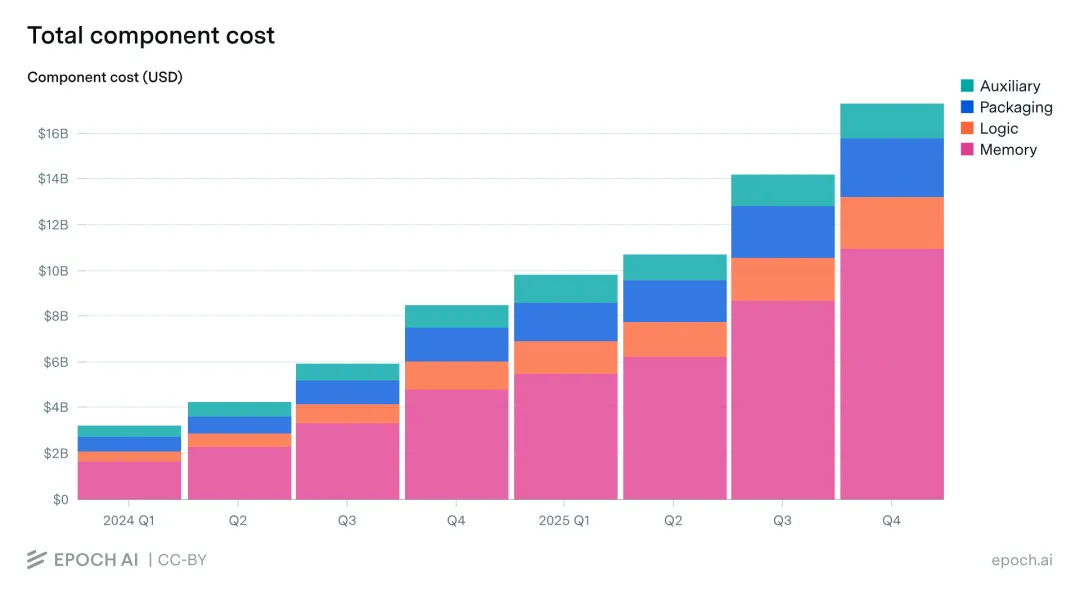
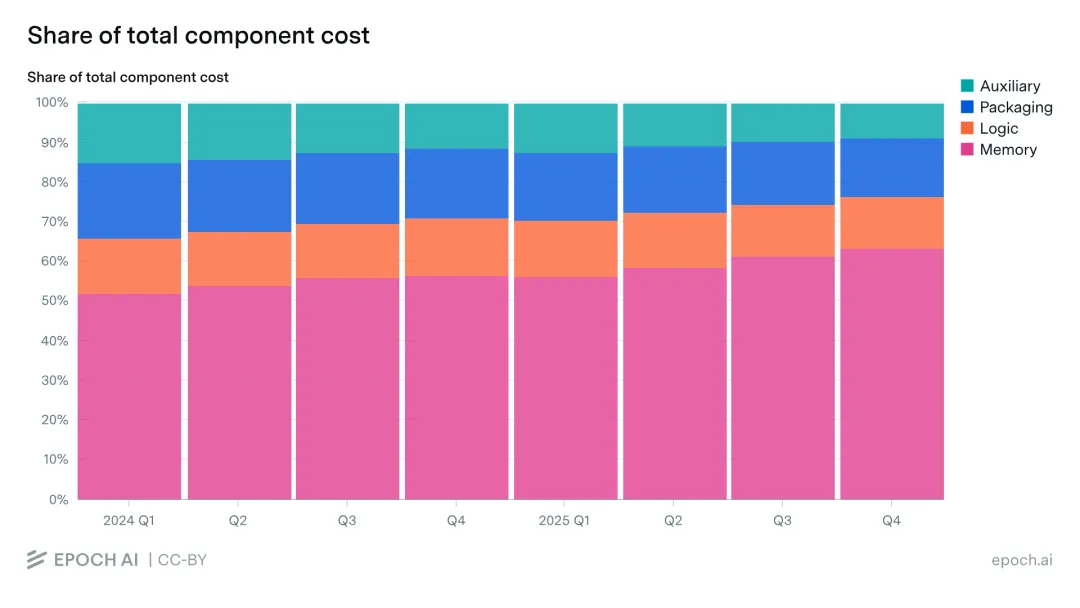
**架构驱动**:每代 AI 加速器的 HBM stack 数量、stack 高度、容量和带宽都在上升,单位加速器的 memory dollars 自然增长。 **工作负载驱动**:从训练到推理、从单次问答到 agent、从短上下文到长上下文——每一步都增加 KV cache、并发状态和内存强度。 **ASP 上升**:供需紧张推高价格,但这是结果而非原因。
## 三、放大器:HBM 的 3:1 挤出效应
## 四、需求端:AI 服务器从五条线同时消耗先进 DRAM
**HBM3E / HBM4 / HBM4E**:GPU/ASIC 侧核心瓶颈,带 3:1+ 的 trade ratio。 **DDR5 RDIMM / MRDIMM**:x86/ARM host memory,128GB/256GB 高容量模组需要先进 die。 **LPDDR5X / LPDDR6 / SOCAMM**:Grace、Vera Rubin 等平台将移动端 LPDDR 引入服务器。 **CXL Memory**:内存扩展和池化,底层仍消耗 DDR5 DRAM die。
### 第五条线:Agent AI 时代的 CPU 侧内存爆炸
## 五、供给端:三重结构性约束
### 约束一:EUV 光刻系统瓶颈
### 约束二:HBM 封装和测试产能
### 约束三:寡头格局与产能互斥
## 六、需求来源的持续性:CSP Capex 从 OCF 约束走向融资扩张
## 七、综合推演:四层叠加的增长逻辑
## 八、时间维度与关键不确定性
**需求端**:AI capex ROI 无法兑现,CSP 削减 2027-2028 支出;利率上行抬高融资成本。 **供给端**:三大厂新产能同步释放;HBM 竞争稀释份额和议价力;库存双重下单引发修正。 **技术替代**:KV cache 压缩、量化、投机解码等软件优化降低每 token 的 HBM 消耗;CXL memory pooling、HBF(高带宽闪存)提高系统内存利用率,削弱 HBM 作为唯一高带宽池的地位。 **CPU 侧不确定性**:Agent 工作负载的实际 CPU 密集度可能低于预期;x86 阵营(AMD EPYC)可能延缓 LPDDR SOCAMM 的采纳速度,坚持 DDR5 RDIMM 路线;若 agent 渗透率不及预期,CPU:GPU 部署比回归传统水平,CPU 侧的第二条需求曲线将被推迟。
