 夜雨聆风
夜雨聆风
你肯定干过这种事:把一份几十页的纯英文 PDF 扔给大模型,然后问“第三章的核心结论是什么”。它几秒钟就能给出精准的中文回答。
它真的把整份文件“背”下来了吗?并没有。它其实是先去文件里“翻书”,找到最相关的段落,再结合这些段落来回答你。
这个“先翻书、再回答”的动作,就是 RAG(Retrieval-Augmented Generation,检索增强生成)。
说白了,就是让 AI 先查资料再回答,不要凭脑子编。
在 AI 核心概念大扫盲,LLM 里提过,LLM 负责"想",RAG 负责"查"。RAG 就是 AI 系统里的资料检索层,给 LLM 做"开卷考试"用的。
为什么需要 RAG
LLM 本身有几个短板:
- 不知道你的私有数据。
公司内部文档、个人笔记、业务数据库,模型训练时从没见过,问了也答不上来。这是 RAG 最核心的价值。 - 可能产生幻觉。
模型有时会一本正经地编造事实。RAG 给它真实的参考材料,能降低编造的概率——但如果检索到的内容本身不靠谱,也可能帮倒忙。 - 成本比微调低。
比起 Fine-tuning(微调模型),RAG 的门槛更低,数据更新也灵活——改知识库就行,不用重新训练。
那直接塞进长上下文不行吗?
现在主流模型的上下文窗口已经到了 100K-200K+ token,很多人会问:直接把文档全丢进去,还要 RAG 干嘛?
简单说:
- 文档少、内容固定→ 直接丢长上下文更省事
- 数据量大、持续更新、要控成本 → RAG 是更优解
- 实际生产中,主流做法是两者结合:RAG 先捞出最相关的内容,再丢进长上下文让模型深度推理
还有个实际问题:关键信息埋在长上下文中间位置时,模型准确率会明显下降(业内叫"lost in the middle",中间丢失问题)。RAG 能把最相关的内容集中送到模型面前,绕开这个坑。
基本流程
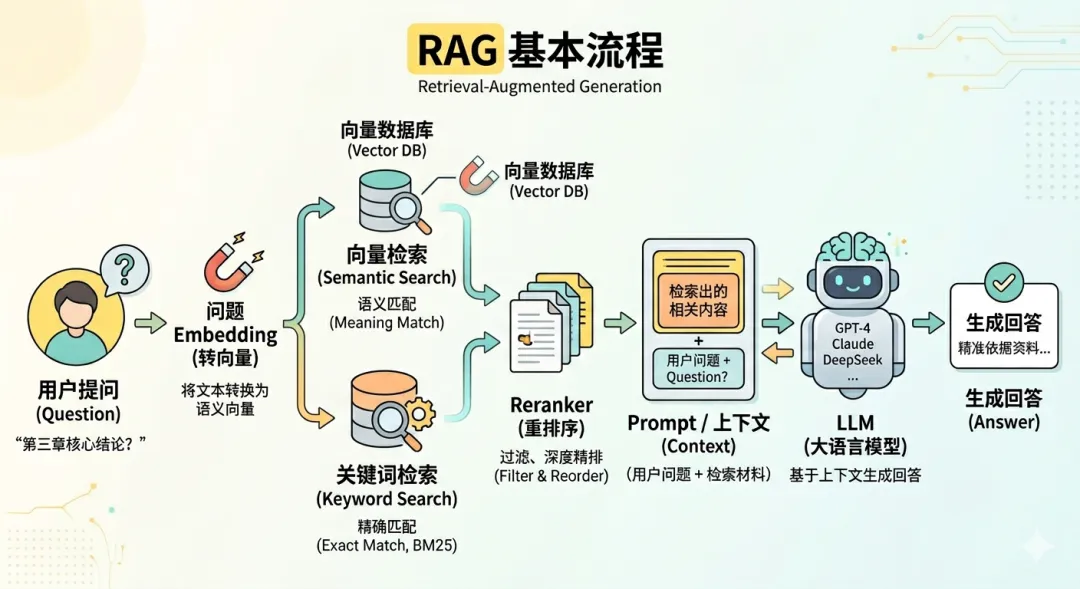 可参考上图。核心流程:
可参考上图。核心流程:
用户提问 → 把问题转成向量(Embedding) → 去数据库检索 → 找到最相关的内容 → 塞进 Context → LLM 生成答案。
这张图完整展示了 RAG 的核心技术闭环:
- 输入端:
捕捉用户提问并进行 Embedding 向量化。 - 检索核心(混合检索):
左侧清晰展示了向量检索(语义匹配)与关键词检索(BM25)的双路并行结构。 - 精排与生成:
检索结果汇总后经过 Reranker(重排序) 精炼,最后与用户原问题拼成 Prompt 塞给 LLM 生成最终回答。
核心组件
| Embedding 模型 | ||
| 向量数据库 | ||
| Retriever(检索器) | ||
| Reranker(重排序) | ||
| LLM |
RAG 的演进
RAG 不是一成不变的,从 2023 年到现在,架构一直在进化。
Naive RAG(基础版)
搜索 → 拼接 → 回答。用户问什么就检索什么,结果直接塞给 LLM。能跑,但检索质量不稳定,文档切块(chunk)方式稍微没弄好,结果就飘了。大部分入门教程教的都是这个。
Advanced RAG(进阶版)
加了查询改写、混合检索、Reranker 重排序、多文档融合这些手段,检索精度上了一个台阶。现在大多数生产系统的基线配置就是这个。Adaptive RAG(自适应)也属于这一层——简单问题走轻量路径省钱,复杂问题才上全套,核心是控成本。
Agentic RAG(智能体版)
AI 不再被动执行"搜→拼→答",而是自己判断:要不要查、查什么、查几次、够不够用,不够就继续查,过程中还会自我纠错。跟 Agent 结合后,就是一个能自主决策的检索智能体。适合复杂问题,比如"对比这三家公司过去五年的财报表现"。LangGraph、LlamaIndex 的 Agent 模式都能搭这种架构。
Graph RAG(图谱版)在文档上面再建一层知识图谱(实体 + 关系),用图结构做推理。适合跨文档关联、理解实体关系的场景。法律、金融、医疗这些行业用得多,精度很高。微软的 GraphRAG 项目把这个方向带火了。
RAG 的局限
RAG 不是万能的,几个坑要知道:
- 检索质量是天花板。
检索结果不相关,LLM 再强也没用——垃圾进,垃圾出。 - 文档切块(Chunk)是门学问。
切太细丢上下文,切太粗噪音多,这个调参过程很折腾。 - 不是所有场景都需要。
数据量小、内容固定,直接用长上下文可能更省事。 - 幻觉不能完全消除。
检索到的内容互相矛盾或不相关时,模型还是可能出错。
一句话收尾
RAG 就是给 AI 装了个"研究助理",先查再答。不一定每个场景都要用,但做 AI 产品大概率绑不开它。
