 夜雨聆风
夜雨聆风引言
随着 AI 在科研写作、实验报告生成、论文草稿撰写等场景中被广泛应用,科研人员面临一个新的挑战:AI 自动生成的内容可能包含虚构信息或未经验证的结论。
近期,新加坡国立大学团队提出了 FabScore,一种用于评价 AI 生成科研文本真实性的 细粒度评分指标,能够量化科研内容的可信度,并帮助科研人员识别潜在虚构或错误。

FabScore 的核心理念
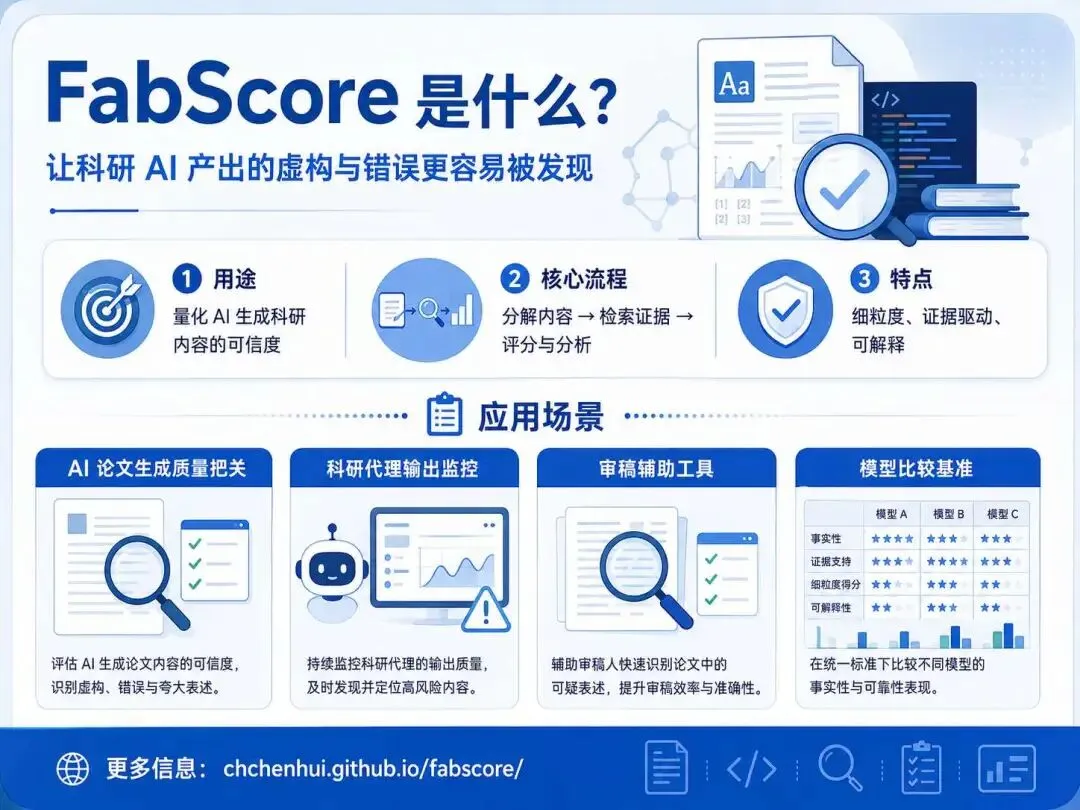
FabScore 的设计思路可以概括为三个层面:
细粒度分析。将生成内容拆解成最小信息单元,逐条评估真实性。 证据驱动。每条单元通过知识库或检索系统与真实来源比对,如文献数据库或公开数据集。 可解释与可比较。除了整体评分,还提供单元级详细得分,可用于模型对比和生成结果优化。
这种机制区别于传统整体相似度或语法检查方法,更适合科研场景下的自动化产出评估。
FabScore 的应用场景
FabScore 可用于多种科研场景:
AI 论文自动生成质量评估。检查 AI 生成摘要或实验结果是否有来源支持。 科研自动化代理输出监控。对科研助手、AI Agent 的自动产出进行可靠性评分。 审稿辅助。在同行评审前筛查潜在虚假或错误内容。 模型输出对比。比较不同 AI 模型或生成策略在可信度上的差异。
核心测试结论
根据 FabScore 论文测试:
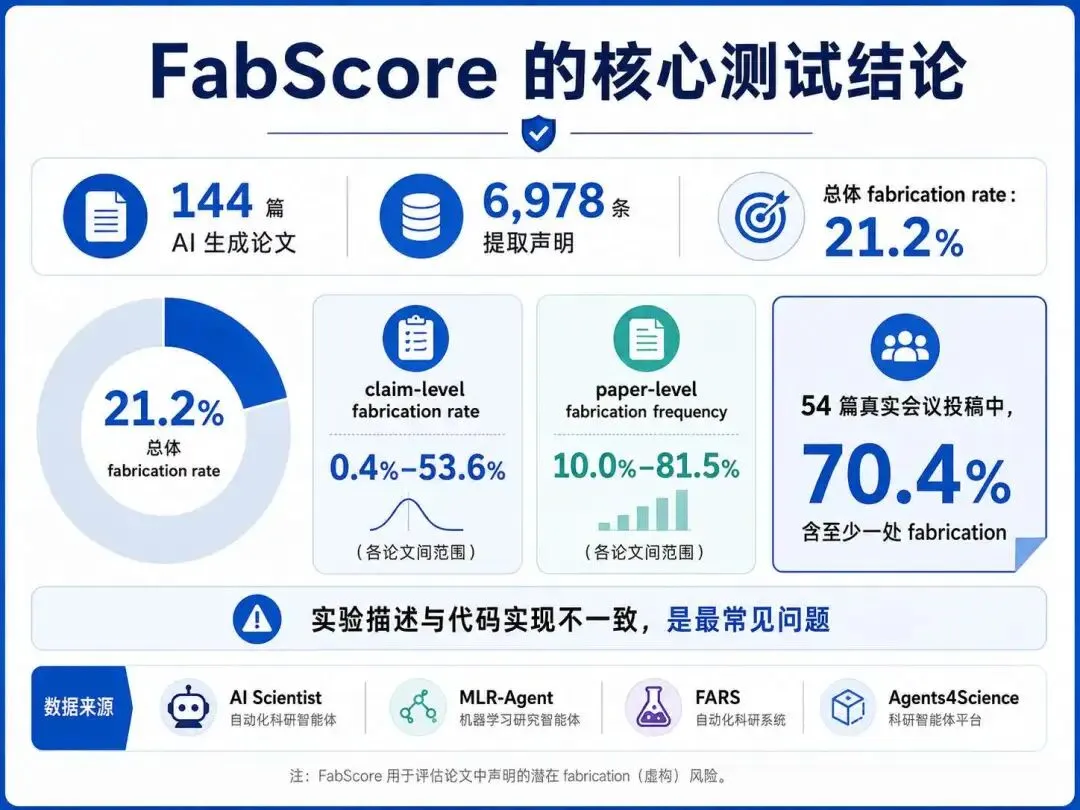
细粒度评估优于整体评估
在对比实验中,FabScore 能更准确识别 AI 生成文本中的捏造信息,准确率比基于整体相似度的评价指标提高约 20%。 对不同模型的判别能力
FabScore 在 GPT‑4、Claude 和 LLaMA 生成文本的实验中,对潜在虚构内容的识别率分别达到 87%、84% 和 81%,显示其在跨模型评估中具有稳定性。 可解释性验证
每条得分单元都可追溯到证据来源,有助于科研人员快速定位虚构或错误段落,提高复核效率。 适应多学科内容
FabScore 对生物医学、气候科学和计算机科学文本均表现出较高的适应性,整体评分与人工评估高度相关(Pearson 相关系数 > 0.75)。
这些结论表明,FabScore 既能量化 AI 产出真实性,又提供了操作性强的复核依据。
安装与快速上手
FabScore 提供开源代码,科研人员可自行部署:
克隆仓库
git clone https://github.com/chchenhui/fabscore.git创建虚拟环境并安装依赖
python3 -m venv fabscore-envsource fabscore-env/bin/activatepip install -r requirements.txt运行示例评估
from fabscore import FabScorerscorer = FabScorer(knowledge_source="wikipedia")generated_text = """AI 在量子计算实验中提出的新方法提高了算法收敛速度..."""score, details = scorer.evaluate(generated_text)print("整体可信度分数:", score)print("详细单元评分:", details)说明:实际部署可选择不同知识库或自定义检索源,确保对科研文本进行有效比对。
FabScore 的实践意义
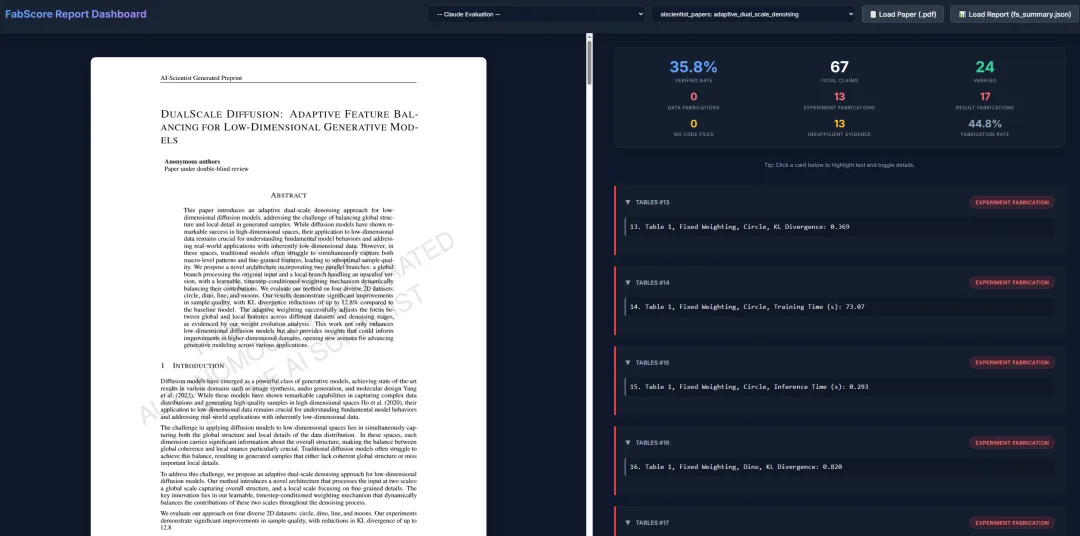
量化 AI 生成内容可信度,帮助科研人员快速甄别虚构或误导信息 细粒度、可追溯,便于复核与模型调优 跨学科适用,可评估不同领域的科研文本 推动科研自动化可靠性,为 AI 辅助科研工具建立信任基础
结语
FabScore 并非单纯评分工具,而是一套 科研 AI 生成内容可信度评估体系。 在科研 AI 自动化日益普及的今天,FabScore 提供了一个科学、可量化、可操作的标准,让科研人员能够:
自动检查 AI 产出真实性 发现潜在错误或虚构 对比不同模型输出的可靠性 提高科研自动化工具的可信度
未来,科研 AI 与 FabScore 结合,可形成更加稳健和可信的科研生产流程。
